Redis是什么?为什么快?
Redis是什么
Redis是一个开源的基于内存的、支持多种数据结构的Key-Value存储系统,适用于用来缓存、计数器(点赞、访问量)、排行榜(ZSet)、分布式锁、消息队列/延迟队列场景。
关键特性:
- 高性能:读写速度极快
- 丰富的数据结构:支持string、hash、list、ZSet、Bitmap等多种数据结构
- 持久化:支持RDB(快照)和AOF(日志)两种方式,重启后数据不丢失(先从AOF恢复,没有再用RDB,都没有就空库启动)
- 功能丰富:支持事务、发布订阅、Lua脚本、主从复制等
Redis为什么这么快
基于内存操作(根本原因)
Redis的所有数据都存在内存中,没有磁盘IO开销,这是它快的基础。
单线程模型(避免了上下文切换)
"单线程"是指 Redis 的网络 I/O 和键值对读写是由一个主线程完成的。(Redis 6.0 之前)Redis的瓶颈通常不在CPU,而在于内存和网络带宽,既然CPU不是瓶颈,那么多线程带来的锁竞争和上下文切换反而会成为累赘, 但是 6.0 之后 Redis 为了进一步提升 IO 的性能,引入了多线程机制,减少 Redis 由于网络 IO 等待造成的影响。
I/O多路复用
Redis是单线程的,利用了OS的epoll(Linux)或kqueue( BSD )机制,采用Reactor模式,有一个文件事件分派器,通过epoll监听多个Socket,哪个Socket有数据了就交给主线程处理,实现非阻塞IO
高效的协议和数据结构(底层优化)
Redis 使用简单的二进制协议,减少了网络传输的开销。同时,其内部使用了高效的数据结构(如哈希表、跳表等),进一步提升了性能。
既然Redis是单线程的,为什么6.0后要引入多线程?
- Redis6.0依旧是默认单线程处理命令,执行GET、SET这些操作的时候,依然由主线程串行执行
- 引入多线程是为了解决网络IO瓶颈:网络数据读写(Read/Write系统调用)和协议解析占用主线程太多时间,Redis6.0引入多线程专门处理网络数据读写和协议解析,但命令执行依然是主线程排队做。
- Redis6.0的多线程是多线程I/O,单线程执行
DB缓存一致性问题
缓存一致性指的是缓存里(Redis)的数据,和数据库(MySQL)里的数据保持一致。有这个问题是因为Rdis与DB是两个系统,更新不是原子的,会遇到网络延迟、并发请求、进程崩溃、顺序错乱的问题,我们要明确,没有100%的强一致Redis+DB架构,我们只能基于业务权衡。
旁路缓存模式(Cache Aside Pattern)------主流
在大多数业务场景下,我们推荐使用'Cache Aside Pattern(旁路缓存模式)',即:先更新数据库,再删除缓存。

为什么是"删除缓存"而不是"更新缓存"?
- 并发竞争问题:
- 如果有两个线程同时更新数据库(A改为1,B改为2)。
- 如果这个时候选择更新缓存,由于网络延迟,可能B先到达Redis,A后到达,结果数据库是2,而缓存里却是1,造成数据不一致。
- 性能浪费
- 有些缓存的值是经过复杂计算的
- 如果每次修改数据库都计算一遍写入缓存,但这个缓存没人读,就会造成计算资源浪费
- 删除缓存相当于懒加载,只有下次有人读的时候,才去回填,效率更高。
为什么不可以更新缓存再更新数据库?
先更新缓存后更新数据库这个方案,只要任何一个出现错误都会导致数据不一致问题。如果更新缓存失败而更新数据库成功,那没有后续补救措施,缓存里一直是旧数据;如果更新缓存成功而更新数据库失败,对于用户来说,拿到的缓存一直是虚假数据,一旦缓存清空,重新从数据库读数据的时候,就与之前拿到的数据不一致了。而且在并发环境下,很容易会造成数据不一致问题。
"更新数据库"和"删除缓存"谁先谁后?
先删除缓存,再更新数据库:
- 流程:
- 线程A删除缓存
- 线程A更新数据库
- 致命问题(并发场景):
- 线程A删除了缓存,还没来得及去更新数据库(比如卡顿)
- 线程B来了,发现缓存为空,去数据库读旧值
- 线程B读了旧值后又写入缓存
- A把新值写入数据库
- 后果:数据库是新值,而缓存里仍然是旧值,造成数据不一致。
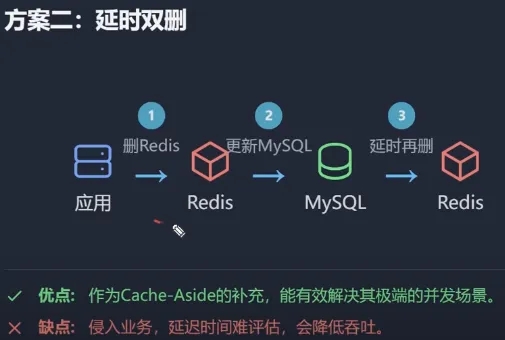
补救方法:延时双删
- 做法:
- 先删除缓存
- 更新数据库
- 休眠一小会
- 再次删除缓存
- 原理:休眠是为了让线程B把旧数据写入缓存这一步完成,线程A睡醒后再删除一次
- 缺点:吞吐量低(因为要sleep),而且无法知道到底要sleep多久
先更新数据库,再删除缓存(标准做法)
- 流程:
- 线程A更新数据库
- 线程A删除缓存
- 潜在问题:
- 理论上仍有不一致问题(概率很低):缓存刚好失效------>A线程读旧库------>线程B更新数据库------>线程B删除缓存------>线程A写入旧值
- 由于数据库的"写操作"通常比"读操作"慢得多。线程 A(读)要在线程 B(写+删)这整个漫长过程结束之后,还能把旧数据塞进去,这需要极其巧合的时间差。
- 但还是有一个致命问题------网络抖动:如果数据库改完了,但Redis挂了或网络抖动,缓存没删掉,这时数据库新值而缓存是旧值。
保障方法:消息队列重试机制
- 针对问题:解决删除缓存失败的问题
- 做法:
- 更新数据库
- 删除缓存
- 如果删除缓存失败,将要删除的Key发送到消息队列(MQ)
- 如果有一个消费者不断从MQ取Key,不断重试删除操作,直到成功。
订阅Binlog+MQ(Canal方案)
核心思想:把"缓存删除"这个动作从业务代码里剥离出来,彻底解耦。
架构:
- 业务代码只管更新数据库,不操作Redis
- 使用Canal(阿里开源中间件)伪装成MySQL的Slave,监听数据库的Binlog
- 一旦数据库发生变化,Canal解析Binlog,把变动的Key发送到MQ
- 消费者服务从MQ取Key,然后去执行Redis删除操作