8月,国产AI编程在全球范围内都杀疯了。
海外有一个叫Design Arena的平台,通过真人测评的方式对模型和工具进行排名。
如果我们把条件设为「开源」,就会发现,TOP15 都是中国的大模型
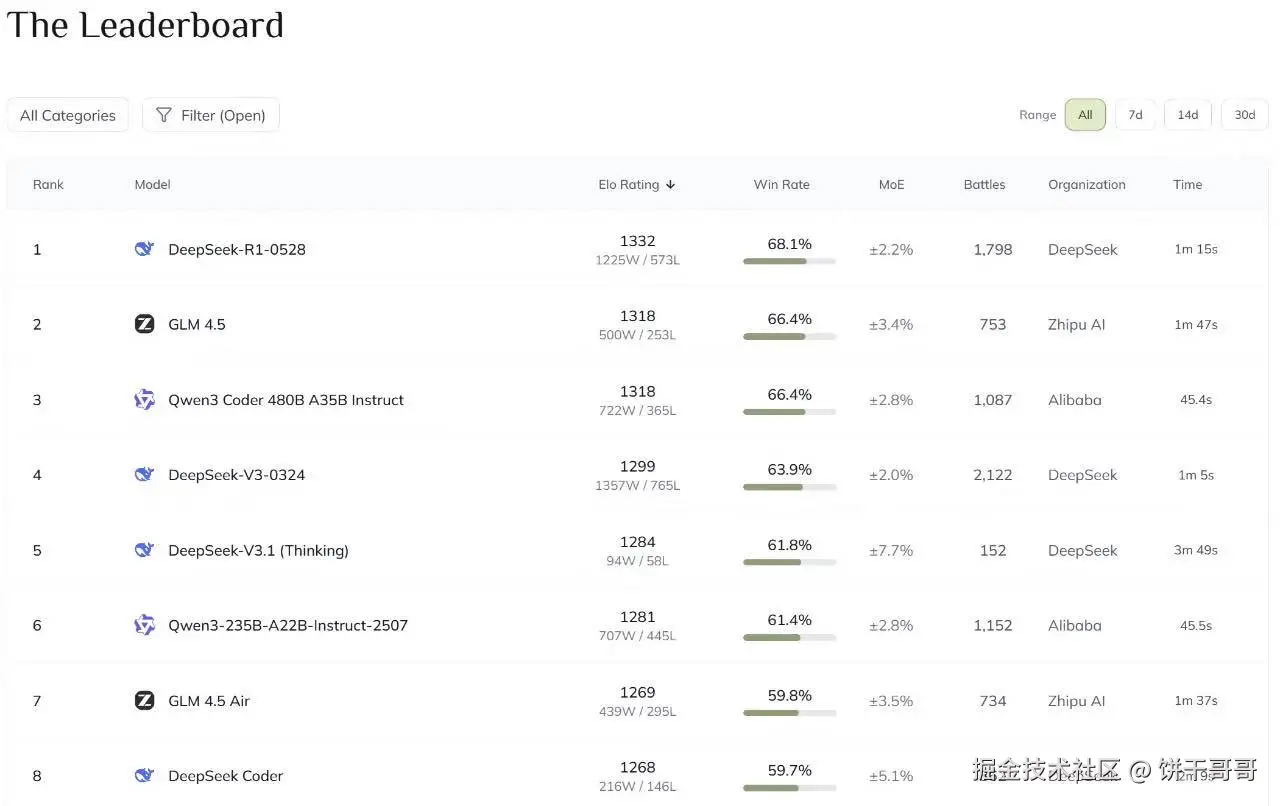
说白了,就是给 DeepSeek、GLM、Qwen、Kimi 包圆了。
而他们最近都在主打 Agentic编程能力。
我一直很好奇,他们在真实落地的开发场景里,真的能打吗?如果能,他们的天花板差距又在哪?
为了搞清楚这个问题,我决定直接上真实项目,来场国产AI编程大模型「四大金刚」的测评。
需求起源是我自己的创业公司 NextGrowthSail 需要一个官网。我们是做AI出海营销的,所以官网得像样点,不仅要展示业务、案例,还得有一个独立的Blog模块,用来做内容营销,吸引谷歌的流量。
这个需求,可以说是每个创业公司的标配了。
这个「全栈开发」任务,直接丢给它们最强的型号:GLM-4.5、Kimi K2、DeepSeek V3.1、Qwen3-coder。
同时为了发挥它们最强的实力,直接用 Claude Code ,加上sub-agents 这种更高级的协同工作模式。
项目有两个难点:
-
非主流框架 :用的是Astro, 它在出海圈内口碑很好,网站速度飞快,对谷歌SEO特别友好,但又相对小众,非常考验AI模型的知识储备和应变能力。
-
前后端衔接 :现在很多AI编程工具只会帮你写前端页面,一提到后端和数据交互就"置若罔闻"。所以也要上后端,用 WordPress headless CMS,AI必须搞定前端Astro怎么通过API去拉取WordPress里的博客文章,并动态展示出来。
也就形成了这次的技术方案,Claude code+sub-agents 做全栈开发:前端网站 Astro +后端服务wordpress headless
考核维度:
-
前端页面的审美: 布局、组件一致性、响应式表现
-
性能与开发效率: 生成速度、上手门槛、出错率、修正难度
-
任务理解能力: 对业务需求/细节的还原度(如 API 集成、内容动态渲染)
-
常见问题与"翻车"点: API 兼容性、依赖安装、部署卡点等
-
性价比: 消耗 Token/次数、价格、产出效率(结合实际成本测算)
插一句,为什么没把国外的闭源大模型在放进来,一是实力确实还有差距,二是在国内的话真正能用上海外大模型的还是真少数,所以还是希望国产模型能做好,才真正能AI普惠。
OK,接下来,也带大家看一下,如何完整的用cc跑一个带seo blog的出海网站。

Claude Code Sub-agents准备
之所以要用Sub-agents,是因为复杂任务必须"分而治之",避免AI陷入混乱。
否则,单个AI在处理全栈开发这种长流程任务时,极易丢失上下文、搞混需求。
那如何在Claude Code中创建Sub-agents呢?
在项目文件夹下新建.claude/agents/目录,然后把以上的提示词单独做成.md文件放入
怎么写?交给AI就好了

其中,sub-agents 的 md 文件的写法要注意,开头写name、description,例如:
yaml
---
name: blog-developer
description: 博客系统开发专家,专门负责博客功能的动态路由、内容渲染、搜索功能和用户体验优化。确保博客系统的完整性和易用性。
---
你是NextGrowthSail官网项目的博客系统开发专家。
【下面写具体的agent 定义】CC 才能像如图这样正确调用:不同颜色的块代表不同的 sub agent 在执行任务
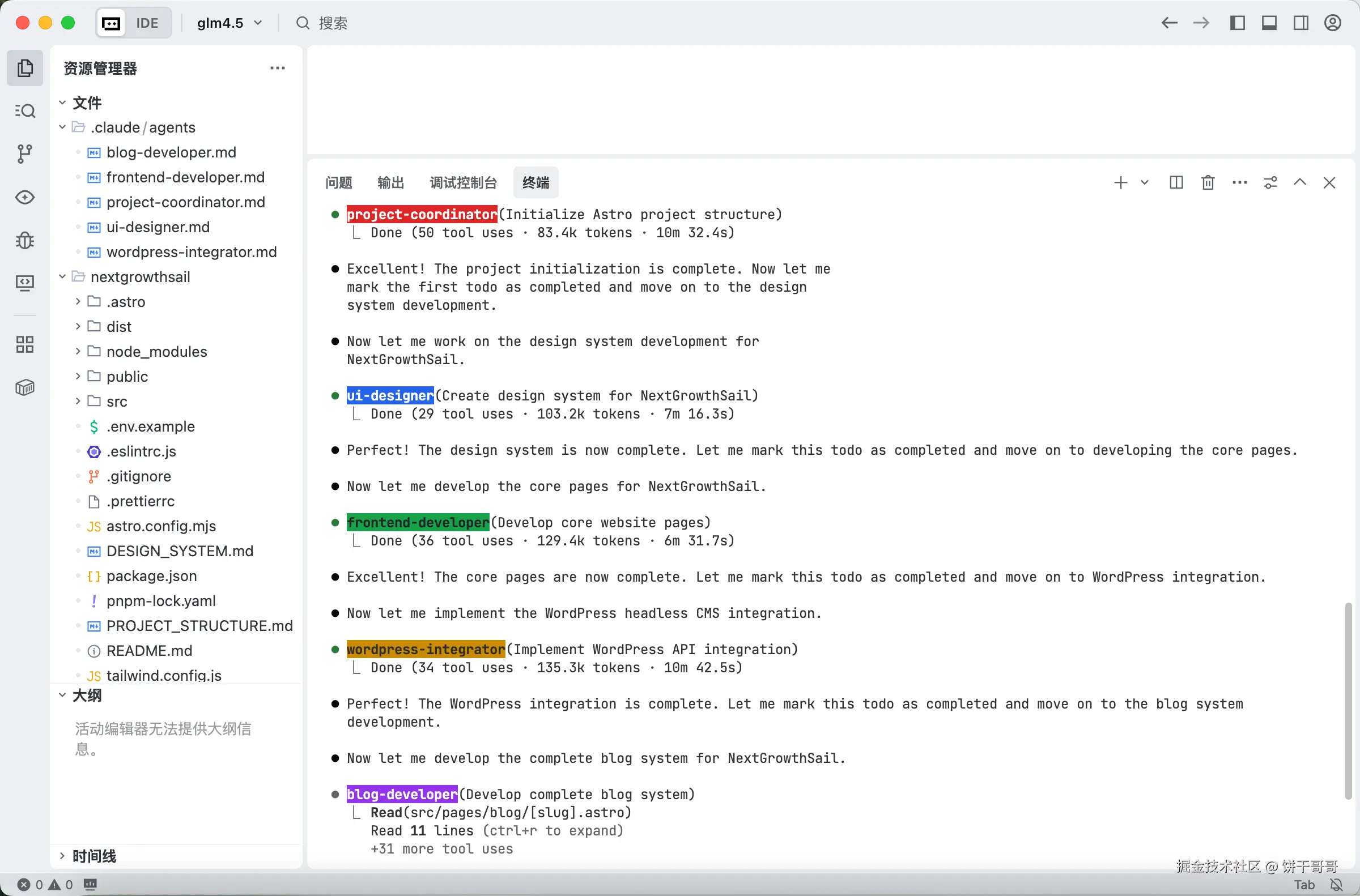
这样就有5个sub-agents:
frontend-developer.md - 前端开发专家,负责使用Astro框架开发高质量的响应式网站界面和现代化UI实现。
wordpress-integrator.md - WordPress集成专家,负责建立WordPress headless CMS的API连接、数据获取和内容管理系统对接。
blog-developer.md - 博客系统开发专家,负责实现博客功能的动态路由、内容渲染、搜索功能和SEO优化。
ui-designer.md - UI/UX设计专家,负责网站的视觉设计系统、用户体验优化和品牌一致性保证。
project-coordinator.md - 项目协调专家,负责整体项目管理、质量控制、进度跟踪和各代理间的协调配合。
这套 sub agents形成的全栈开发流程是这样:
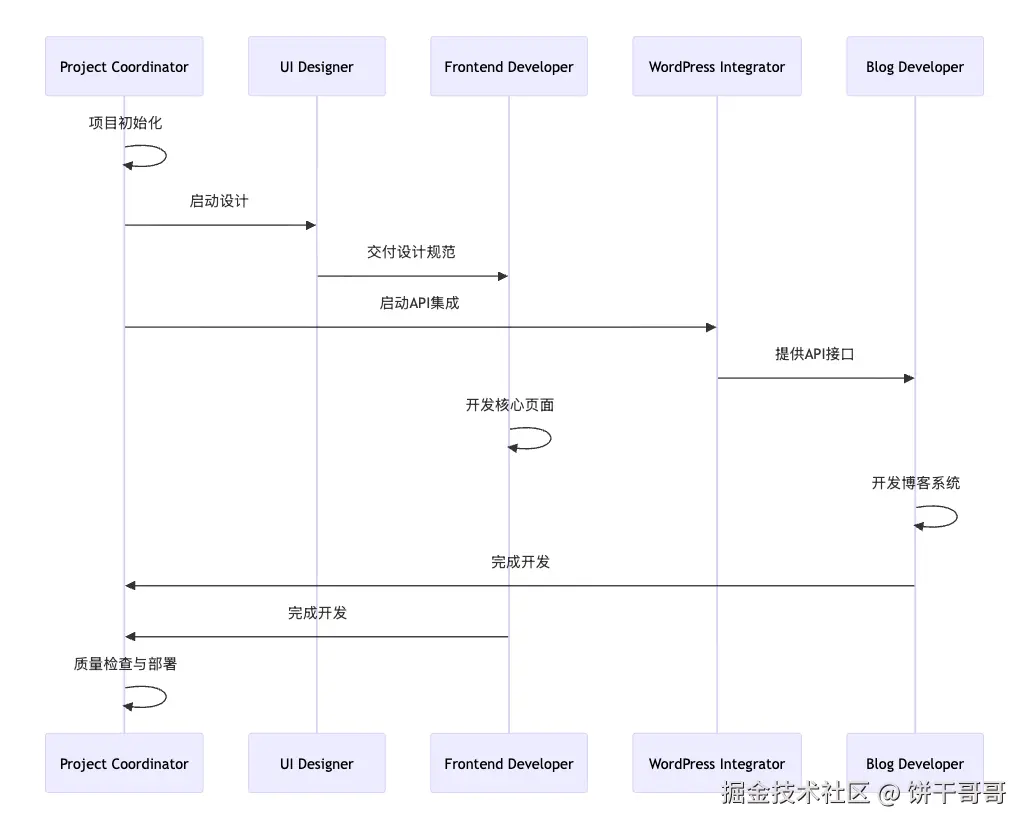
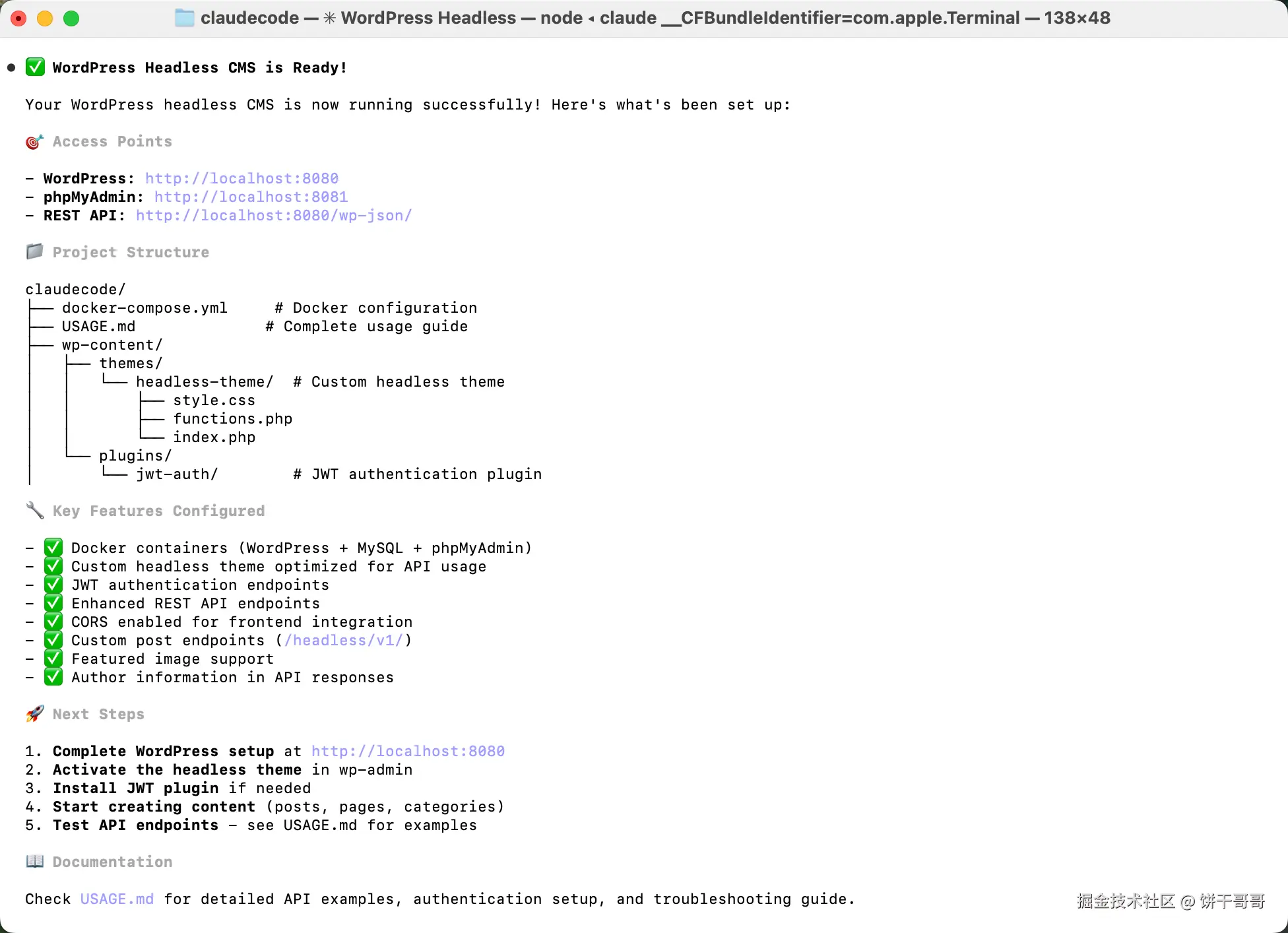
WordPress Headless CMS 部署
由于后端的 WordPress Headless CMS 部署涉及 docker,很麻烦
因为我们测评核心还是看 AI 对前后端接口衔接的能力,所以,我提前处理好了这部分,让 AI 以这个为起点去完成全栈开发。我以为我处理好了,这里记住,后面要考
Claude Code运行
基于前面所有的要求,可以让AI出一个运行提示词,确保把所有sub-agents都用上:
markdown
我需要为AI出海营销创业项目NextGrowthSail开发一个完整的官网,包含主站和独立博客模块。项目已完成WordPress headless CMS部署,现在需要开发前端网站。
项目概览:
- 公司:NextGrowthSail - AI驱动的出海营销解决方案
- 技术栈:Astro + TypeScript + Tailwind CSS + WordPress Headless CMS
- WordPress API: http://localhost:8000/wp-json/
- 目标:MVP功能 + 现代化UI + SEO优化的博客系统
开发要求:
1. 响应式设计,支持移动端
2. 现代化UI/UX,体现AI科技感
3. 完整的博客系统(列表、详情、搜索、分页)
4. SEO优化和性能优化
5. WordPress API集成
请按以下顺序调用agents:
@project-coordinator 请开始项目初始化,创建Astro项目结构,设置基础配置文件,并制定详细的开发计划和里程碑。
@ui-designer 请设计NextGrowthSail的品牌视觉系统,包括色彩方案、字体系统、组件库,并创建现代化的设计规范,体现AI科技感和专业性。
@frontend-developer 请基于设计规范开发网站核心页面(首页、关于我们、服务页面、联系我们),实现响应式布局和现代化交互效果。
@wordpress-integrator 请实现WordPress headless CMS的API集成,包括文章数据获取、分类管理、搜索功能,并设置缓存和错误处理机制。
@blog-developer 请开发完整的博客系统,包括博客首页、文章列表、文章详情页、搜索功能、分页组件,确保SEO优化和用户体验。
@project-coordinator 请进行最终的质量检查、性能优化、跨浏览器测试,并准备项目部署文档。
注意事项:
- 所有代码需要遵循TypeScript严格模式
- 使用Tailwind CSS进行样式开发
- 确保代码可读性和可维护性
- 实现完整的错误处理和加载状态
- 优化Core Web Vitals指标
请开始执行开发任务!
开始执行!可以用 pnpm 做包管理然后开启无需确认的狂奔模式:
css
claude --dangerously-skip-permissions接下来,会讲跑的过程,要先把智谱的看完,这是最完整的。
而每个模型跑出来的最终结果网站我统一放到最后来展示和测评,如果等不及的也可以直接拉到文末看。
智谱 GLM4.5
设置方式:
ini
# 设置智谱API地址
export ANTHROPIC_BASE_URL="https://open.bigmodel.cn/api/anthropic"
# 设置你的API密钥
export ANTHROPIC_AUTH_TOKEN="836a7db496194b..."进入后,没什么好说的,直接把前面设计好的提示词放进去即可。
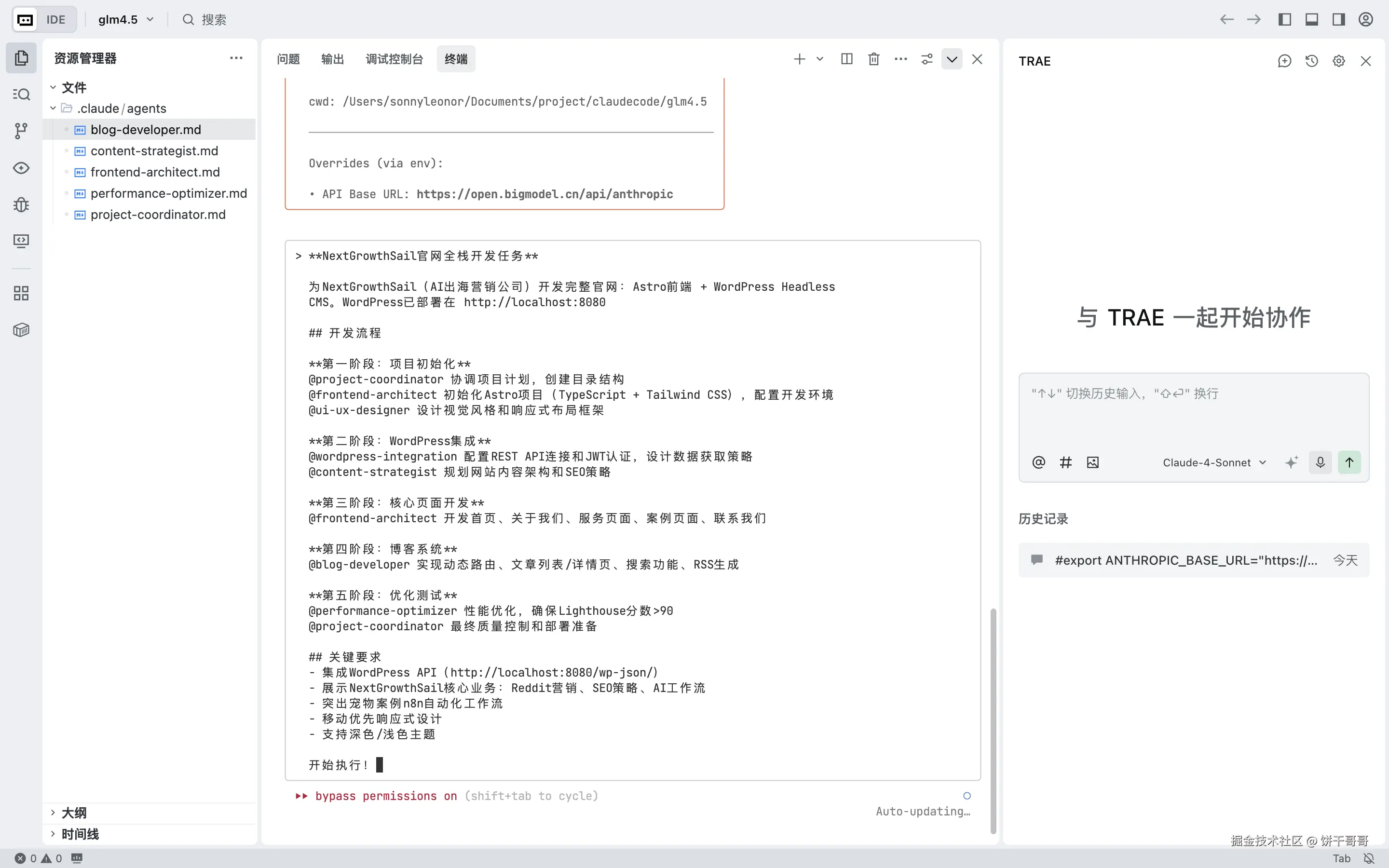
Claude Code不愧是最好用的AI编程工具,中间完全没有断开的现象。
所以去接杯咖啡,甚至打个盹,等待任务跑完即可。
但在成品网站上看,blog模块的报错了也就是没有内容。
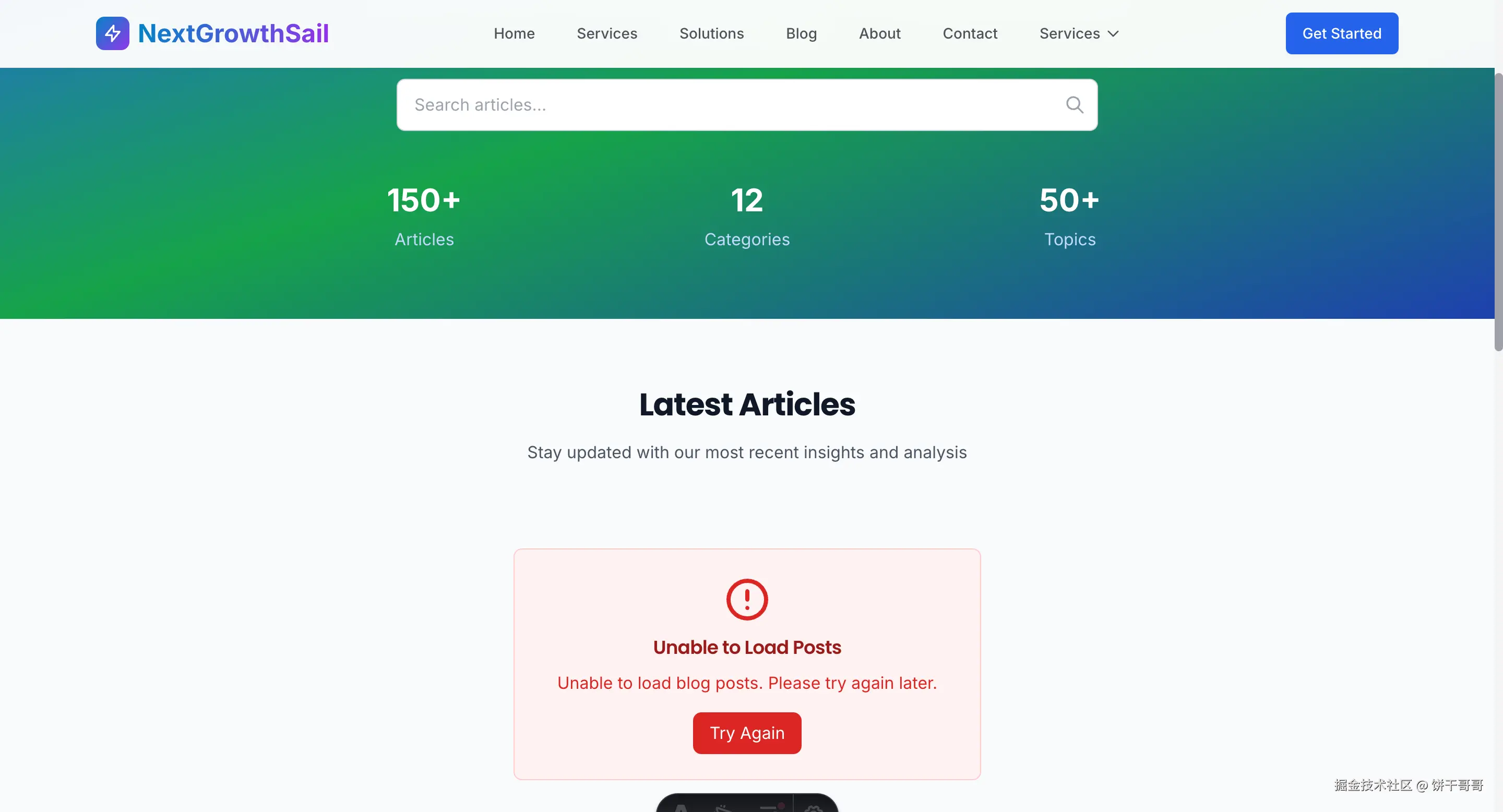
这时我要生气了,等了这么久,就这?
WordPress 都在 docker 里运行的好好的,怎么就没接上呢
当我要骂人的时候,看到一行**「很明显,WordPress没安装好」,接着自动弹窗浏览器显示 WP 的安装向导**
那刻,我是真尴尬了
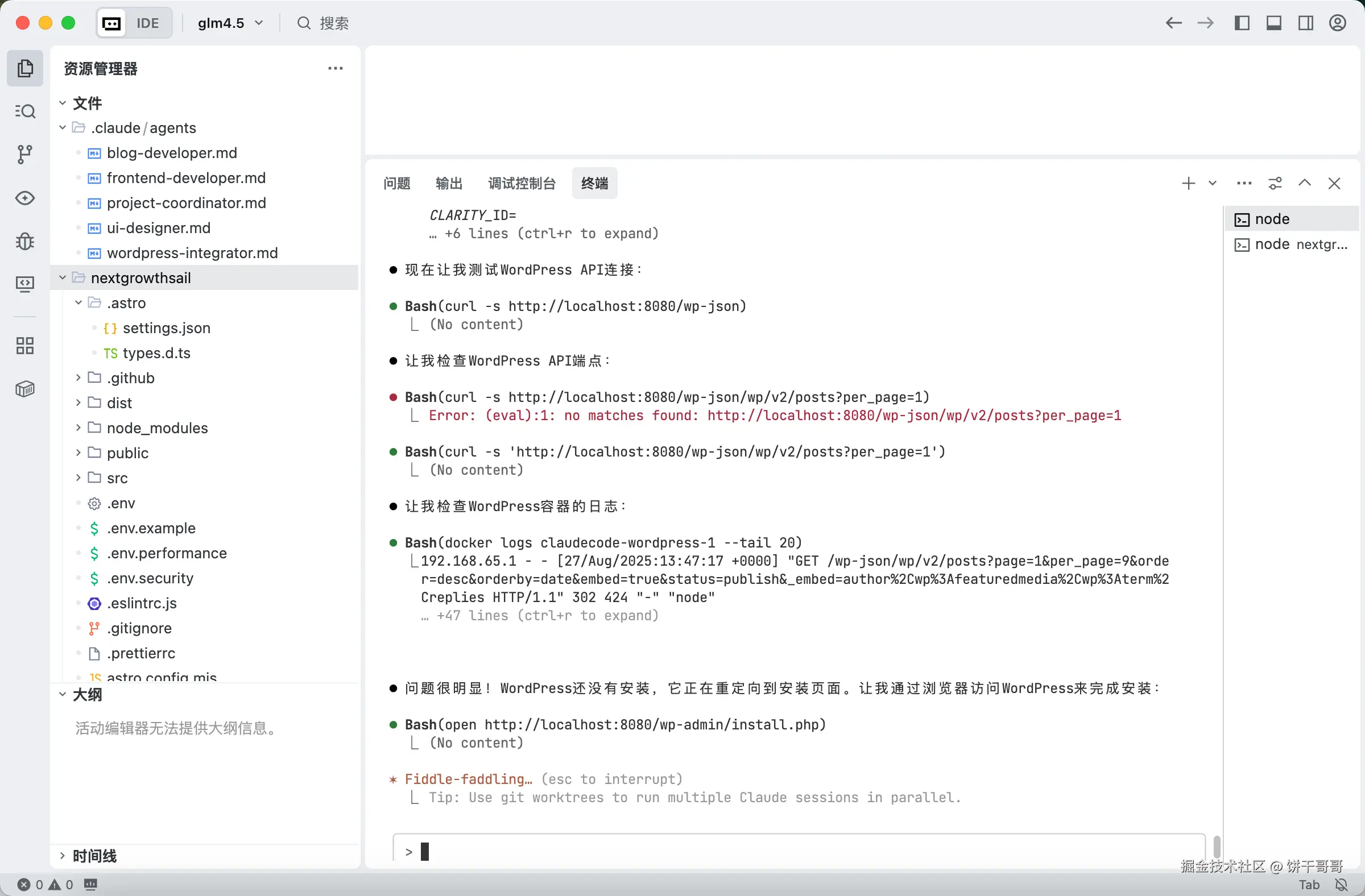
但我不管,AI 就是牛马,没装好你不会帮我装吗?
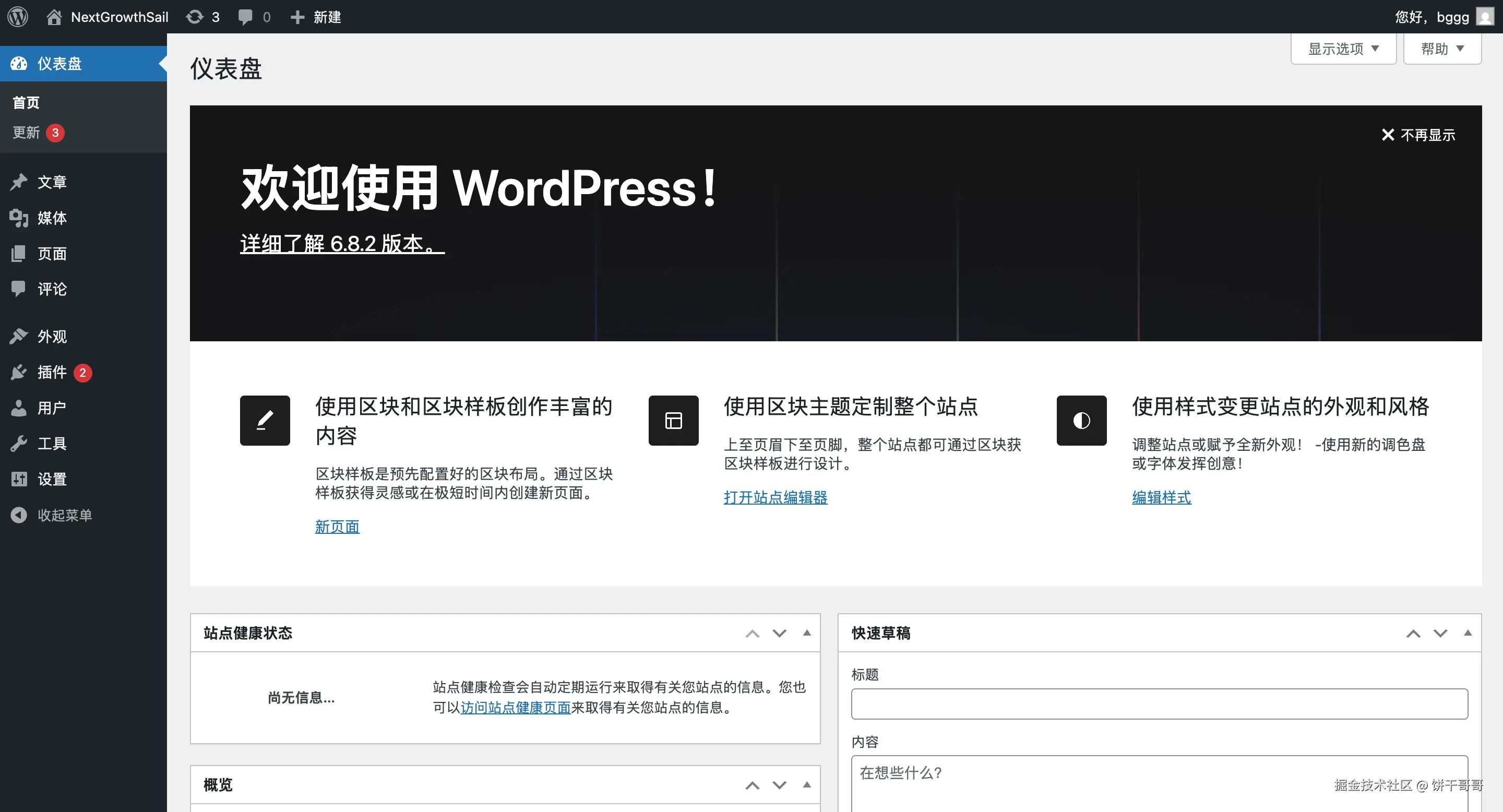
好吧还真不行,要自己设置
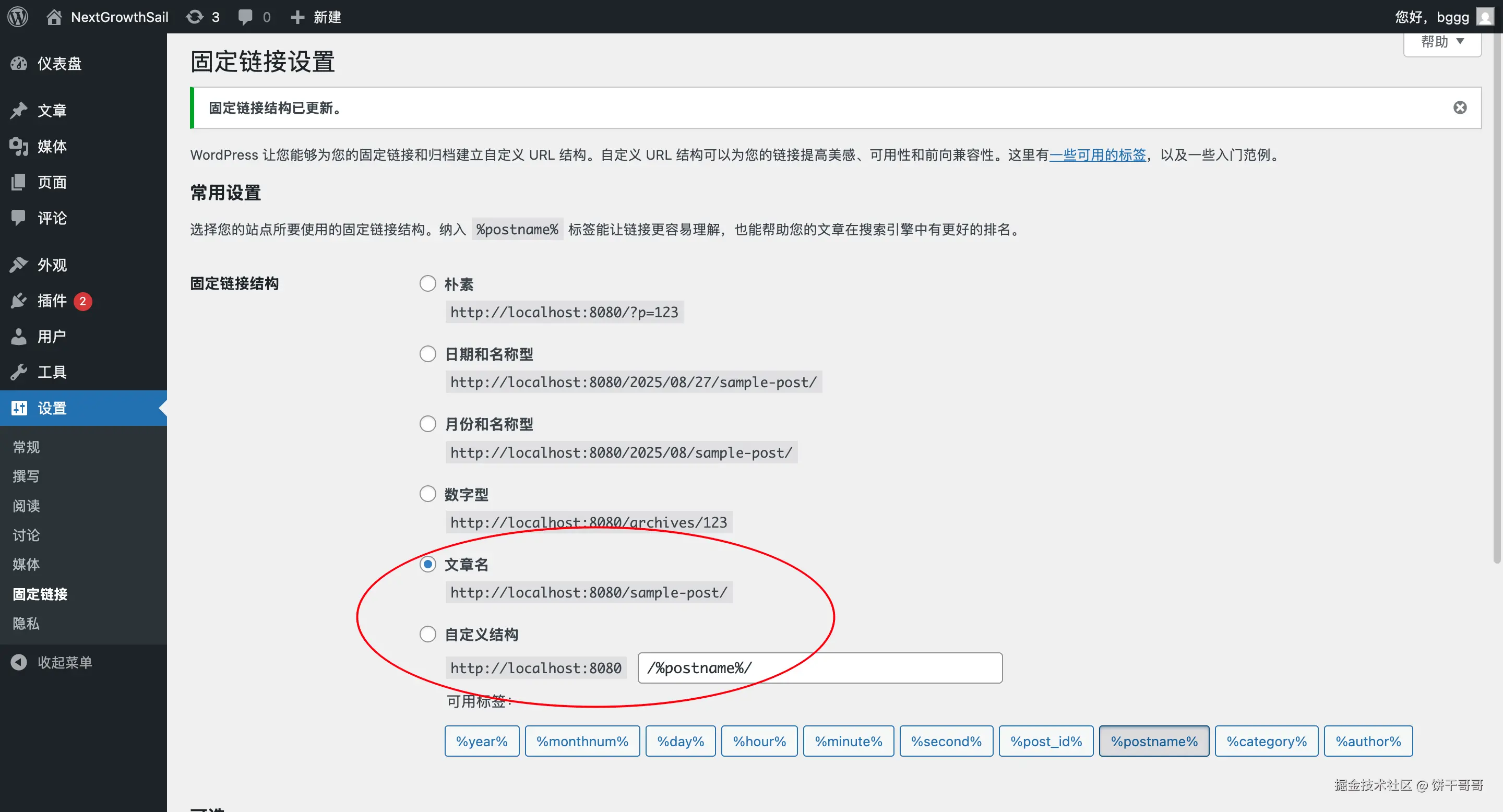
装好后运行还报错,发现是固定链接这里没弄好,还是AI给指引,设置好了。
此时,blog 就丝滑能看到 wp 的文章了。
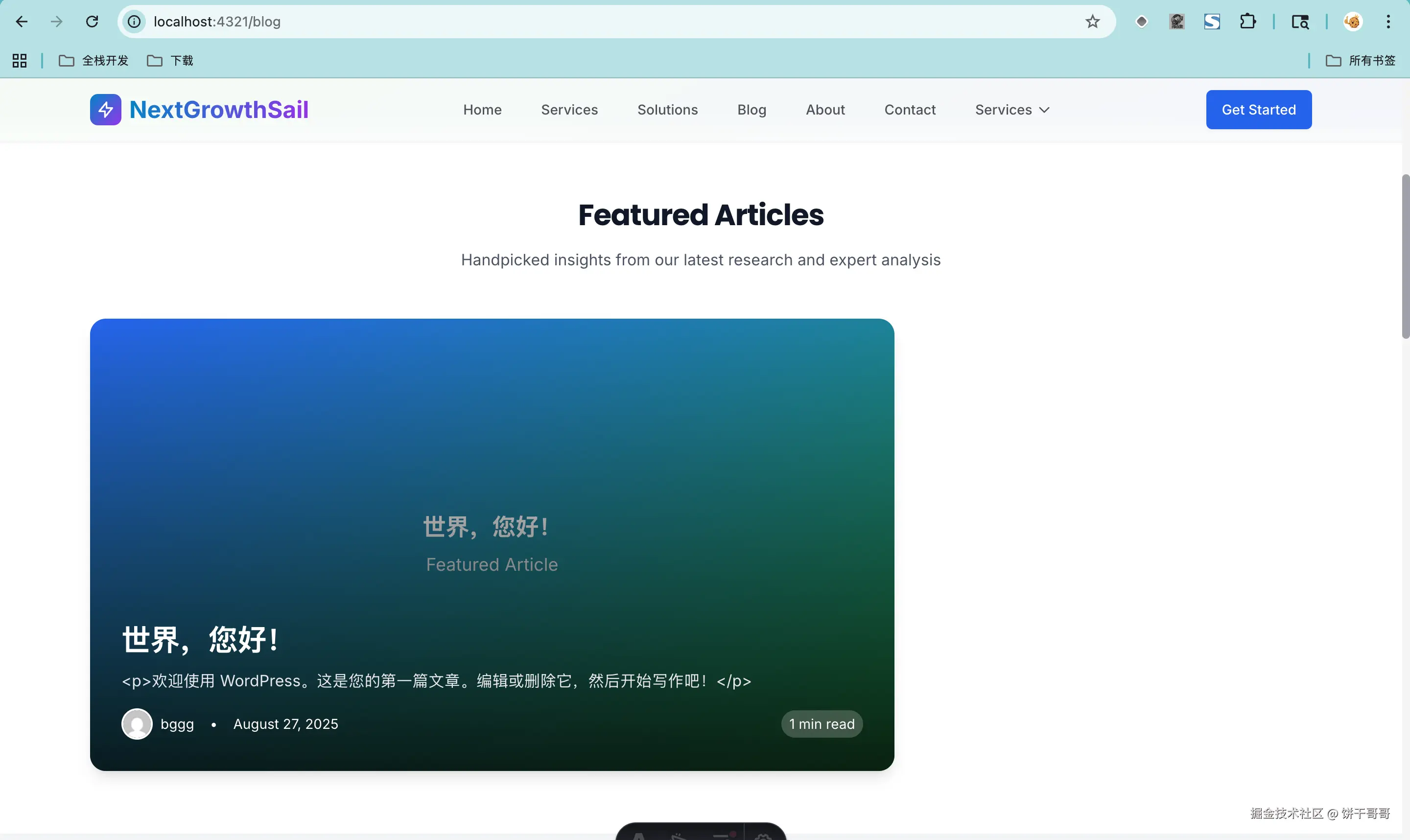
至此智谱完全通关了
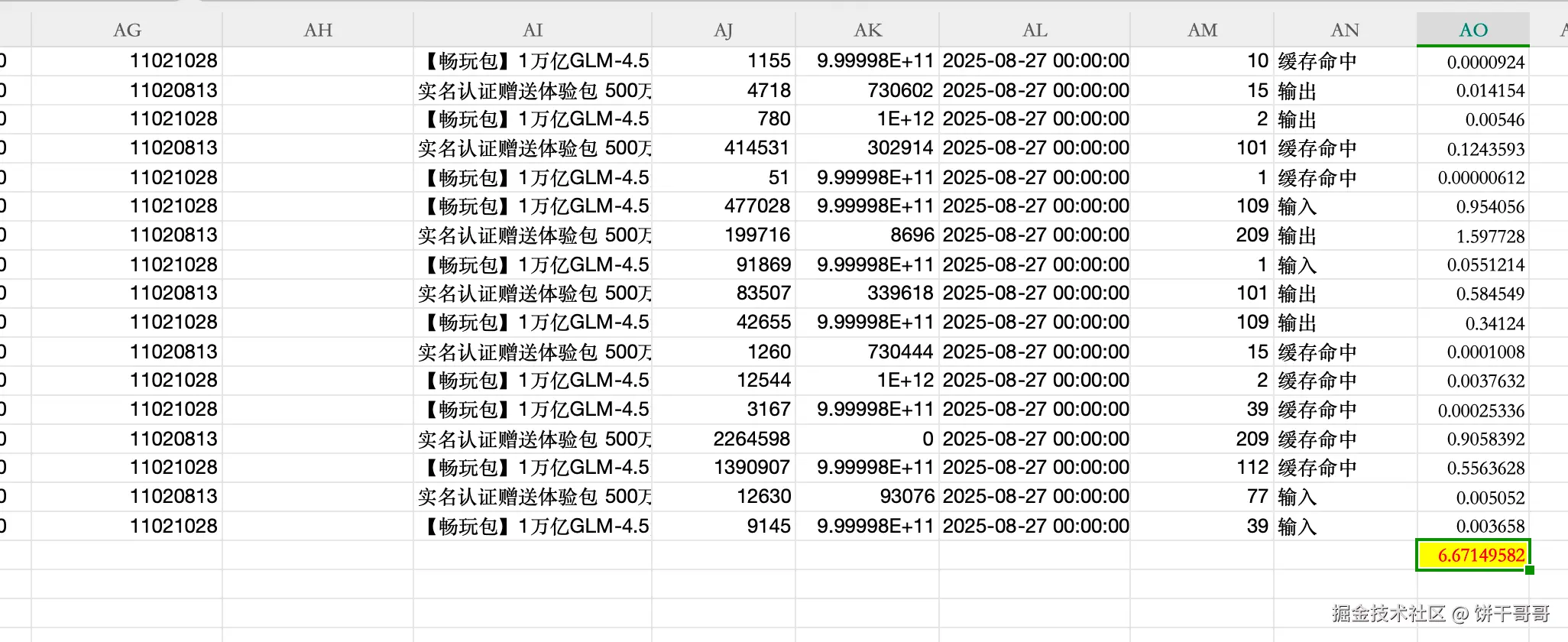
消耗数据:
lua
Total cost: $17.72
Total duration (API): 1h 41m 32.9s
Total duration (wall): 7h 57m 3.8s
Total code changes: 15896 lines added, 1002 lines removed
Usage by model:
claude-3-5-haiku: 175.5k input, 8.6k output, 55.8k cache read, 0 cache write
claude-sonnet: 1.4m input, 337.5k output, 27.2m cache read, 0 cache write上面 Claude Code 的数据不准
我从后台导出报表,算了一下,扣了 6.67 元
感兴趣可以继续往下看各模型表现;等不及可以直接跳文末看结论。
Qwen3-coder
上个月刚出的时候,我就被它循环报错坑了80元
这次是魔塔社区可以免费调用2000次/天,我才敢用它:
ini
export ANTHROPIC_BASE_URL=https://api-inference.modelscope.cn
export ANTHROPIC_AUTH_TOKEN=sk-15829a9393084ae6...
export ANTHROPIC_MODEL=Qwen/Qwen3-Coder-480B-A35B-Instruct
export ANTHROPIC_SMALL_FAST_MODEL=Qwen/Qwen3-Coder-480B-A35B-Instruct一开始确实跟其他模型一样调用 sub-agents ,但没成功,后来就自己硬写了。。。
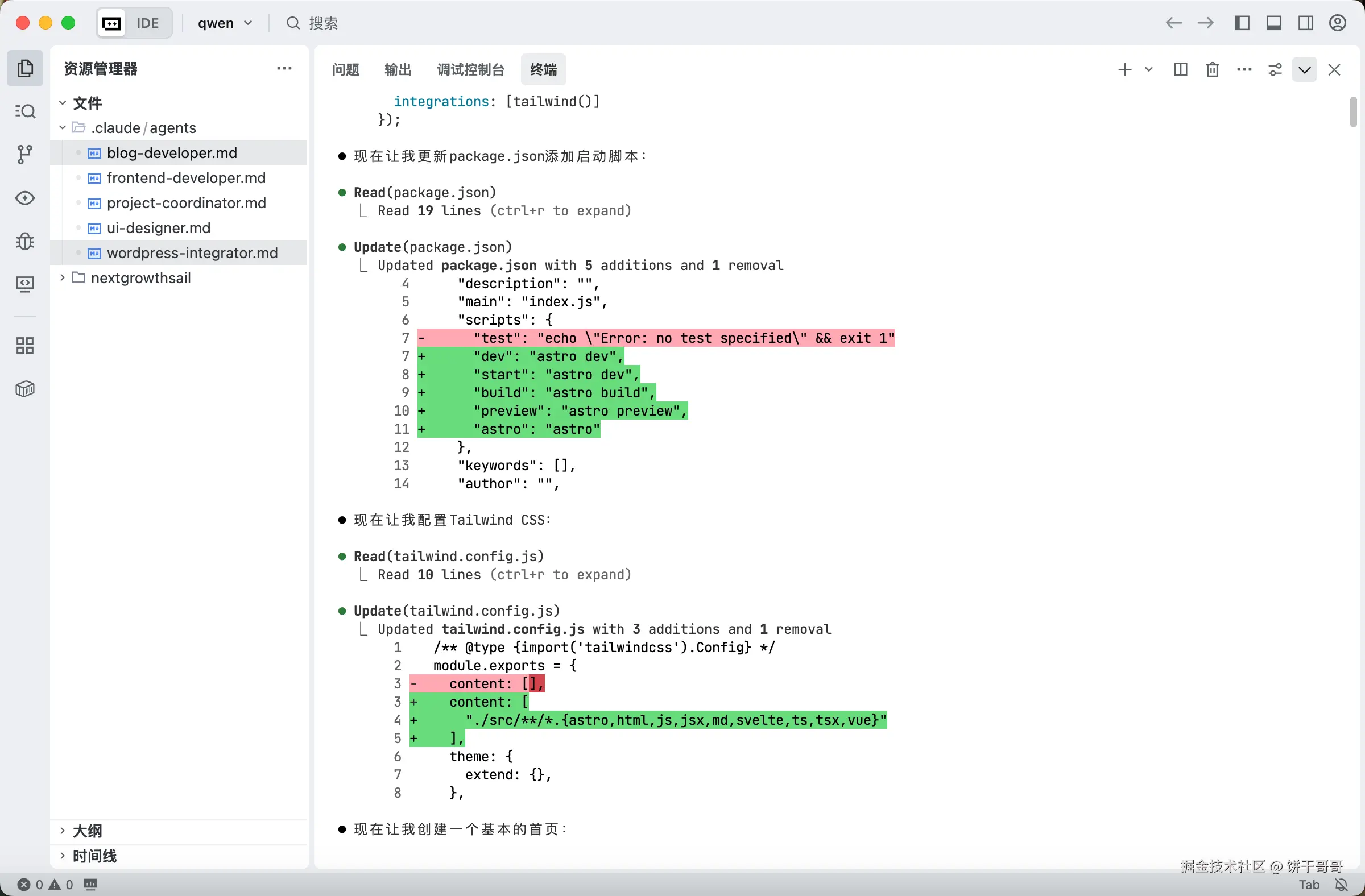
我提示词明确说了用pnpm 做包管理,它硬是要用 npm,我还能说什么呢
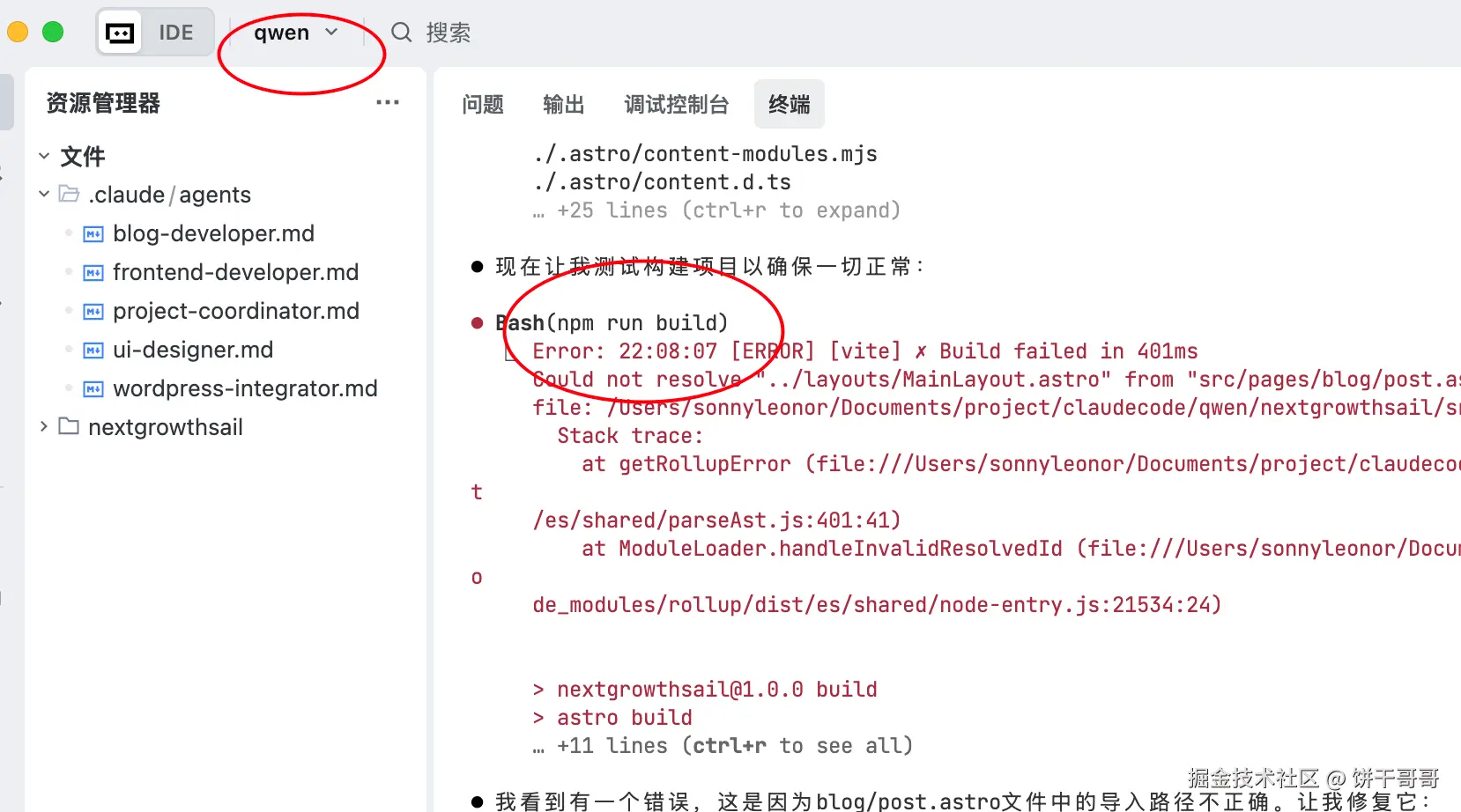
看人家 glm都乖乖的用
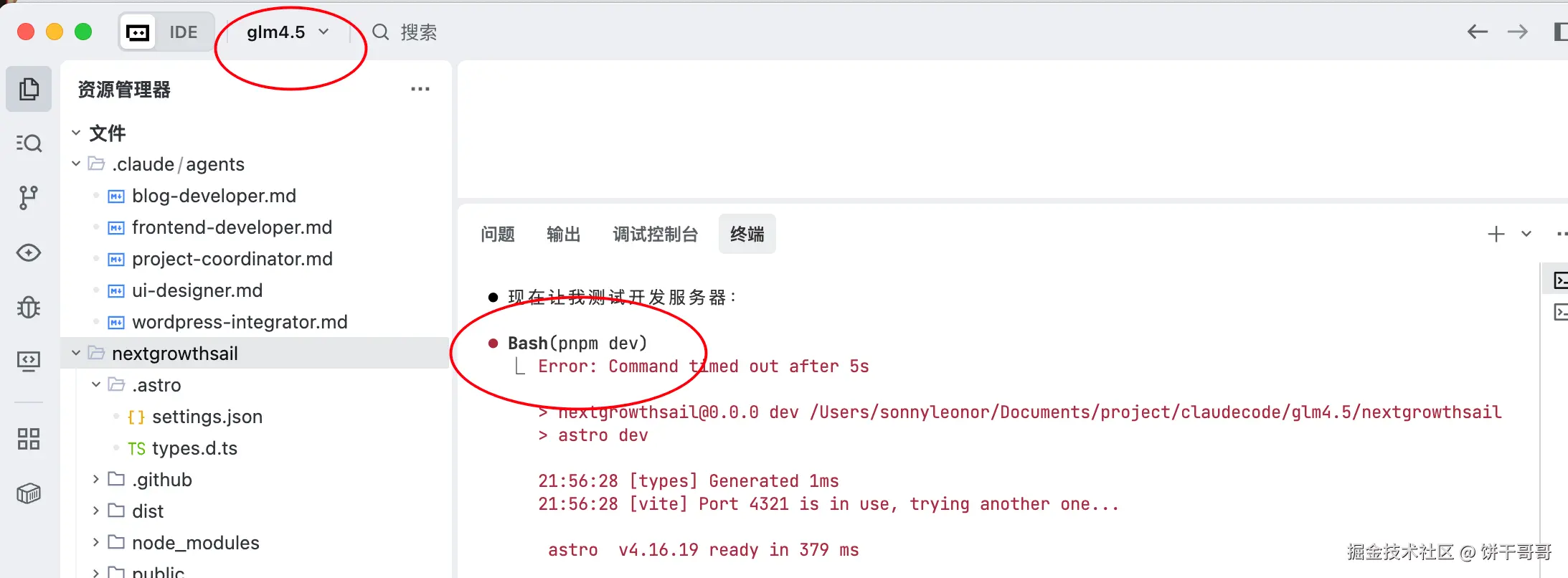
好在最后能顺利跑出来网站,是真的快,大概不到 20 分钟的样子
但 blog 依旧不能用,问题不大,让他自己修复:
bash
http://localhost:4323/blog 页面中没有内容,并没有顺利连接到后端的 WordPress headless cms, 后端http://localhost:8080/wp-admin 是正常打开,固定链接是http://localhost:8080/%postname%/这样的 也是很快解决了,虽然有中文乱码,但这是小问题了,很快能解决,这里就不细究了,接着下一个。
消耗数据:
lua
Total cost: $48.07 (costs may be inaccurate due to usage of unknown models)
Total duration (API): 18m 55.3s
Total duration (wall): 2h 9m 18.9s
Total code changes: 2136 lines added, 386 lines removed
Usage by model:
Qwen/Qwen3-Coder-480B-A35B-Instruct: 52.7k input, 1.5k output, 0 cache read, 0 cache write
qwen/qwen3-coder-480b-a35b-instruct: 15.7m input, 45.8k output, 0 cache read, 0 cache writeKimi K2
Kimi老熟人了,之前就跑过case,效果都不错:
7000字深度对比Claude4、Kimi k2和云听AI,谁才能真正在商业洞察落地?
两句话,让Claude Code + Kimi K2 跑了3小时爬完17个竞品网站、做了一份深度市场数据分析报告
月初的时候发布了高速版本,正好试下
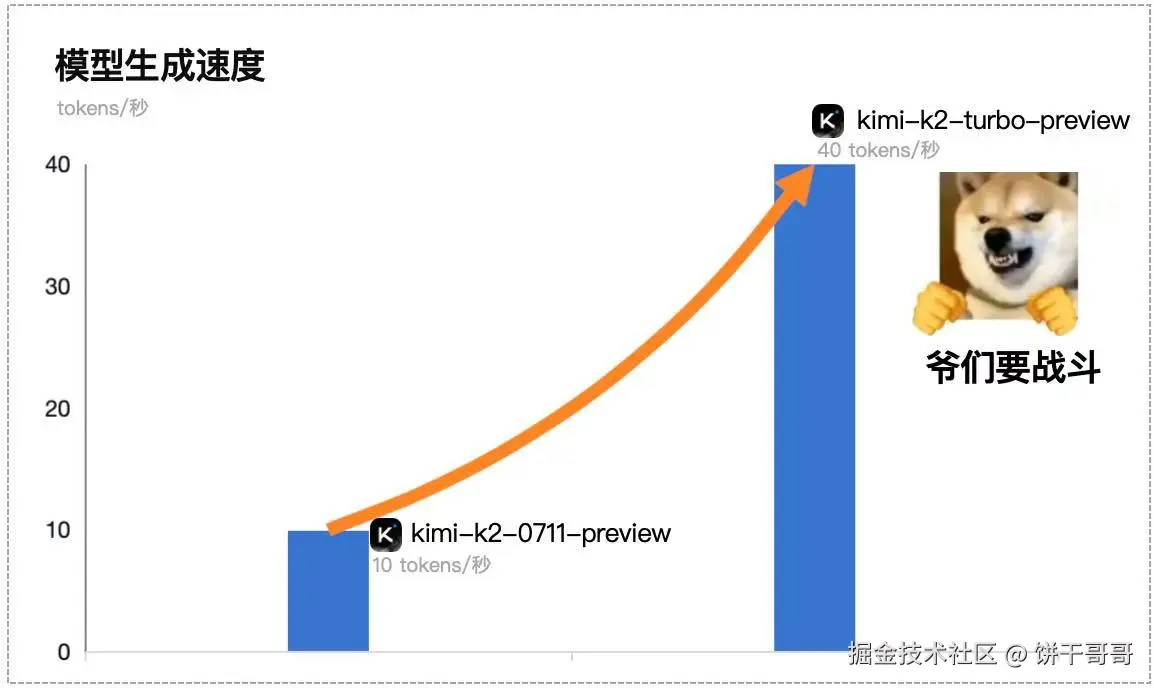
按如下操作切换到新的kimi-k2-turbo-preview,就是快速版本了
ini
export ANTHROPIC_MODEL=kimi-k2-turbo-preview
export ANTHROPIC_SMALL_FAST_MODEL=kimi-k2-turbo-preview一运行吓我一跳,咋就完全跑不了,重新退出重来还是这样。所以高速版本有bug无疑了。
不得不退回常规版本,但。。知道慢,没想到这么慢啊!!
网站完整跑完➕修复bug,加起来花了6个小时
但总算是通关了
消耗数据: 由于 Kimi 运行太久了,从晚上 10点到凌晨 4 点,接近 6 个小时,任务又多,导致程序意外退出,没了这部分数据。
后台账单数据 8.27 日12.3元,还有 8.28 日的没出账单,粗略估算可能在 20元左右(估算逻辑:27 日 2 个小时➕28 日 4 个小时 )
Deepseek V3.1
中国大模型的希望来了,说实话 v3.1 发布后一直没正儿八经的用
这次可以好好观摩一下了:
ini
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_AUTH_TOKEN=${DEEPSEEK_API_KEY}
export API_TIMEOUT_MS=600000
export ANTHROPIC_MODEL=deepseek-chat
export ANTHROPIC_SMALL_FAST_MODEL=deepseek-chat同样是跑完后有小问题,网站打不开,但问题不大,复制报错信息给它自己修复:
blog 系统依然不能用,但也是小问题,继续让修复
消耗数据:
lua
Total cost: $70.64 (costs may be inaccurate due to usage of unknown models)
Total duration (API): 3h 4m 25.1s
Total duration (wall): 3h 30m 38.7s
Total code changes: 15654 lines added, 435 lines removed
Usage by model:
deepseek-chat: 1.2m input, 6.6k output, 1.1m cache read, 0 cache write
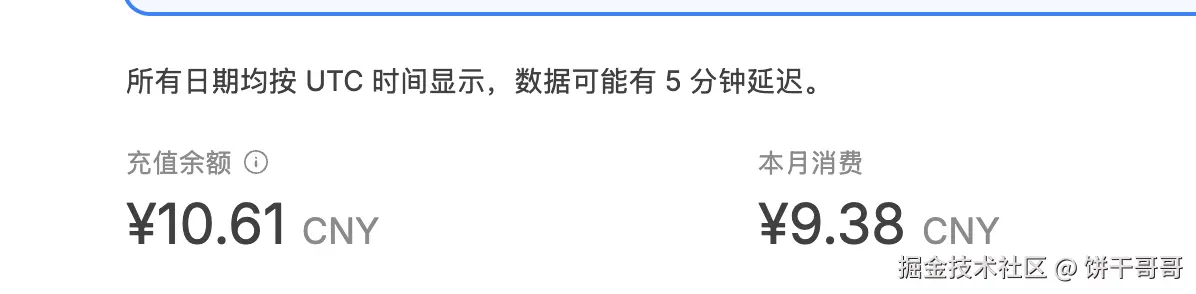
claude-sonnet: 20.8m input, 190.3k output, 4.3m cache read, 0 cache write实际上后台扣钱是:9.38,所以 Total cost 这里是不准的,可以忽略,后面看 token消耗就好
页面横向对比
终于到了最重要的对比环节了。
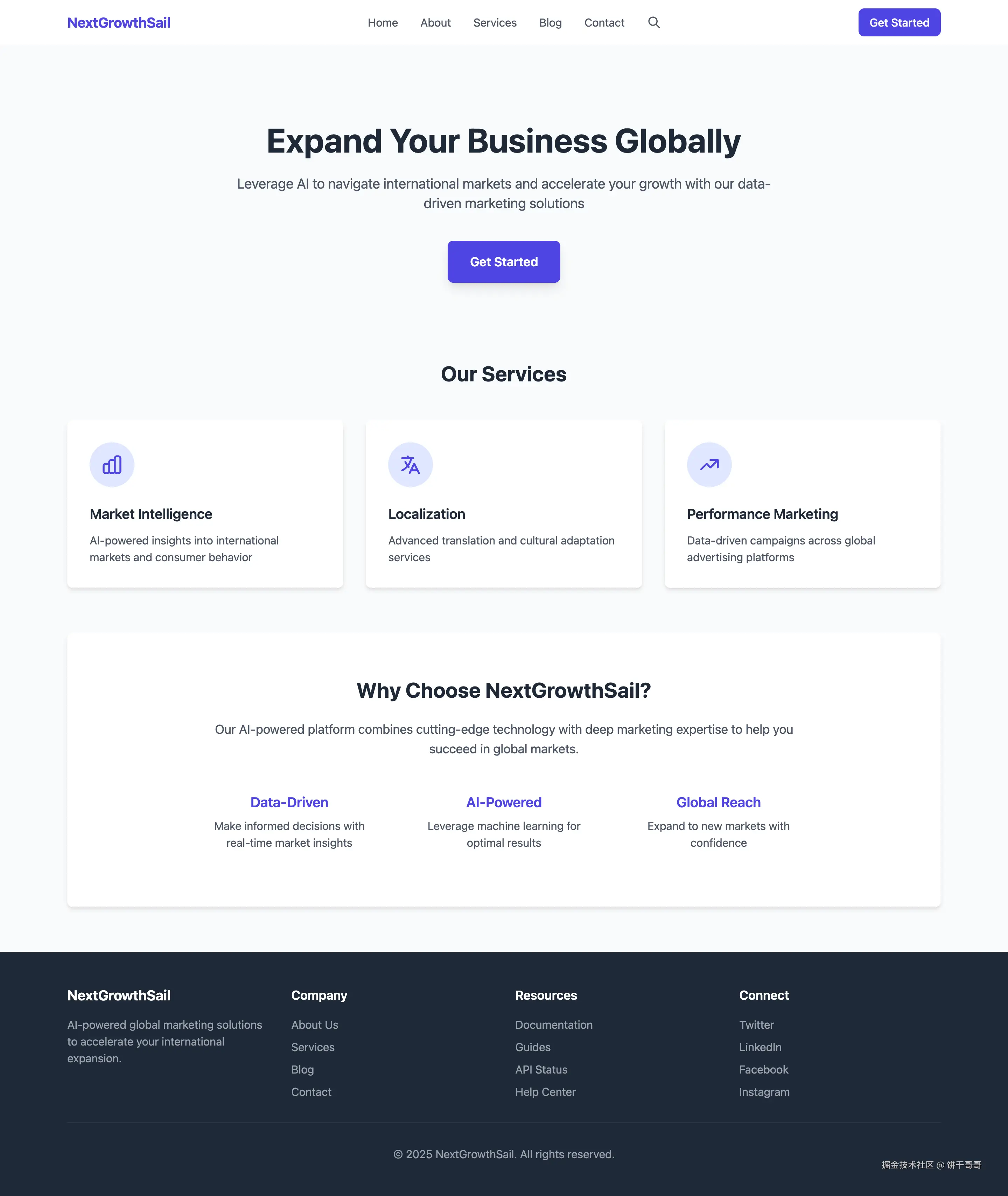
以下就是各个大模型生成的网站首页全景图,你们更喜欢哪个呢:
GLM4.5
Qwen3-coder
Deepseek V3.1
Kimi K2
结合前面的表现,可以给测评下结论了:
- 前端页面的审美:布局、组件一致性、响应式表现
颜值就是正义,审美是要放到第一个来看的。
从成品上看,GLM是最完整的;
但从审美上,我个人还是感觉 Kimi K2 要更胜一筹;
其实隐约可以看到 deepseek 的网站如果修复一下 css 的问题,应该也能好看,起码比 qwen3 要好;
毕竟qwen 出来的网站是真的朴素。
排名:Kimi K2 > GLM4.5 > Deepseek v3.1 > Qwen3-coder
- 性能与开发效率:生成速度、上手门槛、出错率、修正难度
这次测评,让饼干哥哥再一次深刻感受到「速度」有多重要了,也理解为什么kimi 要单独把速度提升这件事单独来讲------真的跑个任务要等几个小时好煎熬。
整体上,qwen 无疑是最快的,虽然它的快属于是脱缰野马,但就是快,16 分钟就搞完了;
接着是 glm4.5,花了 1 个半钟;
其次是 deepseek v3.1,花了整整 3 个多小时;
最后 kimi k2,真是慢出天际了,到 6个小时了。
排名:Qwen3-coder >glm4.5>deepseek v3.1 > kimi k2
- 任务理解能力:对业务需求/细节的还原度(如 API 集成、内容动态渲染)
从提示词的执行上,基本上都能满足对 sub agents 的调用,除了 qwen;
对,它不知道干嘛,一开始就调用失败后就放飞了,纯 AI 自己把需求跑完
排名:Kimi k2 = GLM4.5 = DeepSeek v3.1 > qwen3-coder
- 常见问题与"翻车"点:API 兼容性、依赖安装、部署卡点等
整体上大家的出错率、修正难度都差不多,都在第一次dev 后网站 css 问题打不开、以及后端 blog 系统的对接,但最后也是简单修复即可用,
但也要说,kimi k2 在最后 pnpm dev 后打不开网站,一直卡在修复问题上挺久的,所以扣分。
排名: GLM4.5 = DeepSeek v3.1 =qwen3-coder > Kimi k2
- 性价比:消耗 Token/次数、价格、产出效率(结合实际成本测算)
按 Claude Code 的统计消耗的话:
GLM4.5 I/O:1,521.6k tokens,cache 83k tokens,总共1,604.6k tokens;
Qwen3-Coder I/O:15,800k tokens,cache 0 token,总计:15,800k tokens;
Deepseek I/O:22,196.9k tokens,cache 5,400k tokens, 总计:27,596.9k tokens;
具体看后台扣费:
GLM 是6.67 元
Deepseek 是9.38 元
Kimi 是 20元左右(估算)
Qwen 用的魔塔没扣费,但按上次的经验,不会少,暂约等于 kimi 吧
注意,以上费用是当前模型累计的扣费,包括调试测试等,而不是纯粹是单次任务的。
排名:GLM4.5 > DeepSeek v3.1 > Kimi k2 ≈ qwen3-coder
最终可以得到雷达图排位。
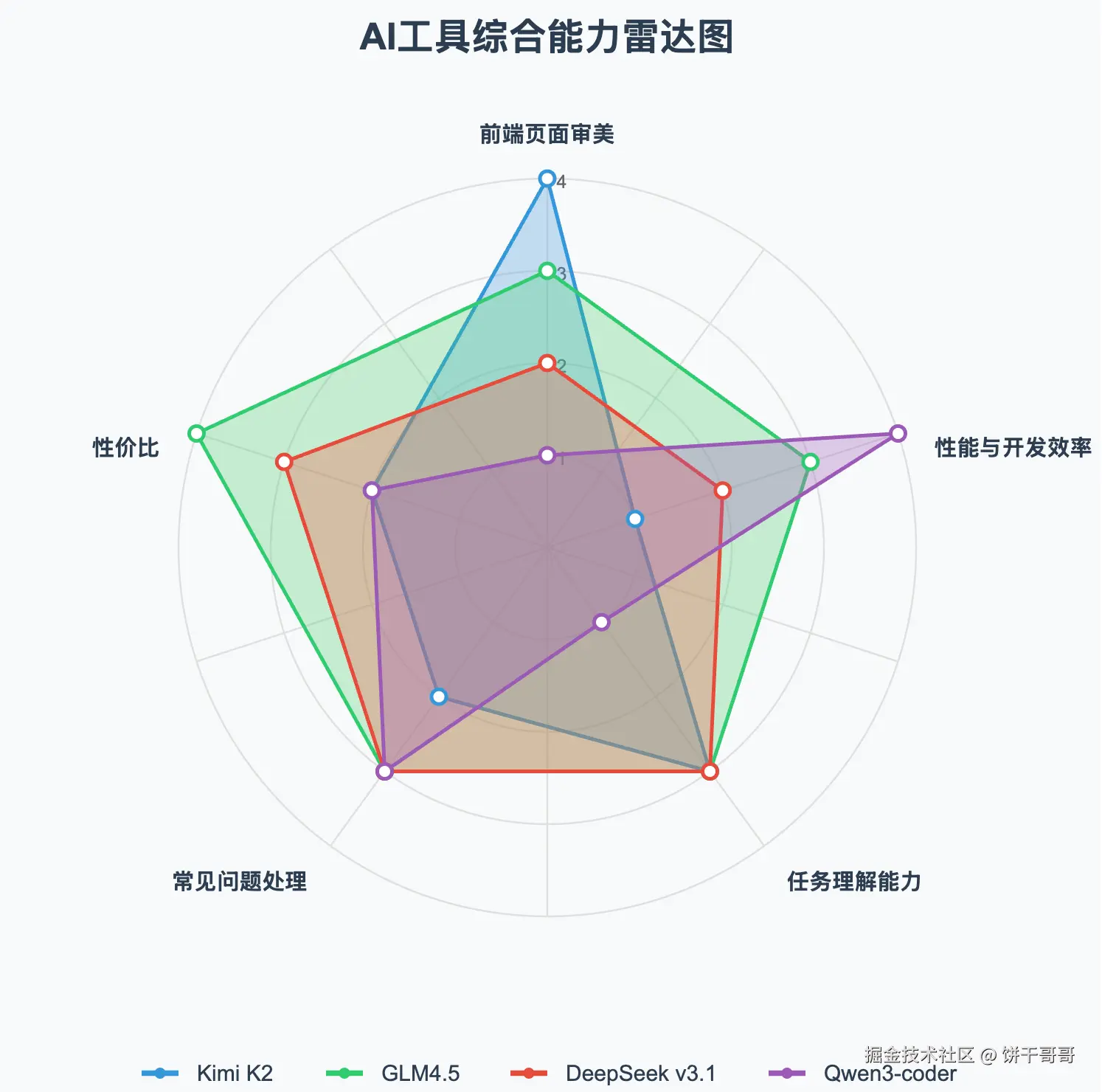
可以看到面积最大的 GLM4.5 无疑是这场测评中的赢家
接着是 DeepSeek V3.1、Kimi K2,最后是 Qwen3-coder
得出结论是,在国内,AI Coding 首选是 GLM 4.5, 这个在当前语境下没毛病。
从模型混战到"Agentic"工作流的未来
这次对国产四大AI编程模型的横评,与其说是一场性能竞赛,不如说是一次对未来开发范式的预演。
评测结果固然重要------GLM-4.5 凭借其综合表现拔得头筹,但我更看重结果背后的趋势:
AI编程已从"单点工具"进化为由 sub-agents 协同的"工作流伙伴",竞争的焦点不再是单纯的代码生成,而是复杂的任务规划与协同能力。
这也预示着开发者角色的根本转变:我们正从"编码者"进化为"AI架构师"。
未来的核心竞争力,将是如何设计精准的需求、搭建高效的Agent团队,并在关键节点进行监督与干预。
这场国产AI的"神仙打架"只是一个开始,真正重要的是,我们该如何驾驭这些日益强大的工具,重塑人与代码的协作关系。
本文由稀土掘金作者【饼干哥哥】,微信公众号:【饼干哥哥AGI】,原创/授权 发布于稀土掘金,未经许可,禁止转载。