本文整理自"IvorySQL 2025 生态大会暨 PostgreSQL 高峰论坛"上的分享内容,演讲者:傅宇,PolarDB for PostgreSQL 研发负责人。
本文主要分享如何通过 Graph 的方式让 RAG 运行的更好,主要涉及以下内容:
- 为什么需要 GraphRAG
- 构建知识图
- 查询知识图
- 在 PostgreSQL 上实践
为什么需要 GraphRAG
RAG 的诞生是为了解决一个特定领域的知识查询问题。RAG(LLM + 知识库) 通过 Vector DB 的近似向量搜索能力,赋予 LLM 长期记忆,实现更好的领域知识问答。而 GraphRAG(LLM + 知识图) 通过 Vector DB 的近似搜索能力结合图的关联搜索能力,提升专业领域的问答能力。
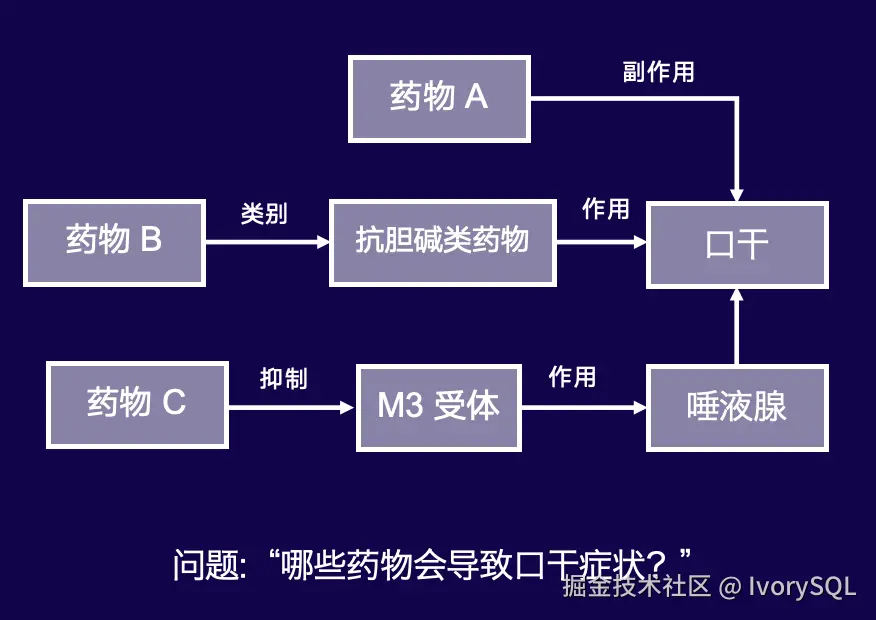
1. RAG 依赖的"知识"并非总是通过文本的近似性相产生关联

以"哪些药物会导致口干"为例,RAG 通过文本相似性识别关键词(如"药物""口干")及相关概念,知识库中第 4 条和第 1 条因词汇重合度高(如"口干")被关联,RAG 可胜任。但 RAG 无法进行推理,例如第 2 条提到药物 B 为抗胆碱类药物,与下文"抗胆碱药物可能导致口干"相关,人类可瞬时推导,而 RAG 基于相似度的局限性难以实现这一点。
但 Graph 可以做到。
Graph 是一个很自然的对知识进行建模的方式。Graph 可以把知识连城一个图,然后就可以在上面搜索出根据丰富的东西。"知识图"是对文本近似搜索的有力补充。
2. RAG 中缺少信息的结构化描述(详细 ➡️ 总结)
其次,单纯的 Rap 缺乏对知识库的整体理解。例如,输入的文档可能仅聚焦软件某一方面或全为法律条文解释单一事件。若询问笼统问题,如"软件用途"或"黄芪类似中药的功效与原理",即使提取 Top20 或 Top50 文档,也仅得零散细节,缺乏总结。总结需从零散知识中构建:获取 10-20 条相关信息后,归纳出更广义的观点,进而层层构建类似图谱中的概念。

构建知识图
Graph RAG 在 RAG 基础上增加了图和社群的构建。
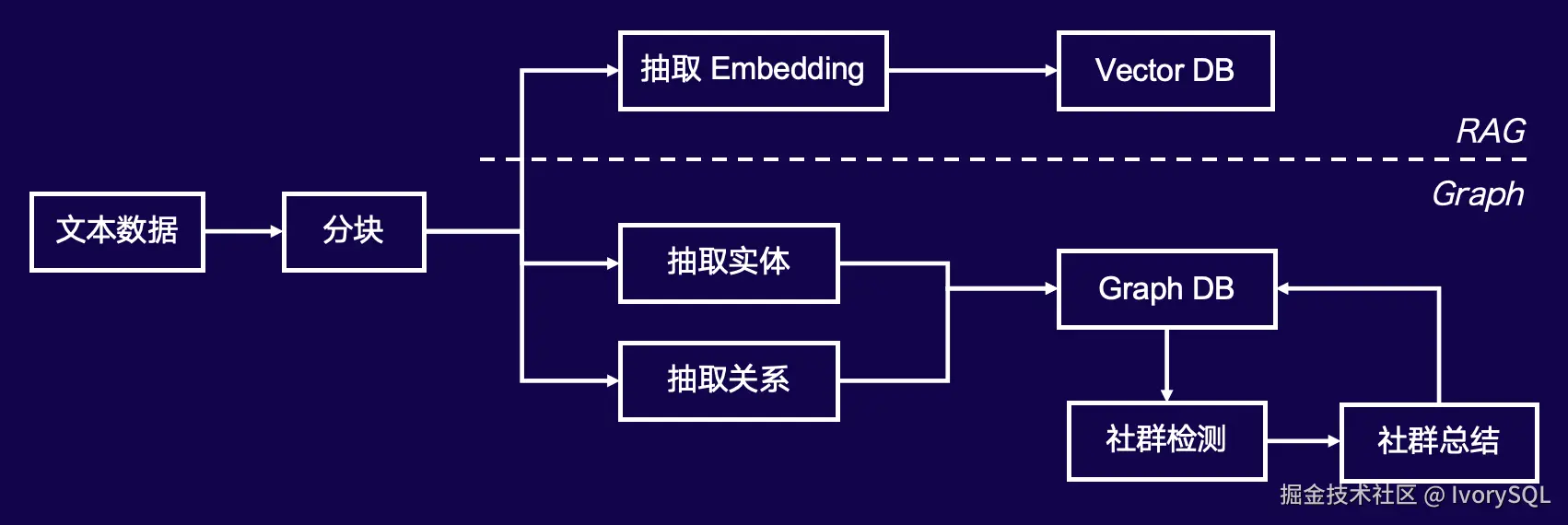
实现过程分为两步:第一步是构建,第二步是查询。就像数据库操作一样,首先需要以某种结构存储数据,然后通过 SQL 语言查询。
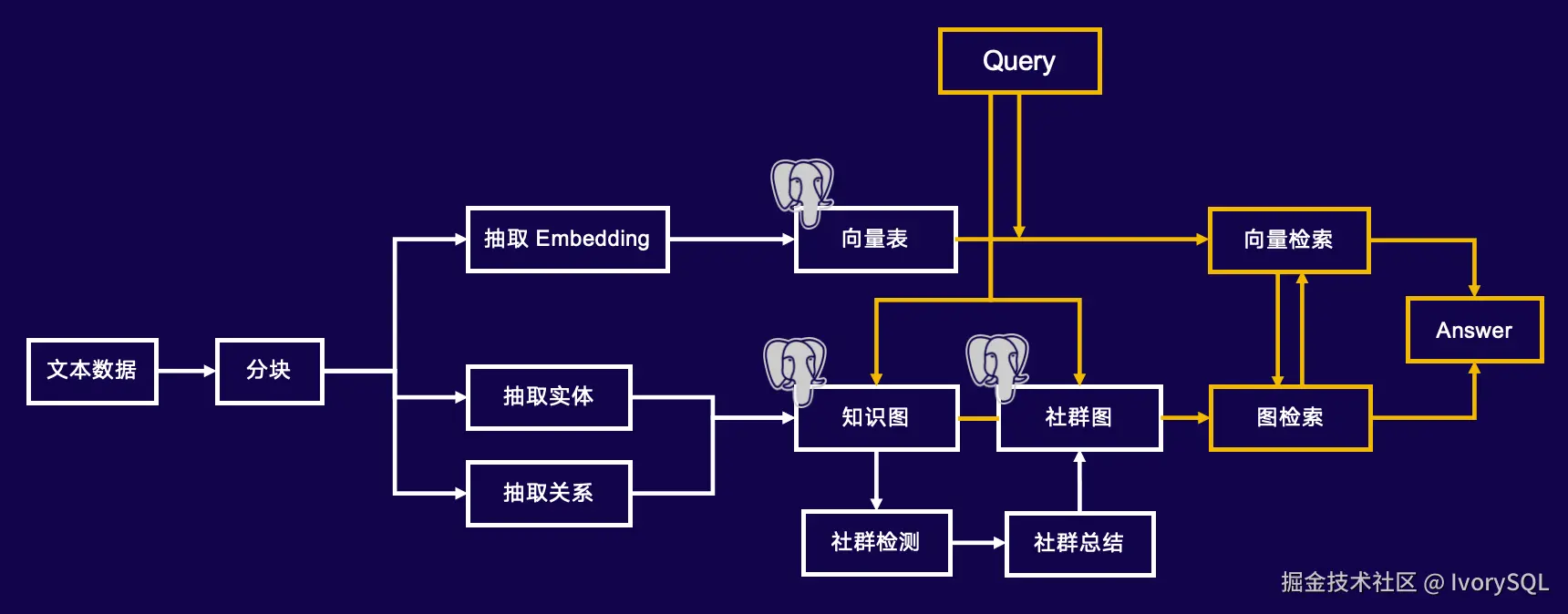
相比传统 RAG,Graph RAG 多了几个步骤。传统 RAG(虚线以上部分)包括:首先从文本中抽取内容(Embedding),然后存入 Vector DB,此时可通过 ID 获取文档。而在 Graph RAG 中,额外需要从文本中抽取出图的节点(称为实体)和节点之间的边(称为关系),这些实体和关系一起存入 Graph DB。此外,在 Graph DB 基础上,还可以进行社群检测,具体细节我们稍后逐步展开。
文本分块 Chunking
第一步是文本分块(Chunking),这在传统 RAG 中也很常见。需要将文本分成大小合适的块,通常 256~512 个 token 是一个合适的范围,既能保留足够的信息,又避免过多冗余,从而检索出较为完整的知识点。分块完成后,可对其进行图处理。
- 将每个文档切割成数百 tokens 以内的段落
- 推荐长度限制:256 ~ 512 tokens
- 每个 chunk 应当语义聚焦
- chunk 太大 → 多个实体混在一起 → 图谱构建混乱
- chunk 太小 → 语义不完整
图构建
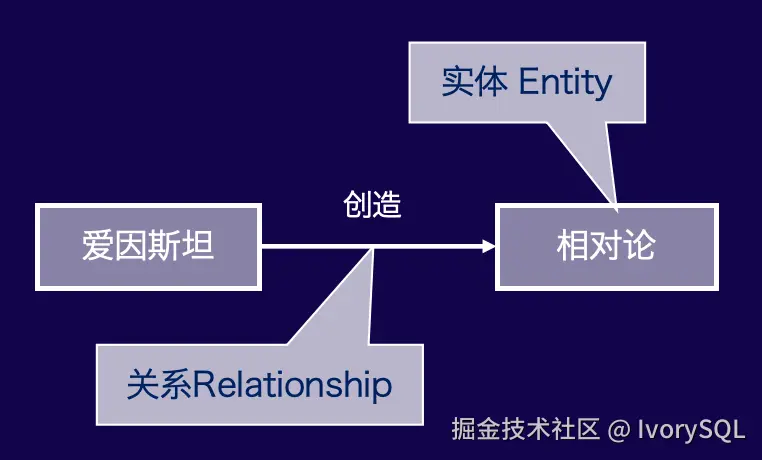
输入是刚刚分好块的文本(Text Chunk),输出是一个子图,例如下图所示的最简单子图(包含 2 个点和 1 条边),实际可能有 3-5 个点或多条边。子图中的实体(点,Vertex)代表一个概念,通常输出包括标题、类型和大模型总结的描述。
如果处理文档后发现多个节点名称相同,大多数情况下它们对应同一概念,此时大模型会再次总结描述,将它们归并为一个实体,进行信息汇总。边(Relationship)也有自己的标题和类型,因其从起点到终点唯一确定,若有重复,可用数字区分。这是技术上的考量。
最终输出是包含若干点和边的子图。
下图是一个例子。

将一段关于公司及其收购行为和活动的描述输入大语言模型,并提供合适的提示后,模型能输出实体(点,如公司)和关系(边,如收购),并按要求的字段(如标题、类型、描述)格式化。这些数据随后可结构化地存入 Graph DB 中。

在 Graph 系统中,许多任务依赖 LLM 完成,以上就是来自微软 GraphRAG 项目中抽取实体和关系所用到的 Prompt。没有 LLM,图的抽取过程将难以处理,这也是历史上知识图谱项目未获广泛关注的原因------其抽取过于依赖人工。如今有了 LLM,构建过程变得轻松高效。
社群总结
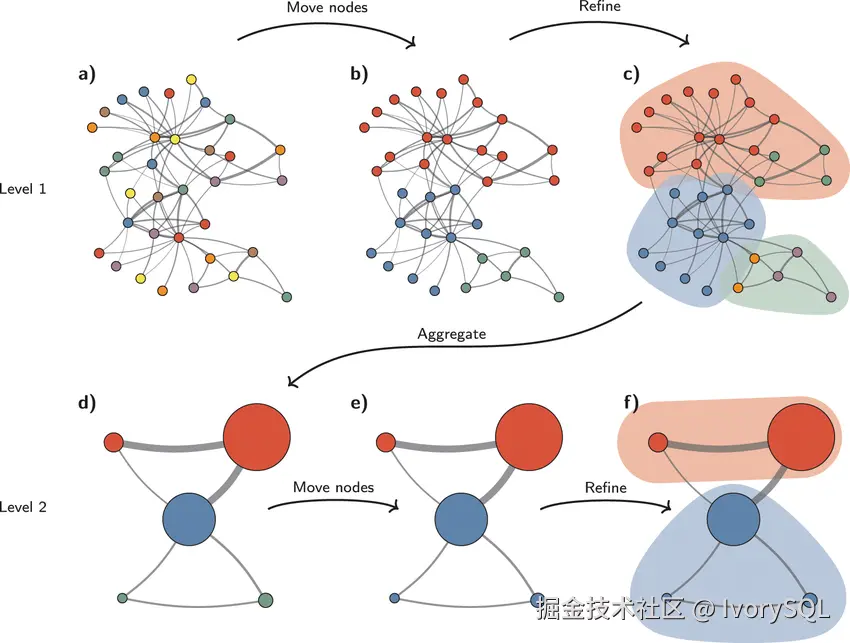
第三步是 Graph 特有的有趣过程,涉及社群(Community)概念。社群是指在图(由点和边构成)中,某些点之间的连接较为密集,类似社交网络中小区居民频繁互动的特点,内部边多于外部边。
图算法中已有经典非 AI 算法(如 Leiden 算法)可识别这些社群。将图中的社群染上不同颜色,这一过程可递归进行,每次将社群合并为新节点,从而逐步提炼出精简、结构化的图。这体现了需要层次结构的需求。
构建向量索引
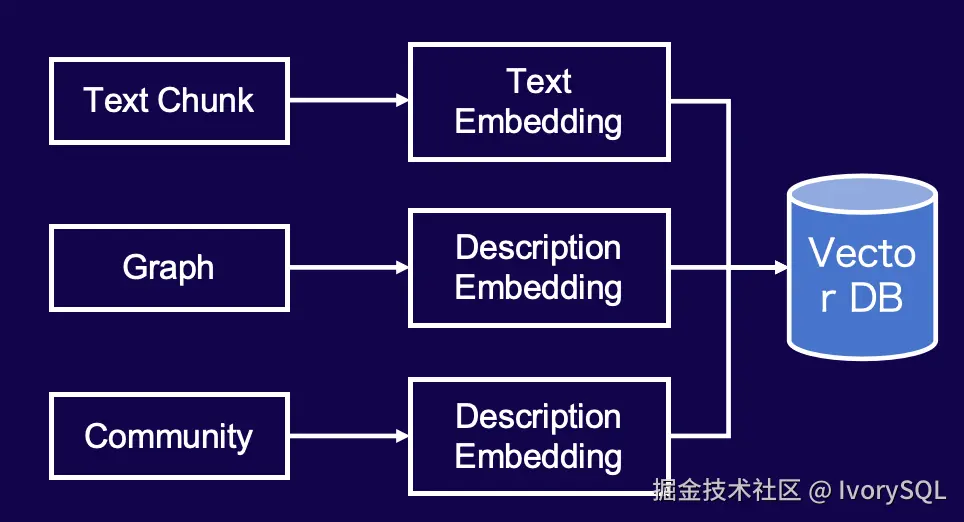
获取 Community 信息后,将其与原始图信息(包括点、边及描述)、二次处理的 Community 信息以及原始 Text Chunk 一并存入 Vector DB,可简单视为三张表。
在处理 Community 时,需补充一点:不仅对图进行总结,其中的点边描述也输入 LLM 进行提炼,生成不同层次的抽象概念,最终一并存入 Vector DB 以便检索。
查询知识图
有了这些信息,下一个问题就是如何利用这些信息处理用户的查询(提问)。这里介绍三种典型方式。
Local Search
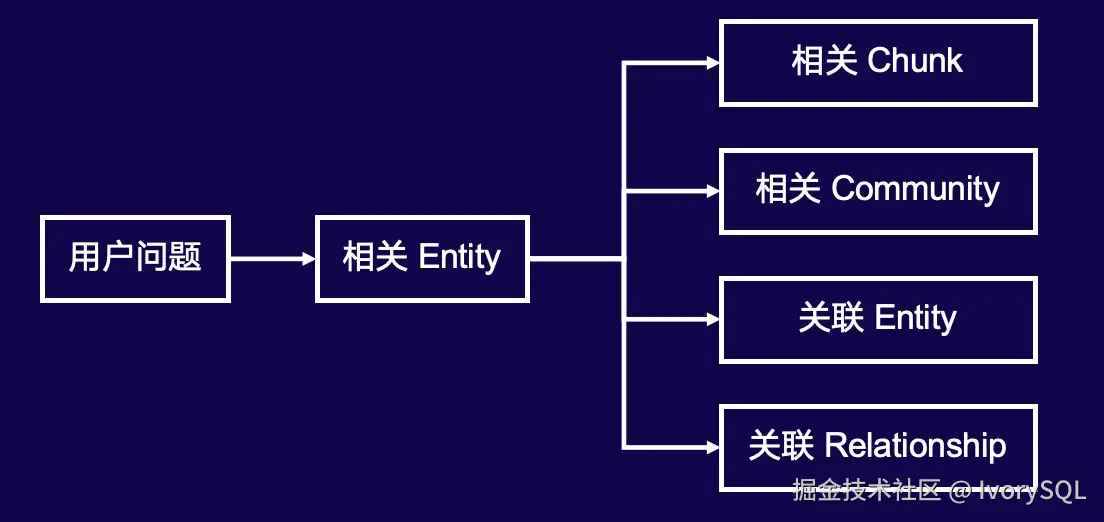
Local Search 针对明确查询对象,如查询"Post class"或"黄芪中药的副作用"/"Disc 公司",以该对象为中心,从图中找到相关节点,提取其周围的边、文本、社区及相关节点,再将这些信息输入 LLM 作为上下文,从而更准确地回答问题。这与传统 RAG 类似。
Global Search
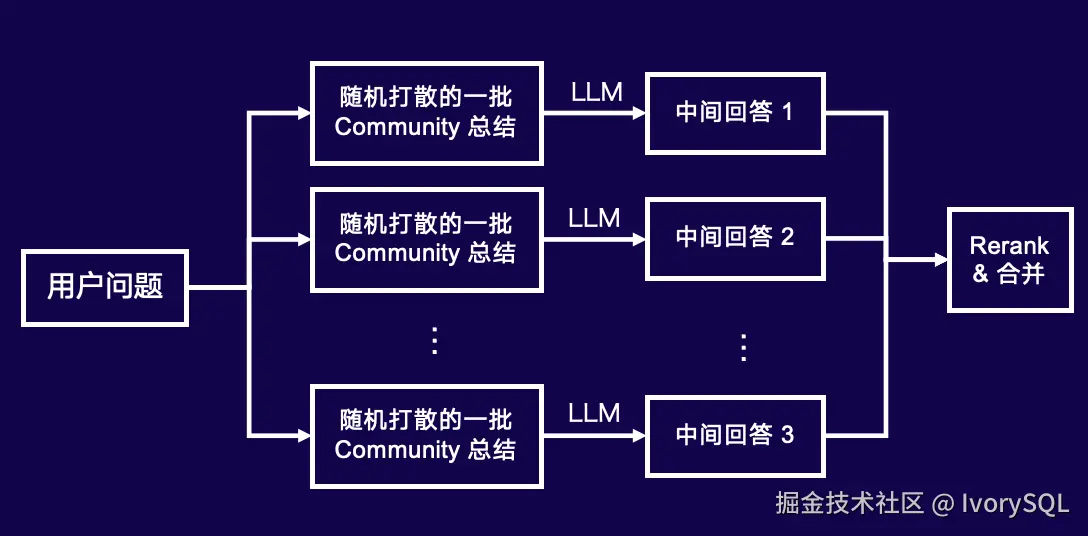
Global Search 适用于整体性问题而非单一概念,例如"总结数据中的 5 个主要主题"或"近年的活跃科研项目"。这种全局理解对专家系统尤为重要,单纯依靠零散文本难以由 LLM 直接获取。为此,利用 Community 概念,通过随机分组处理:每次取 20 个 Community 总结(因超 20 可能超出 LLM 上下文或遗忘问题)输入 LLM 生成中间回答,循环遍历所有 Community。
若某 Community 含有用数据,LLM 应能识别相关性并改进回答。假设所有中间回答已包含所需信息,有用数据会被提取,无用则可能遗漏,导致回答质量下降。第三步运行 Rerank 算法,剔除差的回答,保留有意义的回答,最终输入 LLM 生成最终结果。
DRIFT Search
最后一种方式是 DRIFT Search,体现动态推理(Dynamic Reasoning)和灵活遍历(Flexible Traversal),类似近年流行的 Agent 方法。不同于固定模式的检索,DRIFT 让 LLM 自主决定下一步行动。
其核心在于动态性:从一个节点开始搜索,初始选择最相关的节点生成回答,同时提出几个后续问题(Follow-up Questions)。由于缺乏上下文,LLM 会向系统询问所需数据,基于反馈提取新节点,再用 Local Search 回答追加问题,递归循环进行。
每次生成新节点时,赋予其优先级(Priority),优先处理高优先级问题,循环 50-100 次后,假设大部分有用信息已被覆盖。最后,以所有中间回答为上下文,生成最终答案。
在 PostgreSQL 上实践
PostgreSQL(PG)与 Graph RAG 高度契合,因其是多模数据库,能处理多种非关系型数据,包括图数据。PG 内置了著名图插件 Apache AGE(中文名似"图引擎"),性能优异,支持 Cypher+SQL 查询语言,在点边数量未激增时,单机即可处理大多数任务。
结合 Vector 插件,可构建 Graph 系统,无需过多辅助系统。相比以往需四五个额外系统的复杂搭建,PG 加 Python 库即可完成,效率显著提升。
- 启用插件:
CREATE EXTENSION IF NOT EXISTS age CASCADE; - 创建图:
SELECT create_graph('my_graph'); - 创建点:
css
SELECT * FROM ag_catalog.cypher('my_graph', $$
CREATE (kb:Actor {name: 'Kevin Bacon'}),
(a1:Actor {name: 'Actor 1'}),
(d1:Director {name: 'Director 1'}),
(d2:Director {name: 'Director 2'})
$$) as (a agtype);- 创建边:
css
SELECT * FROM ag_catalog.cypher('my_graph', $$
MATCH (kb:Actor {name: 'Kevin Bacon'}), (m1:Movie {title: 'Movie 1'})
CREATE (kb)-[:ACTED_IN]->(m1)
$$) as (a agtype);- 查询:"所有和 Kevin Bacon 共同演出过的演员"
css
SELECT * FROM ag_catalog.cypher('my_graph', $$
MATCH (kb:Actor {name: 'Kevin Bacon'})-[:ACTED_IN]->(m:Movie)<-[:ACTED_IN]-(coactor:Actor)
RETURN coactor.name AS CoActor
$$) as (CoActor agtype);PolarDB for PostgreSQL 数据库还内置了调用阿里云百炼模型的能力,可以将 LLM 调用的过程也纳入 SQL 中。
最后,我们整合所有步骤,构建 Graph 系统需以下操作:
首先,将文本进行分块,Embedding,存入 Vector DB。接着,通过抽取实体和关系生成图,将图信息(包括节点、边及描述)存入 Graph DB,并将描述 Embedding 后存入 Vector DB。随后,运行 Community 检测算法,用 LLM 总结 Community 信息,再将结果 Embedding 存入第三张 Vector 表。
检索时,结合 Local Search、Global Search、DRIFT 等多种方法提取相关信息,最终由 LLM 整合生成优化答案。
参考资料
- RAG vs. GraphRAG: A Systematic Evaluation and Key Insights:arxiv.org/abs/2502.11...
- From Local to Global: A GraphRAG Approach to Query-Focused Summarization:arxiv.org/abs/2404.16...
- 微软 Graph RAG 项目: microsoft.github.io/graphrag/
- PolarDB for PostgreSQL 文档 - PolarDB for AI :help.aliyun.com/zh/polardb/...
- 百炼大模型 API 参考:help.aliyun.com/zh/model-st...
- Apache AGE:age.apache.org/