VideoMage:文本生成视频扩散模型的多主体与动作定制化
paper title:VideoMage: Multi-Subject and Motion Customization
of Text-to-Video Diffusion Models
paper是National Taiwan University发表在CVPR 2025的工作
Code:链接

图1. 多主体与动作定制化示意图。给定多个主体的图像、一个参考动作视频以及相关的文本提示,我们的 VideoMage 能够生成与这些输入相匹配的视频输出。
Abstract
定制化文本生成视频的目标是生成高质量的视频,其中融入用户指定的主体身份或动作模式。然而,现有方法主要集中于个性化单一概念,即主体身份或动作模式,这限制了它们在处理多个主体及其期望动作模式时的效果。为了解决这一挑战,我们提出了一个统一的框架 VideoMage,用于同时在多个主体及其交互动作上进行视频定制。VideoMage 使用主体 LoRA 和动作 LoRA,从用户提供的图像和视频中捕捉个性化内容,并通过一种与外观无关的动作学习方法,将动作模式从视觉外观中解耦。此外,我们设计了一种时空组合方案,用于在期望动作模式下引导主体之间的交互。大量实验表明,VideoMage 优于现有方法,能够生成连贯的、用户可控的视频,并保持主体身份与交互的一致性。
1. Introduction
近年来,扩散模型 17, 37, 38 取得了前所未有的成功,大大提升了从文本描述生成照片级真实感视频 3, 16, 18, 19, 35 的能力,使视频内容创作有了新的可能性。然而,尽管现在可以合成高质量和多样化的视频,仅依靠文本描述无法对所需内容进行精确控制,难以与用户意图准确对齐 24。因此,从用户提供的参考资料中定制用户特定的视频概念,受到了学术界和工业界的广泛关注。
为了解决这一挑战,一些工作 14, 24, 43, 44 探索了将所需主体身份定制到合成视频中的方法。例如,AnimateDiff 14 通过在预训练图像扩散模型中插入时间模块并对其进行调优,使用户提供的主体实现动画化。VideoBooth 24 进一步采用跨帧注意力机制来保留定制主体的细粒度视觉外观。此外,CustomVideo 43 在所有涉及的主体上同时微调跨注意力层,以在一个场景中定制多个主体。然而,这些方法仅关注静态主体的定制。它们无法为用户或视频创作者提供将所需动态动作(如特定舞蹈风格)个性化到输出视频中的能力,严重限制了视频内容定制的灵活性。
另一方面,为了赋予用户对动态动作的可控性,近期一些方法 23, 28, 32, 48, 51 设计了模块来捕捉来自参考视频的动作模式。例如,Customize-A-Video 32 在时间注意力层中插入低秩适配(LoRA)21 并对其进行微调,以学习所需的动作模式。类似地,MotionDirector 51 通过使用一个捕捉锚帧与其他帧差异的目标,利用 LoRA 来学习动作。然而,仅仅调优时间模块而没有正确地从参考视频中解耦动作信息,会导致严重的外观泄漏问题,进而产生的动作模式无法应用于任意主体身份。此外,在缺乏对主体和动作组合的引导下,模型难以精确控制这些定制视频概念之间的交互。因此,上述方法只能处理单一(即主体或动作)的概念定制。通过自由形式的提示同时定制多个主体和所需动作模式,仍然是一个具有挑战性且尚未解决的问题。
在本文中,我们提出了 VideoMage,一个统一的视频内容定制框架,它能够对主体身份和动作模式实现可控性。VideoMage 引入了主体和动作 LoRA,从用户提供的图像和视频中捕捉各自的信息。为确保动作 LoRA 不会被视觉外观污染,我们提出了一种与外观无关的动作学习方法,从参考视频中分离动作模式。更具体地说,我们采用了基于视觉外观的负向无分类器引导 12, 22,有效地将动作与外观细节解耦。通过学习到的主体和动作 LoRA,我们提出了一种时空协同组合机制,以引导多个主体在所需动作模式下的交互。我们进一步引入基于梯度的融合和空间注意力正则化,以吸收多主体信息,同时鼓励主体的空间排列保持区分性。通过迭代地使用主体和动作 LoRA 引导生成过程,VideoMage 合成的视频具有更强的用户可控性和时空一致性。
我们在此总结本文的贡献如下:
- 我们提出了 VideoMage,一个统一的框架,首次实现了多主体身份及其交互动作的视频概念定制。
- 我们引入了一种新颖的与外观无关的动作学习方法,通过改进的负向无分类器引导,将潜在动作模式与外观解耦。
- 我们提出了一种时空协同组合机制,用于组合获得的多主体和动作 LoRA,以在所需动作模式下生成一致的多主体交互。
2. Related Works
2.1. Text-to-Video Generation
近年来,文本生成视频取得了显著进展。其方法从早期基于生成对抗网络(GANs)34, 36, 40, 41 和自回归 Transformer 20, 45, 46, 49,发展到近期的扩散模型 3, 7, 18, 19, 35, 42,大大提升了生成视频的质量与多样性。开创性工作如 VDM 19 和 Imagen-Video 18 在像素空间中建模视频扩散过程,而 LVDM 16 和 VideoLDM 3 则在潜在空间中建模,以优化计算效率。为了解决缺乏配对视频-文本数据的挑战,Make-A-Video 35 利用图生文先验实现了文本生成视频。另一方面,开源模型如 VideoCrafter 7、ModelScopeT2V 42 和 Zero-Scope 39 融入了时空模块以增强文本生成视频的能力,展现出生成高保真视频的显著性能。这些强大的文本到视频扩散模型推动了定制化内容生成的发展。
2.2. Video Content Customization
主体定制。近年来,定制化生成受到了广泛关注,尤其是在图像合成领域 11, 26, 33。基于这些进展,近期的研究逐渐聚焦于视频主体定制 6, 8, 14, 24, 43, 44,这更具挑战性,因为需要在动态场景中生成主体。例如,AnimateDiff 14 在预训练的图像扩散模型中插入了额外的动作模块,使得自定义主体能够实现动画化。此外,VideoBooth 24 采用跨帧注意力机制来保留定制主体的细粒度视觉外观。最近,CustomVideo 43 在所有相关主体上微调跨注意力层,以实现多主体定制。然而,这些方法往往只能产生轻微的主体动作 44, 47,缺乏用户可控性,无法实现对动作的精确控制。
动作定制。给定少量描述目标动作模式的参考视频,动作定制 23, 28, 32, 44, 48, 51 旨在生成能够复现目标动作的视频。例如,Customize-A-Video 32 在时间注意力层中集成低秩适配(LoRA)21 并对其进行微调,以从参考视频中捕捉特定的动作模式。类似地,MotionDirector 51 通过微调 LoRA 来学习动作,其方法是捕捉锚帧与其他帧之间的差异,从而有效地将动态行为迁移到生成的视频内容中。最新的研究 DreamVideo 44 探索了单一主体执行特定动作的定制化,其方法是分别在空间层和时间层中加入身份适配器(ID adapter)和动作适配器(motion adapter)。然而,外观泄漏问题以及缺乏对主体与动作组合的合理引导,阻碍了这些方法生成多主体交互的视频。因此,利用任意主体和动作模式定制视频内容的灵活性受到严格限制。为赋予用户对主体与动作视频概念更强的可控性,我们采用了独特的 VideoMage 框架,以实现多个定制主体身份之间的所需交互。
3. Method
问题表述。我们首先定义设置和符号。给定 N N N个主体,每个主体由3-5张图像表示,记作 x s , i x_{s,i} xs,i表示第 i i i个主体(为简化省略单个图像索引),一个参考交互动作视频 x m x_m xm,以及用户提供的文本提示 c t g t c_{tgt} ctgt,我们的目标是基于 c t g t c_{tgt} ctgt生成一个视频,其中这 N N N个主体按照动作模式进行交互。为了解决上述问题,我们提出了VideoMage,这是一个统一框架,用于定制多个主体和交互动作的文本生成视频。通过对视频扩散模型的快速回顾(第3.1节),我们详细说明了如何利用LoRA模块分别从输入图像和参考视频中学习视觉和动作信息(第3.2节)。不同于简单的组合方式,我们提出了一种独特的时空协同组合机制,用于整合学习到的主体/动作LoRA以进行视频生成(第3.3节)。
3.1. Preliminary: Video Diffusion Models
视频扩散模型(VDMs)3, 16, 18, 19, 35 旨在通过逐步去噪从高斯分布采样的一系列噪声来生成视频 17。具体而言,扩散模型 ϵ θ \epsilon_\theta ϵθ学习在每个时间步 t t t预测噪声 ϵ \epsilon ϵ,其条件是输入 c c c,而 c c c是在文本生成视频中的文本提示。训练目标简化为一个重建损失:
L = E x , ϵ , t ∥ ϵ θ ( x t , c , t ) − ϵ ∥ 2 2 , (1) \mathcal{L} = \mathbb{E}_{x,\epsilon,t} \left \\left\\\| \\epsilon_\\theta(x_t, c, t) - \\epsilon \\right\\\|_2\^2 \\right, \tag{1} L=Ex,ϵ,t∥ϵθ(xt,c,t)−ϵ∥22,(1)
其中噪声 ϵ ∈ R F × H × W × 3 \epsilon \in \mathbb{R}^{F \times H \times W \times 3} ϵ∈RF×H×W×3从 N ( 0 , I ) \mathcal{N}(0,I) N(0,I)中采样,时间步 t ∈ U ( 0 , 1 ) t \in \mathcal{U}(0,1) t∈U(0,1),并且 x t = α ˉ t x + 1 − α ˉ t ϵ x_t = \sqrt{\bar{\alpha}_t}x + \sqrt{1-\bar{\alpha}_t}\epsilon xt=αˉt x+1−αˉt ϵ
是 t t t时刻的带噪输入, α ˉ t \bar{\alpha}_t αˉt是控制扩散过程的一个超参数 17。为了降低计算成本,大多数VDMs 7, 16, 42 将输入视频数据 x ∈ R F × H × W × 3 x \in \mathbb{R}^{F \times H \times W \times 3} x∈RF×H×W×3 编码为潜在表示(例如,通过VAE 25 获得)。为简化起见,本文始终使用视频数据 x x x作为模型的输入。
3.2. Subject and Motion Customization
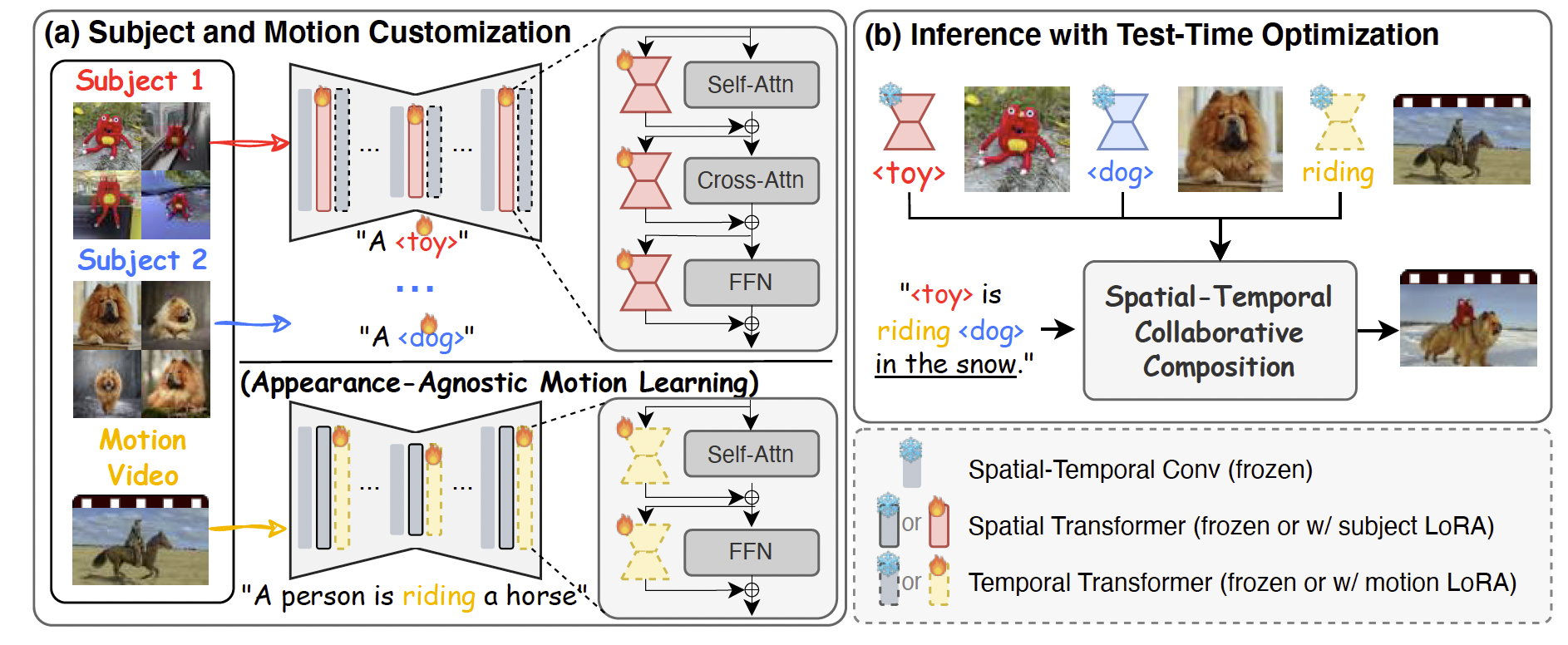
图2. VideoMage 概览。(a) 给定多个主体的图像和一个包含期望动作的参考视频,VideoMage 分别利用 LoRA 来捕捉视觉外观知识和与外观无关的动作信息。(b) 在包含上述视觉与动作概念的文本提示下,我们的时空协同组合机制对输入的带噪潜变量 x t x_t xt进行优化,从而生成匹配期望视觉与动作信息的视频。
视觉主体的学习。如图2(a)顶部所示,为了在视频生成中捕捉主体外观,我们学习一个特殊的token(例如,"<toy>"),并使用主体LoRA( Δ θ s \Delta \theta_s Δθs)对预训练视频扩散模型进行微调。为了避免干扰时间动态,主体LoRA仅应用于UNet的空间层。其目标函数定义为:
L s u b = E x s , ϵ , t ∥ ϵ θ s ( x s , t , c s , t ) − ϵ ∥ 2 2 , (2) \mathcal{L}{sub} = \mathbb{E}{x_s,\epsilon,t} \left \\left\\\| \\epsilon_{\\theta_s}(x_s,t,c_s,t) - \\epsilon \\right\\\|_2\^2 \\right, \tag{2} Lsub=Exs,ϵ,t∥ϵθs(xs,t,cs,t)−ϵ∥22,(2)
其中 x s ∈ R 1 × H × W × 3 x_s \in \mathbb{R}^{1 \times H \times W \times 3} xs∈R1×H×W×3是主体图像, θ s = θ + Δ θ s \theta_s = \theta + \Delta \theta_s θs=θ+Δθs表示施加了主体LoRA的预训练模型参数, c s c_s cs是包含特殊token的提示(例如,"A ")。
然而,仅使用图像数据进行微调可能导致视频扩散模型丧失生成运动信息的能力。参考47,我们利用一个辅助视频数据集 D a u x D_{aux} Daux(例如,Panda70M 9)来正则化微调过程,同时保留预训练的动作先验。更具体地,给定从 D a u x D_{aux} Daux中采样的视频-字幕对 ( x a u x , c a u x ) (x_{aux}, c_{aux}) (xaux,caux),其正则化损失定义为:
L r e g = E x a u x , ϵ , t ∥ ϵ θ s ( x a u x , t , c a u x , t ) − ϵ ∥ 2 2 . (3) \mathcal{L}{reg} = \mathbb{E}{x_{aux},\epsilon,t} \left \\left\\\| \\epsilon_{\\theta_s}(x_{aux}, t, c_{aux}, t) - \\epsilon \\right\\\|_2\^2 \\right. \tag{3} Lreg=Exaux,ϵ,t∥ϵθs(xaux,t,caux,t)−ϵ∥22.(3)
因此,总体目标函数定义为:
L = L s u b + λ 1 L r e g , (4) \mathcal{L} = \mathcal{L}{sub} + \lambda_1 \mathcal{L}{reg}, \tag{4} L=Lsub+λ1Lreg,(4)
其中 λ 1 \lambda_1 λ1是控制正则化损失权重的超参数。优化该目标能够捕捉主体外观,同时保留动作先验。通过我们的训练目标,我们能够在不损害VDM能力的情况下,支持用户提供的主体身份的定制。然而,微调后的VDM在从参考视频中精确控制动作模式方面仍具有挑战性,从而限制了用户的灵活性与可控性。
与外观无关的动作学习。为了从参考视频 x m x_m xm中学习期望的动作模式,一个朴素的策略是微调动作LoRA,并将其注入UNet的时间层(即图2(a)底部的 Δ θ m \Delta \theta_m Δθm)。然而,直接应用公式(1)中的标准扩散损失会导致外观泄漏问题,即动作LoRA无意中捕捉到了参考视频中主体的外观。这种主体外观与动作的纠缠阻碍了将学习到的动作模式应用到新主体的能力。
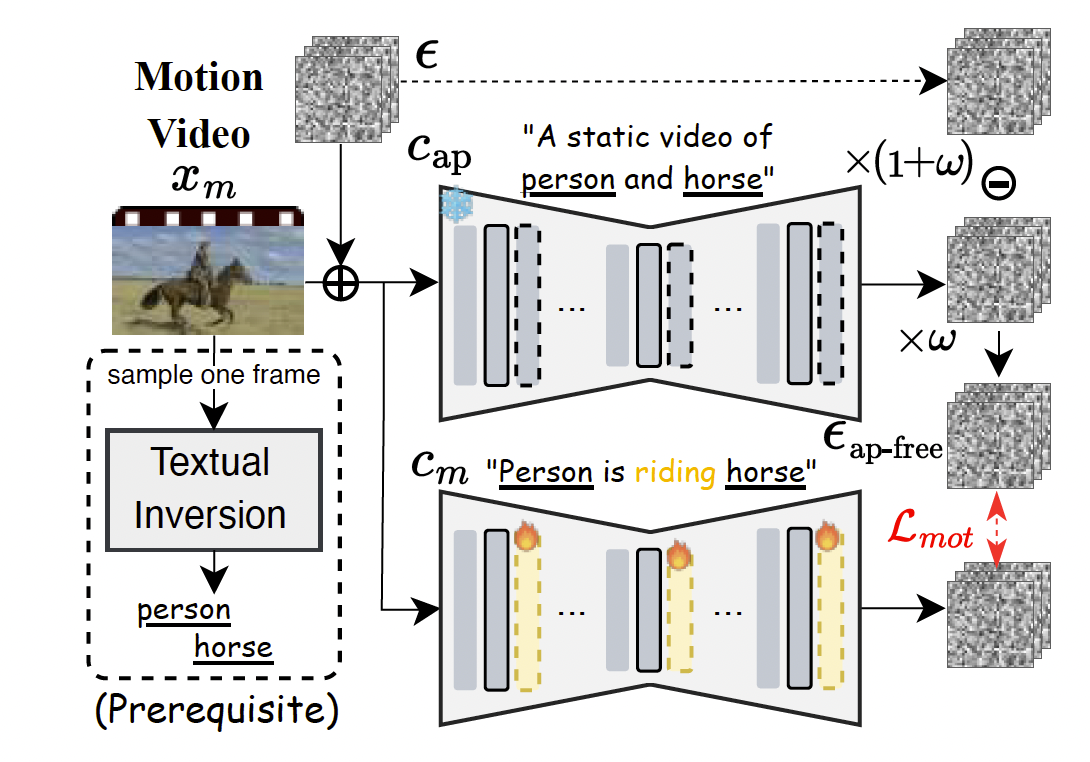
图3. 与外观无关的动作学习。通过利用强调外观信息的文本提示(即 c a p c_{ap} cap),我们旨在通过所提出的负向无分类器引导提取与外观无关的动作信息。
为了解决这一问题,我们提出了一种新颖的与外观无关的目标(appearance-agnostic objective),如图3所示,它能够有效地将参考视频中的动作模式与外观隔离。受到概念擦除方法12, 22的启发,我们提出了基于视觉主体外观的负向无分类器引导(negative classifier-free guidance),专注于在动作学习过程中消除外观信息。这确保了动作LoRA仅专注于动作动态。
为实现这一点,我们首先为参考视频中的主体学习特殊token(例如图3中的"person"和"horse"),方法是在参考视频的一帧上应用文本反演11。这能够捕捉主体外观,同时最小化动作的影响,有效地实现外观与动作的解耦。在获得上述特殊token后,我们训练动作LoRA,使用一个与外观无关的目标函数,该目标通过负向引导抑制外观信息,使动作LoRA能够独立于主体外观学习动作模式。更具体地,训练目标定义为:
L m o t = E x m , ϵ , t ∥ ϵ θ m ( x m , t , c m , t ) − ϵ ap-free ∥ 2 2 , \mathcal{L}{mot} = \mathbb{E}{x_m,\epsilon,t} \left \\left\\\| \\epsilon_{\\theta_m}(x_m,t,c_m,t) - \\epsilon_{\\text{ap-free}} \\right\\\|_2\^2 \\right, Lmot=Exm,ϵ,t∥ϵθm(xm,t,cm,t)−ϵap-free∥22,
其中
ϵ ap-free = ( 1 + ω ) ϵ − ω ϵ θ ( x m , t , c a p , t ) . (5) \epsilon_{\text{ap-free}} = (1+\omega)\epsilon - \omega \epsilon_\theta(x_m,t,c_{ap},t). \tag{5} ϵap-free=(1+ω)ϵ−ωϵθ(xm,t,cap,t).(5)
注意, ϵ ap-free \epsilon_{\text{ap-free}} ϵap-free是经过负向引导的无外观噪声, ω \omega ω是控制引导强度的超参数, c m c_m cm和 c a p c_{ap} cap分别描述动作和静态主体外观(例如,"Person riding a horse"和"A static video of person and horse")。
通过优化公式(5),动作LoRA能够独立于主体外观学习动作模式。这种解耦对于在多个主体之间组合定制动作至关重要,我们将在后文进一步讨论。
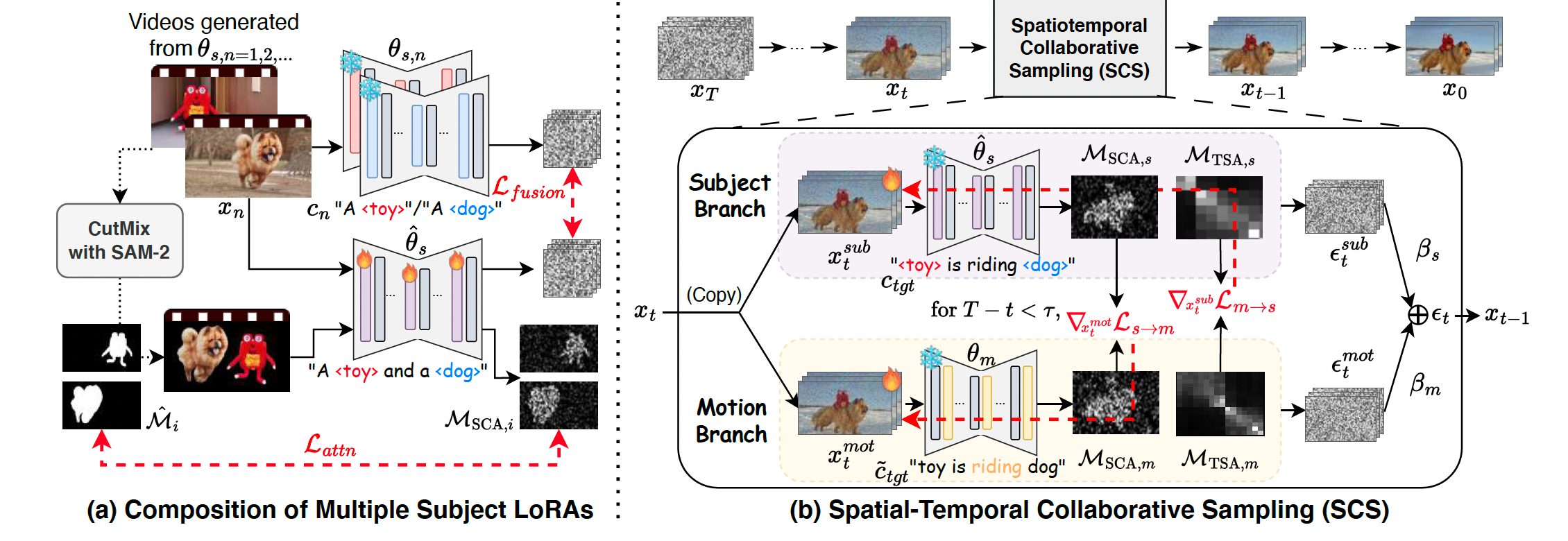
图4. 用于T2V测试时优化的时空协同组合。(a) 测试时融合主体LoRA θ ^ s \hat{\theta}s θ^s,其采用注意力正则化 L a t t n \mathcal{L}{attn} Lattn以确保每个视觉主体的外观得以保留。(b) 时空协同采样(SCS)通过跨模态对齐,将融合的主体LoRA θ ^ s \hat{\theta}_s θ^s与动作LoRA θ m \theta_m θm进行整合,从而确保视觉与时间上的一致性。
3.3. Spatial-Temporal Collaborative Composition
在获得多个主体LoRA和一个交互式动作LoRA之后,我们的目标是生成这些主体按照期望动作模式进行交互的视频。然而,结合具有不同属性(即视觉外观与时空动作)的LoRA并非一项简单的任务。在本工作中,我们提出了一种测试时优化方案------时空协同组合(spatial-temporal collaborative composition),该方案能够使上述LoRA之间进行协作,从而生成同时具备期望外观和动作特性的视频。下面我们将详细讨论所提出的方案。
多主体LoRA的组合。我们首先讨论如何融合描述不同视觉主体信息的LoRA。我们采用基于梯度的融合方法 13,将每个主体LoRA中的独特身份特征提炼为一个单一的融合LoRA。即,给定多个LoRA,记作 Δ θ s , 1 , Δ θ s , 2 , ... , Δ θ s , N \Delta \theta_{s,1}, \Delta \theta_{s,2}, \ldots, \Delta \theta_{s,N} Δθs,1,Δθs,2,...,Δθs,N,其中 N N N是主体数量,每个LoRA对应一个特定主体,我们的目标是学习一个融合LoRA Δ θ ^ s \Delta \hat{\theta}_s Δθ^s,能够生成包含多个主体的视频。
为实现这一点,我们希望强制融合后的LoRA Δ θ ^ s \Delta \hat{\theta}_s Δθ^s 能够生成与每个特定主体LoRA一致的视频。更具体地,我们通过匹配融合LoRA与特定LoRA的预测噪声来优化 Δ θ ^ s \Delta \hat{\theta}s Δθ^s。多主体融合的目标函数 L f u s i o n \mathcal{L}{fusion} Lfusion定义为:
L f u s i o n = 1 N ∑ n = 1 N E x n , ϵ , t ∥ ϵ θ \^ s ( x n , t , c n , t ) − ϵ n ∥ 2 2 , (6) \mathcal{L}{fusion} = \frac{1}{N} \sum{n=1}^{N} \mathbb{E}_{x_n,\epsilon,t} \left \\left\\\| \\epsilon_{\\hat{\\theta}_s}(x_n,t,c_n,t) - \\epsilon_n \\right\\\|_2\^2 \\right, \tag{6} Lfusion=N1n=1∑NExn,ϵ,t ϵθ\^s(xn,t,cn,t)−ϵn 22,(6)
其中 ϵ n = ϵ θ s , n ( x n , t , c n , t ) \epsilon_n = \epsilon_{\theta_{s,n}}(x_n,t,c_n,t) ϵn=ϵθs,n(xn,t,cn,t), x n x_n xn是由 θ s , n \theta_{s,n} θs,n生成的视频, c n c_n cn是对应第 n n n个主体的提示。
此外,为了鼓励不同主体身份合理排列,我们进一步引入空间注意力正则化(spatial attention regularization) L a t t n \mathcal{L}{attn} Lattn,以明确引导模型关注正确的主体区域。具体来说,如图4(a)所示,我们随机采样并使用Grounded-SAM2 30, 31分割两个主体,然后将分割结果组合为CutMix风格 15, 50的视频。我们正式定义 L a t t n \mathcal{L}{attn} Lattn如下:
L a t t n = 1 2 ∑ i = 1 2 ∥ M S C A , i − M ^ i ∥ 2 2 , (7) \mathcal{L}{attn} = \frac{1}{2} \sum{i=1}^{2} \left\| \mathcal{M}_{SCA,i} - \hat{M}_i \right\|_2^2, \tag{7} Lattn=21i=1∑2 MSCA,i−M^i 22,(7)
其中 M S C A , i \mathcal{M}_{SCA,i} MSCA,i是第 i i i个采样主体的空间交叉注意力图, M ^ i \hat{M}_i M^i是对应的真实分割掩码。因此,多主体LoRA的最终目标函数定义为:
L = L f u s i o n + λ 2 L a t t n , (8) \mathcal{L} = \mathcal{L}{fusion} + \lambda_2 \mathcal{L}{attn}, \tag{8} L=Lfusion+λ2Lattn,(8)
其中 λ 2 \lambda_2 λ2控制注意力损失的权重。需要注意的是,我们仅在一次训练中融合多个主体。一旦获得融合LoRA θ ^ s \hat{\theta}_s θ^s,我们即可生成具有任意动作模式的视频。
时空协同采样(SCS)。为了进一步将基于动作的LoRA Δ θ m \Delta \theta_m Δθm 与前述融合后的视觉主体LoRA Δ θ ^ s \Delta \hat{\theta}_s Δθ^s 结合,我们提出了一种新颖的时空协同采样(spatial-temporal collaborative sampling, SCS)方法,以有效控制和引导多个定制主体的交互。在SCS中,我们分别从主体分支和动作分支中独立采样并整合噪声。为鼓励早期时间步的对齐,我们引入了一种协作引导机制,使两个分支的空间与时间注意力图相互细化输入潜变量。这种互相对齐使定制主体及其交互更为一致。
如图4(b)所示,给定带噪输入视频 x t x_t xt,我们将其复制为 x t s u b x_t^{sub} xtsub和 x t m o t x_t^{mot} xtmot,分别送入主体分支和动作分支。在融合主体LoRA模型 θ ^ s \hat{\theta}_s θ^s和动作LoRA模型 θ m \theta_m θm的条件下,我们生成主体噪声 ϵ t s u b \epsilon_t^{sub} ϵtsub和动作噪声 ϵ t m o t \epsilon_t^{mot} ϵtmot:
ϵ t s u b = ϵ θ ^ s ( x t s u b , c t g t , t ) , ϵ t m o t = ϵ θ m ( x t m o t , c ~ t g t , t ) , (9) \epsilon_t^{sub} = \epsilon_{\hat{\theta}s}(x_t^{sub}, c{tgt}, t), \\ \epsilon_t^{mot} = \epsilon_{\theta_m}(x_t^{mot}, \tilde{c}_{tgt}, t), \tag{9} ϵtsub=ϵθ^s(xtsub,ctgt,t),ϵtmot=ϵθm(xtmot,c~tgt,t),(9)
其中 c t g t c_{tgt} ctgt是包含主体特殊token的输入提示(例如"A is riding a "),而 c ~ t g t \tilde{c}_{tgt} c~tgt则通过将特殊token替换为对应类别构造(例如"A toy is riding a dog")。
然而,主体分支(仅含主体LoRA)会生成错误的动作,动作分支(仅含动作LoRA)会产生不准确的空间排列,直接结合 ϵ t s u b \epsilon_t^{sub} ϵtsub和 ϵ t m o t \epsilon_t^{mot} ϵtmot可能导致信息不完整。为此,我们鼓励 θ ^ s \hat{\theta}s θ^s和 θ m \theta_m θm之间的对齐,以生成一致的噪声输出。具体来说,如图4(b)所示,我们考虑主体空间排列的空间交叉注意力图 M S C A \mathcal{M}{SCA} MSCA,以及捕捉动作动态的时间自注意力图 M T S A \mathcal{M}_{TSA} MTSA。相应的协作引导损失为:
L s → m = ∥ M S C A , s − M S C A , m ∥ 2 2 , L m → s = ∥ M T S A , s − M T S A , m ∥ 2 2 , (10) \mathcal{L}{s \to m} = \left\| \mathcal{M}{SCA,s} - \mathcal{M}{SCA,m} \right\|2^2, \\ \mathcal{L}{m \to s} = \left\| \mathcal{M}{TSA,s} - \mathcal{M}_{TSA,m} \right\|_2^2, \tag{10} Ls→m=∥MSCA,s−MSCA,m∥22,Lm→s=∥MTSA,s−MTSA,m∥22,(10)
其中下标 s s s与 m m m分别表示来自主体分支和动作分支。
随后,我们更新 x t s u b x_t^{sub} xtsub和 x t m o t x_t^{mot} xtmot:
x t s u b : = x t s u b − α t ∇ x t s u b L m → s , x t m o t : = x t m o t − α t ∇ x t m o t L s → m , (11) x_t^{sub} := x_t^{sub} - \alpha_t \nabla_{x_t^{sub}} \mathcal{L}{m \to s}, \\ x_t^{mot} := x_t^{mot} - \alpha_t \nabla{x_t^{mot}} \mathcal{L}_{s \to m}, \tag{11} xtsub:=xtsub−αt∇xtsubLm→s,xtmot:=xtmot−αt∇xtmotLs→m,(11)
其中 α t \alpha_t αt是梯度更新的步长,该引导在前 τ \tau τ个去噪步骤中应用, τ \tau τ是超参数。最后,预测噪声由下式计算:
ϵ t = β s ϵ t s u b + β m ϵ t m o t , (12) \epsilon_t = \beta_s \epsilon_t^{sub} + \beta_m \epsilon_t^{mot}, \tag{12} ϵt=βsϵtsub+βmϵtmot,(12)
其中我们设定 β s = β m = 0.5 \beta_s = \beta_m = 0.5 βs=βm=0.5以简化计算。更多细节见附录中的算法1。