Mit6.5840课程学习链接
为什么要学习分布式系统
- 一个单体系统的性能是有上限的,通过分布多个系统可以提高性能,分布式是未来
- 可以完成大量互相协作的计算,大量并行运算、cpu、内存、磁盘
- 可以提供容错,一台发送故障,可以切换到另一台
- 有些问题原生涉及分布式:银行转账,涉及多个系统
- 最后安全性,比如有一些代码并不被信任,但是你又需要和它进行交互,这些代码不会立即表现的恶意或者出现bug。你不会想要信任这些代码,所以你或许想要将代码分散在多处运行,这样你的代码在另一台计算机运行,我的代码在我的计算机上运行,我们通过一些特定的网络协议通信。所以,我们可能会担心安全问题,我们把系统分成多个的计算机,这样可以限制出错域。
什么是好的分布式系统
- 容错性、可用性(多副本存储)
- 一致性(共识算法)
- 可扩展性(性能上与服务器数量成比例,例如一个大的分布式共享存储GFS)
- 安全性
构建分布式系统的挑战
- 涉及各种并发编程,以及事件对事件的依赖,同步异步事件
- 分布式系统有多个部分组成,加上网络,可能会发生各种意想不到的问题,如网络不稳定、网络分区、服务异常下线(断电)
- 最后一个是性能,用分布式系统往往是为了提高性能,比如一千台计算机并行计算,但是它的性能很难衡量
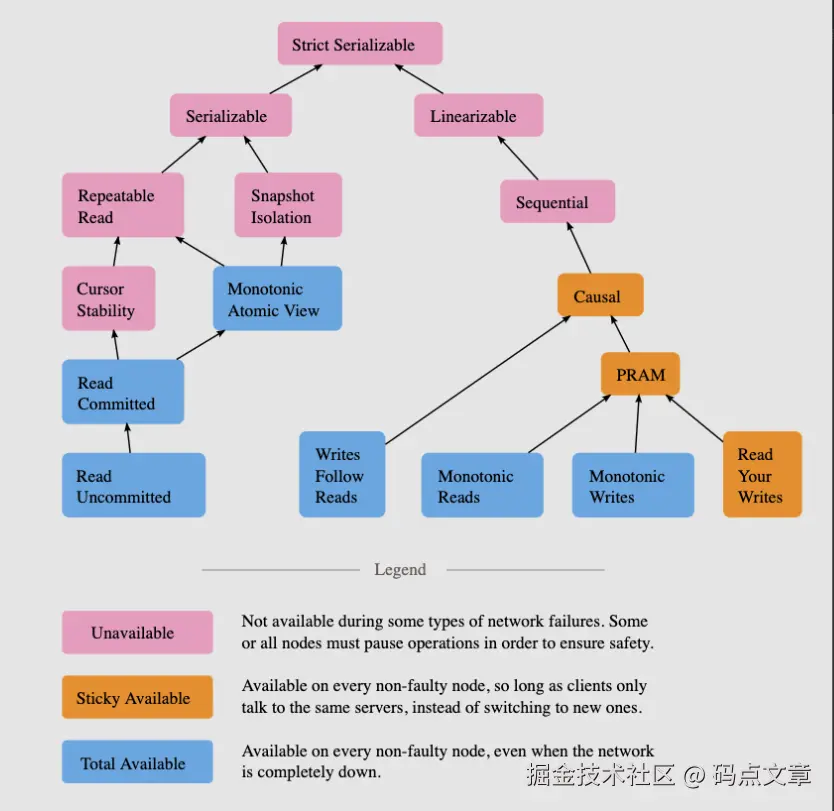
线性一致性
mp.weixin.qq.com/s/qnvl_msvw...
指的是分布式系统中CAP的C(consistency),指的就是线性化一致(强一致性)
顺序一致性定义3,4:如果一个并发执行过程所包含的所有读写操作能够重排成一个全局线性有序的序列,并且这个序列满足以下两个条件,那么这个并发执行过程就是满足顺序一致性的:
- 条件I:重排后的序列中每一个读操作返回的值,必须等于前面对同一个数据对象的最近一次写操作所写入的值。
- 条件II:原来每个进程中各个操作的执行先后顺序,在这个重排后的序列中必须保持一致。
线性一致性的定义5,与顺序一致性非常相似,也是试图把所有读写操作重排成一个全局线性有序的序列,但除了满足前面的条件I和条件II之外,还要同时满足一个条件:
- 条件III:不同进程的操作,如果在时间上不重叠,那么它们的执行先后顺序,在这个重排后的序列中必须保持一致。(考虑了时间先后的一致性,保证总是读到最新值)
思考数据库事务ACID特性的C一致性和CAP理论的C指的是同一个意思吗??
个人理解数据库事务的C更多是指对于整个数据库一致状态的维持。抽象看,对数据库每一次进行事务操作,它的状态就发生了一次改变,只要起始状态一致,那每次操作就能保持一致。因此指的是前后数据的一致性(应用层即业务逻辑的一致性)
而CAP的C指线性一致性,是系统之间数据复制的同步
但是为了保持强一致性,必然需要在副本节点之间做很多通信和协调工作。这降低了系统的可用性(availability )和性能。于是,在一致性、可用性、系统性能之间进行权衡的结果,就是降低系统提供的一致性保障,转向了最终一致性(相对于强一致性来说的)。
最终一致性
- 系统并不保证连续进程或者线程的访问都会返回最新的更新过的值。系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到。但会尽可能保证在某个时间级别(比如秒级别)之后,可以让数据达到一致性状态。最终一致性是弱一致性的特定形式。
最终一致性的种类
在实际工程实践中,最终一致性常被分为 5 种:
因果一致性(Causal consistency)
如果节点 A 在更新完某个数据后通知了节点 B,那么节点 B 之后对该数据的访问和修改都是基于 A 更新后的值。与此同时,和节点 A 无因果关系的节点 C 的数据访问则没有这样的限制。
读己之所写(Read your writes)
节点 A 更新一个数据后,它自身总是能访问到自身更新过的最新值,而不会看到旧值。其实也算一种因果一致性。
会话一致性(Session consistency)
系统能保证在同一个有效的会话中实现 "读己之所写" 的一致性,也就是说,执行更新操作之后,客户端能够在同一个会话中始终读取到该数据项的最新值。
单调读一致性(Monotonic read consistency)
如果一个节点从系统中读取出一个数据项的某个值后,那么系统对于该节点后续的任何数据访问都不应该返回更旧的值。
单调写一致性(Monotonic write consistency)
一个系统要能够保证来自同一个节点的写操作被顺序的执行。
 在现代关系型数据库中,大多都会采用同步和异步方式来实现主备数据复制技术。在同步方式中,数据的复制通常是更新事务的一部分,因此在事务完成后,主备数据库的数据就会达到一致。而在异步方式中,备库的更新往往存在延时,这取决于日志在主备数据库之间传输的时间长短,如果传输时间过长或者甚至在日志传输过程中出现异常导致无法及时将事务应用到备库上,那么很显然,从备库中读取的的数据将是旧的,因此就出现了不一致的情况。当然,无论是采用多次重试还是将数据修正,关系型数据库还是能够保证最终数据达到一致------这就是关系数据库提供最终一致性保证的经典案例。
在现代关系型数据库中,大多都会采用同步和异步方式来实现主备数据复制技术。在同步方式中,数据的复制通常是更新事务的一部分,因此在事务完成后,主备数据库的数据就会达到一致。而在异步方式中,备库的更新往往存在延时,这取决于日志在主备数据库之间传输的时间长短,如果传输时间过长或者甚至在日志传输过程中出现异常导致无法及时将事务应用到备库上,那么很显然,从备库中读取的的数据将是旧的,因此就出现了不一致的情况。当然,无论是采用多次重试还是将数据修正,关系型数据库还是能够保证最终数据达到一致------这就是关系数据库提供最终一致性保证的经典案例。