免责声明:下面的内容由ai阅读源码生成,有错误欢迎指出
现在很多chatbox组件都会涉及到将markdown渲染为html,我们有很多可选择的库:
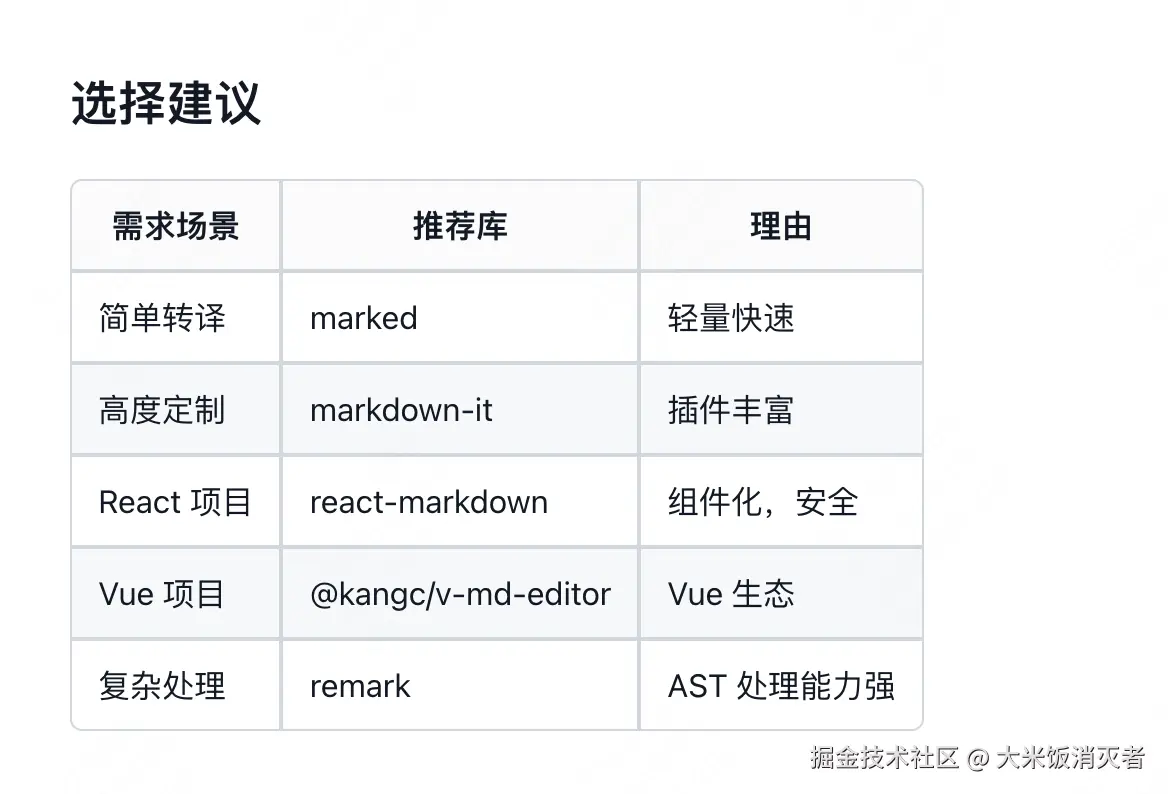
这里我主要讲解一下markdown-it,markdown-it是怎么将markdown转为html的。
下面是一个看不懂的流程图:
graph TD
A[Markdown 输入] --> B[MarkdownIt 实例]
B --> C[parse 方法]
C --> D[Core Parser 处理]
D --> E[Token 流生成]
E --> F[render 方法]
F --> G[Renderer 处理]
G --> H[HTML 输出]
subgraph "Core Parser 阶段"
D --> D1[normalize 标准化输入]
D1 --> D2[block 块级解析]
D2 --> D3[inline 行内解析]
D3 --> D4[linkify 链接识别]
D4 --> D5[replacements 文本替换]
D5 --> D6[smartquotes 智能引号]
D6 --> D7[text_join 文本合并]
end
subgraph "Block Parser"
D2 --> B1[heading 标题]
D2 --> B2[paragraph 段落]
D2 --> B3[blockquote 引用]
D2 --> B4[list 列表]
D2 --> B5[code 代码块]
D2 --> B6[fence 围栏代码]
D2 --> B7[table 表格]
D2 --> B8[hr 分割线]
end
subgraph "Inline Parser"
D3 --> I1[text 纯文本]
D3 --> I2[emphasis 强调]
D3 --> I3[link 链接]
D3 --> I4[image 图片]
D3 --> I5[backticks 行内代码]
D3 --> I6[escape 转义]
D3 --> I7[entity HTML实体]
end
subgraph "Renderer 阶段"
G --> R1[遍历 Token 流]
R1 --> R2[匹配渲染规则]
R2 --> R3[生成 HTML 片段]
R3 --> R4[组合最终 HTML]
end
1.Markdown-it是怎么将Markdown转化为html的:
整体流程简单概述:
graph LR
A[Markdown 文本] --> B[解析阶段]
B --> C[Token 流]
C --> D[渲染阶段]
D --> E[HTML 字符串]
subgraph "这段代码的位置"
C --> F[md.renderer.render]
F --> E
end
核心代码demo:
js
// ===== 创建核心状态对象 =====
// StateCore 是 markdown-it 的核心状态类,用于管理整个解析过程
const StateCore = md.core.State;
// 创建一个新的状态实例
// 参数说明:
// - testMarkdown: 要解析的 Markdown 源文本
// - md: MarkdownIt 实例,包含所有解析器和配置
// - {}: 环境对象,用于存储解析过程中的额外数据(如引用链接等)
const state = new StateCore(testMarkdown, md, {});
console.log('\n初始状态:');
// 显示源文本的长度
console.log('- src 长度:', state.src.length);
// 显示初始 token 数量(应该为 0,因为还没开始解析)
console.log('- tokens 数量:', state.tokens.length);
// ===== 手动执行核心规则链 =====
// 获取所有核心规则的函数数组
// 这些规则按顺序执行:normalize -> block -> inline -> linkify -> replacements -> smartquotes -> text_join
const coreRules = md.core.ruler.getRules('');
console.log('\n执行 Core 规则链:');
// 逐个执行每个核心规则,并监控 token 数量的变化
coreRules.forEach((rule, index) => {
// 记录执行规则前的 token 数量
const beforeTokens = state.tokens.length;
// 执行当前规则,规则会修改 state 对象
// 每个规则都会对 state.tokens 数组进行操作
rule(state);
// 记录执行规则后的 token 数量
const afterTokens = state.tokens.length;
// 输出规则执行的效果:规则名称和 token 数量变化
// rule.name 可能为 undefined,所以使用 'anonymous' 作为后备
console.log(`${index + 1}. ${rule.name || 'anonymous'}: ${beforeTokens} -> ${afterTokens} tokens`);
});
// ===== 分析最终生成的 Token 流 =====
console.log('\n最终 Token 流:');
// 遍历所有生成的 token,显示其详细信息
state.tokens.forEach((token, index) => {
// 显示 token 的基本信息:
// - type: token 类型(如 heading_open, paragraph_open, inline 等)
// - tag: 对应的 HTML 标签(如 h1, p 等)
// - nesting: 嵌套级别(1=开启标签, 0=自闭合, -1=关闭标签)
console.log(`${index}: ${token.type} (${token.tag}) nesting:${token.nesting}`);
// 如果 token 有内容,显示内容
// 通常 inline 类型的 token 会有 content
if (token.content) {
console.log(` content: "${token.content}"`);
}
// 如果 token 有子 token(通常是 inline 类型的 token)
// 子 token 包含了行内元素的详细解析结果
if (token.children && token.children.length > 0) {
console.log(` children: ${token.children.length} tokens`);
// 遍历并显示所有子 token
token.children.forEach((child, childIndex) => {
// 显示子 token 的类型和内容
// 子 token 可能是:text, strong_open, strong_close, em_open, em_close 等
console.log(` ${childIndex}: ${child.type} "${child.content}"`);
});
}
});
console.log('\n=== 渲染阶段详细步骤 ===');
// 演示渲染过程
const html = md.renderer.render(state.tokens, md.options, {});
console.log('\n最终 HTML 输出:');
console.log(html);renderer函数(md.renderer.render)的内容大致为:
js
// 默认的 token 渲染逻辑
Renderer.prototype.renderToken = function (tokens, idx, options) {
const token = tokens[idx]
let result = ''
// 根据 nesting 值决定是开启标签、关闭标签还是自闭合标签
if (token.nesting === 1) {
// 开启标签: <h1>, <p>, <strong> 等
result = '<' + token.tag
} else if (token.nesting === -1) {
// 关闭标签: </h1>, </p>, </strong> 等
result = '</' + token.tag + '>'
} else {
// 自闭合标签: <br />, <img /> 等
result = '<' + token.tag
}
return result
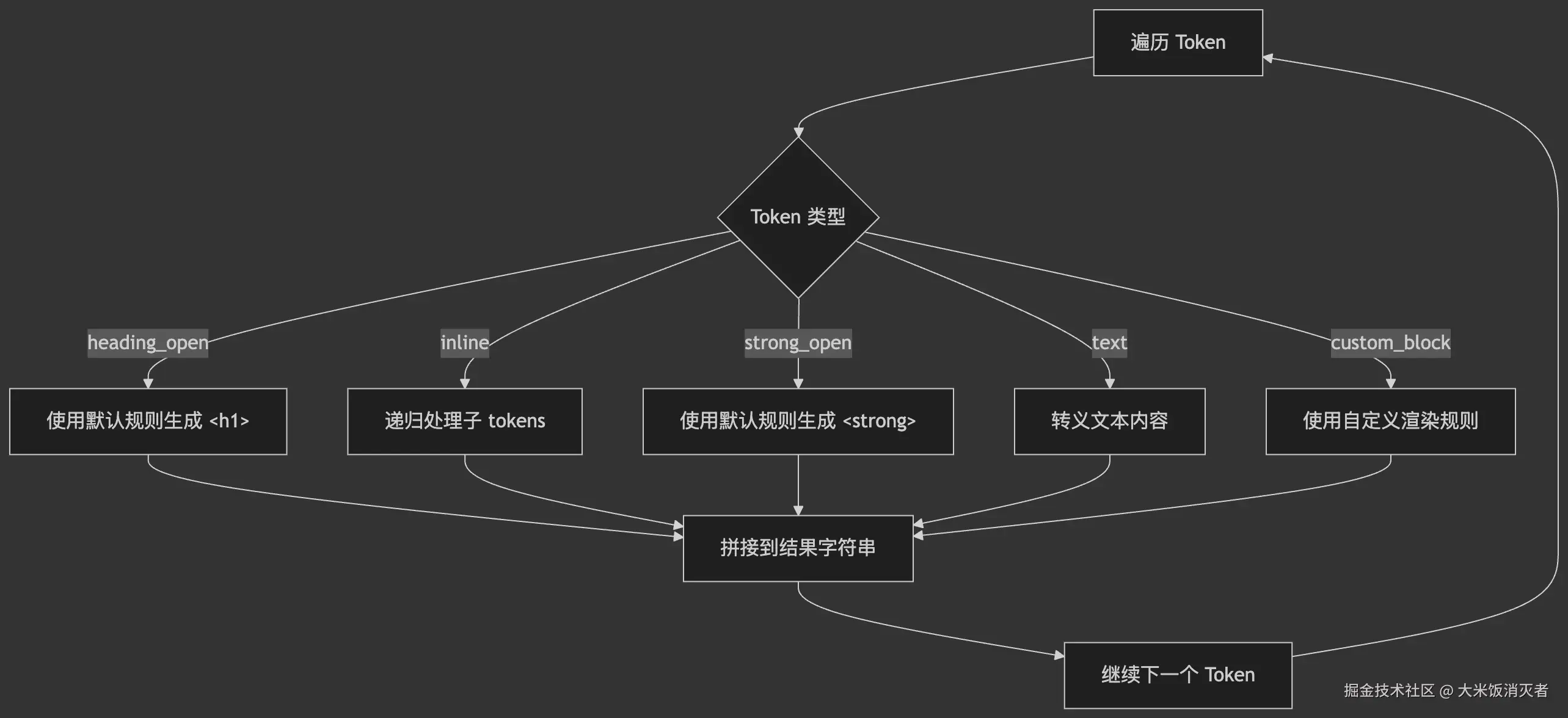
}接下来结合流程图再过一遍整体流程:
阶段1:解析流程图
graph TD
A[Markdown 输入] --> B[创建 StateCore]
B --> C[normalize 规则]
C --> D[标准化换行符和BOM]
D --> E[block 规则]
E --> F[按行扫描文本]
F --> G{匹配块级规则?}
G -->|标题| H[生成 heading tokens]
G -->|段落| I[生成 paragraph tokens]
G -->|列表| J[生成 list tokens]
G -->|代码块| K[生成 code tokens]
H --> L[inline 规则]
I --> L
J --> L
K --> L
L --> M[处理 inline tokens 的内容]
M --> N[生成最终 Token 流]
阶段2:Token 流结构
以下面的markdown为例:

js
[
{
type: 'heading_open',
tag: 'h1',
nesting: 1,
markup: '#'
},
{
type: 'inline',
content: '标题',
children: [
{ type: 'text', content: '标题' }
]
},
{
type: 'heading_close',
tag: 'h1',
nesting: -1,
markup: '#'
},
{
type: 'paragraph_open',
tag: 'p',
nesting: 1
},
{
type: 'inline',
content: '这是 **粗体** 文本。',
children: [
{ type: 'text', content: '这是 ' },
{ type: 'strong_open', tag: 'strong', nesting: 1 },
{ type: 'text', content: '粗体' },
{ type: 'strong_close', tag: 'strong', nesting: -1 },
{ type: 'text', content: ' 文本。' }
]
},
{
type: 'paragraph_close',
tag: 'p',
nesting: -1
}
]阶段3:渲染流程图
源码demo终端输出:
shell
=== Markdown-it 源码深度分析 ===
1. MarkdownIt 实例结构分析:
- core: object - 核心解析器
- block: object - 块级解析器
- inline: object - 行内解析器
- renderer: object - 渲染器
- linkify: object - 链接识别器
- options: object - 配置选项
2. 解析器规则链分析:
Core 规则: [
'normalize',
'block',
'inline',
'linkify$1',
'replace',
'smartquotes',
'text_join'
]
Block 规则: [
'table', 'code',
'fence', 'blockquote',
'hr', 'list',
'reference', 'html_block',
'heading', 'lheading',
'paragraph'
]
Inline 规则: [
'text',
'linkify',
'newline',
'escape',
'backtick',
'strikethrough_tokenize',
'emphasis_tokenize',
'link',
'image',
'autolink',
'html_inline',
'entity'
]
Inline2 规则: [
'link_pairs',
'strikethrough_postProcess',
'emphasis_post_process',
'fragments_join'
]
3. 渲染器规则分析:
默认渲染规则: [
'code_inline',
'code_block',
'fence',
'image',
'hardbreak',
'softbreak',
'text',
'html_block',
'html_inline'
]
4. 详细解析过程演示:
输入 Markdown:
# 标题
这是 **粗体** 文本。
=== 解析阶段详细步骤 ===
初始状态:
- src 长度: 19
- tokens 数量: 0
执行 Core 规则链:
1. normalize: 0 -> 0 tokens
2. block: 0 -> 6 tokens
3. inline: 6 -> 6 tokens
4. linkify$1: 6 -> 6 tokens
5. replace: 6 -> 6 tokens
6. smartquotes: 6 -> 6 tokens
7. text_join: 6 -> 6 tokens
最终 Token 流:
0: heading_open (h1) nesting:1
1: inline () nesting:0
content: "标题"
children: 1 tokens
0: text "标题"
2: heading_close (h1) nesting:-1
3: paragraph_open (p) nesting:1
4: inline () nesting:0
content: "这是 **粗体** 文本。"
children: 5 tokens
0: text "这是 "
1: strong_open ""
2: text "粗体"
3: strong_close ""
4: text " 文本。"
5: paragraph_close (p) nesting:-1
=== 渲染阶段详细步骤 ===
最终 HTML 输出:
<h1>标题</h1>
<p>这是 <strong>粗体</strong> 文本。</p>
5. 自定义规则演示:
测试自定义规则:
输入: ::: 这是自定义块
输出: <div class="custom-block">这是自定义块</div>
6. 性能分析:
解析时间: 2.824ms
渲染时间: 0.492ms
Token 数量: 258
HTML 长度: 1831
=== 分析完成 ===2.如果markdown格式不完整,流式输出,怎么处理:
- markdown-it 本身不支持真正的流式解析
- 强调规则需要完整的分隔符对才能工作
- 实际应用中需要实现缓冲和延迟渲染策略
- 可以通过自定义解析器实现更好的流式体验
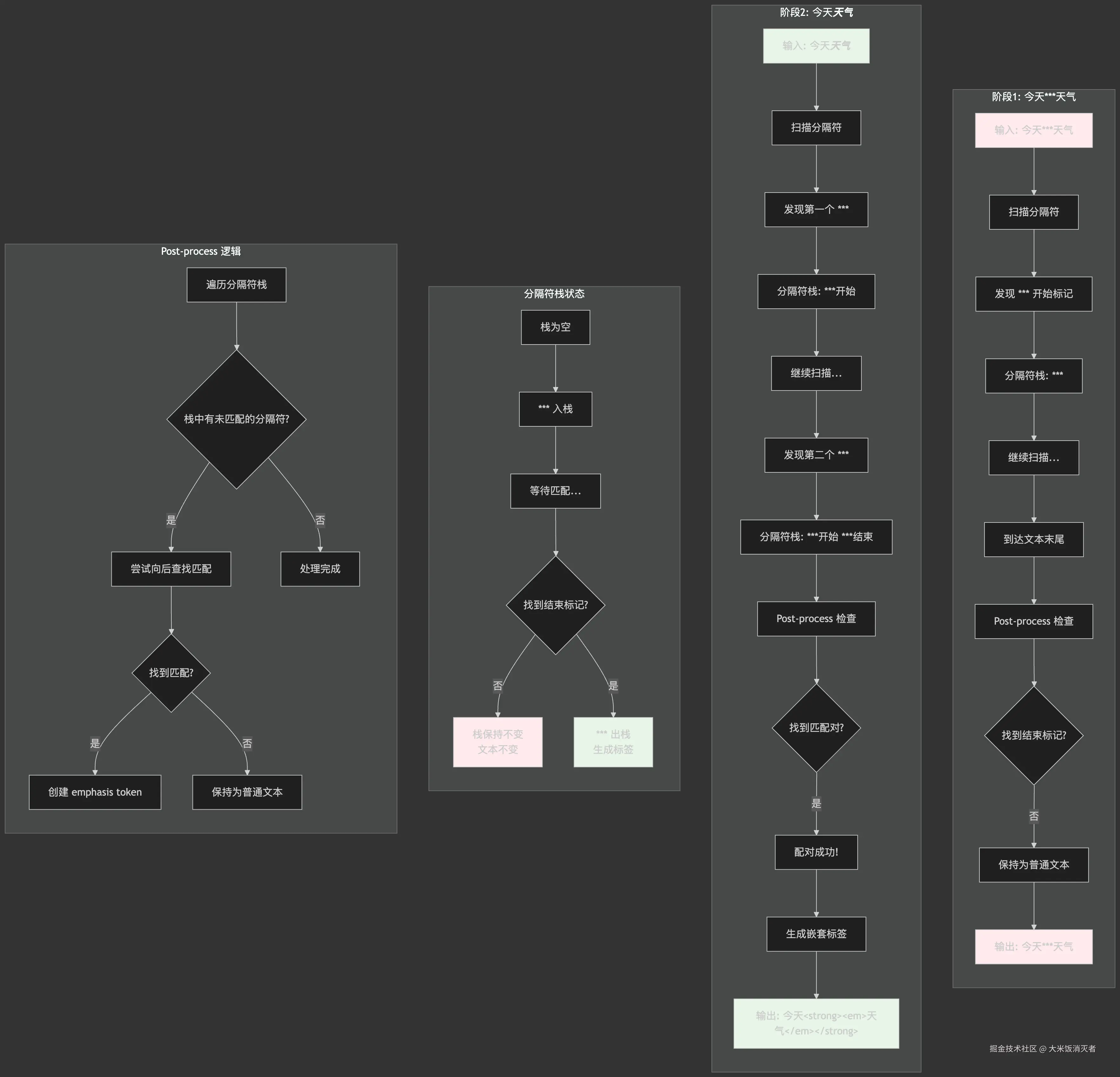
模拟AI流式输出终端输出:
shell
=== Markdown-it 流式输出深度分析 ===
📈 流式输入各阶段分析:
🔍 详细分析: "***天气"
==================================================
📝 初始状态:
文本: "***天气"
长度: 5
🔄 Tokenize 阶段:
位置 0: 匹配规则 emphasis_tokenize
位置 3: 匹配规则 text
📊 生成的 tokens (3 个):
0: text "*"
1: text "*"
2: text "*"
🎯 分隔符栈 (3 个):
0: "*" 长度:3 开启:true 关闭:false 结束:-1
1: "*" 长度:3 开启:true 关闭:false 结束:-1
2: "*" 长度:3 开启:true 关闭:false 结束:-1
⚡ Post-process 阶段:
分隔符匹配结果:
📋 最终 tokens (3 个):
0: text "*"
1: text "*"
2: text "*"
🎨 HTML 输出: <p>***天气</p>
🔍 详细分析: "***天气*"
==================================================
📝 初始状态:
文本: "***天气*"
长度: 6
🔄 Tokenize 阶段:
位置 0: 匹配规则 emphasis_tokenize
位置 3: 匹配规则 text
位置 5: 匹配规则 emphasis_tokenize
📊 生成的 tokens (5 个):
0: text "*"
1: text "*"
2: text "*"
3: text "天气"
4: text "*"
🎯 分隔符栈 (4 个):
0: "*" 长度:3 开启:true 关闭:false 结束:-1
1: "*" 长度:3 开启:true 关闭:false 结束:-1
2: "*" 长度:3 开启:true 关闭:false 结束:-1
3: "*" 长度:1 开启:false 关闭:true 结束:-1
⚡ Post-process 阶段:
分隔符匹配结果:
📋 最终 tokens (5 个):
0: text "*"
1: text "*"
2: text "*"
3: text "天气"
4: text "*"
🎨 HTML 输出: <p>**<em>天气</em></p>
🔍 详细分析: "***天气**"
==================================================
📝 初始状态:
文本: "***天气**"
长度: 7
🔄 Tokenize 阶段:
位置 0: 匹配规则 emphasis_tokenize
位置 3: 匹配规则 text
位置 5: 匹配规则 emphasis_tokenize
📊 生成的 tokens (6 个):
0: text "*"
1: text "*"
2: text "*"
3: text "天气"
4: text "*"
5: text "*"
🎯 分隔符栈 (5 个):
0: "*" 长度:3 开启:true 关闭:false 结束:-1
1: "*" 长度:3 开启:true 关闭:false 结束:-1
2: "*" 长度:3 开启:true 关闭:false 结束:-1
3: "*" 长度:2 开启:false 关闭:true 结束:-1
4: "*" 长度:2 开启:false 关闭:true 结束:-1
⚡ Post-process 阶段:
分隔符匹配结果:
📋 最终 tokens (6 个):
0: text "*"
1: text "*"
2: text "*"
3: text "天气"
4: text "*"
5: text "*"
🎨 HTML 输出: <p>*<strong>天气</strong></p>
🔍 详细分析: "***天气***"
==================================================
📝 初始状态:
文本: "***天气***"
长度: 8
🔄 Tokenize 阶段:
位置 0: 匹配规则 emphasis_tokenize
位置 3: 匹配规则 text
位置 5: 匹配规则 emphasis_tokenize
📊 生成的 tokens (7 个):
0: text "*"
1: text "*"
2: text "*"
3: text "天气"
4: text "*"
5: text "*"
6: text "*"
🎯 分隔符栈 (6 个):
0: "*" 长度:3 开启:true 关闭:false 结束:-1
1: "*" 长度:3 开启:true 关闭:false 结束:-1
2: "*" 长度:3 开启:true 关闭:false 结束:-1
3: "*" 长度:3 开启:false 关闭:true 结束:-1
4: "*" 长度:3 开启:false 关闭:true 结束:-1
5: "*" 长度:3 开启:false 关闭:true 结束:-1
⚡ Post-process 阶段:
分隔符匹配结果:
📋 最终 tokens (7 个):
0: text "*"
1: text "*"
2: text "*"
3: text "天气"
4: text "*"
5: text "*"
6: text "*"
🎨 HTML 输出: <p><em><strong>天气</strong></em></p>
================================================================================
🎯 核心问题分析
================================================================================
❌ 问题根源:
1. markdown-it 的强调规则使用"分隔符栈"算法
2. 该算法需要在 post-process 阶段匹配开始和结束分隔符
3. 只有找到匹配的分隔符对,才会生成强调 token
4. 在流式输出中,结束分隔符可能还未到达
🔍 具体流程:
1. Tokenize 阶段:将所有 '*' 标记添加到分隔符栈
2. Post-process 阶段:从后往前遍历分隔符栈,寻找匹配对
3. 只有找到匹配对的分隔符才会被转换为 em/strong token
4. 未匹配的分隔符保持为普通文本
💡 为什么 "***天气" 不会被加粗:
- 分隔符栈中只有开始的 "***",没有结束的 "***"
- Post-process 阶段找不到匹配的结束分隔符
- 所有 "*" 保持为普通文本 token
================================================================================
🛠️ 流式输出解决方案
================================================================================
方案1: 延迟渲染 (最常用)
- 维护一个缓冲区,等待更多内容
- 只渲染"安全"的部分(确定不会改变的内容)
- 对于未完成的标记,延迟到有足够上下文时再处理
方案2: 增量解析
- 实现自定义的流式解析器
- 维护解析状态,支持增量更新
- 只在确定匹配时才输出格式化内容
方案3: 预测性解析
- 基于上下文和模式预测可能的结束标记
- 提供"临时"渲染,后续可能需要回滚
- 适用于交互式编辑器
方案4: 混合模式
- 对于简单格式(如单个*)立即处理
- 对于复杂格式(如***)使用延迟策略
- 平衡实时性和准确性
📝 实用流式解析策略演示:
🧪 测试实用流式解析器:
步骤 1: 添加 "今天" -> 输出 "今天" (累计: "今天")
步骤 2: 添加 "***" -> 输出 "" (累计: "今天")
步骤 3: 添加 "天" -> 输出 "" (累计: "今天")
步骤 4: 添加 "气" -> 输出 "" (累计: "今天")
步骤 5: 添加 "***" -> 输出 "<strong><em>天气</em></strong>" (累计: "今天<strong><em>天气</em></strong>")
步骤 6: 添加 "很好" -> 输出 "" (累计: "今天<strong><em>天气</em></strong>")
最终: 剩余 "**很好" (完整结果: "今天<strong><em>天气</em></strong>**很好")
✅ 分析完成!
🎯 关键结论:
1. markdown-it 本身不支持真正的流式解析
2. 强调规则需要完整的分隔符对才能工作
3. 实际应用中需要实现缓冲和延迟渲染策略
4. 可以通过自定义解析器实现更好的流式体验想要实现demo的可以后台私信我发送喵