1.1 为什么你应该读本章
本章作为全书的导言,介绍了接下来章节将如何借助机器(例如计算机和机器人)来处理语言。为什么自然语言处理(NLP)重要?
NLP 能够分析语言的意义。这里的"语言"指人们日常交流中使用的语言,如英语、德语、法语和印地语等。借助机器(主要是计算机系统),自然语言处理长期以来扮演着许多有用的角色:这些系统可以校正语法、将语音转换为文本,甚至实现语言之间的翻译。Google 翻译就是此类翻译系统的典型代表。NLP 可以帮助机器用人的语言与人沟通。借助这项技术,机器可以自动读取文本、识别并理解语音,并在社交媒体平台(如 Twitter(现称 X))上对公共舆情(比如新产品发布或政治话题)进行情感分析。
1.2 自然语言处理导论
现在正式介绍 NLP。亚马逊将其定义为"使计算机能够解释、操作和理解人类语言的一种机器学习技术"。同样,IBM 将其定义为"计算机科学和人工智能(AI)的一个子领域,使用机器学习使计算机能够理解并与人类语言进行交流"。
NLP 领域的研究催生了生成式 AI(GenAI)平台的新纪元,例如 ChatGPT 等许多系统。这类软件被称为大规模语言模型(LLMs)。生成式 AI 软件能生成文本、图像甚至视频。对于许多人来说,NLP 已成为日常生活的常规组成部分。这类用户不仅分布在发达国家,许多发展中国家也已离不开 NLP 与生成式 AI 软件的日常工作。NLP 的常见应用包括为 Google、Microsoft 等公司的搜索引擎提供支持、驱动用于客户服务的对话机器人、基于语音的 GPS 系统,甚至像 Apple 的 Siri 与 Amazon 的 Alexa 这样的数字助理。
近年来数据科学与机器学习领域的进步极大地推动了 NLP 的发展。NLP 大致可以分为三个领域:
- 语音理解:将英语等口语翻译为人类可读的文本。
- 自然语言理解:机器(通常为计算机或同等系统)理解语言的能力。
- 自然语言生成:例如 ChatGPT 一类的应用,使计算机能够生成自然语言。
人类使用的自然语言之所以特殊,有很多原因。首先,词在句子或段落中的意义具有上下文性------同一个词在不同语境中可能有不同含义。
斯坦福大学的 AI 教授 Chris Manning(克里斯·曼宁)认为,NLP 是一种信号系统,其中的符号具有离散、符号化和类别化的特性。相同的含义可以通过不同方式传达:语音、手势或符号等每种方式既独特又存在歧义。其他使 NLP 更具挑战性的因素包括拼写错误、口语和俚语、过多的地方语言与方言(例如仅非洲大陆就有 3000 多种语言)等等。
尽管 NLP 科学存在局限,但它仍为人类带来广泛好处。随着新技术的快速发展,许多阻碍正在以前所未有的速度被突破。
我们再看一下全球数据生成量的规模。Srinivasa-Desikan 给出一些具体数据:Google 每年处理超过 1 万亿次查询,Twitter 每天有 16 亿次查询,WhatsApp 每天处理超过 300 亿条消息。下面是一些数字:
- 全球每天产生约 402.74 百万 TB(terabytes)的数据。
- 2024 年大约产生 147 泽字节(zettabytes)的数据。
- 预计 2025 年大约产生 181 泽字节的数据。
图 1-1 展示了自 2020 年以来每年的数据量。毋庸赘述,这些数据中有大量是结构化与非结构化的语音/文本数据。公司通过使用各种机器学习技术分析这些数据可以创造巨大价值,从而为以数据驱动的商业决策提供可用的洞见。许多用于数据分析的机器学习技术被归在 NLP 的范畴内,用于自动从结构化与非结构化文本数据中提取有价值的信息。企业利用文本分析技术快速消化来自多种来源的在线数据与文档,并将其转化为可执行的洞见。像 Amazon、Google、Microsoft 这样的全球科技公司在这一方向上已经取得了显著领先。
机器学习是计算机算法的一个发展分支,它通过从周围环境(文本与数值数据)学习来模拟人类智能。6
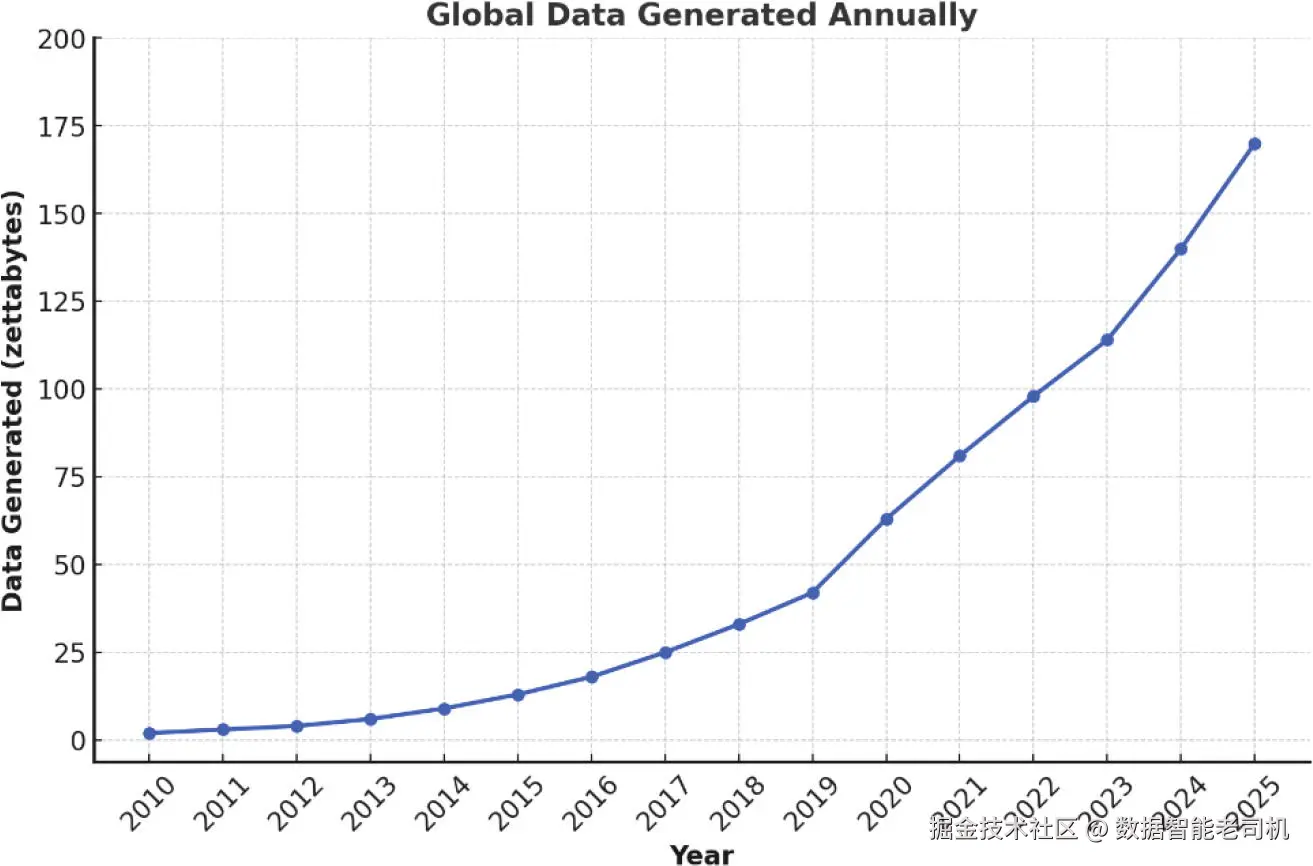
图 1-1 2010 至 2025 年全球数据生成量
NLP 在接下来的章节中将被进一步讨论。
1.2.1 NLP 技术
更正式地说,NLP 是从文本数据中提取高质量且可操作信息的技术。大量文本数据分布在网站、电子邮件、评论(如 Amazon 与 X(前 Twitter)上的评论)、书籍与研究论文中。这些数据需要被提取、清洗、格式化,并经过其他数据处理步骤。数据处理是一个费时的过程,可能占整个 NLP 项目总时间的 80%。随后,使用统计算法在文本数据中寻找模式,并根据具体任务选用机器学习或深度学习算法。最后对结果进行评估并解释,以供数据驱动的决策使用。典型的 NLP 任务包括文本分类与聚类、实体抽取、细粒度目录的开发、文本摘要等。对社交媒体数据的情感分析是利用 NLP 技术的热门任务之一。
NLP 使用许多基础与进阶技术。较简单的包括文本分类、计算词频、文本抽取与聚类、词性标注、情感分析、搭配与语境分析、停用词去除以及词义消歧等。下面将简要介绍这些较简单的技术;更复杂的 NLP 技术将在后续章节中讨论。
1.2.2 文本分类
文本分类是一种分析方法,用于将文本归类或分配到事先定义的不同组中。例如,一条推文可以表示正面或负面情感(正面用 1 表示,负面用 0 表示)。假设你有一千条已标注为正面或负面的推文,那么你可能会训练一个简单的机器学习算法,比如逻辑回归。尽管仅有一千条推文对于训练任何机器学习算法来说可能偏少,但它仍可作为示例演示。
一旦逻辑回归模型训练好,它就可以用于将新的推文分类为正面或负面。这类项目属于文本分类范畴。逻辑回归属于线性家族的机器学习算法,可能是我们工具箱中最简单的算法。为完整性考虑,还有其它非线性且更复杂的分类算法,如随机森林、XGBoost,以及神经网络家族的算法。只要数据被适当清洗并按文本分类项目的要求预处理,这些复杂算法也可以用于文本分类项目,在某些情况下它们的准确性可能高于逻辑回归。算法的选择取决于许多因素,如任务的性质、计算资源的可用性、技能储备与可用时间等。图 1-2 展示了一个简单的电子邮件分类器的工作流程。
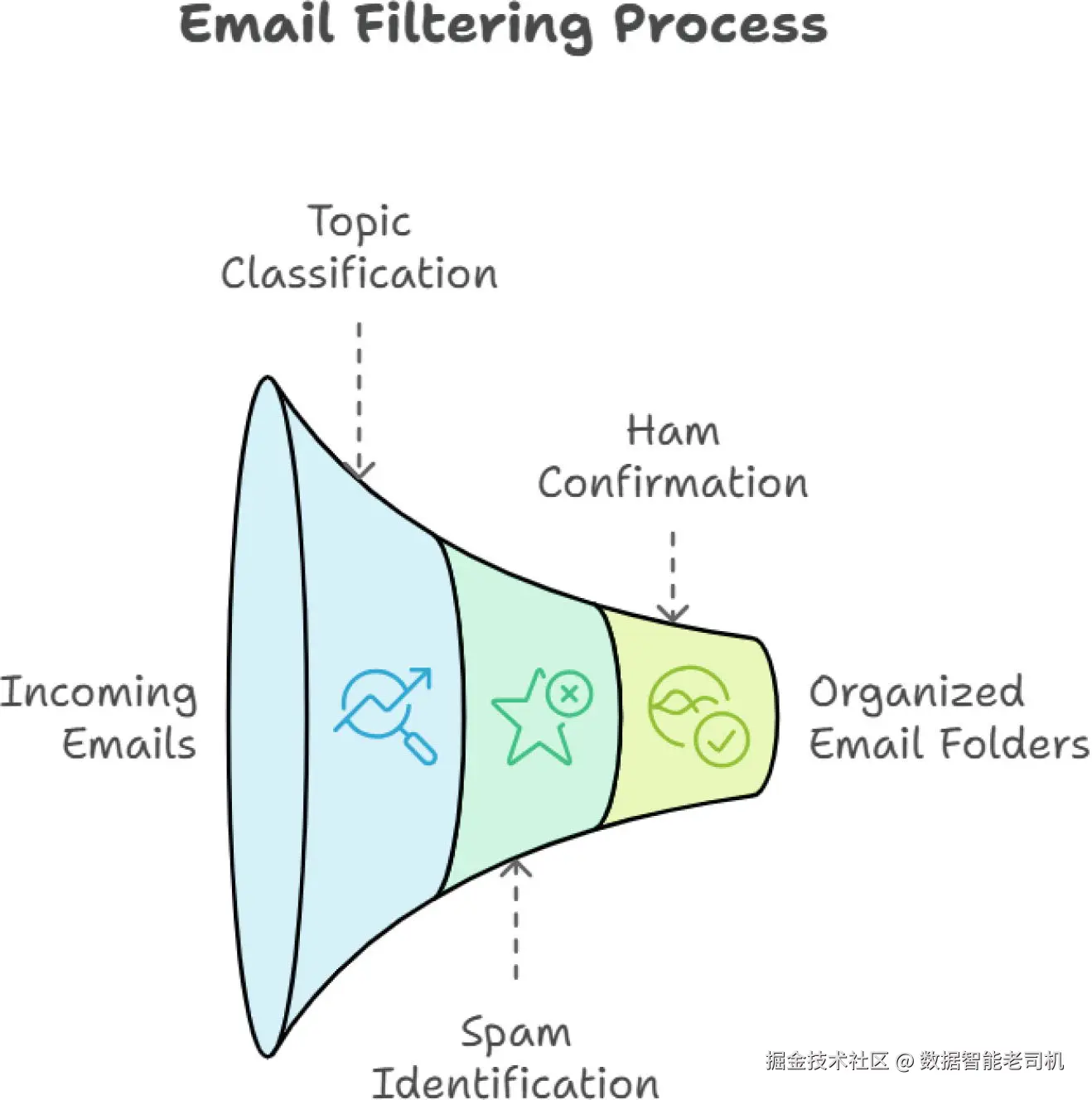
图 1-2 主题分类用于标记接收的垃圾邮件并将其过滤到垃圾邮件文件夹
1.2.3 聚类
用一个简单例子来理解聚类。想象你有十段关于不同主题的文本段落,但没有任何标题信息。阅读时你会发现其中一些关于线性代数、一些关于欧洲史、一些关于量子力学。你将这些段落按主题分组,这就是文本聚类的典型实例!
学会了文本聚类后,再看一个实际用途的例子:假设你需要管理大量已知标题的文本数据,使用机器学习算法的文本聚类可以自动将这些数据组织成有意义的组,这样就无需逐一阅读全文就能更容易地查找与分析信息。
常用的文本聚类算法包括 k-means 聚类、层次聚类、基于密度的 DBSCAN、潜在狄利克雷分配(LDA)、用于词向量表示的 GloVe、以及双向编码器表示(BERT)等。某些技术单独使用,某些则结合使用,视具体任务而定。本书后续章节将介绍其中的一些技术。图 1-3 描绘了聚类过程:一篇文章的内容被分类到医疗、科技和体育等主题簇中,通常在文档与簇之间存在一个 NLP 聚类处理器(或类似 k-means 的算法)将文章内容归入相应组。
 图 1-3 一篇通用文章的主题聚类示意图
图 1-3 一篇通用文章的主题聚类示意图
1.2.4 搭配(Collocation)
再从一个简单例子开始。假设你是五星级酒店的一名厨师,长期烹饪中你会注意到某些配料经常在菜谱中一起出现,比如"花生酱"与"果酱",或"盐"与"胡椒"。在烹饪领域,这类经常一起出现的配料对就称为搭配(collocations)。在文本或语言中,搭配指的是经常一起出现、且对母语者听起来自然的一对或一组词。
例如 "make a choice"、"take a break"、"heavy rain" 和 "do homework" 都是英文中的搭配。理解并运用搭配能使语言更自然、流畅。由于这些词天然地搭配在一起,搭配知识有助于写作与口语表达。
Word2Vec 是一种基于深度学习的模型,它从大型语料中学习词的搭配关联。关键在于经常一起出现的词会有相似的向量表示。我们将在后续章节讨论这些以及更多技术。
1.2.5 语境共现 / 词频统计(Concordance)
仍然从简单例子说起。假设你正在写一篇较长文章,想知道词 "rain" 在文中出现了多少次。共现(或词频统计)可以帮你完成这个任务。查找共现(或词频)的整个过程通常由计算机程序完成。因此,在 NLP 的语境下,共现是指在文本语料库中查找某个词或短语出现位置及其上下文的过程。
像 NLTK(Natural Language Toolkit)这样的 NLP 专用 Python 库可以用来通过处理并分析文本数据来生成共现列表。我们将在本书前部讨论该库。其他一些软件工具也可以提供词频及其上下文的可视化表示。
1.2.6 文本抽取(Text Extraction)
在 NLP 程序的语境中,文本抽取就是从大量文本语料中提取感兴趣的特定信息。举个例子:想象你在读一本书,但你只需要讨论你爱好(如网球)的段落,文本抽取就像用高光笔标记出这些部分。在文本抽取下,主要涵盖的主题包括:
- 命名实体识别(NER):从语料中抽取人名、日期、地点等实体。
- 关键词抽取:抽取能概括文档或语料主题的重要关键字或短语。
- 词性标注:给文本中的词打上各种名词、动词、形容词等标签,有助于理解句法结构与抽取相关信息。
- 正则表达式(RegEx):使用模式匹配提取显式文本串,例如从邮件正文提取地址或电话号码。
- 文本摘要:生成较长文档的摘要并突出关键点。
1.2.7 停用词去除(Stop Word Removal)
还是从例子说起。考虑句子 "The cat is on a mat." 去掉所有停用词后,剩下的只有 "cat" 和 "mat",它们是关键词。停用词去除是 NLP 中过滤掉常见高频词的过程,这类词包括 "and"、"the"、"is"、"in" 等,这些词对句子意义贡献较小,因此在很多任务中会被剔除。
停用词去除通常从分词(tokenization)开始:将文本文档(在 NLP 语境中,文档指的是一整段文本)切分成单个词。接下来将每个词与预定义的停用词列表比较,如果匹配则将其移除。该步骤有助于减少词汇表规模,并将分析关注点集中在更重要的词上。
常见支持停用词去除的库包括 NLTK、spaCy、Gensim、scikit-learn 和 TextBlob。本书前部会介绍这些库中的大多数,并在代码案例中反复使用它们。
1.2.8 词义消歧(Word Sense Disambiguation,WSD)
考虑句子 "John noticed a bat flying in the sky." 这里单词 "bat" 可能有两种不同含义:一种是夜行性动物,另一种是棒球、网球或板球中使用的球棒器具。WSD 程序会分析 "bat" 周围的词和整个句子的句法结构,利用这些信息判断 "bat" 在该语境下最合适的含义。这类分析对于机器翻译、情感分析和信息检索等各种 NLP 应用至关重要。在该类任务中,精确理解词义可以提升 NLP 程序的性能与可靠性。WSD 过程(在图 1-4 中有近似示意)8 可总结为:
- 语境分析:聚焦目标词并分析其在句子中的上下文。
- 词义库存:通常使用预定义的词义词典或库存来列出目标词的不同含义(sense)。
- 特征提取:提取相邻词、词性标注以及各种句法依赖等相关特征。
- 消歧算法:应用适当的机器学习算法来确定最可能的词义。
- 评估:使用精确率、召回率与 F1 等分类指标,在带标注的数据上评估准确性。
- 应用:将 WSD 技术集成到机器翻译、情感分析等 NLP 任务中。
这个过程现在看起来可能有些陌生,不用担心。你可以先读一遍,即便没有完全看懂也可以继续往下读。本书后面包含了基于代码的案例研究来帮助理解。
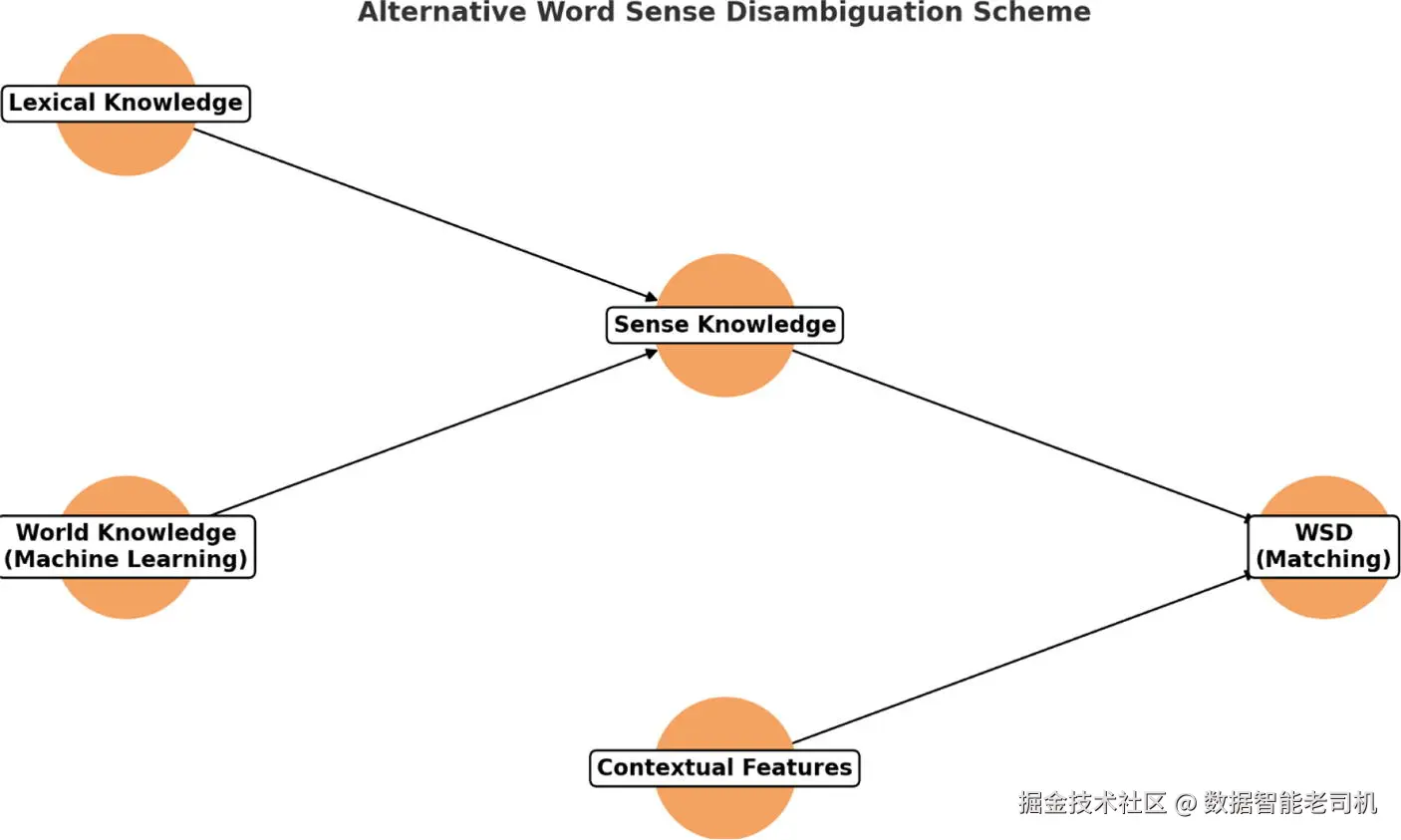 图 1-4 WSD 程序的工作原理
图 1-4 WSD 程序的工作原理
1.3 NLP 面临的挑战
NLP 及其相关分支在处理词语与文本方面持续快速发展,但人类语言本身极其复杂、流动且不一致。所有自然语言(包括英语)都带来了严重挑战,NLP 研究者在不断努力克服。2016 年的一篇研究论文对主要挑战给出了相对完整的概览,将这些挑战划分为以下五类:
挑战 1:多样且异构的数据源带来的复杂性。 我们处理的文本语料库中文档存在多种形式和格式的差异。这种多样性可能来自很多方面,例如文档编码格式不同、文档长度差异、文档使用不同语言等。
挑战 2:在许多商业与工业应用场景中必须处理短小且稀疏的文本。 这类文本不具备足够的统计冗余(与研究者常用的大型标准语料库相比),因此 NLP 算法难以从中获得可靠的统计证据。另一个问题是监督式 NLP 技术中标签的不平衡(class imbalance);例如在信用卡交易数据中,欺诈交易通常不到 1%。
挑战 3:算法结果的评估与解释具有主观性,较难量化。 在某些业务应用中(如推文情感分析、文本分类与聚类),固有的主观性使得评估成为挑战。学术研究中常用的"金标准"数据集在工业与真实场景中往往难以获得。相关的挑战还包括用于训练监督式模型的标注数据短缺,例如文本分类与情感分析等问题常常缺乏高质量标注数据。
挑战 4:人类在处理自然语言时接近完美,而当前 NLP 系统尚无法达到这种 100% 的性能。 在某些领域(如航空航天、航天等对错误容忍度极低的场景)这种局限性尤为关键。为提升性能,许多 NLP 应用(例如文本分类)开始采用主动学习(active learning)来改进模型表现。主动学习是一类机器学习方法,算法可交互地向人类(或外部来源)请求对新数据点进行标注,从而在模型不确定时获得人工干预以提升整体性能。举例来说,若系统在识别照片中某款车时无法判定型号,它可能请求人工标注该样本,从而改进后续识别效果。
挑战 5:在真实、动态的文本流场景中实时处理需求带来的挑战。 这类场景常见于支持关键决策的应用中,要求对文本数据进行及时、高效的处理并返回结果。相关的另一个挑战是数据生成速率极高,例如在某些短消息应用(如推文)中,平均每秒约产生 6000 条消息。要准确处理如此高速的文本流非常困难,因为它要求及时分析以从中抽取相关且有意义的信息。
这些挑战可以从多个角度来观察,并且在具体的 NLP 项目中还会出现更多挑战。本节旨在做入门性概述,随着本书推进你将会遇到更多挑战及其对应的解决方法。
1.4 NLP 的应用
NLP 适用于文本与语音,对所有人类语言(口语与书面语)同样适用,因此应用场景繁多。因篇幅限制,这里仅列举一小部分。我们日常或多或少都在接触 NLP:比如 Siri、文字处理器中的拼写检查、iPhone、Amazon 的 Alexa 等,这些应用中有些处理人类语音并帮助解决常见查询。其它常见的 NLP 工具还包括邮件垃圾过滤、AI 驱动的网络搜索引擎、文本或语音机器翻译、自动文档摘要、社交媒体情感分析等。
NLP 被广泛应用于各行各业,已成为许多工业流程的组成部分,正在改变客户与机构的交互方式(例如基于 NLP 的客户服务聊天机器人)。许多业务流程包含大量非结构化文本数据(社交媒体消息、调查、电子邮件等),NLP 技术可以相对容易地将这些流程自动化。以下是一些具体示例(图 1-5 展示了若干有趣的用例)。
 图 1-5 NLP 用例
图 1-5 NLP 用例
1.4.1 银行与金融行业(BFSI)
该行业广泛使用 NLP 驱动的聊天机器人与数字虚拟助理,以提供即时且个性化的服务。许多银行与金融机构还使用 NLP 驱动的金融欺诈检测系统,在发现可疑活动(如高额欺诈交易)时立即提醒后台人员。NLP 可以从大量文本中抽取与监管合规相关的关键信息,处理财务报告、股票市场数据和新闻文章等文档,从而支持风险分析与更好的决策。技术驱动的金融机构还将 NLP 用于贷款与信用卡申请、保险理赔文档、合同等场景的快速决策与自动化处理。
1.4.2 医疗健康
医疗行业产生大量非结构化文本(病历、监管文档等)。许多医疗公司利用 NLP 引擎分析这些信息以获得有价值洞见并在管理层各级做数据驱动决策。行业也在使用临床聊天机器人来辅助医生诊断疾病。NLP 可分析患者反馈、线上健康论坛数据及相关社交媒体信息,用于监测患者情绪并发现社区健康新趋势。有时这类分析是实时进行的,从而为公共卫生响应提供及时预警,帮助提高患者满意度并快速处理其关注点。
1.4.3 法律
法律专业人员花费大量时间在庞大法律文档集合中检索相关信息,这些研究数据常常对诉讼(刑事或民事)结果有决定性影响。NLP 引擎可以自动化大量法律检索与发现流程,使法律从业者能把更多时间用于案件其他关键环节。NLP 可通过分析海量文档实现文档分类,帮助法律人员高效管理与组织大量文档,快速检索相关信息。
以上只是少数示例,NLP 在许多其它领域也有应用,接下来再列举几个。
1.4.4 自动化常规业务流程
聊天机器人与数字助理(如 Siri、Alexa)能识别以人声形式提出的查询,并匹配企业或政府数据库中相应条目以检索相关信息。获取信息后,数字助理会构造合适的回答以回复用户。在业务运营中,NLP 可通过处理电子邮件、报告和表单等非结构化数据来自动化数据录入与信息抽取工作,甚至可根据内容分析来优先排序任务,从而保证及时有序地执行。NLP 应用可以自动化许多重复性任务,帮助组织提高准确性、降低成本并更有效地分配资源。
1.4.5 改善检索(Search)
基于 NLP 的应用可以改进文档或互联网的关键词检索。它们通过基于上下文消歧词义来检索相关信息(例如英文单词 "bat" 可根据上下文有不同含义),这对于 FAQ 与聊天机器人中的客户问题解析非常有用。此外,NLP 驱动的搜索引擎能够有效处理语音搜索,允许用户通过语音与搜索系统交互,提高可访问性与便利性。对于搜索引擎,NLP 还能基于过去的搜索、交互性质与人口统计信息分析用户行为与偏好,从而个性化推荐结果,预测用户意图并提供贴合个人偏好的结果。
1.4.6 搜索引擎优化(SEO)
SEO 是优化网站及其内容以提升在搜索引擎结果页(SERP)中可见性与排名的艺术。SEO 流程包括关键词研究(猜测用户搜索时常用的词)、页面内优化(确保网站内容对搜索引擎友好)与页面外优化(通过外部活动提升站点权威性与排名)。NLP 在整个 SEO 过程中非常有用,因为它能理解与分析用户查询背后的意图,帮助企业更准确地满足用户需求,从而提升搜索排名并带来更多自然流量(即非付费的访问者)。
1.4.7 机器翻译:使用 NLP 自动翻译语言
机器翻译技术近年已相当成熟。NLP 应用能够在多种自然语言间提供较为准确的翻译,既能处理文本也能处理语音,通常能够在语法与语境上较好地传达原意。图 1-6 展示了一个简化的机器翻译模型。到目前为止,最先进的 NLP 技术在很大程度上已克服了词义歧义、保留原文风格与语气、以及专门领域准确性等挑战。但机器翻译仍是一个不断演进的应用领域。
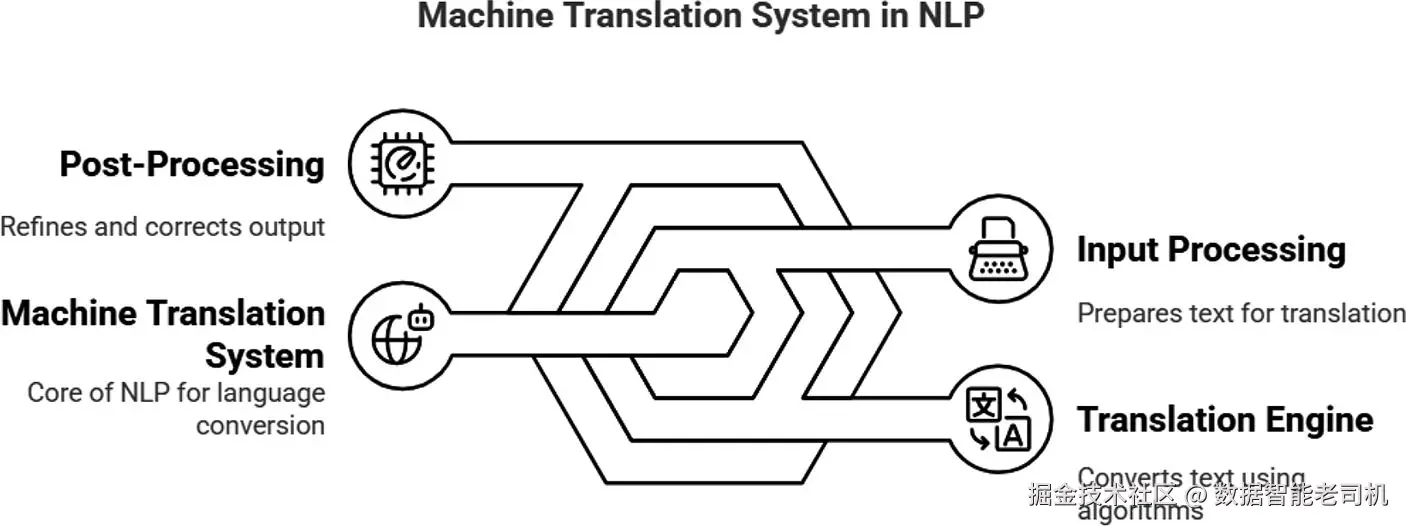 图 1-6 机器翻译模型
图 1-6 机器翻译模型
1.4.8 文本摘要:浓缩大量文本信息
文本摘要的压缩比例在不同定义下可从 10% 到 50% 不等(见图 1-7)。文本摘要应用常使用深度学习架构,特别是 Transformer。我们将在后续章节讨论一些深度学习 NLP 技术,但 Transformer 的详细论述超出本书范围。抽取式摘要(extractive summarization)从原文中提取不变的句子,这类技术被新闻聚合器、法律文档审阅者和学术研究者广泛使用,目的是快速传达长文档的要点以节省读者时间与精力。另一类是基于 LLM(如 ChatGPT)的生成式摘要,它们能用模型生成的原创句子(非原文中直接出现的句子)来概括内容,这些模型基于 Transformer 等复杂架构。LLM 是 2020 年后出现的较新创新,目前虽然非常有用,但有时会生成不真实或错误的信息(称为"幻觉")。关于 LLM 的研究十分活跃,其能力随各大厂商(如 Google、OpenAI)发布的新模型不断提升。
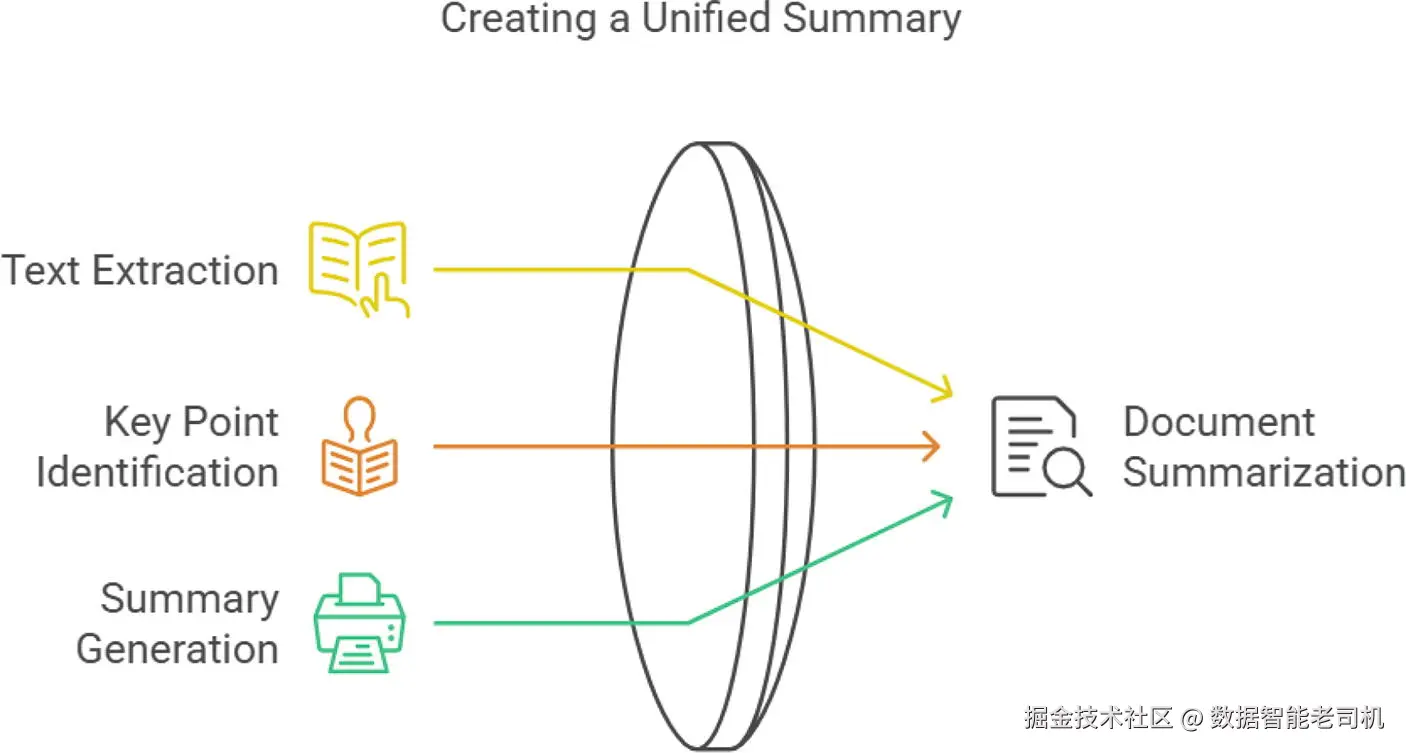 图 1-7 文档摘要
图 1-7 文档摘要
1.5 最新趋势与未来方向
NLP 是一个不断演进的领域。来自计算机科学与工程、人工智能与机器学习、语言学等领域的众多研究者持续为 NLP 做出积极贡献。推动 NLP 快速发展的主要因素包括机器学习的创新与计算能力的提升。近年来,深度学习与基于 Transformer 的模型(如 BERT、GPT)使许多 NLP 相关的新趋势成为可能。这些模型显著提升了机器在语言理解、翻译与生成等方面的能力。近几年,NLP 研究的重点逐渐转向更具上下文感知和类人交互的方向。这些进展正在增强聊天机器人与个人数字助理的能力,使其更像人类地进行互动。其他正在兴起的 NLP 研究方向包括可解释性(explainable NLP)、偏见缓解与伦理考量。
通常,训练 NLP 模型会消耗大量资源,需要庞大的文本语料以及相应的软件与硬件计算资源。因此,低资源语言处理能力的开发成为一个重要方向。另一个关注点是自动的多语言处理。这些最新发展正在改善机器理解与与人类语言交互的方式。下面列举了一些值得注意的 NLP 趋势。
1.5.1 迁移学习:预训练的优势
预训练模型(或称迁移学习模型)是指在大规模语料上事先训练好的深度学习模型,这些语料可能来自可获取的互联网内容。换言之,这些模型将学习以权重、偏置及其他可调参数的形式"存储"在模型中。通过调整原神经网络结构的最后几层,就可以将这种学习迁移到其他具体任务上,从而节省新任务的训练时间和训练数据。这种做法被称为迁移学习。它允许将复杂的预训练深度学习模型应用于多种场景。
迁移学习已彻底改变了 NLP 领域。开发者可以将预先学到的知识迁移到其他任务上,即便这些任务与原始训练任务不同。BERT、ELMo、GPT、ERNIE、ELECTRA、RoBERTa 等都是常见的预训练 NLP 模型。这些模型在大规模语料上预训练后,可以通过微调(fine-tuning)用于更具体的任务。对 NLP 开发者而言,预训练模型大幅节省了时间和资源,避免从零开始训练模型;由于需要更少的标注数据和计算资源(内存、存储、CPU/GPU),它们成为语言翻译、聊天机器人、社媒情感分析、主题建模与文本摘要等任务的吸引选项。图 1-8 比较了迁移学习与传统方法。
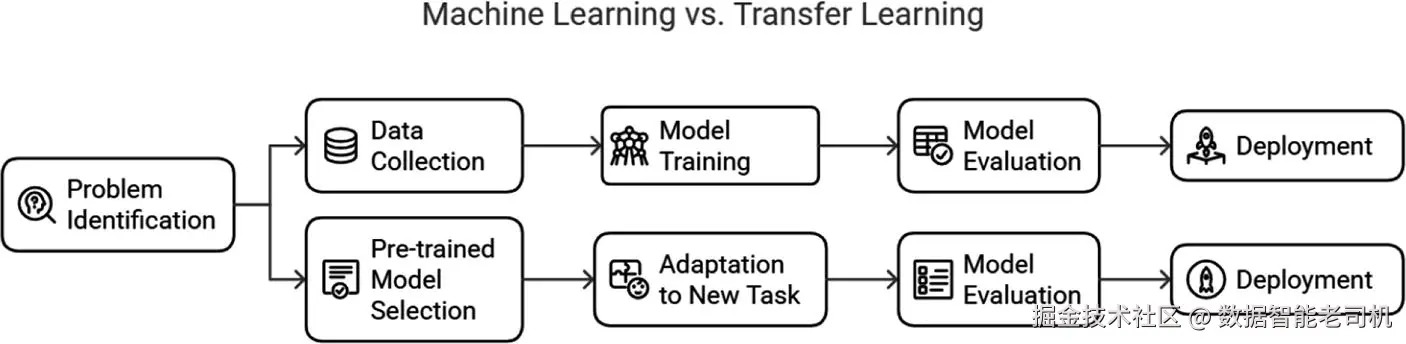 图 1-8 传统机器学习与预训练模型的比较
图 1-8 传统机器学习与预训练模型的比较
Wang 等人(2022)对迁移学习模型的方法与框架做了完整综述:先介绍迁移学习模型的基本概念,随后给出代表方法与适用框架,接着分析迁移学习模型的效果与挑战,并在结尾简要报告该领域的未来研究趋势。
1.5.2 大规模语言模型(LLMs):类人交互
大量研究论文讨论了 LLM(如 ChatGPT)在教育、医学等领域的应用。几乎所有人都知道 ChatGPT,并且很大概率已经亲自试用过。Enkelejda 等人专题讨论了 ChatGPT 及相关软件在教育领域的现状,指出 ChatGPT 可用于生成高质量教育内容、提升学生参与度与个性化学习体验,但在使用前师生需理解这些系统的局限性与有时意外表现出的脆弱性(brittleness)。持续的人类监督对于应对 LLM 输出中可能出现的偏见是必要的。该文最后给出了解决 LLM 常见挑战的建议。
按定义,LLM 是能够理解并生成自然语言文本的复杂深度学习模型。它们能进行类人交互、讨论几乎任何话题,但有时也会犯严重错误(称为"幻觉")。LLM 在巨量数据上训练,因此名为"大规模"。训练数据集规模可从千兆字节到百万兆字节不等。LLM 可通过微调进一步适配特定任务或领域(比如金融、医疗或教育)。LLM 的应用几乎遍及所有领域,包括聊天机器人、情感分析、客户服务、DNA 研究与在线搜索。常见 LLM 示例包括 GitHub Copilot、OpenAI 的 ChatGPT、Google 的 Bard、Meta 的 Llama 以及微软的 Bing Chat。具体任务包括文本生成、摘要、翻译、问答、代码生成(Copilot)与情感分析等。
1.5.3 跨语种与多语种模型:处理多语言
跨语种(cross-lingual)NLP 模型能够理解多种语言,并能在语言之间迁移知识,从而快速支持机器翻译与跨语种理解。多语种模型(multilingual models, MLMs)也能同时处理多种语言,但不一定在语言间做知识迁移。MLM 可在不为每种语言分别训练独立模型的情况下完成多种 NLP 任务。单一的多语种模型可并行处理多种语言任务。
跨语种模型可执行的任务包括机器翻译、社媒情感分析、跨语种信息检索、多语种文本分类、跨语种问答、实体识别与语言推理等;而多语种模型可用于文本分类、语言检测、命名实体识别、词性标注、情感分析、机器翻译、问答与文本摘要等任务。现实中的多语种/NLP 服务实例包括 Google Translate、Microsoft Translator、Amazon Comprehend、Facebook 的 M2M-100 与 IBM Watson Language Translator;跨语种模型的代表有 XLM-R(Cross-lingual Language Model--RoBERTa)、mBERT(multilingual BERT)、M2M-100(Many-to-Many 100)、LASER(Language-Agnostic SEntence Representations)与 T5(Text-To-Text Transfer Transformer)。
1.5.4 可解释的 NLP:解释模型结果
通俗地说,可解释的 NLP 就像一个同事能解释她为什么认为某件事为真,让你明白她的推理过程。正如 Søgaard(2021)在其 NLP 著作中提出的,解释性 NLP 是一个新兴领域,近年来受到全球技术社区的广泛关注。包括医疗与法律在内的许多行业要求 NLP 开发者能够对模型的预测结果给出理由;在某些国家这甚至是法律要求。
理解可解释性 NLP 的重要性有两点:一是确认 AI 驱动的解决方案符合本地与国际法规(尤其在金融、医疗等敏感领域);二是更好地理解模型工作原理可以减少错误、提前预见模型的强项与弱点。尤其是在生产环境中,深刻理解模型内在机制有助于避免意外行为并降低社会偏见的影响------偏见往往源于训练数据本身的不平衡或偏向。因此,可解释性研究能增强在生产环境中部署 NLP 解决方案时的信任度與可靠性。
1.5.5 NLP 的新兴领域
NLP 的研究边界日益扩展。情感 AI(Emotional AI)正在兴起,NLP 模型能通过分析文本与语音模式识别人类情绪。使用 LLM(如 ChatGPT)进行多语种处理正在打破语言壁垒、促进全球交流。NLP 模型正越来越多地与图像与语音等模态结合(多模态 NLP),并与增强现实(AR)集成以在沉浸式环境中交互。实时与交互式 NLP 的速度与响应能力也将提升,从而改进实时翻译(例如用于国际重要会谈)、视频字幕生成与类似 Alexa 的交互式语音助理的表现。
伦理与负责任的 AI 也是备受关注的研究方向,研究者持续致力于缓解偏见、保障数据隐私并提高 AI 系统的透明性。未来的 NLP 模型(包括生成式 AI 领域的模型)预计将具备更好的泛化能力,更可靠,在调整到新任务时需更少的微调数据。未来几年,我们可以期待更大、更强、更可靠的语言模型出现------这些模型将更深刻理解上下文,从而生成更加精确与语境恰当的回应。
1.6 简短商业案例 1:NLP 在医学文本分析中的应用
全球范围内,医疗行业产生大量文本数据,包括临床记录、病历、研究文章等。从这些文本中提取可操作的洞见既具有挑战性也十分必要。此类洞见有助于改善患者护理、推进医学研究并优化运营。今天已有许多强大的 NLP 解决方案能够分析并解释不同语言的医学文本,将非结构化数据转化为有价值的信息。
NLP 应用可以通过从电子病历中抽取关键信息为患者医疗业务显著增值。例如,NLP 能识别症状、诊断与治疗模式,这最终有助于早期疾病诊断与更个性化的治疗方案。一个基于 NLP 的系统可能会在发现某些症状模式与检验结果组合时发出糖尿病潜在诊断的早期预警,从而促使医疗人员及时干预。
1.6.1 精简临床研究流程
医学研究人员经常要检索大量电子病历、相关研究及临床试验结果以开展研究。NLP 应用可以自动从研究文章、临床试验数据库与病历中抽取相关信息,例如快速定位符合特定条件的研究或查找具有特定基因标记的患者以便开展靶向试验。
1.6.2 提高行政效率
许多行政工作(如编码、计费与文档处理)既繁琐又耗时且易出错。NLP 应用可通过自动抽取与分类用于计费、保险理赔与合规所需的信息来简化这些流程。例如,NLP 系统能读取并理解医生的病历记录,自动提取计费代码,从而显著减轻医疗机构的行政负担并减少错误风险。
1.6.3 增强数据可访问性
手工存取与检索病历既费力又耗时。NLP 应用能自动化这一流程;事实上,目前多数医疗机构已开始采用相关应用。通过将非结构化文本记录转换为结构化数据,NLP 可创建可检索的医疗记录数据库,从而实现快速访问患者病史与治疗结果,辅助医疗人员做出快速决策与协调。此外,NLP 还可生成患者友好的摘要(并以其母语提供,如有需要),帮助患者更好理解复杂医疗信息并提升参与度。
1.6.4 促进预测分析
NLP 应用能对数据进行准确分析以预测患者结局并识别潜在风险。通过分析非结构化医疗文本中的相关信息,NLP 可增强医疗领域的预测分析能力。例如,基于历史电子病历的分析,NLP 应用能识别再入院或并发症的风险因素,从而启用前瞻性干预举措,改善患者结局并有望降低医疗成本。
1.6.5 商业案例结论
除上述节省资源的医疗应用外,医疗文本分析仍面临诸多挑战,如病历的复杂性与多样性或语言差异。确保 NLP 应用的准确性与可靠性至关重要------在医疗场景中,哪怕是小错误也可能带来严重后果。没有任何 AI 领域的分析是 100% 准确的------NLP 亦然。因此,需要持续改进算法并与医疗专业人士协作以提升精确性与适用性。
医学 NLP 应用在改善医疗服务、精简临床研究、提高行政效率与促进预测分析方面展现出巨大潜力。通过利用 NLP 技术,医疗专业人员能够从非结构化数据中解锁有价值的洞见,从而带来更好的患者结局与更高效的医疗体系。随着医疗领域的 NLP 持续发展,未来它有望在推进个性化医学与优化医疗服务方面发挥关键作用。
 (图 1-9 展示了更多基于 NLP 的应用场景。)
(图 1-9 展示了更多基于 NLP 的应用场景。)
1.7 短商业案例 2:NLP 在客户服务中的应用 --- 提升客户互动
ABC 公司是一家总部位于纽约市中心、在服装电商领域领先的公司,以丰富的产品线和"客户至上"著称。随着公司在未来数十年持续增长,线上客户互动量也大幅上升。维持高水平的客户满意度变得愈发重要。为了解决这些及相关问题,公司决定部署定制化的 NLP 应用,以提升客服运营并维持客户满意度。
1.7.1 挑战
在实施 NLP 解决方案之前,ABC 公司的客服部门面临若干问题:
- 客服询问量大:客服团队难以有效应对每天的大量询问,导致响应延迟并加剧客户不满。
- 响应质量不一致:公司实行 24/7 人工值守,回答质量高度依赖坐席个体,频繁引发客户投诉。
- 运营成本高:为了保持全天候服务,公司需维持庞大客服团队,成本高且面临高离职率等人事挑战。
- 缺乏洞见:公司无法基于已有的语音与文本数据有效分析客户情绪与常见问题,难以及时采取主动措施,进而影响运营效率。实施主动预警与洞见成为优先事项之一。
1.7.2 NLP 的实施
为应对上述挑战,ABC 公司采用了多项 NLP 技术,包括自动化聊天机器人、从客户文本中进行情感分析、对文本与语音询问进行分类,以及自然语言理解(NLU)。
- 引入 AI 驱动的聊天机器人以处理常见询问,许多常规问题得到即时回应。聊天机器人的训练基于历史客服数据,使其更容易理解并回应关于订单、退货与商品信息的常见问题。
- 对来自邮箱、社交媒体与在线评价等渠道的客户反馈进行情感分析,帮助公司实时判断客户情绪并迅速处理问题。
- 使用文本分类解决方案自动对进线询问进行分类,基于内容将询问路由到相应部门,必要时再升级或交由人工坐席接管。
- 新部署的聊天机器人与虚拟助理具备先进的 NLU 能力,能够理解客户询问的上下文与语义细节,从而生成更准确、有用的响应。
(图 1-10 显示了吸引当代客户的关键要素)
1.7.3 成果与收益
ABC 公司实施 NLP 后获得了多项显著收益,包括提升的客户满意度、改进的响应速度、可操作性洞见、运营可扩展性与成本降低等:
- 响应时间改善:引入聊天机器人后,ABC 能对大量询问提供即时响应,大幅缩短客户等待时间。
- 降本增效:随着聊天机器人承担大量询问处理工作,公司能减少夜间/全天候的人力配置,节省成本。
- 可操作性洞见:对客户感知与痛点的洞察使公司能主动改进产品与服务。
- 可扩展运营:高自动化水平让业务在高峰期也能以较低成本扩展。当前高峰时段约有 80% 的询问在无需人工干预的情况下被自动回复。
1.7.4 结论
多种 NLP 解决方案的采用改变了 ABC 公司的客户服务模式。自动化增强了客户互动与运营效率:自动聊天机器人、情感分析、文本分类与自然语言理解被用于提升运营效率。ABC 在很大程度上解决了主要挑战并获得显著收益。随着公司继续扩张,计划进一步优化其 NLP 能力,以在激烈的电商竞争中持续提升客户体验并保持竞争优势。
1.8 Python 示例
本节给出一个 NLP 入门教程并配以说明性注释。所用 Python 代码均带有注释。业务问题是预测测试推文的正负情感(positive/negative)。训练数据带有标签,测试数据无标签。我们的任务是编写 Python 代码预测测试推文并评估模型的 F1 分数。示例中我们使用随机森林(Random Forest)算法进行预测。
1.8.1 NLP 教程
1.8.2 使用 Python 进行 YouTube 评论垃圾信息检测(Spam Detection)
第一个 NLP 教程使用 YouTube Spam Collection Dataset。我们采用一种简单方法将文本转换为机器学习可处理的数值格式,然后使用随机森林算法构建模型,最后对目标变量做预测并评估模型准确性。本书假定你已有基本的 Python 以及机器学习/深度学习(神经网络)建模经验。下面开始写代码并在编写过程中理解它。
python
# 导入所需库
import pandas as pd
import numpy as np
# 以下用于机器学习模型相关操作
from sklearn import feature_extraction, linear_model, model_selection, preprocessing
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 忽略警告
import warnings
warnings.filterwarnings('ignore')数据准备
读取与查看数据:
ini
# 读取与本代码同一文件夹下的数据文件
Youtube01_psy = pd.read_csv('Youtube01-Psy.csv')
Youtube02_katyperry = pd.read_csv('Youtube02-KatyPerry.csv')
Youtube03_lmfao = pd.read_csv('Youtube03-LMFAO.csv')
Youtube04_eminem = pd.read_csv('Youtube04-Eminem.csv')
Youtube05_shakira = pd.read_csv('Youtube05-Shakira.csv')
# 查看各数据集的大小
print(Youtube01_psy.shape)
print(Youtube02_katyperry.shape)
print(Youtube03_lmfao.shape)
print(Youtube04_eminem.shape)
print(Youtube05_shakira.shape)
# 输出示例:
# (350, 5)
# (350, 5)
# (438, 5)
# (448, 5)
# (370, 5)
# 合并所有五个数据集
combined_df = pd.concat([Youtube01_psy, Youtube02_katyperry, Youtube03_lmfao, Youtube04_eminem, Youtube05_shakira])
# 重置索引
combined_df.reset_index(drop=True, inplace=True)
combined_df.head(3)(示例输出略;数据表结构包含 COMMENT_ID, AUTHOR, DATE, CONTENT, CLASS 等列)
ini
# 仅选择有用的 "CONTENT" 与 "CLASS" 列
combined_df = combined_df[["CONTENT", "CLASS"]]
# 随机抽取 5 行查看
random_sample = combined_df.sample(n=5)
print(random_sample)
# 查看数据集大小
combined_df.shape
# (1956, 2)
# 将特征与目标分离
X = np.array(combined_df['CONTENT'])
y = np.array(combined_df['CLASS'])
X.shape
# (1956,)向量化(Building Vectors)
文本中出现的词是判定是否为垃圾信息的重要线索。下面使用 scikit-learn 的 CountVectorizer 统计词频并将文本转换为机器可用的数值向量(vector)。
scss
demo_text = ["Stella is a good girl. She loves to swim"] # 示例句子
count_vectorizer = feature_extraction.text.CountVectorizer() # 实例化 CountVectorizer
count_vectorizer.fit(demo_text) # 拟合示例文本
print(count_vectorizer.vocabulary_) # 打印词表映射
# 输出示例:{'stella': 5, 'is': 2, 'good': 1, 'girl': 0, 'she': 4, 'loves': 3, 'to': 7, 'swim': 6}
# 对文档编码
demo_vector = count_vectorizer.transform(demo_text)
print(demo_vector.shape)
print(demo_vector.toarray())
# 输出:
# (1, 8)
# [[1 1 1 1 1 1 1 1]]示例解释:向量长度为 8,对应 8 个不同词;每个词在文本中均只出现一次,因此向量元素均为 1。
再举一例:
scss
demo_text2 = ["The sky is blue. I wish to fly in the blue sky"] # 示例句子 2
count_vectorizer = feature_extraction.text.CountVectorizer() # 实例化 CountVectorizer
count_vectorizer.fit(demo_text2) # 拟合示例文本
print(count_vectorizer.vocabulary_)
# 输出示例:{'the': 5, 'sky': 4, 'is': 3, 'blue': 0, 'wish': 7, 'to': 6, 'fly': 1, 'in': 2}
# 编码文档
demo_vector = count_vectorizer.transform(demo_text2)
print(demo_vector.shape)
print(demo_vector.toarray())
# 输出:
# (1, 8)
# [[2 1 1 1 2 2 1 1]]这里"the"、"sky"、"blue"在文本中出现两次,因此对应的向量值为 2。
对前五条内容统计词向量:
ini
## 对 combined_df 中前 5 条 CONTENT 生成向量计数
demo_vectors = count_vectorizer.fit_transform(combined_df['CONTENT'][0:5])
type(demo_vectors)
# 输出类型:scipy.sparse._csr.csr_matrix
demo_vectors.shape
# (5, 46)
# 使用 .todense() 查看稠密表示(因向量为稀疏矩阵)
print(demo_vectors[0].todense().shape)
print(demo_vectors[0].todense())
# 输出示例:
# (1, 46)
# [[0 1 0 1 1 ... 1]]解释要点:
- 前 5 条样本在词表中共有 46 个不同 token(词)。
- 每条推文只包含这些 token 的一部分,因此向量以稀疏形式保存。
继续为所有数据条目构建代表性向量并划分训练/测试集:
ini
combined_df.shape
# (1956, 2)
X.shape
# (1956,)
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
X_train.shape
# (1369,)
X_test.shape
# (587,)
# 对文本向量化:训练集使用 fit_transform,测试集只使用 transform
X_train = count_vectorizer.fit_transform(X_train)
X_test = count_vectorizer.transform(X_test) # 测试集只 transform
X_train.shape
# (1369, 3458)
X_test.shape
# (587, 3458)构建与训练简单机器学习模型(随机森林),并以 F1 作为评估指标:
ini
# 初始化随机森林模型
clf = RandomForestClassifier(n_estimators=100, random_state=42)
# 使用交叉验证评估(3 折)的 F1 分数
scores = model_selection.cross_val_score(clf, X_train, y_train, cv=3, scoring="f1")
scores
# 可能输出举例:array([0.95067265, 0.95594714, 0.95594714])交叉验证的 F1 分数看起来不错!你还可以使用本书后续章节介绍的其他 NLP 技术进一步提升效果。
训练模型并在测试集上做预测:
ini
clf.fit(X_train, y_train)
# 训练完成后对测试集预测
y_pred = clf.predict(X_test)
y_pred.shape
# (587,)
# 构造包含真实值与预测值的 DataFrame
test_df = pd.DataFrame()
test_df["y"] = y_test
test_df["y_predict"] = y_pred
# 随机显示 10 条预测结果
random_sample = test_df.sample(n=10)
print(random_sample)
# 示例输出(y 为真实标签,y_predict 为预测标签)结语:我们在此处结束示例,预测效果不错。需要注意的是,真实世界的分析应在测试集上计算 F1 等评估指标;本示例略去该步骤。
注意:本教程省略了大量的数据清洗与预处理步骤,但已经得到相对令人满意的模型结果。第 5 章将再次使用相同的示例,并在那时进行更充分的数据清洗,看看模型结果是否进一步改进。
本示例仅为演示用途,过于简化。至此,本部分示例结束。
1.9 关键概念回顾
本章对自然语言处理(NLP)及其在当今产业格局中的影响做了全面的梳理。章首说明了 NLP 的重要性,随后深入介绍了当下 NLP 领域常用的基础技术。接着讨论了若干核心概念,包括文本分类、聚类与搭配(collocation)。其它重要流程诸如词频统计、文本抽取、词义消歧(WSD)与停用词去除也在文中有所阐述,并说明了 NLP 如何解决同一词在不同语境中意义混淆的问题。本章还探讨了 NLP 面临的挑战。
随后文本扩展到 NLP 在各行业的真实应用场景,包括银行与金融服务领域、用于分析财务文档的 NLP、以及通过聊天机器人与个人数字助理实现客户交互自动化。在医疗健康领域,NLP 用于文本分析并通过增强的数据洞见改善患者护理。在法律界,NLP 被用于文档审查、法律检索、文本摘要与其它常规业务流程的自动化。章节还强调了 NLP 的最新趋势与未来方向,如迁移学习、LLM 与跨语种模型等------这些较新的 NLP 应用正推动更复杂、更类人的交互系统的发展。
最后,本章包含两个简短的行业商业案例:第一个聚焦医学文本分析,展示 NLP 工具如何增强医疗信息的提取与解读;第二个考察 NLP 在客户服务与业务外包中的应用。章末还有一个完整解答的 Python 实战案例,演示如何在推文分析中应用 NLP 的关键概念。该教程的主要目的是帮助你入门并启动在 NLP 领域的 Python 编程实践。
1.10 结论
本章对 NLP 的概览足以帮助你建立对 NLP 在现代技术中关键作用的全面认识。本章有助于掌握若干基本 NLP 技术,如文本分类、聚类与词义消歧(WSD),为理解 NLP 如何分析非结构化文本数据奠定基础。对 NLP 所面临挑战的讨论能帮助你理解构建能处理语言细微差别的健壮系统时所涉及的复杂性。NLP 在银行与金融、医疗和法律等多个行业中的多样化应用凸显了其长期的变革性影响:NLP 可自动化常规业务(如 SEO)、改进现代搜索引擎的检索能力、实现跨语言翻译、进行文本摘要并改善客户互动,从而在实际商业场景中创造价值。
展望未来,本章审视了 NLP 研究的最新趋势与未来方向(即迁移学习、LLM 与跨语种能力),以凸显该领域的持续进展。持续的 NLP 研究对于应对不断演化的挑战并提升现有系统的有效性至关重要------在 NLP 领域不断探索与发展的过程中,才能真正发挥其全部潜能。
1.11 练习
我们在本章中使用分类技术解决了教程问题。试着应用聚类算法(例如 k-means)将文本样本按相似度分成若干簇。
a. 聚类能否帮助识别训练数据中的潜在模式或主题?
b. 做一场展示:两组分别展示它们的分类与聚类结果,并讲解流程与遇到的挑战。
c. 讨论要点:
a. 文本分类与聚类如何帮助组织数据?
b. 本次练习中遇到的主要挑战是什么?
c. 这些技术如何应用于现实场景?
阅读本章给出的两则简短商业案例,并准备一份小型课堂展示,讨论以下内容:
a. 不同行业最常用的 NLP 技术有哪些?
b. 在每个案例中,NLP 如何提升效率与效果?
c. 对这些行业而言,NLP 未来可能的发展方向是什么?
在 Python 教程问题中应用 TF--IDF(term frequency--inverse document frequency,词频---逆文档频率)。你是否观察到结果有所改进?该技术将在后续章节中讲解。
参考文献(References)
- Alberto, T. C. and Lochter, J. V. (2017). YouTube Spam Collection. UCI Machine Learning Repository. doi.org/10.24432/C5....
- Amazon Web Services (2024). Available at: aws.amazon.com/what-is/nlp.... Last Accessed: July 6, 2024.
- IBM (2024). Available at: www.ibm.com/topics/natu.... Last Accessed: July 6, 2024.
- Donges, N. (2023). Introduction to Natural Language Processing (NLP), Available at: builtin.com/data-scienc.... Last Accessed: July 6, 2024.
- Srinivasa-Desikan, B. (2018). Natural Language Processing and Computational Linguistics: A Practical Guide to Text Analysis with Python, Gensim, spaCy, and Keras. Packt Publishing Ltd.
- Duarte, F. (2024). Amount of Data Created Daily, Available at: explodingtopics.com/blog/data-g.... Last Accessed: July 6, 2024.
- El Naqa, I., and Murphy, M. J. (2015). What is machine learning? (pp. 3-11). Springer International Publishing.
- Suhail, A. (2023). Text Multi-Classification with Flair NLP. Available at: medium.com/tensor-labs.... Last Accessed: July 9, 2024.
- Zhou, X., and Han, H. (May 2005). "Survey of Word Sense Disambiguation Approaches." In FLAIRS (pp. 307--313).
- Ittoo, A., and van den Bosch, A. (2016). "Text analytics in industry: Challenges, desiderata and trends." Computers in Industry, 78, 96--107.
- Text Summarization- An emerging NLP technique for your business requirements, Available at: medium.com/@annoberry/.... Last Accessed: July 13, 2024.
- Geeksforgeeks (2024). Machine Translation in AI, Available at: www.geeksforgeeks.org/machine-tra.... Last Accessed: July 13, 2024.
- Annoberry Technology Solutions (2022). Text Summarization: An emerging NLP technique for your business requirements. Last Accessed: July 13, 2024.
- Becker, C., Hahn, N., He, B., Jabbar, H., Plesiak, M., Szabo, V., ... and Wagner, J. (2020). Modern Approaches in Natural Language Processing. LMU Munich, Munich.
- Wang, H., Li, J., Wu, H., Hovy, E., and Sun, Y. (2022). Pre-trained language models and their applications. Engineering.
- Kasneci, E., Seßler, K., Küchemann, S., Bannert, M., Dementieva, D., Fischer, F., and Kasneci, G. (2023). "ChatGPT for good? On opportunities and challenges of large language models for education." Learning and Individual Differences, 103, 102274.
- Thirunavukarasu, A. J., Ting, D. S. J., Elangovan, K., Gutierrez, L., Tan, T. F., and Ting, D. S. W. (2023). Large language models in medicine. Nature Medicine, 29(8), 1930--1940.
- Søgaard, A. (2021). Explainable natural language processing. Morgan & Claypool Publishers.
- Ariwals, P. (2024). Top 14 Use Cases of Natural Language Processing in Healthcare. Available at: marutitech.com/use-cases-o.... Last Accessed: July 21, 2024.
- Khubwani, H. (2023). Why Customer Experience Should be the Top Accessory in the Fashion Industry. Available at: www.clootrack.com/blogs/custo.... Last Accessed: July 21, 2024.