背景:一个普通的下午,CPU爆了
下午 3 点,团队同学反馈线上新上的服务器没跑几天CPU突然炸了
node_exporter 进程 CPU 占用率接近 70%,重启node_exporter就好了,隔几个小时就又出现了。
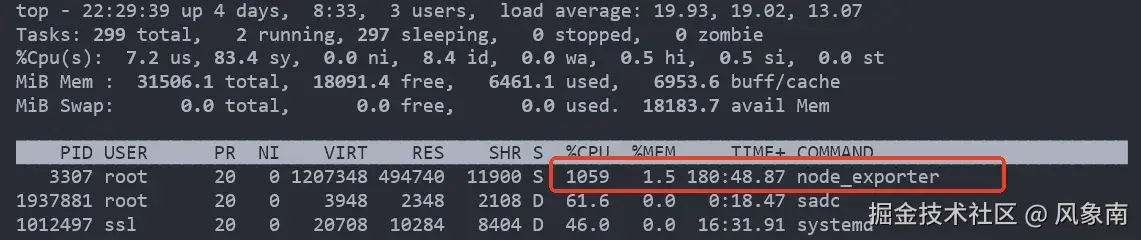
立马连上服务器检查了node_exporter日志及系统日志没有发现明显的错误日志。
好在新服务没有切多少流量过来,可以基于线上环境进行一定的排查分析。
初步分析:确定问题方向
首先需要确定的是node_exporter在执行什么或者调用什么函数。
于是用 perf top --pid xx 命令一查node_exporter进程,发现 CPU 热点全在内核函数上:
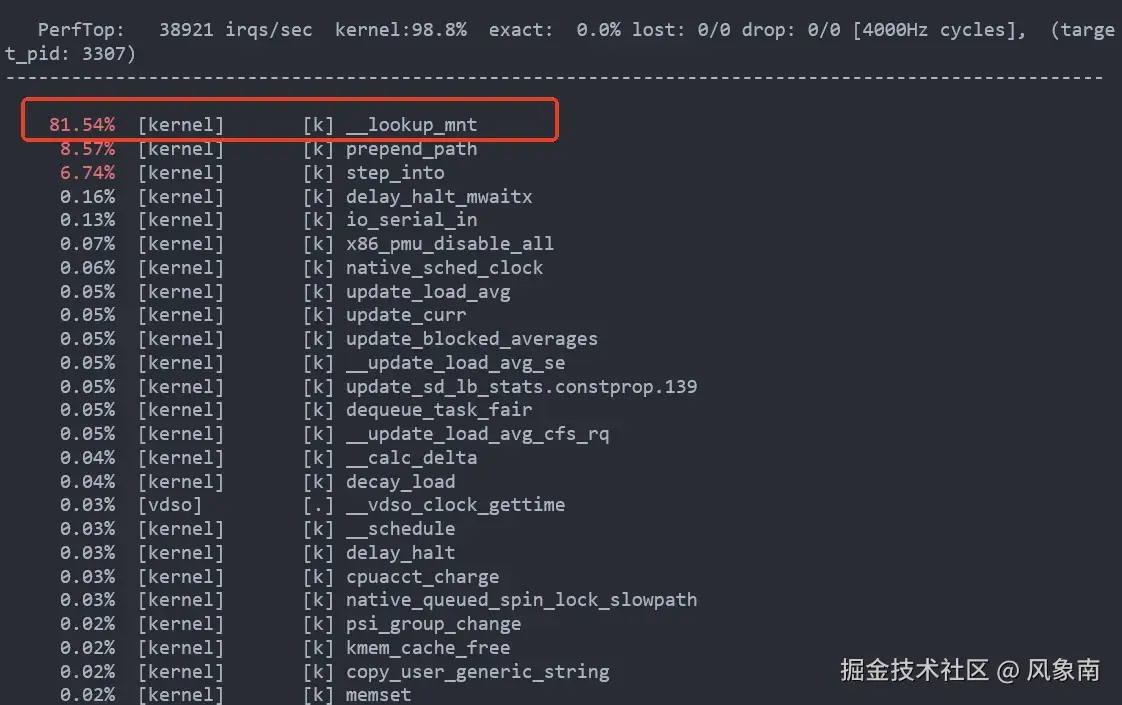
这明显不正常,一个监控进程就采集下机器的资源信息怎么会把 CPU 吃这么狠?
然后看CPU占用最高的那个函数,从字面意思大概可以理解这是扫描挂载点的函数
随即执行 cat /proc/mounts查询挂载表,但是查询到的挂载并不多。
好奇怪,难道是node_exporter的BUG ?
于是去github查了node_exporter的ISSUE记录,发现没有类似的问题。
问题定位:mount 表在疯狂增长
于是进一步查看node_exporter进程的 mount 表:
bash
cat /proc/{pid}/mountinfo | wc -l
咦,看起来好像有点多,为了进一步确认又找了一台相同版本相同配置的服务器连上去看

发现正常服务的挂载点数量远远小于出问题的服务器
于是又继续观察问题服务器的mount 表,发现每隔几分钟都会有接近 50个左右的增长。
接着查看挂载表明细,看看都挂载了什么内容,怎么会有4w多个,于是得到下面的结果。
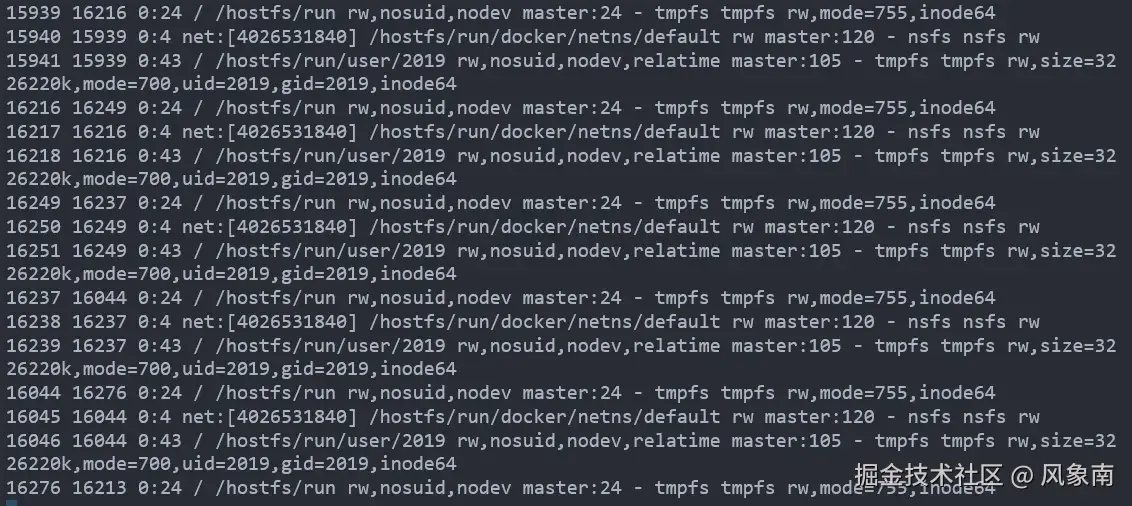
大量的 /hostfs/run 挂载,这是哪里来的,容器本身也没配置类似的挂载路径,于是将上面的信息交给AI进行分析,最终AI的结果也没太多有效信息,但是AI的回答里面有一个关键字给了我提醒,就是"运行时"。

我基本上可以确定的是,容器初始化是正常的,一定是容器启动后有一些什么程序在执行或者触发挂载操作。
根因分析:docker cp 产生的挂载
这时就回归分析当前这个问题服务器与正常运行服务器上的程序存在什么差异,是否存在什么改动。
于是乎想到上线前客户提了一个需求,要求通过snmp的方式提供业务运行指标,当时是拿了一台进行测试验证。
经多方确认,发现就是当前出问题这一台。
立即找到开发对接的同学,了解做了什么内容更新。
最终,知道了该同学提供了几个snmp shell采集脚本,并通过定时器定期将外部的脚本拷贝进容器(为了防止容器DOWN -> UP 后脚本丢失),利用容器内的snmp进程对外吐指标。
于是,我分析了脚本发现也没什么特别的,也没有对容器进行配置修改之类的操作,唯一看到的就是10多次的docker cp 操作。
不会是 docker cp 的问题吧,于是我执行了一行测试命令
bash
docker cp 1.txt myapp:/tmp此处省略两个字,每执行一次 docker cp,/proc/{pid}/mountinfo 就新增几条 /hostfs/run 的挂载记录。
于是又执行了一下开发同学提供的脚本,果然,执行一次,挂载表增加了 51 条记录。
至此,问题原因找到了,可是为什么docker cp 会触发挂载,不应该是一次简单的拷贝操作么。
技术原理:docker cp 为什么会出现 mount ?
于是将这个问题丢给了AI,得到以下结果

最佳实践:如需频繁拷贝文件避免使用 docker cp
如需大量进行宿主机与容器之间的文件拷贝,最好的办法是避免频繁使用 docker cp,改用更优雅的文件传输方式:
bash
# 宿主机 → 容器
tar -C ./ -cf - 1.txt | docker exec -i myapp tar -C /tmp -xf -
# 容器 → 宿主机
docker exec -i myapp tar -C /app -cf - data | tar -C /host/dest -xf -这种方式全程无额外挂载,不会导致 mountinfo 膨胀。