文章目录
- [Ⅰ. Elasticsearch 的介绍与安装](#Ⅰ. Elasticsearch 的介绍与安装)
- [Ⅱ. Elasticsearch 的核心概念](#Ⅱ. Elasticsearch 的核心概念)
-
-
- **索引**(Index)
- ~~**类型**(Type)~~
- **文档**(Document)
- **字段**(Field)
- **映射**(Mapping)
- [倒排索引(Inverted Index)](#倒排索引(Inverted Index))
- 分析器(Analyzer)
- 查询(Query)
-
- [Ⅲ. Kibana 访问 es 进行测试](#Ⅲ. Kibana 访问 es 进行测试)
- [Ⅳ. ES 客户端接口介绍与使用](#Ⅳ. ES 客户端接口介绍与使用)
- [Ⅴ. ES 客户端二次封装](#Ⅴ. ES 客户端二次封装)

Ⅰ. Elasticsearch 的介绍与安装
Elasticsearch ,也简称 ES ,它是个 开源分布式搜索引擎。
它的特点有:分布式、零配置、自动发现、索引自动分片、索引副本机制、restful 风格接口、多数据源、自动搜索负载等。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。es 也使用 Java 开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。
Elasticsearch 是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它 不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。
在 Elasticsearch 中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
安装Elasticsearch服务
shell
# 添加仓库秘钥
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
# 添加镜像源仓库
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elasticsearch.list
# 更新软件包列表
sudo apt update
# 安装 es
sudo apt-get install elasticsearch=7.17.21
# 启动 es
sudo systemctl start elasticsearch
# 查看 es 服务的状态
sudo systemctl status elasticsearch.service
# 安装 ik 分词器插件(ik分词器是中文分词器)
sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/7.17.21
# 验证 es 是否安装成功
curl -X GET "http://localhost:9200/"若
apt update更新源报错:
shellliren@hcss-ecs-7ba8:~/chat_platform/es$ apt-key list Warning: apt-key is deprecated. Manage keyring files in trusted.gpg.d instead (see apt-key(8)). /etc/apt/trusted.gpg # ubuntu 希望将 apt-key 放到 /etc/apt/trusted.gpg.d/下而不是这个文件中 -------------------- pub rsa2048 2013-09-16 [SC] 4609 5ACC 8548 582C 1A26 99A9 D27D 666C D88E 42B4 # 注意最后这 8 个字符 uid [ unknown] Elasticsearch (Elasticsearch Signing Key) <dev_ops@elasticsearch.org> sub rsa2048 2013-09-16 [E] liren@hcss-ecs-7ba8:~/chat_platform/es$ sudo apt-key export D88E42B4 | sudo gpg --dearmour -o /etc/apt/trusted.gpg.d/elasticsearch.gpg # 完成后,查看/etc/apt/trusted.gpg.d/,应该已经将 apt-key 单独保存到目录下了若启动
es的时候报错:
shell# 调整 ES 虚拟内存,虚拟内存默认最大映射数为 65530,无法满足 ES 系统要求,需要调整为 262144 以上 sysctl -w vm.max_map_count=262144 # 增加虚拟机内存配置 vim /etc/elasticsearch/jvm.options # 在上述文件中新增如下内容 -Xms512m -Xmx512m
设置外网访问操作:如果新配置完成的话,默认只能在本机进行访问!
shell
vim /etc/elasticsearch/elasticsearch.yml
# 新增配置
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"] 然后浏览器访问 http://ip地址:9200/ 即可,但是一般不开启,因为开启了容易受到攻击!
安装kibana
Kibana 是一个 开源的数据分析与可视化平台 ,主要用于与 Elasticsearch 配合使用。它能够帮助用户搜索、查看和分析存储在 Elasticsearch 中的数据,并通过丰富的图表、表格、地图等形式直观地展示数据,从而实现高级的数据分析和可视化功能。
Kibana 提供了一个控制台插件 Dev Tools ,允许用户直接与 Elasticsearch 的 REST API 交互,执行查询、插入、更新和删除数据等操作,我们这里也主要用的就是这个功能!
shell
# 安装 Kibana:
sudo apt install kibana
# 配置 Kibana(可选):
# 根据需要配置 Kibana。配置文件通常位于 /etc/kibana/kibana.yml。可能需要设置如服务器地址、端口、Elasticsearch URL 等。
# 例如,你可能需要设置 Elasticsearch 服务的 URL: 大概 32 行左右 elasticsearch.host: "http://localhost:9200"
sudo vim /etc/kibana/kibana.yml
# 启动 Kibana 服务:
sudo systemctl start kibana
# 设置开机自启(可选):如果你希望 Kibana 在系统启动时自动启动,可以使用以下命令来启用自启动。
sudo systemctl enable kibana
# 验证安装是否成功:
sudo systemctl status kibana 启动服务后,就可以在浏览器中访问 Kibana,通常地址是 http://ip地址:5601。
注意:如果访问不了的话,很可能是云服务器里面没有开通这个端口的访问权限,去后台打开即可!
安装Elasticsearch客户端
代码:https://github.com/seznam/elasticlient
官网:https://seznam.github.io/elasticlient/index.html
ES C++ 的客户端选择并不多,我们这里使用 elasticlient 库,下面进行安装:
shell
# 克隆代码
git clone https://github.com/seznam/elasticlient
# 切换目录
cd elasticlient
# 更新子模块
git submodule update --init --recursive
# 编译代码
mkdir build && cd build
sudo apt-get install libmicrohttpd-dev
cmake -DCMAKE_INSTALL_PREFIX=/usr ..
make
# 安装
sudo make install 最后运行测试用例:make test,如果没问题的话就是安装成功了!
Ⅱ. Elasticsearch 的核心概念
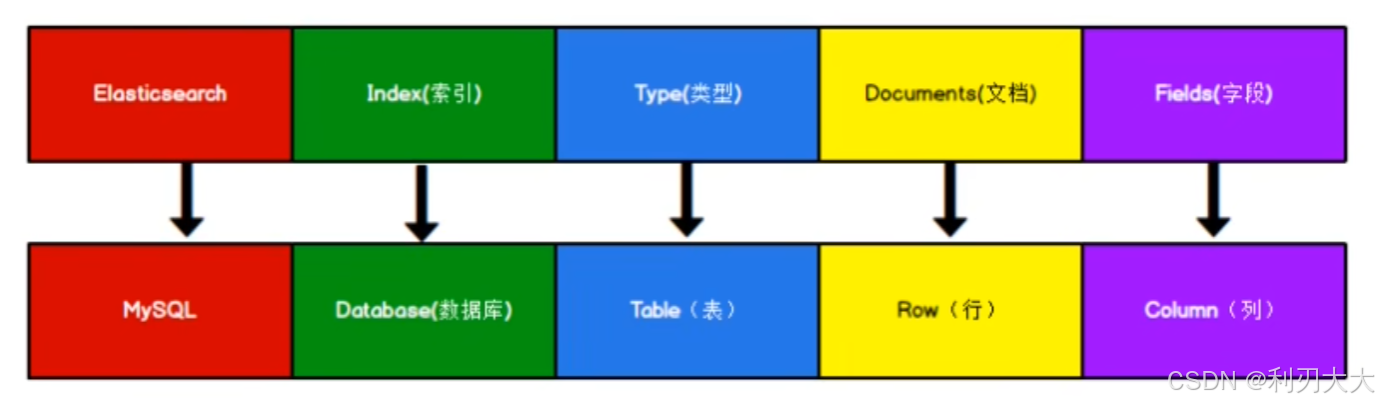
索引(Index)
- 定义 :类似数据库中的库,用于存储相关文档。
- 特点:每个索引有唯一名称,支持分片和副本。
类型(Type)
- 定义 :索引中的逻辑分类,类似数据库中的表(在 6.x 版本后逐渐弃用,7.x 已移除)
文档(Document)
- 定义 :索引中的基本数据单元,以
JSON格式存储。类似数据库的表中的每行数据。 - 特点 :每个文档有唯一
ID,属于某个索引和类型。
字段(Field)
- 定义 :相当于是数据表的字段,也就是表的每一列,对文档数据根据不同属性进行的分类标识。
| 分类 | 类型 | 备注 |
|---|---|---|
| 字符串 | text、keyword | text 会被分词生成索引; keyword 不会被分词生成索引,只能精确值搜索 |
| 整形 | integer、long、short、byte | |
| 浮点 | double、float | |
| 逻辑 | boolean | true 或 false |
| 日期 | date、date_nanos | "2018-01-13" 或 "2018-01-13 12:10:30"或者时间戳,即 1970 到现在的秒数/毫秒数 |
| 二进制 | binary | 二进制通常只存储,不索引 |
| 范围 | range |
映射(Mapping)
- 定义 :定义索引中字段的类型和属性。简单的说,映射是在处理数据的方式和规则方面做一些限制,类似于数据库中的表结构,如某个字段的数据类型、默认值、分析器、是否被索引等等。
- 作用:决定字段如何被索引和搜索。
| 名称 | 数值 | 备注 |
|---|---|---|
| enabled | true(默认) | false | 是否仅作存储,不做搜索和分析 |
| index | true(默认) | false | 是否构建倒排索引(决定了是否分词,是否被索引) |
| index_option | ||
| dynamic | true(缺省) | false | 控制 mapping 的自动更新 |
| doc_value | true(默认) | false | 是否开启 doc_value,用户聚合和排序分析,分词字段不能使用 |
| fielddata | fielddata": {"format":"disabled"} | 是否为 text 类型启动 fielddata,实现排序和聚合分析 针对分词字段,参与排序或聚合时能提高性能,不分词字段统一建议使用 doc_value |
| store | true | false(默认) | 是否单独设置此字段的是否存储而从 _source 字段中分离,只能搜索,不能获取值 |
| coerce | true(默认) | false | 是否开启自动数据类型转换功能,比如:字符串转数字,浮点转整型 |
| analyzer | "analyzer": "ik" | 指定分词器,默认分词器为 standard analyzer |
| boost | "boost": 1.23 | 字段级别的分数加权,默认值是 1.0 |
| fields | "fields": { "raw": {"type": "text", "index": "not_analyzed" } } | 对一个字段提供多种索引模式,同一个字段的值,一个分词,一个不分词 |
| data_detection | true(默认) | false | 是否自动识别日期类型 |
倒排索引(Inverted Index)
- 定义:用于快速查找文档的数据结构,存储单词到文档的映射。
- 特点:支持全文搜索。
分析器(Analyzer)
- 定义 :用于文本分析,将文本转换为词条(
terms)。 - 组成 :
- 字符过滤器(Character Filter):预处理文本
- 分词器(Tokenizer):将文本拆分为词条
- 词条过滤器(Token Filter):进一步处理词条
查询(Query)
- 定义:用于搜索索引中文档的请求。
- 类型 :
- 全文查询(Full-text Queries) :如
match查询。 - 词条查询(Term-level Queries) :如
term查询。
- 全文查询(Full-text Queries) :如
Ⅲ. Kibana 访问 es 进行测试
创建索引库
cpp
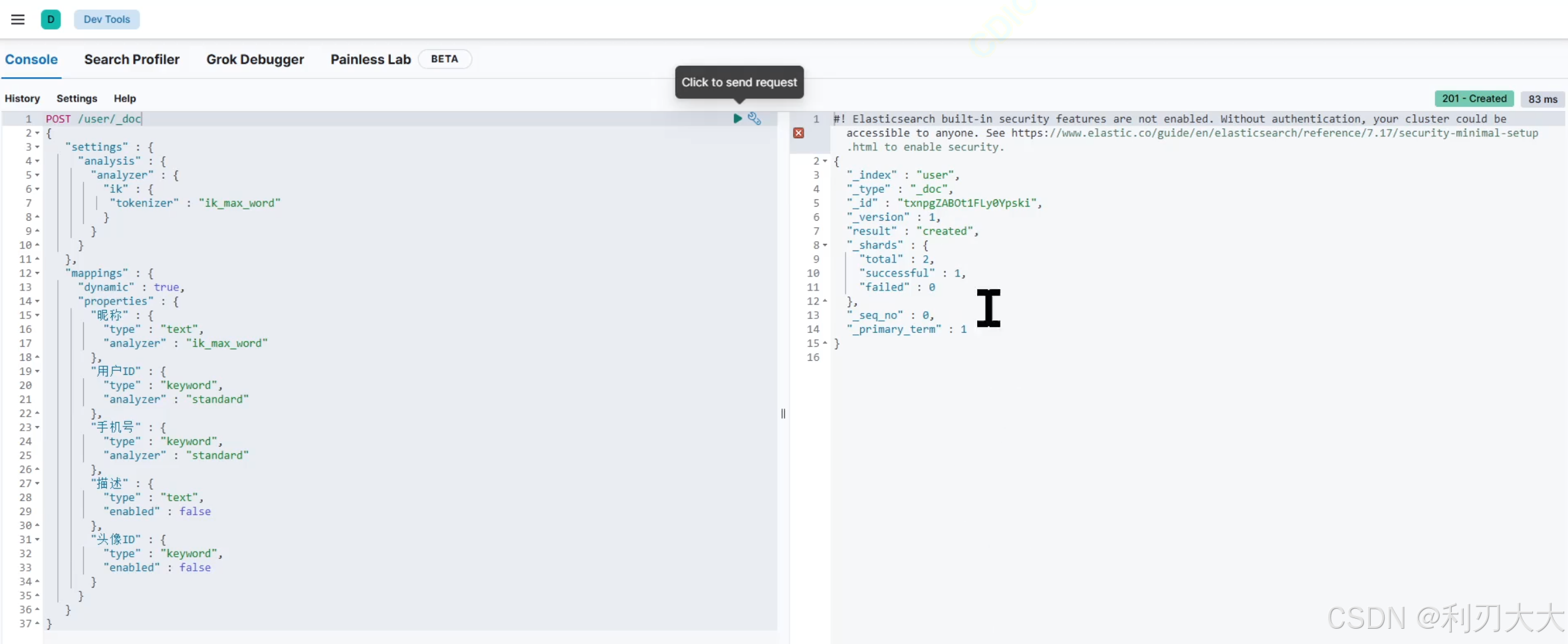
POST /user/_doc // user是索引名,_doc是类型名(es默认的,但是通常也要写上)
{
"settings" : {
"analysis" : {
"analyzer" : {
"ik" : {
"tokenizer" : "ik_max_word"
}
}
}
},
"mappings" : {
"dynamic" : true, // 动态映射,表示如果索引文档中包含未定义的字段,会自动创建字段
"properties" : {
"昵称" : {
"type" : "text",
"analyzer" : "ik_max_word"
},
"用户id" : {
"type" : "keyword",
"analyzer" : "standard"
},
"手机号" : {
"type" : "keyword",
"analyzer" : "standard"
},
"描述" : {
"type" : "text",
"enabled" : false // 禁用该字段的索引,意味着不能进行搜索
},
"头像id" : {
"type" : "keyword",
"enabled" : false
}
}
}
}
新增数据
cpp
POST /user/_doc/_bulk // _bulk就表示插入一堆数据
{"index":{"_id":"1"}}
{"user_id" : "USER4b862aaa-2df8654a-7eb4bb65-e3507f66","nickname" : "昵称 1","phone" : "手机号 1","description" : "签名 1","avatar_id" : "头像 1"}
{"index":{"_id":"2"}}
{"user_id" : "USER14eeeaa5-442771b9-0262e455-e4663d1d","nickname" : "昵称 2","phone" : "手机号 2","description" : "签名 2","avatar_id" : "头像 2"}
{"index":{"_id":"3"}}
{"user_id" : "USER484a6734-03a124f0-996c169d-d05c1869","nickname" : "昵称 3","phone" : "手机号 3","description" : "签名 3","avatar_id" : "头像 3"}
{"index":{"_id":"4"}}
{"user_id" : "USER186ade83-4460d4a6-8c08068f-83127b5d","nickname" : "昵称 4","phone" : "手机号 4","description" : "签名 4","avatar_id" : "头像 4"}
{"index":{"_id":"5"}}
{"user_id" : "USER6f19d074-c33891cf-23bf5a83-57189a19","nickname" : "昵称 5","phone" : "手机号 5","description" : "签名 5","avatar_id" : "头像 5"}
{"index":{"_id":"6"}}
{"user_id" : "USER97605c64-9833ebb7-d0455353-35a59195","nickname" : "昵称 6","phone" : "手机号 6","description" : "签名 6","avatar_id" : "头像 6"}查看并搜索数据
cpp
GET /user/_doc/_search?pretty
{
"query" : { // query指定检索条件
"bool" : {
"must_not" : [
{
"terms" : {
"user_id.keyword" : [
"USER4b862aaa-2df8654a-7eb4bb65-e3507f66",
"USER14eeeaa5-442771b9-0262e455-e4663d1d",
"USER484a6734-03a124f0-996c169dd05c1869"
]
}
}
],
"should" : [
{
"match" : {
"user_id" : "昵称"
}
},
{
"match" : {
"nickname" : "昵称"
}
},
{
"match" : {
"phone" : "昵称"
}
}
]
}
}
}删除索引
cpp
DELETE /userⅣ. ES 客户端接口介绍与使用
cpp
/**
* @brief 在指定的索引和文档类型中索引(创建或更新)一个文档。
*
* @param indexName 要索引文档的索引名称。
* @param docType 要索引文档的文档类型。
* @param id 要索引的文档的ID。如果为空,则es自动生成一个ID。
* @param body 包含文档内容的JSON格式的请求体。
* @param routing 可选的 routing 参数,用于指定文档的路由值。
* @return cpr::Response 返回一个包含操作结果的HTTP响应对象。
*/
cpr::Response index(const std::string &indexName,
const std::string &docType,
const std::string &id,
const std::string &body,
const std::string &routing = std::string());
/**
* @brief 在指定的索引和文档类型中执行搜索操作。
*
* @param indexName 要搜索的索引名称。
* @param docType 要搜索的文档类型。
* @param body 包含搜索查询的JSON格式的请求体。
* @param routing 可选的 routing 参数,用于指定文档的路由值。
* @return cpr::Response 返回一个包含搜索结果的HTTP响应对象。
*/
cpr::Response search(const std::string &indexName,
const std::string &docType,
const std::string &body,
const std::string &routing = std::string());
/**
* @brief 从指定的索引和文档类型中获取指定ID的文档。
*
* @param indexName 要获取文档的索引名称。
* @param docType 要获取文档的文档类型。
* @param id 要获取的文档的ID。如果为空,则返回所有文档。
* @param routing 可选的 routing 参数,用于指定文档的路由值。
* @return cpr::Response 返回一个包含文档内容的HTTP响应对象。
*/
cpr::Response get(const std::string &indexName,
const std::string &docType,
const std::string &id = std::string(),
const std::string &routing = std::string());
/**
* @brief 从指定的索引和文档类型中删除指定ID的文档。
*
* @param indexName 要删除文档的索引名称。
* @param docType 要删除文档的文档类型。
* @param id 要删除的文档的ID。
* @param routing 可选的 routing 参数,用于指定文档的路由值。
* @return cpr::Response 返回一个包含删除操作结果的HTTP响应对象。
*/
cpr::Response remove(const std::string &indexName,
const std::string &docType,
const std::string &id,
const std::string &routing = std::string()); 下面我们编写一个入门样例:
cpp
#include <elasticlient/client.h>
#include <cpr/cpr.h>
#include <iostream>
int main()
{
// 1. 构造ES客户端
elasticlient::Client client({"http://127.0.0.1:9200/"}); // 注意最后有一个/不要漏!
// 2. 发起搜索请求(需要捕获异常)
try {
auto rsp = client.search("user", "_doc", "{\"query\": { \"match_all\":{} }}");
std::cout << rsp.status_code << std::endl;
std::cout << rsp.text << std::endl;
} catch(std::exception &e) {
std::cout << "请求失败:" << e.what() << std::endl;
return -1;
}
return 0;
} makefile 文件如下所示,注意链接动态库:-lcpr 与 -lelasticlient。
makefile
main : main.cc
g++ -std=c++17 $^ -o $@ -lcpr -lelasticlientⅤ. ES 客户端二次封装
封装客户端 api 主要是因为客户端只提供了基础的数据存储获取调用功能,无法根据我们的需要完成索引的构建,以及查询正文的构建,需要使用者自己组织好 json 进行序列化后才能作为正文进行接口的调用。
而封装的目的就是简化用户的操作,将索引的 json 正文构造,以及查询搜索的正文构造操作给封装起来,使用者调用接口添加字段就行,不用关心具体的 json 数据格式!
整个封装的过程其实就是对 Json::Value 对象的一个组织的过程,并无太大的难点。封装内容如下所示:
- 构造索引过程的封装 :
- 索引正文构造过程,大部分正文都是固定的,唯一不同的地方是各个字段不同的名称以及是否只存储不索引这些选项,因此重点关注以下几个点即可:
- 字段类型
type:text/keyword - 是否索引
enable:true/false - 索引的话分词器类型
analyzer:ik_max_word/standard
- 字段类型
- 索引正文构造过程,大部分正文都是固定的,唯一不同的地方是各个字段不同的名称以及是否只存储不索引这些选项,因此重点关注以下几个点即可:
- 新增文档构造过程的封装 :
- 新增文档其实在常规下都是单条新增,并非批量新增,因此直接添加字段和值就行
- 文档搜索构造过程的封装 :
- 搜索正文构造过程,我们默认使用条件搜索,我们主要关注的两个点:
- 应该遵循的条件是什么:
should中有什么 - 条件的匹配方式是什么:
match是term/terms,还是wildcard - 过滤的条件字段是什么:
must_not中有什么 - 过滤的条件字段匹配方式是什么:
match还是wildcard,还是term/terms
- 应该遵循的条件是什么:
- 搜索正文构造过程,我们默认使用条件搜索,我们主要关注的两个点:
cpp
#pragma once
#include <elasticlient/client.h>
#include <cpr/cpr.h>
#include <json/json.h>
#include <iostream>
#include <sstream>
#include <memory>
#include "logger.hpp"
/**
* @brief 将 Json::Value 对象序列化为字符串。
* @param val 需要序列化的 Json::Value 对象。
* @param dst 输出参数,存储序列化后的字符串。
* @return 如果序列化成功返回 true,否则返回 false。
*/
bool Serialize(const Json::Value &val, std::string &dst)
{
// 定义 Json::StreamWriter 工厂类 Json::StreamWriterBuilder
Json::StreamWriterBuilder swb;
std::unique_ptr<Json::StreamWriter> sw(swb.newStreamWriter());
// 通过 Json::StreamWriter 中的 write 接口进行序列化
std::stringstream ss;
int ret = sw->write(val, &ss);
if (ret != 0) {
LOG_ERROR("Json 序列化失败!");
return false;
}
dst = ss.str();
return true;
}
/**
* @brief 将字符串反序列化为 Json::Value 对象。
* @param src 需要反序列化的字符串。
* @param val 输出参数,存储反序列化后的 Json::Value 对象。
* @return 如果反序列化成功返回 true,否则返回 false。
*/
bool UnSerialize(const std::string &src, Json::Value &val)
{
Json::CharReaderBuilder crb;
std::unique_ptr<Json::CharReader> cr(crb.newCharReader());
std::string err;
bool ret = cr->parse(src.c_str(), src.c_str() + src.size(), &val, &err);
if (ret == false) {
LOG_ERROR("Json 序列化失败:{}", err);
return false;
}
return true;
}
/**
* @brief ESIndex 类用于创建和管理 Elasticsearch 索引。
*/
class ESIndex
{
public:
/**
* @brief 构造函数,初始化索引名称、类型和 Elasticsearch 客户端。
* @param client Elasticsearch 客户端对象的共享指针。
* @param name 索引名称。
* @param type 索引类型,默认为 "_doc"。
*/
ESIndex(std::shared_ptr<elasticlient::Client> &client,
const std::string &name,
const std::string &type = "_doc")
: _name(name)
, _type(type)
, _client(client)
{
// 初始化索引的 settings 部分,配置分词器
Json::Value analysis;
Json::Value analyzer;
Json::Value ik;
Json::Value tokenizer;
tokenizer["tokenizer"] = "ik_max_word"; // 使用 ik_max_word 分词器
ik["ik"] = tokenizer;
analyzer["analyzer"] = ik;
analysis["analysis"] = analyzer;
_index["settings"] = analysis; // 将分词器配置添加到索引 settings 中
}
/**
* @brief 向索引中添加字段。
* @param key 字段名称。
* @param type 字段类型,默认为 "text"。
* @param analyzer 分词器,默认为 "ik_max_word"。
* @param enabled 是否启用字段,默认为 true。
* @return 返回当前对象的引用,支持链式调用。
*/
ESIndex& append(const std::string &key,
const std::string &type = "text",
const std::string &analyzer = "ik_max_word",
bool enabled = true)
{
Json::Value fields;
fields["type"] = type; // 设置字段类型
fields["analyzer"] = analyzer; // 设置分词器
if (enabled == false)
fields["enabled"] = enabled; // 设置字段是否启用
_properties[key] = fields; // 将字段添加到 properties 中
return *this;
}
/**
* @brief 创建 Elasticsearch 索引。
* @param index_id 索引的 ID,默认为 "default_index_id"。
* @return 如果索引创建成功返回 true,否则返回 false。
*/
bool create(const std::string &index_id = "default_index_id")
{
// 将 mappings 部分添加到索引配置中
Json::Value mappings;
mappings["dynamic"] = true; // 允许动态映射
mappings["properties"] = _properties; // 添加字段属性
_index["mappings"] = mappings;
// 将索引配置序列化为字符串
std::string body;
bool ret = Serialize(_index, body);
if (ret == false) {
LOG_ERROR("索引序列化失败!");
return false;
}
// LOG_DEBUG("{}", body);
// 发起创建索引请求
try {
auto rsp = _client->index(_name, _type, index_id, body);
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("创建 ES 索引 {} 失败,响应状态码异常: {}", _name, rsp.status_code);
return false;
}
} catch(std::exception &e) {
LOG_ERROR("创建 ES 索引 {} 失败: {}", _name, e.what());
return false;
}
return true;
}
private:
std::string _name; // 索引名称
std::string _type; // 索引类型
Json::Value _properties; // 索引字段属性
Json::Value _index; // 索引配置
std::shared_ptr<elasticlient::Client> _client; // Elasticsearch 客户端
};
// ESInsert类用于将数据插入到 Elasticsearch 中
class ESInsert
{
public:
// 构造函数,初始化 Elasticsearch 客户端、索引名称、类型(默认为 "_doc")
ESInsert(std::shared_ptr<elasticlient::Client> &client,
const std::string &name,
const std::string &type = "_doc")
: _name(name)
, _type(type)
, _client(client)
{}
// 模板函数,用于向待插入的 JSON 数据中追加键值对
template<typename T>
ESInsert &append(const std::string &key, const T &val)
{
_item[key] = val; // 将键值对插入到内部的 JSON 对象 _item 中
return *this; // 返回当前对象的引用,支持链式调用
}
// 插入数据到 Elasticsearch 中,返回是否成功
bool insert(const std::string id = "")
{
std::string body; // 保存序列化后的 JSON 字符串
bool ret = Serialize(_item, body); // 序列化 _item 为 JSON 格式的字符串
if (ret == false) {
LOG_ERROR("索引序列化失败!");
return false;
}
// LOG_DEBUG("{}", body);
// 发起插入请求
try {
// 使用客户端发起索引请求,将数据插入到指定的索引中
auto rsp = _client->index(_name, _type, id, body);
if (rsp.status_code < 200 || rsp.status_code >= 300) { // 如果响应状态码不在成功范围内
LOG_ERROR("新增数据 {} 失败,响应状态码异常: {}", body, rsp.status_code);
return false;
}
} catch(std::exception &e) {
LOG_ERROR("新增数据 {} 失败: {}", body, e.what());
return false;
}
return true;
}
private:
std::string _name; // 索引名称
std::string _type; // 索引类型
Json::Value _item; // 待插入的数据,存储为 JSON 对象
std::shared_ptr<elasticlient::Client> _client; // Elasticsearch 客户端
};
class ESRemove {
public:
ESRemove(std::shared_ptr<elasticlient::Client> &client,
const std::string &name,
const std::string &type = "_doc")
: _name(name)
, _type(type)
, _client(client)
{}
bool remove(const std::string &id) {
try {
auto rsp = _client->remove(_name, _type, id);
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("删除数据 {} 失败,响应状态码异常: {}", id, rsp.status_code);
return false;
}
} catch(std::exception &e) {
LOG_ERROR("删除数据 {} 失败: {}", id, e.what());
return false;
}
return true;
}
private:
std::string _name;
std::string _type;
std::shared_ptr<elasticlient::Client> _client;
};
class ESSearch
{
public:
// 构造函数,初始化搜索类所需的基本参数,包括客户端、索引名称和类型
ESSearch(std::shared_ptr<elasticlient::Client> &client,
const std::string &name,
const std::string &type = "_doc")
: _name(name)
, _type(type)
, _client(client)
{}
// 添加一个"must_not"条件,意味着这些条件的字段值不能匹配
ESSearch& append_must_not_terms(const std::string &key, const std::vector<std::string> &vals) {
Json::Value fields;
// 将所有的条件值添加到对应的字段
for (const auto& val : vals) {
fields[key].append(val);
}
Json::Value terms;
terms["terms"] = fields; // 构建terms查询条件
_must_not.append(terms); // 将条件添加到must_not数组中
return *this; // 返回当前对象,支持链式调用
}
// 添加一个"should"条件,表示这些条件值是"推荐匹配"项(即加分项)
ESSearch& append_should_match(const std::string &key, const std::string &val) {
Json::Value field;
field[key] = val; // 设置匹配条件的字段和值
Json::Value match;
match["match"] = field; // 构建match查询条件
_should.append(match); // 将条件添加到should数组中
return *this; // 返回当前对象,支持链式调用
}
// 添加一个"must"条件,表示这些条件值是"必须匹配"项
ESSearch& append_must_term(const std::string &key, const std::string &val) {
Json::Value field;
field[key] = val; // 设置匹配条件的字段和值
Json::Value term;
term["term"] = field; // 构建term查询条件
_must.append(term); // 将条件添加到must数组中
return *this; // 返回当前对象,支持链式调用
}
// 添加一个"must"条件(match类型),表示这些条件值是"必须匹配"项
ESSearch& append_must_match(const std::string &key, const std::string &val){
Json::Value field;
field[key] = val; // 设置匹配条件的字段和值
Json::Value match;
match["match"] = field; // 构建match查询条件
_must.append(match); // 将条件添加到must数组中
return *this; // 返回当前对象,以支持链式调用
}
// 发起实际的搜索请求,并返回结果
Json::Value search(){
// 搭建搜索请求的正文框架
Json::Value cond;
if (_must_not.empty() == false) cond["must_not"] = _must_not; // 如果有must_not条件,添加到查询中
if (_should.empty() == false) cond["should"] = _should; // 如果有should条件,添加到查询中
if (_must.empty() == false) cond["must"] = _must; // 如果有must条件,添加到查询中
Json::Value query;
query["bool"] = cond; // 将上述条件组成一个bool查询
Json::Value root;
root["query"] = query; // 将查询条件放入query中
// 序列化查询条件为字符串
std::string body;
bool ret = Serialize(root, body);
if (ret == false) {
LOG_ERROR("索引序列化失败!");
return Json::Value();
}
// LOG_DEBUG("{}", body);
// 发起搜索请求
cpr::Response rsp;
try {
rsp = _client->search(_name, _type, body); // 使用Elasticsearch客户端发起搜索
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("检索数据 {} 失败,响应状态码异常: {}", body, rsp.status_code);
return Json::Value();
}
} catch(std::exception &e) {
LOG_ERROR("检索数据 {} 失败: {}", body, e.what());
return Json::Value();
}
// 需要对响应正文进行反序列化
// LOG_DEBUG("检索响应正文: [{}]", rsp.text); // 可选,调试时可以打印响应的正文
Json::Value json_res;
ret = UnSerialize(rsp.text, json_res);
if (ret == false) {
LOG_ERROR("检索数据 {} 结果反序列化失败", rsp.text);
return Json::Value();
}
return json_res["hits"]["hits"]; // 返回命中的结果部分
}
private:
std::string _name; // 索引名称
std::string _type; // 文档类型
Json::Value _must_not; // 存放"must_not"条件的数组
Json::Value _should; // 存放"should"条件的数组
Json::Value _must; // 存放"must"条件的数组
std::shared_ptr<elasticlient::Client> _client; // Elasticsearch客户端
};测试代码
下面的测试代码就是进行索引创建、插入数据等操作:
cpp
// main.cc
#include "../../header/elastic.hpp"
#include <gflags/gflags.h>
DEFINE_bool(run_mode, false, "程序的运行模式,false-调试; true-发布;");
DEFINE_string(log_file, "", "发布模式下,用于指定日志的输出文件");
DEFINE_int32(log_level, 0, "发布模式下,用于指定日志输出等级");
int main(int argc, char *argv[])
{
google::ParseCommandLineFlags(&argc, &argv, true);
init_logger(FLAGS_run_mode, FLAGS_log_file, FLAGS_log_level);
// 完成index创建
std::vector<std::string> host_list = {"http://127.0.0.1:9200/"};
auto client = std::make_shared<elasticlient::Client>(host_list);
bool ret = ESIndex(client, "test_user").append("nickname")
.append("phone", "keyword", "standard", true)
.create();
if (ret == false) {
LOG_INFO("索引创建失败!");
return -1;
}
else
LOG_INFO("索引创建成功!");
// 数据的新增
ret = ESInsert(client, "test_user")
.append("nickname", "张三")
.append("phone", "15566667777")
.insert("00001");
if (ret == false) {
LOG_ERROR("数据插入失败!");
return -1;
}else
LOG_INFO("数据新增成功!");
// 数据的修改
ret = ESInsert(client, "test_user")
.append("nickname", "张三")
.append("phone", "13344445555")
.insert("00001");
if (ret == false) {
LOG_ERROR("数据更新失败!");
return -1;
}else
LOG_INFO("数据更新成功!");
std::this_thread::sleep_for(std::chrono::seconds(2)); // 在每次插入或更新数据之后增加一些延迟
Json::Value user = ESSearch(client, "test_user")
.append_should_match("phone.keyword", "13344445555")
//.append_must_not_terms("nickname.keyword", {"张三"})
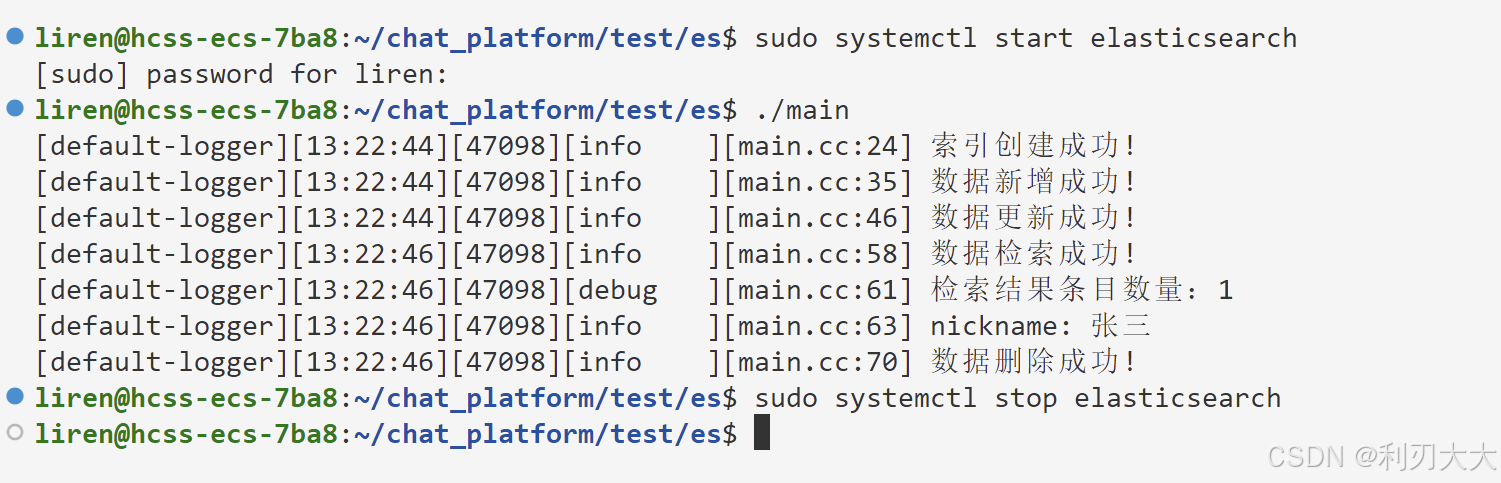
.search();
if (user.empty() || user.isArray() == false) {
LOG_ERROR("结果为空,或者结果不是数组类型");
return -1;
} else
LOG_INFO("数据检索成功!");
int sz = user.size();
LOG_DEBUG("检索结果条目数量:{}", sz);
for (int i = 0; i < sz; i++)
LOG_INFO("nickname: {}", user[i]["_source"]["nickname"].asString());
ret = ESRemove(client, "test_user").remove("00001");
if (ret == false) {
LOG_ERROR("删除数据失败");
return -1;
} else
LOG_INFO("数据删除成功!");
return 0;
} makefile 文件:
makefile
main : main.cc
g++ -std=c++17 $^ -o $@ -lcpr -lelasticlient -lspdlog -lfmt -lgflags -ljsoncpp