一、SOD任务的含义、特性、分类
小目标的定义
将目标物的bbox表示为 ( x , y , w , h ) (x,y,w,h) (x,y,w,h)
小目标:短边长度不小于4像素,长边不超过32像素。
m i n ( w , h ) ≥ 4 p i x e l m a x ( w , h ) ≤ 32 p i x e l min(w,h) \ge 4 pixel \\ max(w,h) \le 32 pixel min(w,h)≥4pixelmax(w,h)≤32pixel
学术界还细分为:
- 小目标检测:SOD(Small Object Detection)
- 微小目标检测:TOD(Tiny Object Detection)
但具体的标准没有明确的标准,这里都统称为小目标检测
小目标的特性
- 小目标之间的交叠概率比较低,即使有交叠,其IoU多数情况下也是比较小的


- 小目标自身的纹理显著度有强弱区别,但是总体来说纹理特征都较弱,很多时候需要借助一定的图像上下文来帮助确认

如图左侧的图片,人都很难判断是什么。但是不断添加上下文信息,看到人的身体轮廓,人肉眼就能识别出是人脸。
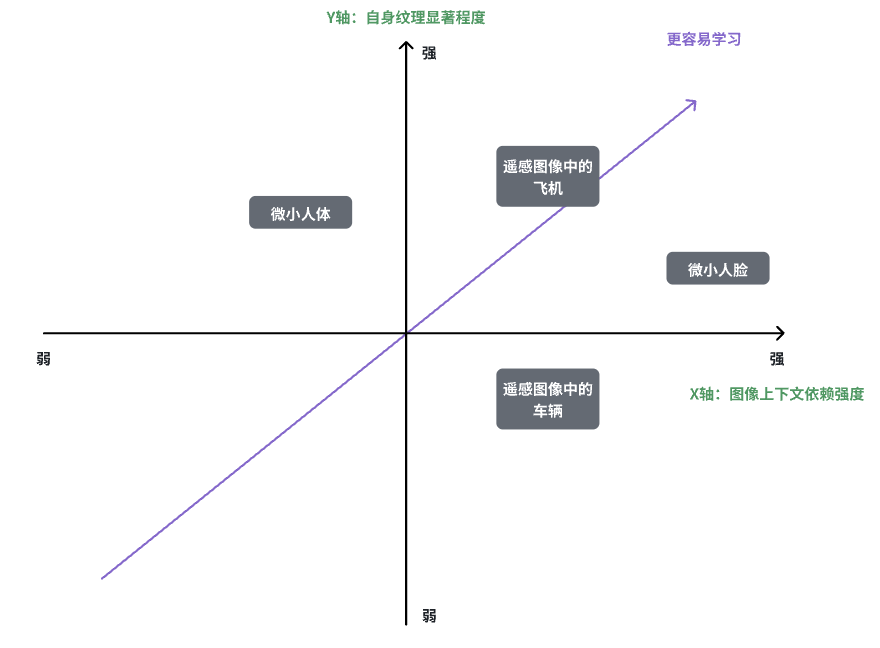
小目标的分类
分类依据:
- 图像上下文的依赖程度
- 比如微小人脸,他是人身体的一部分,所以有身体就能确定是人脸。
- 而微小人体,背景可以随意换,所以上下文变化很大,依赖程度低。
- 一般目标是a bart of类的,就都是上下文依赖程度强的。
- 自身纹理显著程度
- 比如飞机,轮廓特征就很明显,纹理特征显著。
- 车辆就是一个矩形,很容易和其他物体混淆。
二、基于感受野的理论推出backbone的设计原则
各个backbone的感受野
做任何尺寸目标的检测任务,模型都需要达到一定的感受野。
由于有效感受野不能被精确计算,所以理论感受野必须要大于目标尺度。
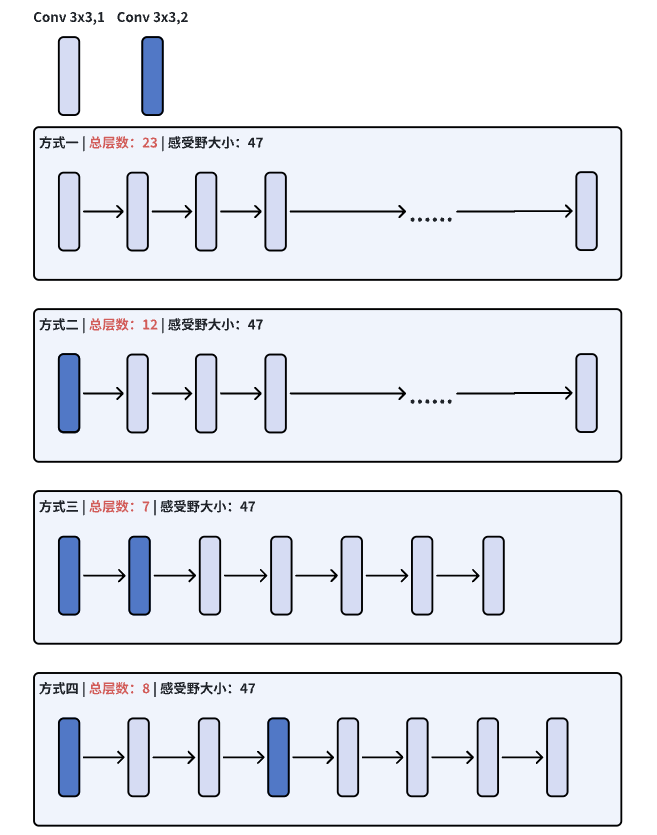
要达到某个固定的理论感受野数值,网络结构如何设计。
这里只选取两个层,
- 3x3步长为1的卷积
- 3x3步长为2的卷积,用于下采样
达到相同的感受野,有很多不同的设计方式
基本认识:在不考虑宽度的情况下,网络深度越深(合理范围内),通常来说更有利于特征学习
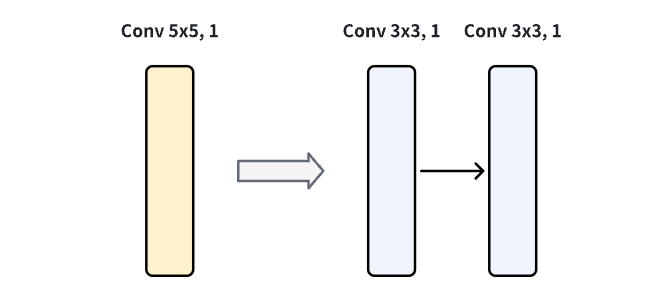
很早就发现,把一个5x5的卷积换成两层3x3的卷积,有利于特征学习,参数量少了,感受野增量相同。
对于大多数推理来说,优化的最好的OP为,3x3和1x1的卷积操作。
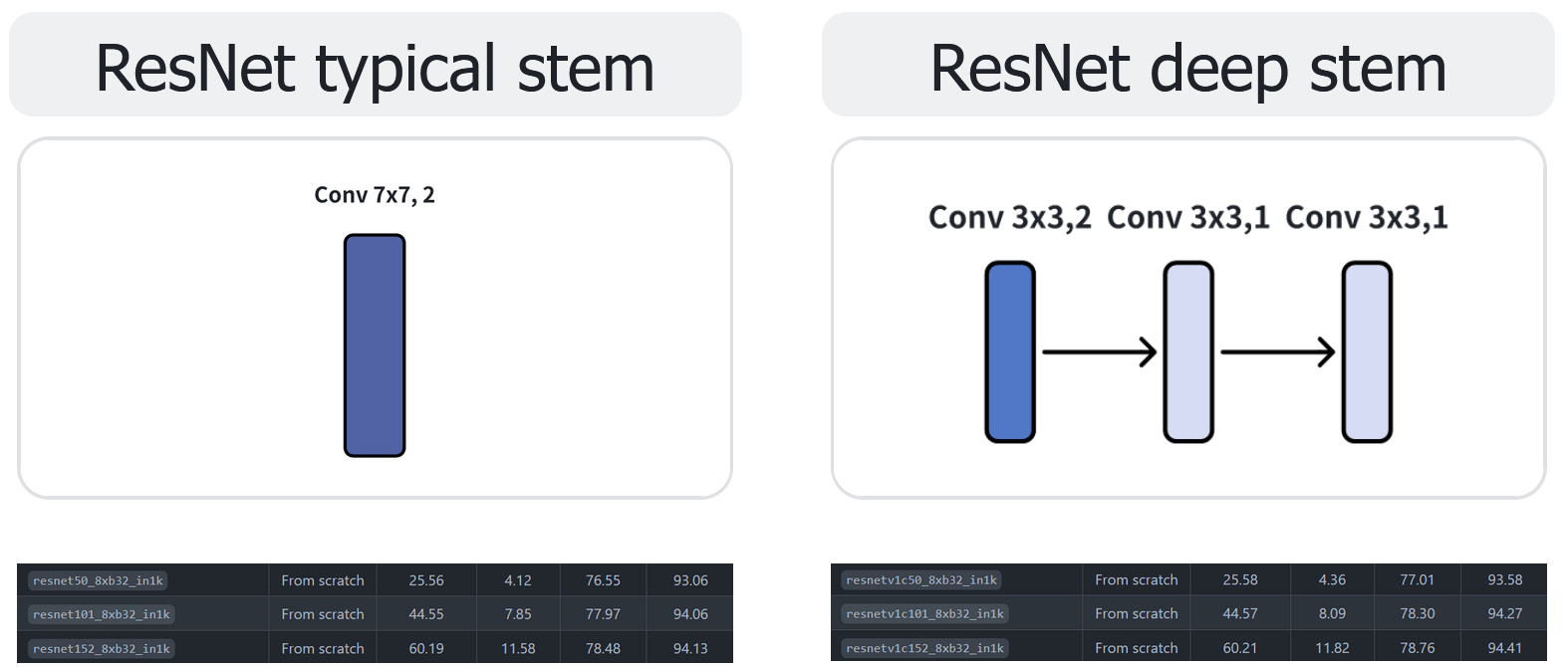
对于ResNet 有两个版本,
- typical stem是7x7,步长为2的。感受野为7
- deep stem 是三个3x3卷积,第一个步长为2,后两个步长为1。感受野为11
deep stem版本的精度高于typical stem 版本
参考:https://github.com/open-mmlab/mmpretrain/tree/main/configs/resnet
-
一个不严谨的共识:在达到相同大小感受野的情况下,网络越深越好。那么方式一,也就是全用步长为1的3x3卷积,达到相同感受野的同时有最深的深度。但实际要权衡速度和精度。
-
二次加工以后的共识:在确保网络结构在各种资源消耗可行 的前提下,达到相同大小感受野 的情况下,网络越深越好
关注步长为2的卷积所在位置 ,控制的是达到某个大小感受野的网络深度。对于小目标检测,精心设计放置步长为2卷积的位置以及数量非常重要。
- 如果有多个步长为2的卷积,那么它越多,网络越浅
- 如果只有一个步长为2的卷积,那么它越靠前,网络越浅
小目标检测backbone的设计
为了有利于小目标检测的特征学习:
- 使用步长为2的卷积替代pooling操作进行下采样
- 避免使用步长超过2的卷积,比如步长为4的卷积
- 在两个步长为2的卷积之间,需要加入若干步长为1的卷积,这里可以是3x3的卷积也可以是1x1的卷积
- 达到预期感受野大小的前提下,尽可能让网络更深,但是要把握好各项资源消耗和精度的平衡,要具备可行性
三、Neck的设计
feature map
普通目标检测网络中,neck的两大核心作用:
- 分而治之:FPN能将backbone上的特征图融合后,输出多个不同大小的特征图。不同尺度的目标,分别由不同的特征图进行预测。大目标分配到低分辨率的feature map,小目标分配到高分辨率的feature map
- 目标匹配:这个目标因该被分配到哪个分辨率的特征图,这个feature map 的那些points负责预测这个目标。
然而小目标检测网络中,上述Neck的两大核心作用发生变化:
- 分而治之将不再重要
- 目标匹配也不再错综复杂
检测任务中最小学习样本不是一个图像,而是feature map 上的 point,因为每个point都是被单独监督的。
要增多小目标的学习样本,就是要更多的point被小目标bbox覆盖,就会有 更多的学习机会,成功检测的概率就增加。
所以目的简化为小目标能被更多的points学到。
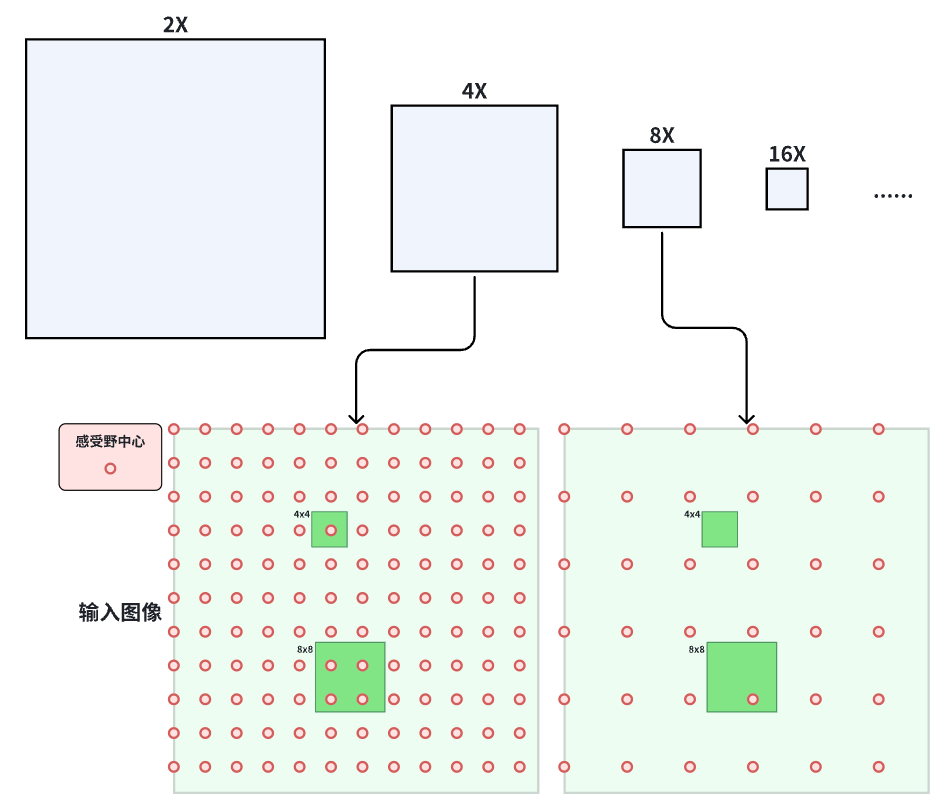
- P1虽然分辨率最高,但是计算量太大,得不偿失。
- P2:4x4的小目标,仅会覆盖一个Anchor point
- P3:比8x8更小的目标,可能覆盖不到Anchor point。目标越小,覆盖概率越低。
计算一个bbox会有多少感受野中心命中:
N h i t = ⌊ W b b o x / S w ⌋ × ⌊ H b b o x / S h ⌋ N_{hit} = \lfloor W_{bbox}/S_{w}\rfloor \times \lfloor H_{bbox}/S_{h}\rfloor Nhit=⌊Wbbox/Sw⌋×⌊Hbbox/Sh⌋
W b b o x , H b b o x W_{bbox}, H_{bbox} Wbbox,Hbbox分别是bbox的宽和高, S w , S h S_w, S_h Sw,Sh分别是特征图在宽和高方向上的步长,通常它们相等。
Neck的设计
- 使用更高分辨率的特征图(如P2层)对小目标进行检测,这会显著增多小目标的学习样本数
- 有更多的point命中目标 ,就意味着目标有更多的被学习到的机会 ,也就是变相增多了目标的样本数
- 增加更多的多个不同分辨率的特征图 对小目标进行检测,不仅增多了目标的样本数,更多的anchor point 负责预测,同时提供了更多感受野大小的可能性,提升目标被准确预测的概率
- 使用朴素的命中(覆盖中心)即匹配的策略,可以确保上述两点中增多样本学习数的结论,这种匹配机制简单有效。