引言
Go语言相比C++、Java等语言,最大的特点就是在内置的并发支持。Go语言内置了轻量级的并发机制------协程Goroutine 和通道Channel 。Goroutine的内存占用极小,可以轻松支持数十万级别的并发任务。通过通道,开发者可以方便地实现线程间通信,避免复杂的锁机制。
通过这篇文章,你将学习以下内容:
- 线程的概念和机制
- 协程Goroutine的概念和机制
- 通道Channel的概念和机制
一、线程
什么是线程
多线程、线程同步、线程安全.....相信经常大家一定经常听到这些词语,那么请问你真的能描述清楚线程到底是个什么玩意儿吗?
这里参考stackoverflow上的一个高赞回答:线程是一个执行上下文,它包含 CPU 执行指令流所需的所有信息
什么是 "执行上下文"?(用考试周复习举例)
考试周到了,明天考数学和物理,今天你在临时抱佛脚复习《高等数学》和《大学物理》。你打算交替复习,那么从一本书切换到另一本书时,怎么从之前的进度继续往后复习?
你可以记下「课本、页码、行数、第几个字」这几个信息。等你回来,只要根据这几个信息,就能从上次停下的地方继续往后看。
这里的「课本 + 页码 + 行数 + 字数」,就是你"复习"这件事 的执行上下文:它记录了 "继续复习" 所需要的全部关键信息。
线程就是 CPU 的 "执行上下文"
CPU 的工作是 "执行一串指令"(比如计算 1+1、打开文件),但 CPU 同一时间只能真正 "跑" 一个指令流。那为什么我们用电脑时,能同时聊微信、听音乐、写文档?
这是 CPU 玩的 "障眼法":它给每个任务(聊微信、听音乐)都记了一套 "执行上下文",然后快速在不同任务间切换 ------ 先给 "微信" 跑几十毫秒,记住它的上下文(比如当前处理到哪条消息、临时数据存在哪),再切到 "音乐" 跑几十毫秒,同样记住上下文...... 因为切换速度极快(毫秒级),我们就感觉这些任务在 "同时运行"。
而线程,就是 CPU 给每个任务分配的 "执行上下文容器":
- 它装着 CPU 执行这个任务所需要的所有信息(比如临时数据存在 CPU 寄存器里的值、当前执行到哪条指令的地址);
- 多个线程可以 "共享" 一个 CPU:CPU 切换线程时,只需保存当前线程的上下文,再加载下一个线程的上下文,就能无缝继续执行。
技术细节:线程的执行上下文具体是什么?
从硬件角度看,线程的执行上下文核心是CPU 寄存器的值:
CPU 里有一些临时存储数据的 "小格子"(寄存器,比如存计算结果的 EAX 寄存器、存指令地址的 IP 寄存器)。执行任务时,CPU 会把临时数据存在这些寄存器里;切换任务前,先把这些寄存器的值 "抄下来" 存在线程的上下文里;等下次切回这个线程,再把 "抄下来的值" 填回 CPU 寄存器 ------ 这样 CPU 就像没中断过一样,继续处理这个任务。
-
切换前:保存当前线程(A)的寄存器值
当操作系统决定暂停线程 A,切换到线程 B 时,首先要做的是:
把 CPU 寄存器里当前所有的值(线程 A 的指令地址、临时数据、状态标记等)复制到内存中专门为线程 A 开辟的 "线程控制块(TCB)" 里。
-
切换后:加载目标线程(B)的寄存器值
保存完线程 A 的状态后,CPU 会从线程 B 的 "线程控制块(TCB)" 里,把之前保存的线程 B 的寄存器值(比如 B 上次暂停时的指令地址、临时数据)复制回 CPU 寄存器。
关键区分:线程(Thread)≠ 进程(Process)
-
线程是 "执行上下文" :负责 "跑指令",是 CPU 调度的最小单位(CPU 只认线程);
-
进程是 "资源集合" :负责 "装资源",是操作系统分配资源的最小单位(比如内存、文件、权限)。
更通俗的比喻:
把 "用浏览器看视频" 这件事拆成:
-
进程:浏览器这个 "资源包"------ 里面装着 "视频页面的内存数据"(比如视频缓存)、"打开的网络连接"(比如和视频服务器的 socket)、"你的用户权限"(比如你能看会员视频);
-
线程:浏览器里的多个 "执行任务"------ 比如 "播放视频" 线程(跑播放指令)、"接收弹幕" 线程(跑加载弹幕的指令)、"处理鼠标点击暂停" 线程(跑响应操作的指令)。
它们的关系是:
-
一个进程里可以有多个线程(比如浏览器进程里有播放、弹幕、点击 3 个线程);
-
同一进程的所有线程,会共享进程的资源(比如 3 个线程都能访问浏览器的内存、网络连接,不用各自再申请一份);
-
线程只负责 "执行指令",不单独拥有资源(比如 "播放线程" 没有自己的内存,用的是浏览器进程的内存)。
总结
-
线程 = CPU 的 "任务书签"(执行上下文),让 CPU 能快速切换任务,假装 "同时做事";
-
进程 = "资源包",装着任务需要的内存、文件等,同一进程的线程共享这些资源;
-
我们平时说的 "多任务",本质是 "多线程"------CPU 在不同线程间切换,而线程依赖进程的资源才能跑起来。
线程的开销
内存开销
线程的内存开销仅指 线程独自占用、其他线程无法共享 的内存资源(排除进程共享的堆内存、全局变量、共享库等),核心由 4 个模块构成,其中 用户态栈是绝对主力,占比超过 90%。
用户态栈:最大头的内存开销
-
作用:存储线程执行时的临时数据,包括函数局部变量(如
int a=10)、函数调用栈帧(参数、返回地址、临时计算结果)、函数返回值。遵循 "先进后出(LIFO)" 规则,由编译器和操作系统自动管理(无需手动分配 / 释放)。 -
大小特征:
- 预分配机制:操作系统在创建线程时,会为其预分配一块连续的虚拟内存作为用户态栈(避免运行时动态扩容的性能波动);
- 系统差异大:不同操作系统的默认大小相差一个数量级,且支持手动调整(需平衡 "栈溢出风险" 和 "内存浪费")。
-
关键影响:用户态栈是线程内存开销的 "决定性因素"------ 例如,Linux 默认线程的 8MB 内存中,8MB 均为用户态栈,其他模块仅占几十 KB。
内核栈:固定的小开销
-
作用:线程进入内核态(如调用系统调用、处理中断 / 异常)时使用的栈,与用户态栈完全隔离(避免用户代码污染内核数据)。例如,线程调用
read()读取文件时,内核会在该线程的内核栈中存储系统调用参数、内核函数栈帧。 -
大小特征:
- 固定大小:由操作系统内核硬编码配置,不支持用户手动调整(需保证内核操作的安全性和稳定性);
- 数值极小:通常在几 KB 到十几 KB,远小于用户态栈。
线程控制块(TCB / 线程元数据):管理线程的 "身份证"
-
作用:操作系统内核用于管理线程的元数据结构,存储线程的核心状态信息,包括:
- 线程 ID(TID)、优先级、状态(就绪 / 运行 / 阻塞);
- 寄存器上下文(如指令地址 IP、栈指针 SP,用于切换时恢复执行);
- 内核栈指针、用户态栈指针;
- 关联的进程 ID(PID)、资源限制(如 CPU 时间配额)。
-
大小特征:
- 结构体大小固定:不同操作系统的 TCB 结构体字段差异不大,大小通常在 1KB~3KB;
- 内核分配:TCB 存储在内核空间(用户代码无法直接访问),由内核在创建线程时自动分配。
线程私有数据(TLS:Thread-Local Storage):按需分配的开销
-
作用:存储线程的 "局部全局变量"------ 即仅当前线程可见、其他线程无法访问的全局变量(如 C++ 的
thread_local、Java 的ThreadLocal)。例如,线程内的日志 ID、数据库连接池实例。 -
大小特征:
- 按需分配:若线程不使用 TLS,此部分开销为 0;若使用,开销等于 "变量大小 + TLS 管理结构大小"(管理结构通常几十字节);
- 动态扩容:部分系统支持 TLS 空间动态扩容(如 Linux 的
pthread_key_create),但默认上限较低(如最多支持 1024 个 TLS 键)。
-
示例:线程使用 1 个
thread_local std::string(存储 100 字节字符串),TLS 总开销≈100 字节(变量)+32 字节(管理结构)=132 字节。
内存开销的核心影响:限制并发规模
线程的内存开销直接决定了系统可创建的最大线程数 ------ 例如:
-
1GB 物理内存下,按 Linux 默认 8.0184MB / 线程计算,最多可创建 ≈ 1GB / 8MB = 128 个线程;
-
若调整用户态栈为 16KB,1GB 内存可创建 ≈ 1GB / 34.4KB ≈ 29000 个线程(但需内核支持,且栈溢出风险升高)。
这也是为什么传统线程无法支撑 "百万级并发"------ 内存开销会先于 CPU 资源耗尽。
调度开销
线程的调度开销是指 操作系统内核将 CPU 从 "执行线程 A" 切换到 "执行线程 B" 时消耗的 CPU 时间,核心来自 "上下文保存 / 加载" 和 "内核调度决策",是线程并发性能的关键瓶颈(高频切换会导致 CPU 资源被浪费在切换上,而非实际任务执行)。
调度开销的触发场景:什么时候会切换线程?
线程切换由操作系统内核的 "调度器" 触发,常见场景包括:
-
时间片耗尽:每个线程被分配一个 "时间片"(如 10ms),时间片用完后,调度器强制切换到下一个就绪线程;
-
线程阻塞:线程执行 IO 操作(如
read/write)、等待锁(如pthread_mutex_lock)或睡眠(如sleep(1))时,主动放弃 CPU,调度器切换到其他就绪线程; -
高优先级抢占:高优先级线程从 "阻塞" 变为 "就绪" 时,调度器会立即暂停当前低优先级线程,切换到高优先级线程(抢占式调度);
调度开销的核心构成:三步消耗 CPU 资源
(1)保存当前线程(A)的上下文(约 50~100ns)
-
操作内容:将线程 A 的 "寄存器上下文" 和 "状态信息" 保存到其 TCB 中,核心包括:
-
用户态寄存器:指令地址寄存器(IP/EIP)、栈指针寄存器(SP/ESP)、通用寄存器(EAX/EBX/ECX 等,共 16 个 64 位寄存器)、浮点寄存器(如 SSE 寄存器,若线程使用浮点运算);
-
内核态状态:线程 A 的当前状态(如从 "运行" 改为 "就绪 / 阻塞")、剩余时间片、资源使用统计(如 CPU 时间累计)。
-
-
开销来源:
-
寄存器数据复制:每个寄存器 8 字节(64 位),16 个通用寄存器 + 1 个 IP+1 个 SP=18 个寄存器,共 144 字节,需从 CPU 寄存器复制到内存中的 TCB(内存访问速度远慢于 CPU);
-
状态标记更新:修改 TCB 中的线程状态字段,需执行内核指令(如
mov/store)。
-
(2)内核调度器决策(约 10~50ns)
-
操作内容:调度器从 "就绪线程队列" 中选择下一个要执行的线程(B),核心逻辑包括:
-
遍历就绪队列:按调度策略筛选符合条件的线程;
-
优先级排序:优先选择高优先级线程,若优先级相同,选择 "累计 CPU 时间最少" 的线程;
-
资源检查:确认线程 B 所需的资源(如 CPU 核心、内存页)已就绪。
-
-
开销来源:
-
队列遍历:就绪队列通常用链表或红黑树实现,遍历操作需消耗 CPU 周期(若就绪队列过长,开销会显著增加);
-
策略计算:调度器需计算 "虚拟运行时间",涉及除法、比较等运算(耗时高于简单遍历)。
-
(3)加载目标线程(B)的上下文(约 50~100ns)
-
操作内容:将线程 B 的 "寄存器上下文" 从其 TCB 中加载回 CPU 寄存器,核心包括:
-
从 TCB 中读取线程 B 的 IP、SP、通用寄存器、浮点寄存器值;
-
将这些值写入 CPU 对应的寄存器(如将 IP 值写入 EIP 寄存器,确保 CPU 从线程 B 的断点继续执行);
-
更新内核态状态:将线程 B 的状态从 "就绪" 改为 "运行",分配新的时间片。
-
-
开销来源:
-
内存读取:从 TCB(内存)读取寄存器数据到 CPU,受内存延迟影响(约 60~100ns / 次);
-
寄存器写入:CPU 寄存器写入本身极快(1~2ns / 个),但需等待内存数据读取完成,总耗时取决于内存速度。
-
隐藏开销:缓存失效(占比最高,约 100~300ns)
上述三步是 "显性开销",而缓存失效是更关键的 "隐性开销"------ 线程切换后,CPU 缓存(L1/L2/L3)中存储的 "线程 A 的指令和数据" 会失效,线程 B 的指令和数据需从内存重新加载到缓存,导致大量 "缓存缺失"(Cache Miss),耗时远高于显性开销。
总结
内存开销特点
-
用户态栈主导:占总内存开销的 90% 以上,调整用户态栈大小是优化内存开销的关键;
-
系统差异大:Linux 默认 8MB 栈,Windows 默认 1MB 栈,跨平台开发需注意栈溢出风险;
-
限制并发规模:默认配置下,线程并发数上限为 "千级",无法支撑百万级并发。
调度开销特点
-
缓存失效是主因:占总调度开销的 50% 以上,减少线程切换频率是降低调度开销的核心;
-
依赖调度策略:CFS 调度器在就绪线程少的场景下高效,线程多则开销增加;
-
IO 密集型场景敏感:线程频繁阻塞导致切换频繁,开销占比骤升。
通过以上拆解可见:线程的内存开销和调度开销均源于其 "内核级管理" 的定位 ------ 内核为保证线程的稳定性,分配了大栈和完整上下文,但也导致其在高并发场景下的开销过高。这也是为什么在 IO 密集、高并发场景中,协程(用户态管理、轻量开销)逐渐取代线程成为主流选择。
二、Goroutine
上面讨论了操作系统线程存在的一些弊端,那么Goroutine是如何解决操作系统线程存在的问题呢?
根据下图快速理解一下Goroutine跟操作系统线程的关系:多任务并发时,其实是操作系统给每个线程分配了CPU时间片例如0.1ms, 即每个线程最多占用CPU的时间为0.1ms。线程在分配给自己的CPU时间片中,如果执行的任务很快就完成,那么剩余的CPU时间会浪费掉。那么如何将线程的CPU时间片充分利用于任务的执行呢?Goroutine就是Go语言针对这种问题而设计的一套机制。
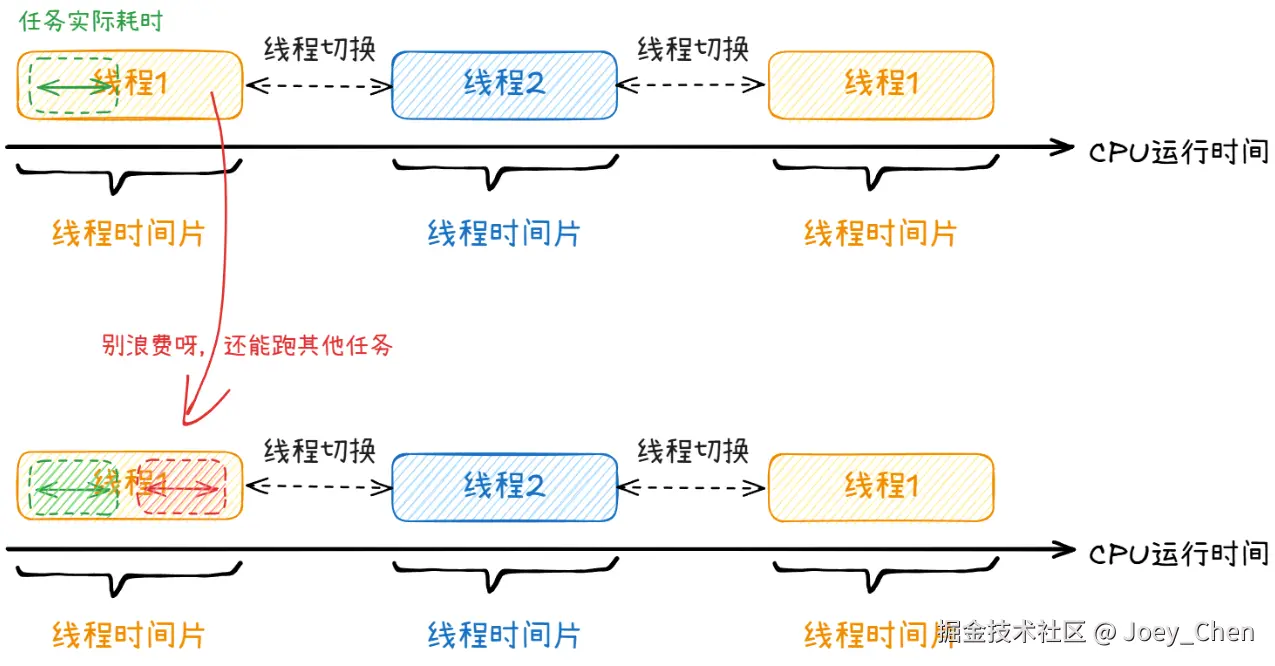
学习Goroutine,除了熟悉其基本特性,关键要掌握的是Goroutine的调度。
Goroutine 的基本特性
-
轻量级
- 初始栈大小仅为 2KB(可动态扩容,最大可达 GB 级别),而操作系统线程的栈通常为 1-8MB。
- 上下文切换无需陷入内核态(由 Go 调度器在用户态完成),成本仅为线程切换的几十分之一。
-
由 Go 运行时调度
- 不直接映射到操作系统线程,而是由 Go 调度器(Scheduler)通过 "M:N 调度" 机制,将多个 Goroutine 动态映射到少量操作系统线程上执行。
- 调度器会自动处理 Goroutine 的创建、阻塞、唤醒和销毁,开发者无需手动管理。
-
并发执行
- 多个 Goroutine 可在同一线程上 "并发" 执行(通过时间片切换),也可在多线程上 "并行" 执行(利用多核 CPU)。
- 本质是 "用户态线程",但 Go 调度器会智能利用多核资源,实现真正的并行。
创建 Goroutine
通过 go 关键字即可启动一个 Goroutine,语法为:
go
go 函数名(参数列表)当执行 go 语句时,Go 会创建一个新的 Goroutine,并在后台异步执行函数,当前程序会继续往下执行,不会等待 Goroutine 完成。
示例一:启动普通函数
go
func sayHello() {
fmt.Println("Hello from Goroutine!")
}
func main() {
go sayHello() // 启动 Goroutine
time.Sleep(100 * time.Millisecond) // 等待 Goroutine 执行
}示例二:启动匿名函数
go
func main() {
go func() { // 匿名函数直接作为 Goroutine
fmt.Println("Anonymous Goroutine")
}()
time.Sleep(100 * time.Millisecond)
}示例三:两个Goroutine并发
go
package main
import (
"fmt"
"time"
)
// 定义一个要在 Goroutine 中执行的函数
func printNumbers() {
for i := 1; i <= 5; i++ {
fmt.Printf("%d ", i)
time.Sleep(100 * time.Millisecond) // 模拟耗时操作
}
}
func main() {
// 启动一个 Goroutine 执行 printNumbers
go printNumbers()
// 主 Goroutine 执行其他操作
for i := 6; i <= 10; i++ {
fmt.Printf("%d ", i)
time.Sleep(100 * time.Millisecond)
}
// 等待子 Goroutine 完成(实际开发中需用同步机制,这里简化用 Sleep)
time.Sleep(1 * time.Second)
}输出(顺序可能因调度器而异):
go
6 1 7 2 8 3 9 4 10 5 - 主程序(
main函数本身运行在一个 "主 Goroutine" 中)和printNumbers函数在两个 Goroutine 中并发执行,因此输出是交替的。
Goroutine 的调度模型:GPM
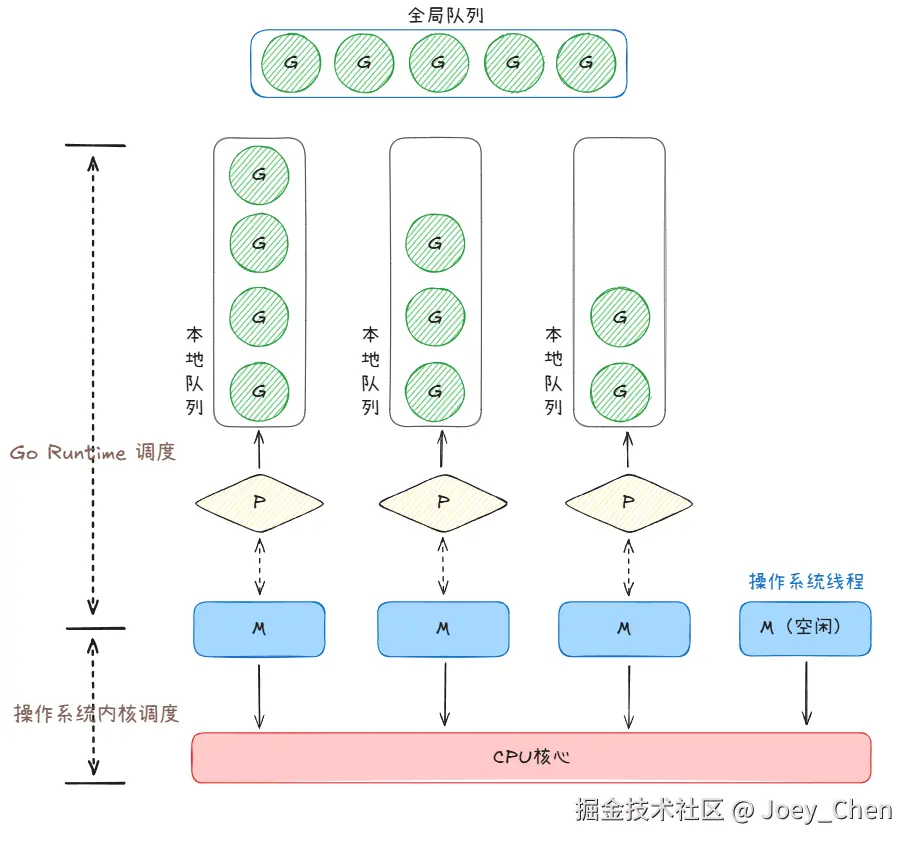
模型组件
Go 调度器通过 GPM 模型 管理 Goroutine,核心由三个组件构成:
-
G:Goroutine。代表一个计算任务,包含了执行栈、状态等信息。
-
P :Processor(调度器)。代表一个调度的上下文,是连接 G 和 M 的桥梁。P 的数量默认等于 CPU 逻辑核心数(可通过
GOMAXPROCS设置)。 -
M:Machine(操作系统线程)。由操作系统管理,是真正执行计算的载体。M 的数量通常会略多于 P 的数量。
调度逻辑
GPM 的核心目标是:让尽可能多的 G 被 M 执行,同时最大化利用多核 CPU,最小化调度开销。
1. 绑定:G、P、M 的关联关系
- 每个运行中的 M 必须绑定一个 P(
M-P绑定):M 通过 P 获取待执行的 G; - 每个P 管理一个本地 G 队列:新创建的 G(如
go func())会优先加入当前 P 的本地队列(无锁,高效); - 全局还有一个全局 G 队列:当本地队列满了(默认容量 256),新 G 会被转移到全局队列(需加锁,低效,因此尽量避免)。
2. 执行:G 如何在 CPU 上运行?
- 绑定了 P 的 M 会从 P 的本地队列中 "取出" 一个 G(按 FIFO 顺序),设置为 "运行中" 状态;
- M 执行 G 的代码:此时 G 的指令通过 M 在 CPU 上执行,G 的栈数据被加载到 CPU 缓存;
- 执行过程中,若 G 遇到非阻塞操作 (如
time.Sleep(0)、通道操作但未阻塞),Go Runtime 会触发 "用户态调度":暂停当前 G,将其放回 P 的本地队列,M 从队列中取下一个 G 继续执行(无需内核参与,切换成本极低,约几 ns)。
3. 切换:G 阻塞时如何处理?
当 G 执行阻塞操作 (如 IO 系统调用、time.Sleep(100ms)、等待锁)时,为避免 M 和 P 被闲置,GPM 会触发 "解绑 - 再绑定" 逻辑:
- 步骤 1:解绑 M 和 P :G 阻塞时,M 会与 P 解绑(
M-P分离),P 被 "释放"; - 步骤 2:P 绑定新 M:Go Runtime 会唤醒一个空闲的 M(或创建新 M),绑定到释放的 P 上,继续执行 P 本地队列中的其他 G;
- 步骤 3:G 唤醒后重入队列:当阻塞的 G 恢复(如 IO 完成、休眠结束),会被放入某个 P 的本地队列(或全局队列),等待 M 再次执行。
例 :G1 执行read()系统调用(阻塞),则:
- M1 与 P1 解绑,P1 被释放;
- 空闲的 M2 绑定 P1,执行 P1 本地队列中的 G2;
- G1 完成 IO 后,被放入 P2 的本地队列,等待 M3(绑定 P2)执行。
4. 负载均衡:工作窃取(Work Stealing)机制
为避免 "有的 P 队列满,有的 P 队列空" 的资源浪费,GPM 设计了工作窃取机制:
- 当一个 P 的本地队列无 G 可执行时,它会先检查全局队列,若有 G 则取一批(通常 1/2)到本地队列;
- 若全局队列也为空,它会 "窃取" 其他 P 的本地队列中的 G(通常取一半,如从 P2 的队列中取 50% 的 G 到自己的队列);
- 窃取时需加锁,但因本地队列优先调度,窃取频率低,锁开销可忽略。
GPM 模型的核心优势:为什么 Goroutine 高效?
GPM 通过 "用户态调度 + 资源隔离 + 负载均衡",解决了传统线程调度的三大问题:
调度开销极低(用户态完成)
- 传统线程切换需要进入内核态,保存 / 加载完整上下文(约 200~500ns);
- Goroutine 切换由 Go Runtime 在用户态完成,仅需保存 / 加载 G 的用户态上下文(PC、栈指针等),切换成本约几 ns(是线程切换的 1/100~1/10)。
内存利用率极高(动态资源分配)
- 线程需要预分配 MB 级栈 + 独立内核栈(如 Linux 线程约 8MB);
- Goroutine 采用动态栈(初始 2KB)+ 复用 M 的内核栈,单 G 内存仅 4KB,1GB 内存可创建 20 万个以上 G。
多核利用率最大化(P 数量控制并行度)
- P 的数量默认等于 CPU 核心数(
GOMAXPROCS = NumCPU),确保同时运行的 G 数量不超过 CPU 核心数(无超线程浪费); - 工作窃取机制避免多核空闲,让每个 CPU 核心都满负荷运行。
阻塞处理高效(M 与 P 分离)
- 线程阻塞时,会占用内核资源且无法释放;
- Goroutine 阻塞时,M 与 P 解绑,P 可绑定新 M 继续工作,内核线程资源不浪费(如 1000 个 G 阻塞 IO,仅需 10 个 M 即可支撑)。
总结
GPM 模型通过G(任务)、P(资源 + 调度)、M(执行载体) 的协同设计,将 "用户态轻量协程" 与 "操作系统线程""CPU 核心" 高效绑定,实现了:
- 极致的内存效率(KB 级 Goroutine);
- 极低的调度开销(用户态切换);
- 完美的多核利用(工作窃取 + 并行度控制)。
这也是为什么 Go 语言能轻松支撑 "百万级并发连接"------GPM 模型让每个 Goroutine 的 "运行成本" 低到可以忽略,从而在有限的硬件资源下,实现远超传统线程的并发规模。
三、通道Channel
在C++、Java等语言中,进行多线程编程时需要考虑线程间的通信方式以及线程安全问题。类似的,协程Goroutine之间也有一套安全通信和同步协作的机制,就是接下来将要介绍的通道Channel。
Channel 的本质:协程间的 "安全管道"
Channel 的核心功能是在 Goroutine 之间传递数据,并协调它们的执行节奏。想象多个 Goroutine 是工厂里的工人,Channel 就是连接工人的 "传送带"------ 工人 A 生产的数据(如计算结果)通过传送带(Channel)传递给工人 B,且传送带会确保 "同一时间只有一个工人操作数据",避免混乱。
- 通信 :Goroutine 可以通过 Channel 发送数据(
ch <- data)或接收数据(data <- ch),实现数据的跨协程传递; - 同步:发送 / 接收操作会自动阻塞,直到对方准备好(如发送方等待接收方接收,接收方等待发送方发送),天然实现了 Goroutine 的执行顺序协调。
Channel 的基本语法:创建、发送、接收、关闭
Channel 需要通过make函数创建,使用<-操作符进行数据传递,用close函数关闭,语法简洁直观:
声明与创建
Channel 是有类型的(只能传递指定类型的数据),声明格式为:var 通道名 chan 数据类型
但需通过make函数初始化后才能使用,分为无缓冲 Channel 和有缓冲 Channel两类:
go
// 1. 无缓冲Channel(unbuffered):没有缓冲区,发送和接收必须同步
ch1 := make(chan int) // 只能传递int类型数据
// 2. 有缓冲Channel(buffered):有固定容量的缓冲区,容量为3
ch2 := make(chan string, 3) // 只能传递string类型,缓冲区最多存3个数据发送数据(ch <- data)
通过<-操作符向 Channel 发送数据,发送方的行为取决于 Channel 类型:
- 无缓冲 Channel:发送方会阻塞,直到有其他 Goroutine 从该 Channel 接收数据;
- 有缓冲 Channel:若缓冲区未满,数据直接存入缓冲区,发送方不阻塞;若缓冲区已满,发送方阻塞,直到有数据被接收(缓冲区有空闲)。
go
ch := make(chan int)
go func() {
ch <- 100 // 发送数据100到Channel
}()接收数据(data <- ch 或 data, ok <- ch)
通过<-操作符从 Channel 接收数据,接收方的行为同样取决于 Channel 类型:
- 无缓冲 Channel:接收方会阻塞,直到有其他 Goroutine 向该 Channel 发送数据;
- 有缓冲 Channel:若缓冲区非空,直接从缓冲区取数据,接收方不阻塞;若缓冲区为空,接收方阻塞,直到有新数据发送。
接收时可通过第二个返回值判断 Channel 是否已关闭:
go
ch := make(chan int, 1)
ch <- 100 // 向有缓冲Channel发送数据
// 方式1:仅接收数据
num := <-ch // num = 100(缓冲区有数据,不阻塞)
// 方式2:接收数据并判断Channel是否关闭
ch2 := make(chan int)
close(ch2) // 关闭Channel
num2, ok := <-ch2 // num2=0(int的零值),ok=false(Channel已关闭)关闭 Channel(close(ch))
通过close函数关闭 Channel,关闭后:
- 不能再向 Channel 发送数据(否则会触发
panic); - 仍可从 Channel 接收剩余数据(缓冲区中的数据),接收完后返回 "零值 +
false"; - 通常由发送方关闭 Channel(避免接收方关闭导致发送方 panic)。
go
ch := make(chan string, 2)
ch <- "hello"
ch <- "world"
close(ch) // 关闭Channel
// 接收剩余数据
fmt.Println(<-ch) // 输出 "hello"
fmt.Println(<-ch) // 输出 "world"
fmt.Println(<-ch) // 输出 ""(string零值),此时若用ok判断,ok=false无缓冲与有缓冲Channel对比
| 类型 | 核心特点 | 典型场景 |
|---|---|---|
| 无缓冲 Channel | 发送和接收必须同步("手递手" 传递),发送方和接收方会互相等待对方就绪。 | 强同步场景(如 Goroutine 协作完成同一任务) |
| 有缓冲 Channel | 数据先存入缓冲区,发送 / 接收仅在缓冲区满 / 空时阻塞,类似 "消息队列"。 | 异步通信场景(如生产者 - 消费者模型) |
Channel 的核心作用:3 大典型场景
Channel 是 Go 并发编程的 "瑞士军刀",几乎所有 Goroutine 协作场景都能通过 Channel 解决:
数据传递:安全交换跨协程数据
多个 Goroutine 通过 Channel 传递数据,无需手动加锁(Channel 内部已实现同步),避免数据竞争。
例:生产者 - 消费者模型
go
func producer(ch chan<- int) { // chan<- 表示只能发送
for i := 0; i < 5; i++ {
ch <- i // 生产数据发送到Channel
fmt.Printf("生产: %d\n", i)
}
close(ch) // 生产完毕,关闭Channel
}
func consumer(ch <-chan int) { // <-chan 表示只能接收
for num := range ch { // for-range遍历Channel,自动处理关闭
fmt.Printf("消费: %d\n", num)
}
}
func main() {
ch := make(chan int, 2) // 有缓冲Channel,平衡生产和消费速度
go producer(ch)
go consumer(ch)
time.Sleep(time.Second) // 等待执行完成
}同步等待:协调 Goroutine 执行顺序
利用 Channel 的阻塞特性,实现 "等待某个 Goroutine 完成后再执行下一步"。
例:等待多个 Goroutine 完成
go
func worker(id int, done chan<- bool) {
fmt.Printf(" worker %d 完成工作\n", id)
done <- true // 工作完成,发送信号
}
func main() {
done := make(chan bool, 3) // 有缓冲,避免阻塞
// 启动3个worker
for i := 0; i < 3; i++ {
go worker(i, done)
}
// 等待所有worker完成
for i := 0; i < 3; i++ {
<-done // 接收3次信号,表示所有worker完成
}
fmt.Println("所有工作已完成")
}控制并发:限制同时运行的 Goroutine 数量
通过带缓冲的 Channel 作为 "信号量",控制并发执行的 Goroutine 数量(缓冲区容量即最大并发数)。
例:限制最多 2 个 Goroutine 同时运行
go
func task(id int, sem chan struct{}) {
defer func() { <-sem }() // 释放信号量
// defer 是 Go 语言的关键字
//无论当前函数是正常结束(执行完所有代码)还是异常结束(如触发panic),defer后的逻辑都能被执行
fmt.Printf("任务 %d 运行中\n", id)
time.Sleep(1 * time.Second) // 模拟任务耗时
}
func main() {
sem := make(chan struct{}, 2) // 信号量,容量2(最多2个并发)
for i := 0; i < 5; i++ {
sem <- struct{}{} // 获取信号量,满了则阻塞
go task(i, sem)
}
time.Sleep(3 * time.Second) // 等待所有任务完成
}总结
Channel 的设计解决了传统多线程编程中 "共享内存 + 锁" 的复杂性问题:
- 安全:内部实现了同步机制,无需手动加锁,天然避免数据竞争;
- 简洁 :通过
<-操作符即可完成通信和同步,语法直观; - 灵活:无缓冲 / 有缓冲两种类型,适配同步 / 异步场景,支持关闭通知、范围遍历等特性。 简单说,Channel 让 Goroutine 之间的协作 "像传递消息一样自然",是 Go 语言实现高效、安全并发的核心保障。