
磁力链接(Magnet)
磁力链接是一种基于文件内容的统一资源标识符(URI),用于通过点对点(P2P)网络共享文件。与传统的基于服务器的下载方式不同,磁力链接依赖于分布式网络,无需中心化服务器即可获取文件。
磁力链接的组成
典型的磁力链接包含以下参数(以 magnet:?xt=urn:btih: 开头):
- xt(exact topic):唯一标识文件的哈希值(如BTIH哈希)。
- dn(display name):文件名(可选)。
- tr(tracker):Tracker服务器地址(可选)。
- 其他参数:如文件大小、子文件索引等。
示例:
css
magnet:?xt=urn:btih:1A2B3C4D5E6F7G8H9I0J&dn=example.mp4&tr=udp://tracker.example.com:80如何使用磁力链接
-
下载工具
需使用支持P2P协议的客户端,如:
- qBittorrent
- μTorrent
- Transmission
- BitComet
-
操作步骤
- 复制磁力链接。
- 在客户端中选择"添加链接"或直接粘贴。
- 客户端会解析链接并开始下载。
-
无Tracker下载
现代DHT(分布式哈希表)技术允许节点间直接发现资源,即使没有Tracker服务器。
磁力链接的优势
- 去中心化:不依赖特定服务器,降低单点故障风险。
- 隐私性:无需注册或登录即可下载。
- 灵活性:支持动态添加Tracker或文件元数据。
注意事项
- 版权问题:部分资源可能涉及侵权,需遵守当地法律法规。
- 安全性:建议配合防病毒软件使用,避免恶意文件。
- 速度依赖:下载速度受网络环境和节点数量影响。

docs:bitmagnet
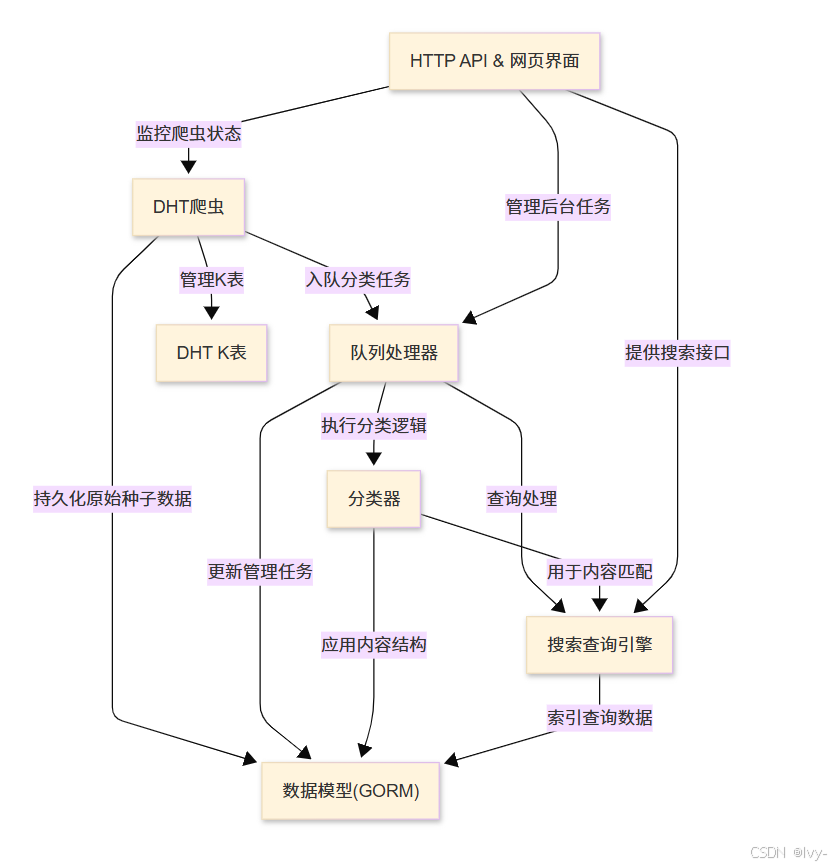
bitmagnet 是一个自托管平台,能够自动发现、分类和索引BitTorrent内容 。它采用独特的DHT爬虫 直接从网络发现种子,然后通过智能分类器 识别电影、音乐等内容类型。所有数据存储在数据库中,并通过强大的搜索查询引擎 提供Web界面和多种API访问。
可视化
章节列表
第1章:HTTP API与Web界面
想象我们已经搭建好bitmagnet系统,它正在后台持续爬取网络上的种子资源。这很棒!但如何实际使用它呢?如何搜索特定电影,或者让媒体管理工具(如Sonarr或Radarr)自动查找最新剧集?
这就是HTTP API 和Web界面的用武之地!它们是系统与外界交互的"门户",为用户(及其他程序)提供控制通道。可以将其视为系统的控制面板和显示屏。
HTTP API与Web界面解析
让我们解析这两个核心组件:
Web用户界面(WebUI)
WebUI是用户最熟悉的部分,基于Angular框架构建,可通过Chrome等浏览器直接访问。
- 类比说明:将系统视为持续发现和组织种子的智能机器人,WebUI就是配备精美显示屏的控制台。用户通过鼠标键盘操作按钮、输入搜索词,直观查看系统发现的所有种子及其详情。专为人工浏览和管理设计。
- 核心功能:可视化检索已索引种子、查看详细信息、监控系统运行状态(如爬取进度)。
HTTP应用程序接口(API)
HTTP API更偏技术向,专为其他程序与系统直接"对话"设计。采用与网页传输相同的HTTP协议,但返回结构化数据而非完整页面。
- 类比说明 :相当于机器人的命令行接口或专用指令集。其他程序(或高级用户脚本)可发送精确指令获取标准化格式数据。适用于自动化任务和第三方软件集成。
- 核心功能 :提供编程访问接口,包含两个主要模块:
- GraphQL端点:灵活查询种子数据的精确字段
- Torznab端点:为Sonarr等媒体管理工具提供标准化的种子搜索接口
使用指南
Web界面操作步骤
- 打开浏览器
- 访问系统地址 :默认运行在本机时访问
http://localhost:8080/webui,根目录会自动重定向至此 - 种子搜索:在搜索框输入关键词(如"The Matrix"),即可查看匹配结果的名称、大小、发现时间等元数据,点击条目可查看详情
- 功能导航 :通过界面链接可访问不同模块,如仪表盘(
/dashboard)查看系统状态,种子搜索页(/torrents)为主操作界面
HTTP API调用方式
1. GraphQL精准查询
通过http://localhost:8080/graphql访问交互式Playground,示例查询:
graphql
query {
search(query: "电影名") {
torrents {
infoHash
title
}
}
}该查询会返回匹配种子的哈希值和标题字段,输出为结构化JSON格式。
2. Torznab自动化对接
媒体管理工具通过标准Torznab接口(通常为http://localhost:8080/torznab/*)自动请求资源。例如Sonarr在需要更新剧集时,系统会返回XML格式的种子列表供其直接处理。
技术实现原理
核心交互流程
WebUI搜索场景
用户 浏览器 服务器 Web处理器 GraphQL处理器 访问/webui 请求界面文件 获取Angular应用 返回前端资源 展示交互界面 输入搜索词 提交GraphQL查询 执行数据库检索 返回JSON结果 展示结果列表 用户 浏览器 服务器 Web处理器 GraphQL处理器
Torznab自动化场景
Sonarr 服务器 Torznab处理器 请求剧集资源 解析查询 返回XML结果 提供种子数据 Sonarr 服务器 Torznab处理器
代码架构解析
- 中央调度器(
server.go)
go
func New(p Params) Result {
g := gin.New() // HTTP服务器核心
for _, o := range p.Options {
o.Apply(g) // 注册各模块路由
}
return Result{}
}采用Gin框架构建,通过选项模式集成各功能模块。
- Web界面处理(
webui/httpserver.go)
go
func (b *builder) Apply(e *gin.Engine) {
e.StaticFS("/webui", staticFiles) // 托管前端资源
e.GET("/", redirectToWebUI) // 根路径重定向
}- GraphQL处理(
gql/httpserver.go)
go
func (b builder) Apply(e *gin.Engine) {
e.POST("/graphql", handleQueries) // 查询端点
e.GET("/graphql", showPlayground) // 调试界面
}- Torznab处理(
torznab/httpserver.go)
go
func (b builder) Apply(e *gin.Engine) {
e.GET("/torznab/*any", handleRequest) // 通配路由
}总结
HTTP API与Web界面构成系统双通道交互体系:
- WebUI提供人性化可视化操作
- API 支持程序化集成与自动化
两者共同搭建起系统与用户/外部工具的沟通桥梁。
接下来我们将深入探索系统的检索核心:搜索查询引擎
第2章:搜索查询引擎
在第1章:HTTP API与Web界面中,我们了解了如何通过Web界面和API与系统交互。但系统在收到搜索请求后具体如何运作?如何从海量数据中精准定位目标资源?
这就是搜索查询引擎的职责所在!它如同系统的智能图书管理员,能理解用户需求,快速筛选数百万"书籍"(种子资源),精准返回结果并推荐相关内容。
搜索查询引擎解析
这是系统实现信息检索的核心大脑,支持通过不同规则和条件检索所有已索引的种子资源。
核心特性:
- 信息检索:支持关键词搜索(如"电影名")
- 智能过滤:支持精确短语、排除项、分类筛选等高级语法
- 结果聚合 :通过分面统计将结果按类别分组(如"电影类:150项")
引擎基于PostgreSQL全文搜索实现高效文本检索。
搜索功能详解
基础搜索
通过Web界面搜索框直接输入关键词即可触发基础搜索。
高级搜索语法
支持在Web界面或GraphQL API中使用特殊语法:
| 语法 | 功能说明 | 示例 |
|---|---|---|
引号(") |
精确短语匹配 | "香蕉船"匹配完整短语 |
点号(.) |
指定词序(类似引号) | 苹果.橙子近似"苹果 橙子" |
| 或运算符(` | `) | 逻辑或 |
非运算符(!) |
排除项 | 橙子!苹果排除含"苹果"结果 |
通配符(*) |
前缀匹配(仅词尾) | appl*匹配"apple"等 |
括号(()) |
条件分组 | `(苹果 |
| 标准化 | 不区分大小写/特殊字符 | cafe匹配"café" |
案例演示:搜索"蒸汽船威利"
"蒸汽船威利" 1928 !4k | "米老鼠""蒸汽船威利":精确匹配标题1928:包含该年份版本!4k:排除4K分辨率资源| "米老鼠":同时显示相关资源
分面统计功能
通过分面过滤实现结果分类导航:
- 分类维度:内容类型、标签、语言等
- 聚合统计:显示各类别结果数量(如"电影(150)")
- 动态筛选:点击分类可实时缩小结果范围
技术实现原理
核心处理流程
用户 前端界面 查询引擎 数据库 提交搜索请求 转发查询 1.语法解析→TSQuery转换 执行TSQuery检索 返回原始数据+统计 2.结果处理+聚合计算 结构化结果 渲染展示 用户 前端界面 查询引擎 数据库
关键代码模块
- 查询解析(
tsquery.go)
go
func AppQueryToTsquery(str string) string {
// 将用户搜索转换为PostgreSQL的TSQuery语法
if str == `"蒸汽船威利" 1928 !4k` {
return "('蒸汽船' <-> '威利') & '1928' & !'4k'"
}
// ...
}- 查询构建(
query.go)
go
func TorrentContent(ctx context.Context, opts ...Option) {
// 组合各类查询条件
query.GenericQuery(
ctx,
query.Options(append([]Option{query.SelectAll()}, opts...)...),
model.TableNameTorrentContent,
// ...
)
}- 分面统计(
facets.go)
go
func calculateAggregations(ctx context.Context) (Aggregations, error) {
// 对每个分类维度执行计数查询
// SELECT count(*) WHERE (...) AND content_type='movie'
// ...
}总结
搜索查询引擎通过:
- 智能语法解析
- 高效数据库检索
- 动态结果聚合
构建起系统的核心检索能力。下一章将深入探讨数据存储结构:数据模型(GORM)