在mongodb中,deleteOne和deleteMany是两种不同的删除操作,主要区别在于删除的文档数量和操作行为,deleteOne删除第一个匹配查询条件的文档(即使有多个文档匹配,也只删一个),deleteMany()功能:删除所有匹配查询条件的文档。
db.user.deleteOne({ "age" : 2828})的explain()输出结果如下,deleteOne执行的策略是DELETE>FETCH>IXSCAN,先按照FETCH>IXSCAN读取数据,再根据DELETE删除。
命令deleteOne类是mongo/db/ops/write_ops_exec.cpp中,performSingleDeleteOp是该接口最核心:(1)获取delete执行器并运行getExecutorDelete,db.user.deleteOne({ "age" : 2828}),deleteOne执行的策略是DELETE>FETCH>IXSCAN,前面文章已经解析这个步骤。
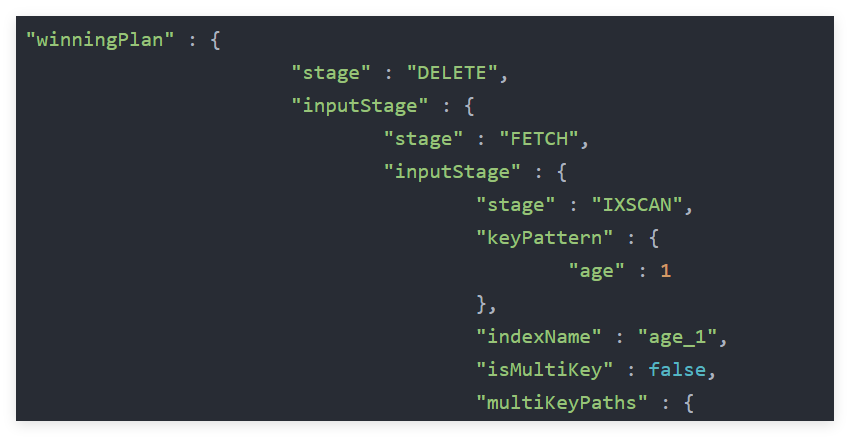
(2)执行删除动作exec->executePlan(),先按照FETCH>IXSCAN读取数据,再根据DELETE删除。
策略DELETE>FETCH>IXSCAN分别对应文件mongo/db/exec/delete.cpp,mongo/db/exec/fetch.cpp,mongo/db/exec/index_scan.cpp。
mongo/db/exec/delete.cpp构建DeleteStage策略如下:
cpp
const char* DeleteStage::kStageType = "DELETE";
DeleteStage::DeleteStage(OperationContext* opCtx,
std::unique_ptr<DeleteStageParams> params,
WorkingSet* ws,
Collection* collection,
PlanStage* child)
: RequiresMutableCollectionStage(kStageType, opCtx, collection),
_params(std::move(params)),
_ws(ws),
_idRetrying(WorkingSet::INVALID_ID),
_idReturning(WorkingSet::INVALID_ID) {
_children.emplace_back(child);
}mongo/db/exec/fetch.cpp构建FetchStage策略如下:
cpp
// static
const char* FetchStage::kStageType = "FETCH";
FetchStage::FetchStage(OperationContext* opCtx,
WorkingSet* ws,
std::unique_ptr<PlanStage> child,
const MatchExpression* filter,
const Collection* collection)
: RequiresCollectionStage(kStageType, opCtx, collection),
_ws(ws),
_filter(filter),
_idRetrying(WorkingSet::INVALID_ID) {
_children.emplace_back(std::move(child));
}mongo/db/exec/index_scan.cpp构建策略如下:
cpp
const char* IndexScan::kStageType = "IXSCAN";
IndexScan::IndexScan(OperationContext* opCtx,
IndexScanParams params,
WorkingSet* workingSet,
const MatchExpression* filter)
: RequiresIndexStage(kStageType, opCtx, params.indexDescriptor, workingSet),
_workingSet(workingSet),
_keyPattern(params.keyPattern.getOwned()),
_bounds(std::move(params.bounds)),
_filter(filter),
_direction(params.direction),
_forward(params.direction == 1),
_shouldDedup(params.shouldDedup),
_addKeyMetadata(params.addKeyMetadata),
_startKeyInclusive(IndexBounds::isStartIncludedInBound(params.bounds.boundInclusion)),
_endKeyInclusive(IndexBounds::isEndIncludedInBound(params.bounds.boundInclusion)) {
_specificStats.indexName = params.name;
_specificStats.keyPattern = _keyPattern;
_specificStats.isMultiKey = params.isMultiKey;
_specificStats.multiKeyPaths = params.multikeyPaths;
_specificStats.isUnique = params.indexDescriptor->unique();
_specificStats.isSparse = params.indexDescriptor->isSparse();
_specificStats.isPartial = params.indexDescriptor->isPartial();
_specificStats.indexVersion = static_cast<int>(params.indexDescriptor->version());
_specificStats.collation = params.indexDescriptor->infoObj()
.getObjectField(IndexDescriptor::kCollationFieldName)
.getOwned();
}MongoDB分析delete源代码核心调用链如下
- mongo/db/commands/write_commands/write_commands.cpp的CmdDelete类
- mongo/db/commands/write_commands/write_commands.cpp的CmdDelete:runImpl
- mongo/db/ops/write_ops_exec.cpp中的performDeletes
- mongo/db/ops/write_ops_exec.cpp中的performSingleDeleteOp
- mongo/db/ops/write_ops_exec.cpp中的getExecutorDelete
- mongo/db/query/get_executor.cpp中的getExecutorDelete,返回<PlanExecutor, PlanExecutor::Deleter>
- mongo/db/query/get_executor.cpp中的prepareExecution,返回PrepareExecutionResult
- mongo/db/query/query_planner.cpp中的QueryPlanner::plan,返回QuerySolution对象
- mongo/db/query/get_executor.cpp中的std::make_unique<DeleteStage>
- mongo/db/query/get_executor.cpp中的PlanExecutor::make,返回<PlanExecutor, PlanExecutor::Deleter
- mongo/db/ops/write_ops_exec.cpp中的exec->executePlan()
- mongo/db/query/plan_executor_impl.cpp中的executePlan
- mongo/db/query/plan_executor_impl.cpp中的getNext
- mongo/db/query/plan_executor_impl.cpp中的_getNextImpl
mongo/db/ops/write_ops_exec.cpp中的getExecutorDelete获取执行器,exec->executePlan()执行删除动作,接上篇文章继续分析。
mongo/db/query/plan_executor_impl.cpp中的executePlan循环调用策略,代码如下:
cpp
Status PlanExecutorImpl::executePlan() {
invariant(_currentState == kUsable);
Document obj;
PlanExecutor::ExecState state = PlanExecutor::ADVANCED;
while (PlanExecutor::ADVANCED == state) {
state = this->getNext(&obj, nullptr);
}
if (PlanExecutor::FAILURE == state) {
if (isMarkedAsKilled()) {
return _killStatus;
}
auto errorStatus = getMemberObjectStatus(obj);
invariant(!errorStatus.isOK());
return errorStatus.withContext(str::stream() << "Exec error resulting in state "
<< PlanExecutor::statestr(state));
}
invariant(!isMarkedAsKilled());
invariant(PlanExecutor::IS_EOF == state);
return Status::OK();
}mongo/db/query/plan_executor_impl.cpp中的getNext
cpp
PlanExecutor::ExecState PlanExecutorImpl::getNext(Document* objOut, RecordId* dlOut) {
Snapshotted<Document> snapshotted;
if (objOut) {
snapshotted.value() = std::move(*objOut);
}
ExecState state = _getNextImpl(objOut ? &snapshotted : nullptr, dlOut);
if (objOut) {
*objOut = std::move(snapshotted.value());
}
return state;
}mongo/db/query/plan_executor_impl.cpp中的_getNextImpl,上面DELETE>FETCH>IXSCAN策略,_root代表DELETE,执行类是mongo/db/exec/delete.cpp
cpp
PlanExecutor::ExecState PlanExecutorImpl::_getNextImpl(Snapshotted<Document>* objOut,
RecordId* dlOut) {
LOG(3) << "conca _getNextImpl " ;
...
for (;;) {
...
WorkingSetID id = WorkingSet::INVALID_ID;
PlanStage::StageState code = _root->work(&id);
LOG(3) << "conca _getNextImpl _root->work(&id),id="<< id ;
if (code != PlanStage::NEED_YIELD)
...
}mongo/db/exec/plan_stage.cpp的work方法代码,work传参返回的工作集合,接受执行结果的指针地址。
cpp
PlanStage::StageState PlanStage::work(WorkingSetID* out) {
invariant(_opCtx);
ScopedTimer timer(getClock(), &_commonStats.executionTimeMillis);
++_commonStats.works;
StageState workResult = doWork(out);
if (StageState::ADVANCED == workResult) {
++_commonStats.advanced;
} else if (StageState::NEED_TIME == workResult) {
++_commonStats.needTime;
} else if (StageState::NEED_YIELD == workResult) {
++_commonStats.needYield;
} else if (StageState::FAILURE == workResult) {
_commonStats.failed = true;
}
return workResult;
}mongo/db/exec/delete.cpp的doWork,这个是DeleteStage获取自己儿子节点FetchStage,执行儿子节点FetchStage,FetchStage的doWork方法继续寻找自己儿子节点IndexScan,继续执行儿子节点IndexScan。
cpp
PlanStage::StageState DeleteStage::doWork(WorkingSetID* out) {
if (isEOF()) {
return PlanStage::IS_EOF;
}
// It is possible that after a delete was executed, a WriteConflictException occurred
// and prevented us from returning ADVANCED with the old version of the document.
if (_idReturning != WorkingSet::INVALID_ID) {
// We should only get here if we were trying to return something before.
invariant(_params->returnDeleted);
WorkingSetMember* member = _ws->get(_idReturning);
invariant(member->getState() == WorkingSetMember::OWNED_OBJ);
*out = _idReturning;
_idReturning = WorkingSet::INVALID_ID;
return PlanStage::ADVANCED;
}
// Either retry the last WSM we worked on or get a new one from our child.
WorkingSetID id;
if (_idRetrying != WorkingSet::INVALID_ID) {
id = _idRetrying;
_idRetrying = WorkingSet::INVALID_ID;
} else {
auto status = child()->work(&id);
switch (status) {
case PlanStage::ADVANCED:
break;
case PlanStage::FAILURE:
// The stage which produces a failure is responsible for allocating a working set
// member with error details.
invariant(WorkingSet::INVALID_ID != id);
*out = id;
return status;
case PlanStage::NEED_TIME:
return status;
case PlanStage::NEED_YIELD:
*out = id;
return status;
case PlanStage::IS_EOF:
return status;
default:
MONGO_UNREACHABLE;
}
}
// We advanced, or are retrying, and id is set to the WSM to work on.
WorkingSetMember* member = _ws->get(id);
// We want to free this member when we return, unless we need to retry deleting or returning it.
auto memberFreer = makeGuard([&] { _ws->free(id); });
invariant(member->hasRecordId());
RecordId recordId = member->recordId;
// Deletes can't have projections. This means that covering analysis will always add
// a fetch. We should always get fetched data, and never just key data.
invariant(member->hasObj());
// Ensure the document still exists and matches the predicate.
bool docStillMatches;
try {
docStillMatches = write_stage_common::ensureStillMatches(
collection(), getOpCtx(), _ws, id, _params->canonicalQuery);
} catch (const WriteConflictException&) {
// There was a problem trying to detect if the document still exists, so retry.
memberFreer.dismiss();
return prepareToRetryWSM(id, out);
}
if (!docStillMatches) {
// Either the document has already been deleted, or it has been updated such that it no
// longer matches the predicate.
if (shouldRestartDeleteIfNoLongerMatches(_params.get())) {
throw WriteConflictException();
}
return PlanStage::NEED_TIME;
}
// Ensure that the BSONObj underlying the WorkingSetMember is owned because saveState() is
// allowed to free the memory.
if (_params->returnDeleted) {
// Save a copy of the document that is about to get deleted, but keep it in the RID_AND_OBJ
// state in case we need to retry deleting it.
member->makeObjOwnedIfNeeded();
}
if (_params->removeSaver) {
uassertStatusOK(_params->removeSaver->goingToDelete(member->doc.value().toBson()));
}
// TODO: Do we want to buffer docs and delete them in a group rather than saving/restoring state
// repeatedly?
try {
child()->saveState();
} catch (const WriteConflictException&) {
std::terminate();
}
// Do the write, unless this is an explain.
if (!_params->isExplain) {
try {
WriteUnitOfWork wunit(getOpCtx());
collection()->deleteDocument(getOpCtx(),
_params->stmtId,
recordId,
_params->opDebug,
_params->fromMigrate,
false,
_params->returnDeleted ? Collection::StoreDeletedDoc::On
: Collection::StoreDeletedDoc::Off);
wunit.commit();
} catch (const WriteConflictException&) {
memberFreer.dismiss(); // Keep this member around so we can retry deleting it.
return prepareToRetryWSM(id, out);
}
}
++_specificStats.docsDeleted;
if (_params->returnDeleted) {
// After deleting the document, the RecordId associated with this member is invalid.
// Remove the 'recordId' from the WorkingSetMember before returning it.
member->recordId = RecordId();
member->transitionToOwnedObj();
}
// As restoreState may restore (recreate) cursors, cursors are tied to the transaction in which
// they are created, and a WriteUnitOfWork is a transaction, make sure to restore the state
// outside of the WriteUnitOfWork.
try {
child()->restoreState();
} catch (const WriteConflictException&) {
// Note we don't need to retry anything in this case since the delete already was committed.
// However, we still need to return the deleted document (if it was requested).
if (_params->returnDeleted) {
// member->obj should refer to the deleted document.
invariant(member->getState() == WorkingSetMember::OWNED_OBJ);
_idReturning = id;
// Keep this member around so that we can return it on the next work() call.
memberFreer.dismiss();
}
*out = WorkingSet::INVALID_ID;
return NEED_YIELD;
}
if (_params->returnDeleted) {
// member->obj should refer to the deleted document.
invariant(member->getState() == WorkingSetMember::OWNED_OBJ);
memberFreer.dismiss(); // Keep this member around so we can return it.
*out = id;
return PlanStage::ADVANCED;
}
return PlanStage::NEED_TIME;
}auto status = child()->work(&id);根据儿子child()节点获取要删除的文档。DELETE的儿子节点是FETCH,FETCH的儿子节点是IXSCAN。DeleteStage获取到Document文档,继续调用collection()->deleteDocument()进行文档删除。具体调用链如下图:
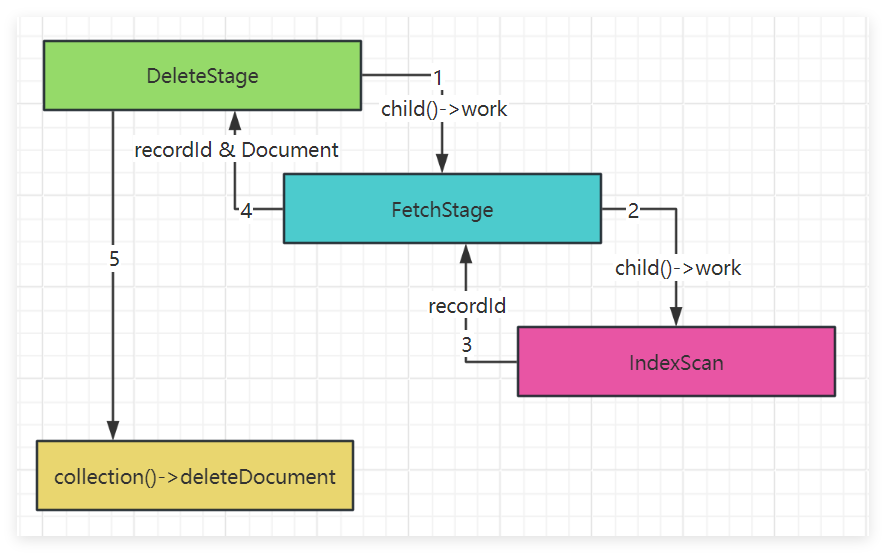
mongo/db/exec/fetch.cpp的doWork方法,FetchStage::doWork 是 MongoDB 查询执行计划中的获取阶段,child()->work(&id)调用儿子节点IXSCAN获取对应文档的$recordId,WorkingSetCommon::fetch(getOpCtx(), _ws, id, _cursor)负责根据索引扫描提供的记录 ID(RecordId)从磁盘或内存中获取完整文档。
cpp
PlanStage::StageState FetchStage::doWork(WorkingSetID* out) {
std::cout << "conca " << " FetchStage doWork..." << std::endl;
if (isEOF()) {
return PlanStage::IS_EOF;
}
// Either retry the last WSM we worked on or get a new one from our child.
WorkingSetID id;
StageState status;
if (_idRetrying == WorkingSet::INVALID_ID) {
status = child()->work(&id);
} else {
status = ADVANCED;
id = _idRetrying;
_idRetrying = WorkingSet::INVALID_ID;
}
std::cout << "conca " << " FetchStage doWork...id="<< id << std::endl;
if (PlanStage::ADVANCED == status) {
WorkingSetMember* member = _ws->get(id);
// If there's an obj there, there is no fetching to perform.
if (member->hasObj()) {
++_specificStats.alreadyHasObj;
} else {
// We need a valid RecordId to fetch from and this is the only state that has one.
verify(WorkingSetMember::RID_AND_IDX == member->getState());
verify(member->hasRecordId());
std::cout << "conca " << " FetchStage doWork...$RecordId="<< member->recordId<< std::endl;
try {
if (!_cursor)
_cursor = collection()->getCursor(getOpCtx());
if (!WorkingSetCommon::fetch(getOpCtx(), _ws, id, _cursor)) {
_ws->free(id);
return NEED_TIME;
}
} catch (const WriteConflictException&) {
// Ensure that the BSONObj underlying the WorkingSetMember is owned because it may
// be freed when we yield.
member->makeObjOwnedIfNeeded();
_idRetrying = id;
*out = WorkingSet::INVALID_ID;
return NEED_YIELD;
}
}
return returnIfMatches(member, id, out);
} else if (PlanStage::FAILURE == status) {
// The stage which produces a failure is responsible for allocating a working set member
// with error details.
invariant(WorkingSet::INVALID_ID != id);
*out = id;
return status;
} else if (PlanStage::NEED_YIELD == status) {
*out = id;
}
return status;
}mongo/db/exec/index_scan.cpp的doWork方法,IndexScan::doWork 是 MongoDB 中通过索引扫描获取文档的核心函数,负责从索引中遍历数据并返回符合条件的记录$recordId,具体代码如下:
cpp
PlanStage::StageState IndexScan::doWork(WorkingSetID* out) {
std::cout << "conca " << " IndexScan doWork..." << std::endl;
// Get the next kv pair from the index, if any.
boost::optional<IndexKeyEntry> kv;
try {
switch (_scanState) {
case INITIALIZING:
kv = initIndexScan();
break;
case GETTING_NEXT:
kv = _indexCursor->next();
break;
case NEED_SEEK:
++_specificStats.seeks;
kv = _indexCursor->seek(IndexEntryComparison::makeKeyStringFromSeekPointForSeek(
_seekPoint,
indexAccessMethod()->getSortedDataInterface()->getKeyStringVersion(),
indexAccessMethod()->getSortedDataInterface()->getOrdering(),
_forward));
break;
case HIT_END:
return PlanStage::IS_EOF;
}
} catch (const WriteConflictException&) {
*out = WorkingSet::INVALID_ID;
return PlanStage::NEED_YIELD;
}
if (kv) {
// In debug mode, check that the cursor isn't lying to us.
if (kDebugBuild && !_startKey.isEmpty()) {
int cmp = kv->key.woCompare(_startKey,
Ordering::make(_keyPattern),
/*compareFieldNames*/ false);
if (cmp == 0)
dassert(_startKeyInclusive);
dassert(_forward ? cmp >= 0 : cmp <= 0);
}
if (kDebugBuild && !_endKey.isEmpty()) {
int cmp = kv->key.woCompare(_endKey,
Ordering::make(_keyPattern),
/*compareFieldNames*/ false);
if (cmp == 0)
dassert(_endKeyInclusive);
dassert(_forward ? cmp <= 0 : cmp >= 0);
}
++_specificStats.keysExamined;
}
if (kv && _checker) {
switch (_checker->checkKey(kv->key, &_seekPoint)) {
case IndexBoundsChecker::VALID:
break;
case IndexBoundsChecker::DONE:
kv = boost::none;
break;
case IndexBoundsChecker::MUST_ADVANCE:
_scanState = NEED_SEEK;
return PlanStage::NEED_TIME;
}
}
if (!kv) {
_scanState = HIT_END;
_commonStats.isEOF = true;
_indexCursor.reset();
return PlanStage::IS_EOF;
}
_scanState = GETTING_NEXT;
if (_shouldDedup) {
++_specificStats.dupsTested;
if (!_returned.insert(kv->loc).second) {
// We've seen this RecordId before. Skip it this time.
++_specificStats.dupsDropped;
return PlanStage::NEED_TIME;
}
}
if (_filter) {
if (!Filter::passes(kv->key, _keyPattern, _filter)) {
return PlanStage::NEED_TIME;
}
}
if (!kv->key.isOwned())
kv->key = kv->key.getOwned();
// We found something to return, so fill out the WSM.
WorkingSetID id = _workingSet->allocate();
WorkingSetMember* member = _workingSet->get(id);
member->recordId = kv->loc;
member->keyData.push_back(IndexKeyDatum(
_keyPattern, kv->key, workingSetIndexId(), getOpCtx()->recoveryUnit()->getSnapshotId()));
_workingSet->transitionToRecordIdAndIdx(id);
if (_addKeyMetadata) {
member->metadata().setIndexKey(IndexKeyEntry::rehydrateKey(_keyPattern, kv->key));
}
*out = id;
return PlanStage::ADVANCED;
}IndexKeyEntry存储索引键(key)和对应记录 ID(loc);IndexCursor索引游标,负责遍历和定位索引项;WorkingSet内存工作集,管理查询过程中的临时数据;IndexBoundsChecker检查索引键是否在查询边界范围内。mongo/db/exec/index_scan.cpp的doWork方法主要逻辑是:1、从索引获取下一个键值对;2、处理获取到的索引项;3、检查索引键是否符合边界条件;4、处理无有效索引项的情况;5. 处理去重逻辑;6. 应用过滤条件;7. 准备返回工作集成员。
mongo/db/exec/delete.cpp的doWork方法,关键代码是开启事务、集合删除Document。后续文档会继续分析collection()->deleteDocument
cpp
WriteUnitOfWork wunit(getOpCtx());
collection()->deleteDocument(getOpCtx(),
_params->stmtId,
recordId,
_params->opDebug,
_params->fromMigrate,
false,
_params->returnDeleted ? Collection::StoreDeletedDoc::On
: Collection::StoreDeletedDoc::Off);
wunit.commit();