深入理解代替单纯记忆
DiffableDataSource是iOS 13引入的一种全新的列表(UITableView、UICollectionView)的构建、更新方式
为什么要引入新的方式
传统写法存在几个问题:
更新时容易出现Crash
比如常见的Invalid Batch Update xxxxCrash非常令人头疼
- 列表UI内部会缓存section、item数量信息,当更新列表时,如果一旦UI缓存的item、section数量与业务所持有的数据源对应不上,就极容易Crash
- 在数据源变化频繁的业务场景下,这样的问题非常常见
代码逻辑更复杂
- 比如需要通过Datasource多个代理方法告知item、section、cell等数据,代码较为分散,更容易出问题
- 业务方必须要持有一个数据源数组,并保证它与UI的indexPath保持一致
- 在代码运行过程中,任何地对UI更新时,这种数据与indexPath保持一致的要求必须时刻关注,否则就出问题
- 任何对UI的更新时,都需要开发者手动计算出indexPath(也就是要展示的数据与当前数据之间的diff),很不方便
DiffableDataSource
传统写法的问题,归根到底核心原因在于:UI(即列表)与数据源强耦合,当然,这个锅也是应该有Apple来背,它设计的列表使用方式就是如此
DiffableDataSource便是来解决该问题的,它核心的思想是:
开发者只需要关心最终展示的数据的state(或者说snapshot)
也就是我们常说的,找到source of the truth,并且这个source越简单、唯一越好,上面所说的state/snapshot,就是这个source
用官方的图示来展示下核心思想,如下图所示:
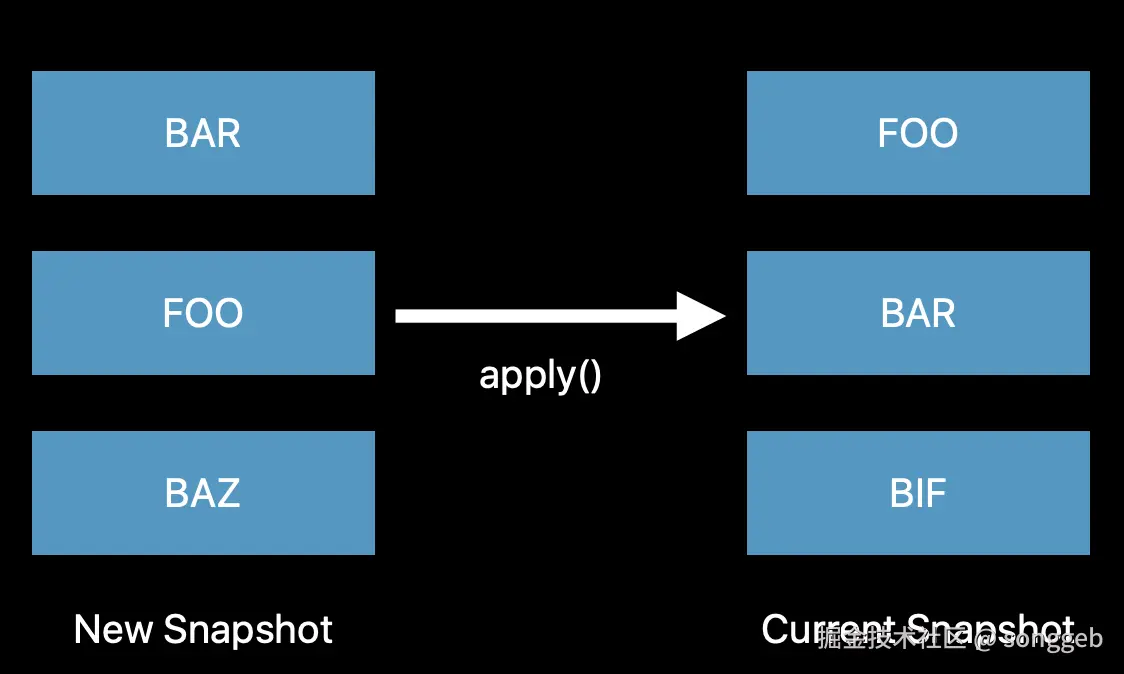
- Current Snapshot表示当前列表显示的数据
- New Snapshot表示需要显示的最新的列表数据
- 注意:此处的New Snapshot描述的是最终展示的完整数据,而非局部数据
- 开发者只需要通过
apply方法告知列表New Snapshot就完成了列表的更新 - 这个过程没有indexPath的计算,不需要开发者自己计算前后数据源的diff
- 其实是列表内部完成了该工作,不过放心,这个diff算法时间复杂度会控制在O(n)
Invalid Batch的Crash将成为历史- 当然,DiffableDataSource还把类似UITableViewDatasource中多个代理方法进行了收敛,开发者不再需要挨个实现
如何使用DiffableDataSource
DiffableDataSource所涉及的类或结构只有2个:
- DataSource
- Snapshot
DataSource是Class类型,针对不同UI、系统,DataSource有:
UICollectionViewDiffableDataSourceUITableViewDiffableDataSourceNSCollectionViewDiffableDataSource
Snapshot则只有NSDiffableDataSourceSnapshot这一个结构,Struct类型
使用方式
核心的使用方式只有简单的3步:
- 构建DataSource,与UI关联
- 构建数据Snapshot
- 通过
dataSource.apply方法应用Snapshot
代码演示如下:
ini
let dataSource = UITableViewDiffableDataSource<Section, Item>(tableView: tableView) { tableView, indexPath, item in
let cell = tableView.dequeueReusableCell(withIdentifier: "123", for: indexPath)
cell.textLabel?.text = item.title
return cell
}
var snapshot = NSDiffableDataSourceSnapshot<Section, Item>()
snapshot.appendSections([.main])
snapshot.appendItems(items, toSection: .main)
dataSource.apply(snapshot, animatingDifferences: true)使用DiffableDataSource后,需要注意几点:
- 不再需要(也不建议)在调用列表的
reloadData/reloadRow/insertRow/performBatchUpdates等方法,所有都改为apply方法 - 需要更新列表时,需要围绕着Snapshot进行更新
- DataSource提供了获取Snapshot的方法
- Snapshot提供了操作内容的方法
- DiffableDataSource也为列表的事件(如点击cell)提供了支持
- 保留了获取indexPath逻辑
- 也提供了通过indexPath获取Snapshot等方法
- 定义DataSource时需要通过泛型提供数据类型,DataSource对数据类型时有要求的
class UITableViewDiffableDataSource<SectionIdentifierType, ItemIdentifierType> where SectionIdentifierType : Hashable, ItemIdentifierType : HashableSectionIdentifierType和ItemIdentifierType必须实现Hashable- 这是因为Snapshot在做数据diff时为了提高速度,需要用到哈希结构
简单总结一下
- 通过引入DataSource和Snapshot,使得列表使用更简单、更健壮
- 你会发现,DiffableDataSource完全改变了原来列表的使用方式,这一点需要开发者在使用过程中逐渐适应
SectionIdentifierType与ItemIdentifierType
SectionIdentifierType和ItemIdentifierType正如其单词本身意思一样,分别表示唯一标识Section和唯一标识Item的类型
来看下Snapshot相关API
struct NSDiffableDataSourceSnapshot<SectionIdentifierType, ItemIdentifierType> where SectionIdentifierType : Hashable, ItemIdentifierType : Hashablemutating func appendSections(_ identifiers: [SectionIdentifierType])mutating func appendItems(_ identifiers: [ItemIdentifierType], toSection sectionIdentifier: SectionIdentifierType? = nil)
通过DataSource.apply方法传入snapshot后,DataSource内部会持有这些数据,为数据展示、后续更新时做diff做准备
需要注意的是,只要实现了Hashable就可以作为SectionIdentifierType或ItemIdentifierType
- 比如很多情况下列表只有1个固定的Section,那完全可以定义一个枚举来实现,因为枚举默认就实现了
Hashable,如下所示:
arduino
private enum Section {
case main
}如何实现ItemIdentifierType
相比于SectionIdentifierType,ItemIdentifierType作为核心要展示的列表数据的一部分,它的实现会更重要
与该问题类似的问法是"DiffableDataSource中如何定义数据模型"
在定义数据模型时一般要看数据或业务是否复杂
对于简单数据,或者仅需要展示数据,编辑情况较少时,通常让数据模型直接作为ItemIdentifierType,如下所示:
swift
struct Item: Hashable {
let id = UUID()
let title: String
var callback: (() -> Void)?
func hash(into hasher: inout Hasher) {
hasher.combine(id)
}
static func == (lhs: Item, rhs: Item) -> Bool {
lhs.id == rhs.id
}
}Item作为结构体类型,数据轻量,业务场景也只是为了展示和通过callback处理简单事件
对于复杂场景,则需要将数据模型与ItemIdentifierType区分开
- 复杂业务场景下,所需的业务数据模型对应也复杂,此时要求其实现Hashable可能并不方便
- 比如原有业务模型的可能已经实现了Hashable,而此处的场景ItemIdentifierType仅仅为了区分列表中每一项,两边对Hashable的要求不同,实现上也会有冲突
- 另外也可能有性能问题,如果数据模型太复杂,DataSource在做diff时可能涉及到参与哈希的每个属性都做对比,可能并不是每个属性都有必要参与到计算中
- 还有是UI与数据解耦方面,实现
ItemIdentifierType的模型,主要用于列表中每一项的展示,而非参与复杂的业务逻辑,更像是ViewModel的概念,这就不适合让原业务模型来充当ItemIdentifierType
下面用代码演示一个复杂数据模型场景:
swift
/// 原业务模型(其中user是Class类型)
struct Item: Identifiable {
let user: UserModel
/// 申请时间戳-秒
let applyTimestamp: TimeInterval
}
/// 单独维护原业务模型
private var items: [Item] = []
/// 构建DataSource,使用Item.ID作为ItemIdentifierType
dataSource = UITableViewDiffableDataSource<Section, Item.ID>(tableView: tableView, cellProvider: { [weak self] tableView, indexPath, itemID in
guard let self, let itemIndex = itemIndex(by: itemID) else { return UITableViewCell() }
// dequeue cell, configure cell
return cell
}
/// 构建Snapshot并apply
let itemIDs = items.map(\.id)
var snapshot = NSDiffableDataSourceSnapshot<Section, Item.ID>()
snapshot.appendSections([.main])
snapshot.appendItems(itemIDs, toSection: .main)
dataSource.apply(snapshot, animatingDifferences: false)- 虽然
Item看上去并不复杂,其实此处省略了很多其他属性,而且user是Class类型,其实该业务场景涉及到了增、删、更新等各种操作
还有什么
- 列表的更新不再强制只能在主线程了,即
apply方法可以在后台线程执行- 当然,官方也不是很建议在主线程和后台线程来回切换,还是保持统一一点比较好