1.前言
即梦AI作为字节跳动旗下的AI绘画与视频生成平台,近年来不断推出新的模型和功能,以提升用户体验和创作能力。
即梦AI 3.0是即梦AI的最新版本,于2025年4月发布,标志着其在中文生图模型上的重大升级。该版本不仅在中文生图能力上有所突破,还支持视频生成、多模态生成等高级功能。即梦AI 3.0的视频生成模型(视频3.0)在动作遵循能力、镜头遵循能力、物理模拟和情绪表达方面有显著提升。此外,即梦AI 3.0还支持"影视质感"效果,提供更高质量的图像输出.

之前也有给大家介绍过关于即梦文生图和文生视频。《全网首发!即梦AI+dify工作流,带你领略AI绘画的无限魅力!》和《dify案例分享-5 步解锁免费即梦文生视频工作流,轻松制作大片》随着即梦AI模型的升级,生成的图片和生成的视频会有更好的效果。昨天在开源想项目上做了一下魔改目前可以实现最新的即梦3.1 模型(文生图)、即梦-Video3.0(文生视频)等模型了。今天就带大家做一个基于即梦AI绘画的免费支持文生图和文生视频的工作流。话不多说下面给大家看一下工作流的效果:
文生图效果:
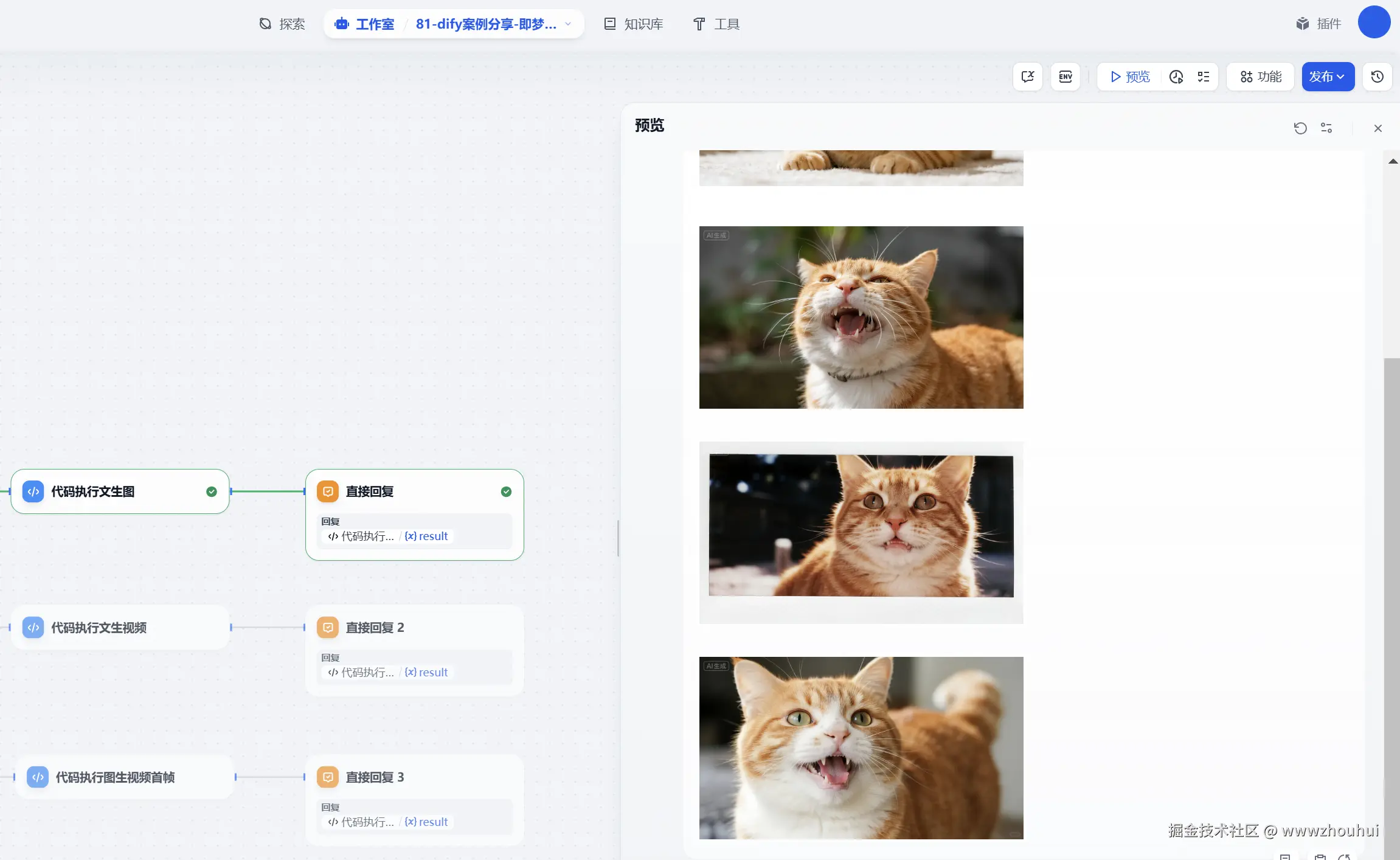
文生视频:

图生视频效果
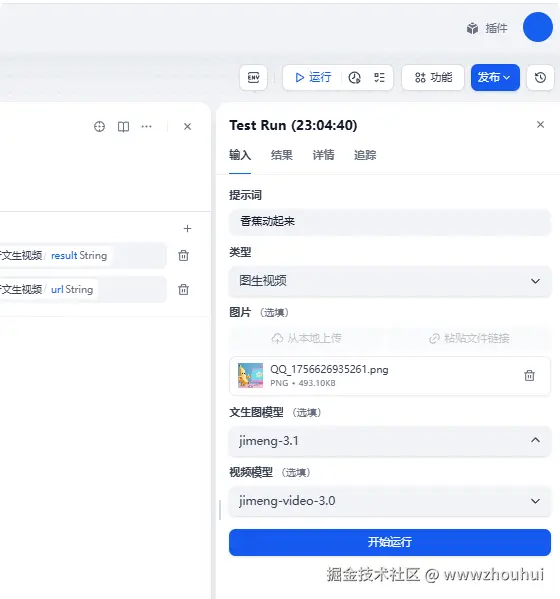
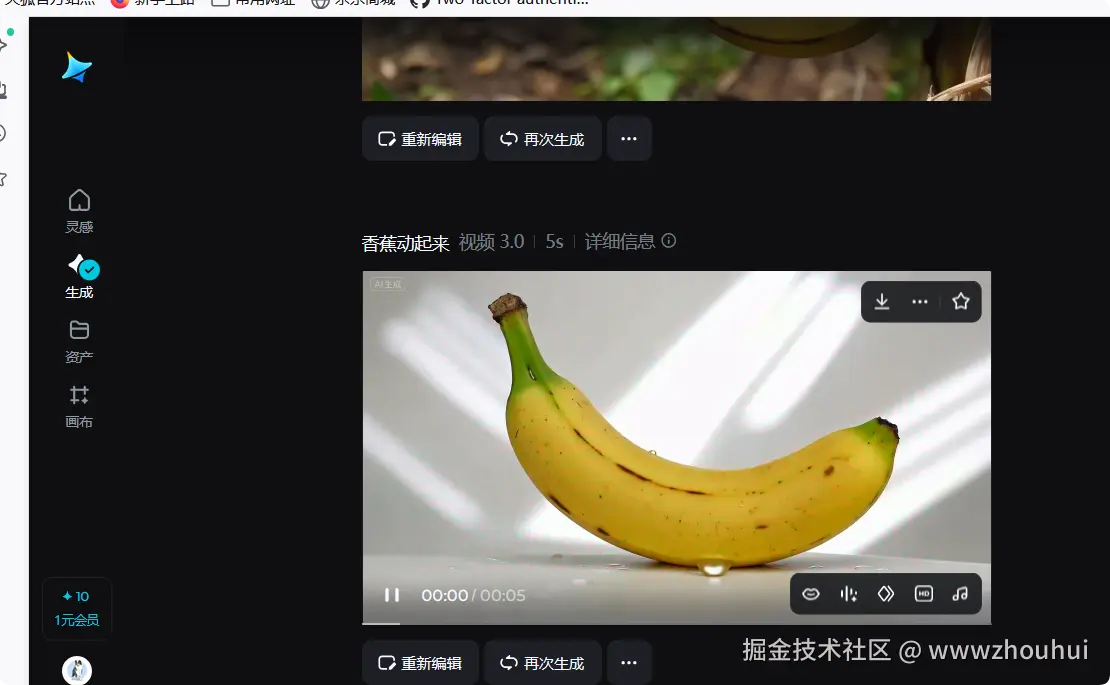
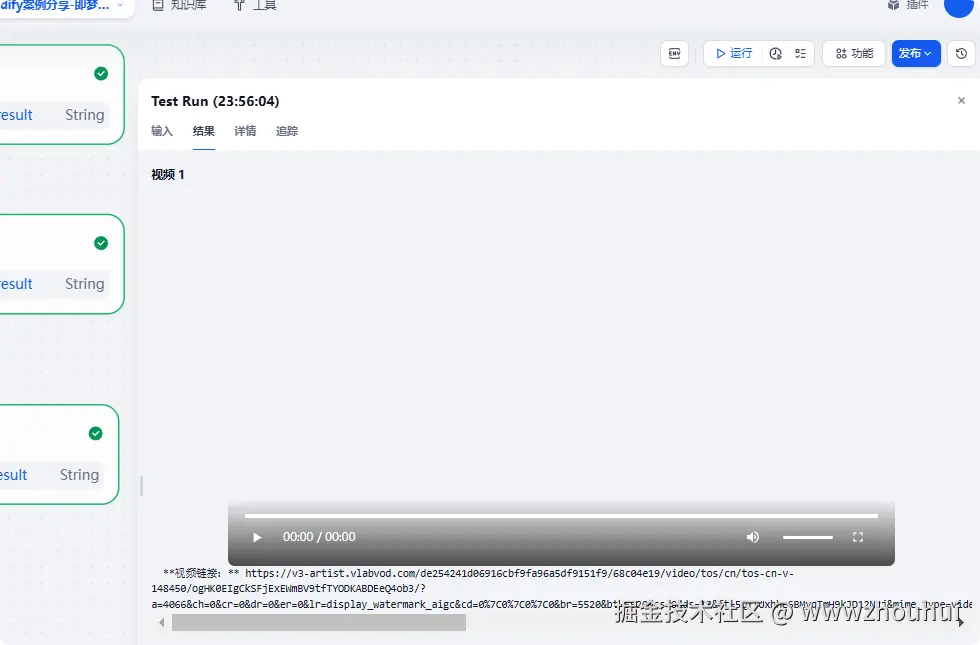
打开视频链接
那么这样的工作流是如何制作的呢?下面带大家手把手做一遍。
2.工作流制作
开始
开始节点这地方设置比较简单,就是接受用户的提示词-prompt
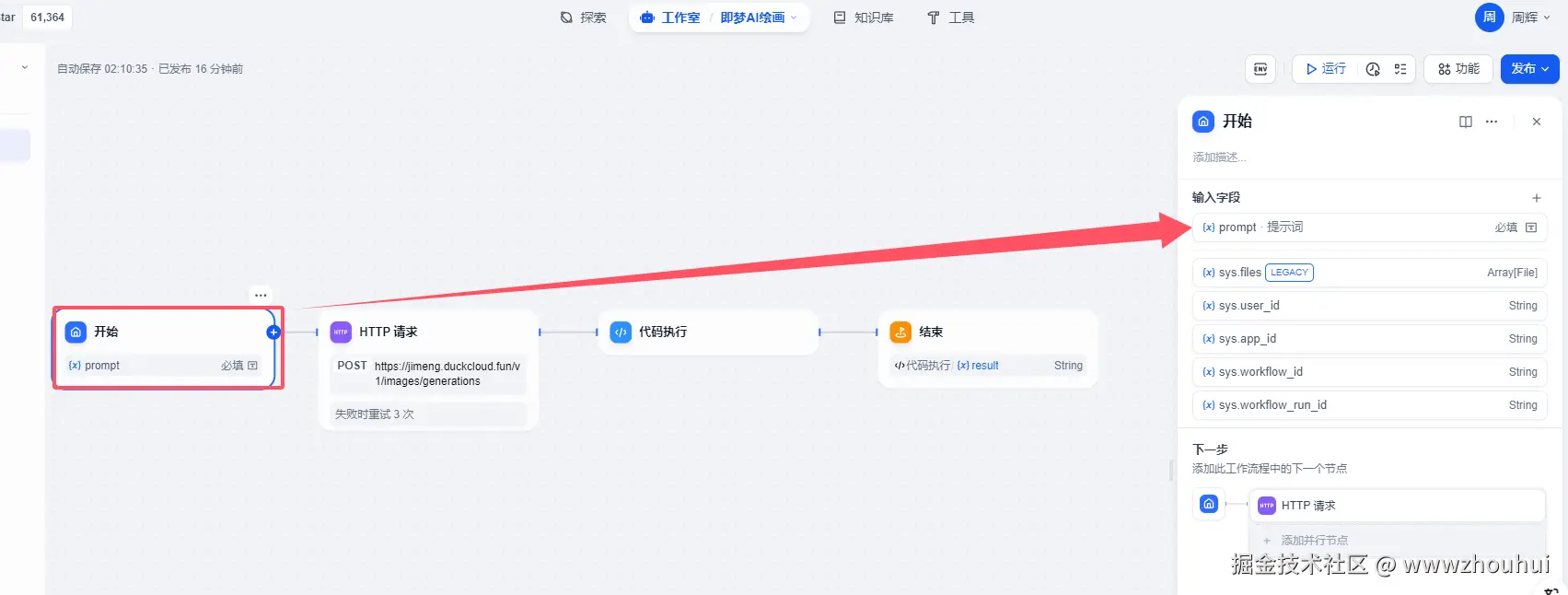
提示词 文本输入,这里主要是接受用户输入的提示词文本信息。
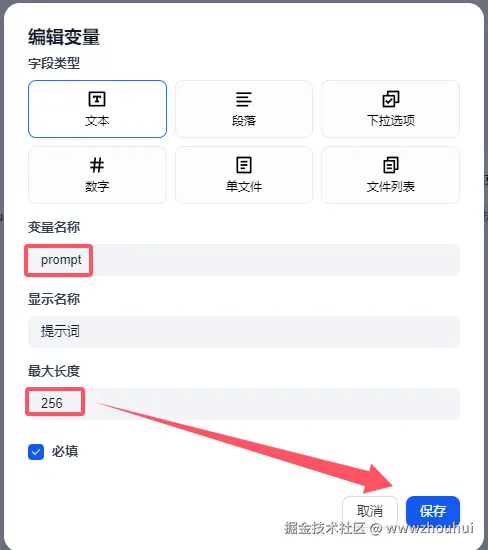
目前dify 文本输入地方最大长度是256,这里小伙伴要注意了,如果提示词过长会截断的。
考虑到这个工作流支持文生图、文生视频,所以开始节点配置参数要比其他工作流多。主要是多了一下模型选择,type类型等。
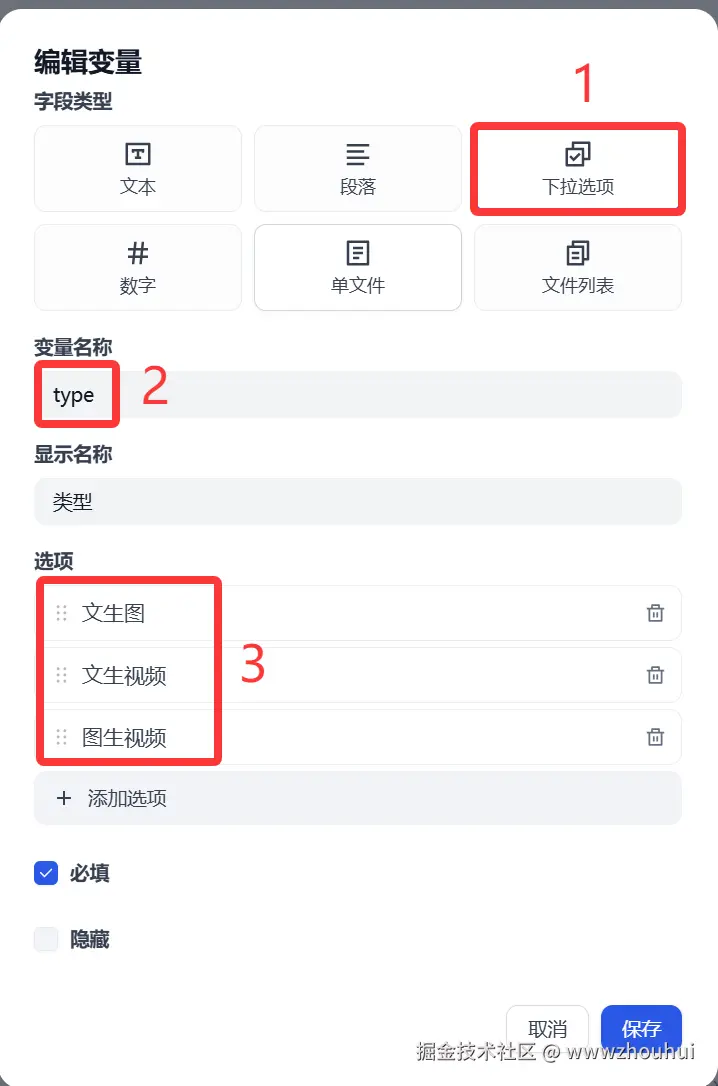
这个picture接受用户输入的图片,主要是为后面图生视频使用。(这块设置可选选)
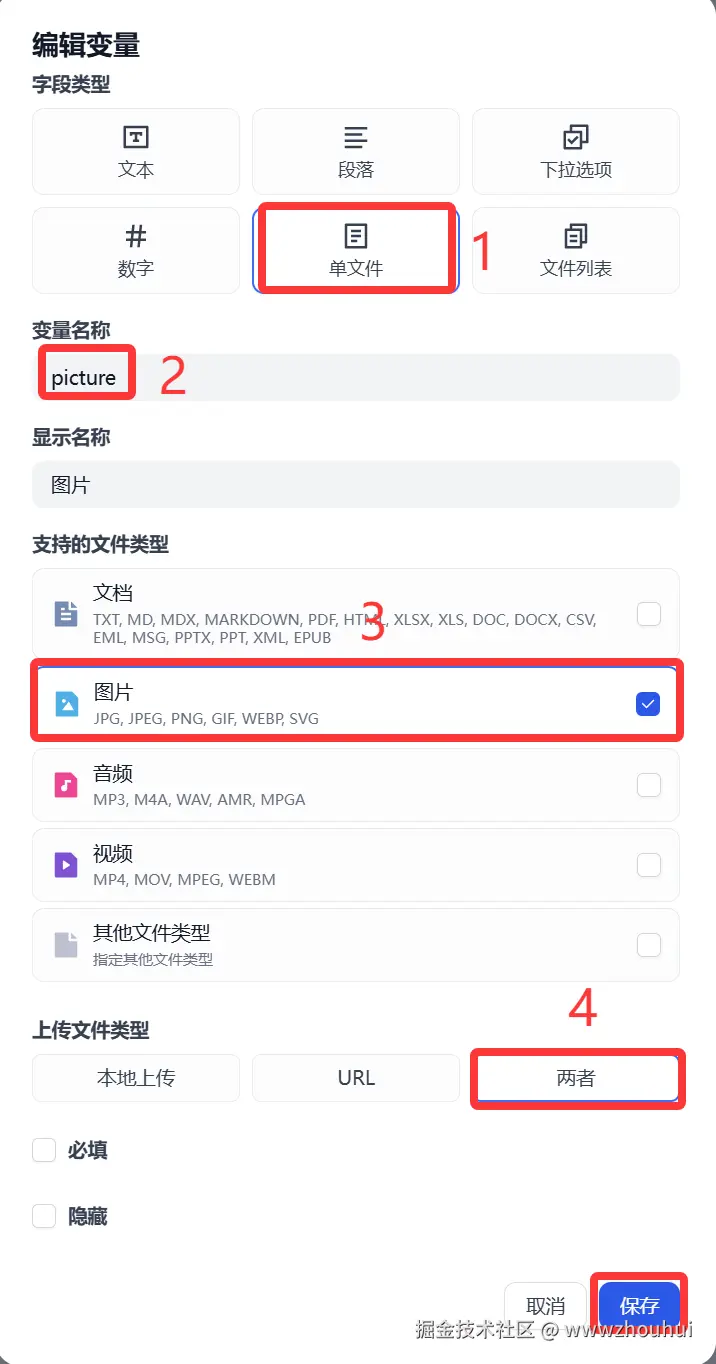
pmodel 主要是让用户选择文生图模型使用(这块设置可选选)
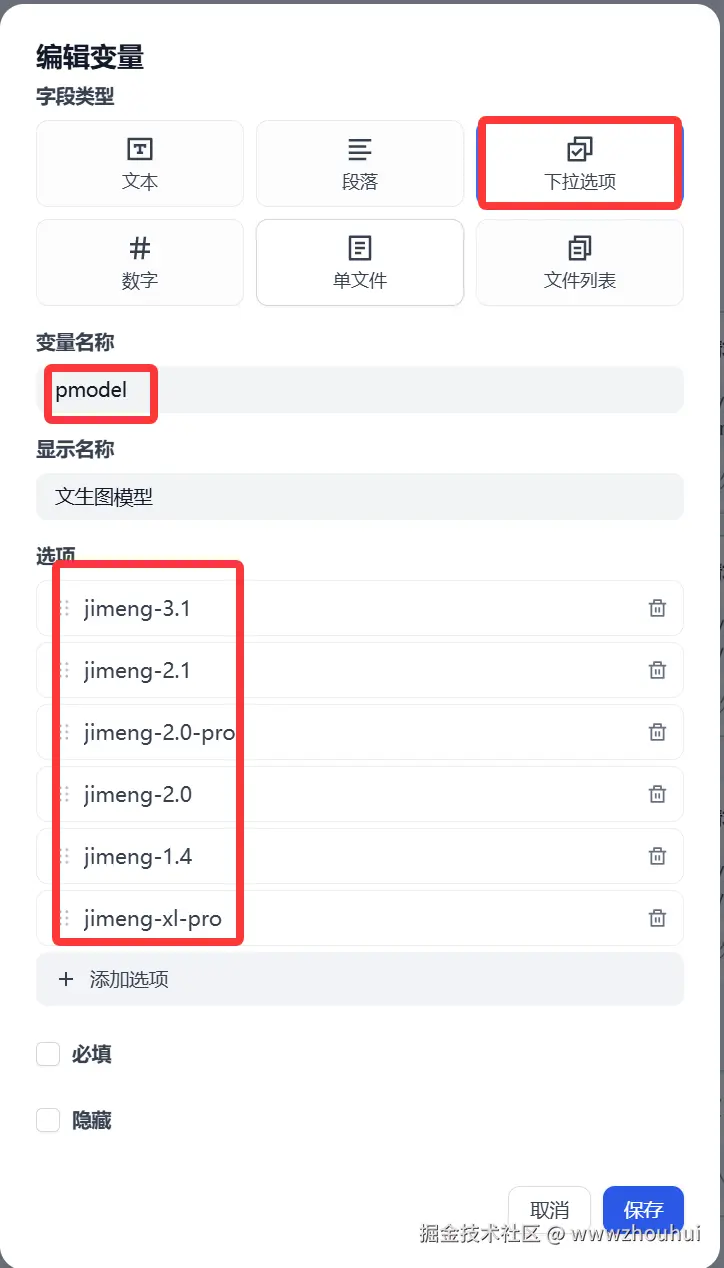
vmodel主要是让用户选择文生视频模型使用(这块设置可选选)
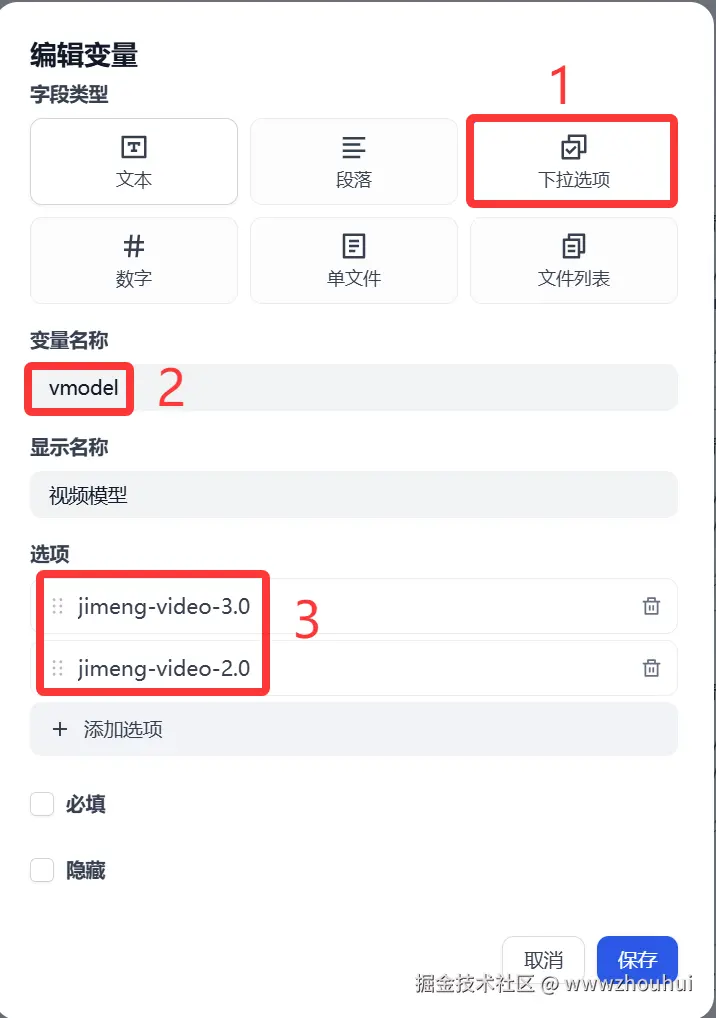
以上我们就完成了开始节点的设置。
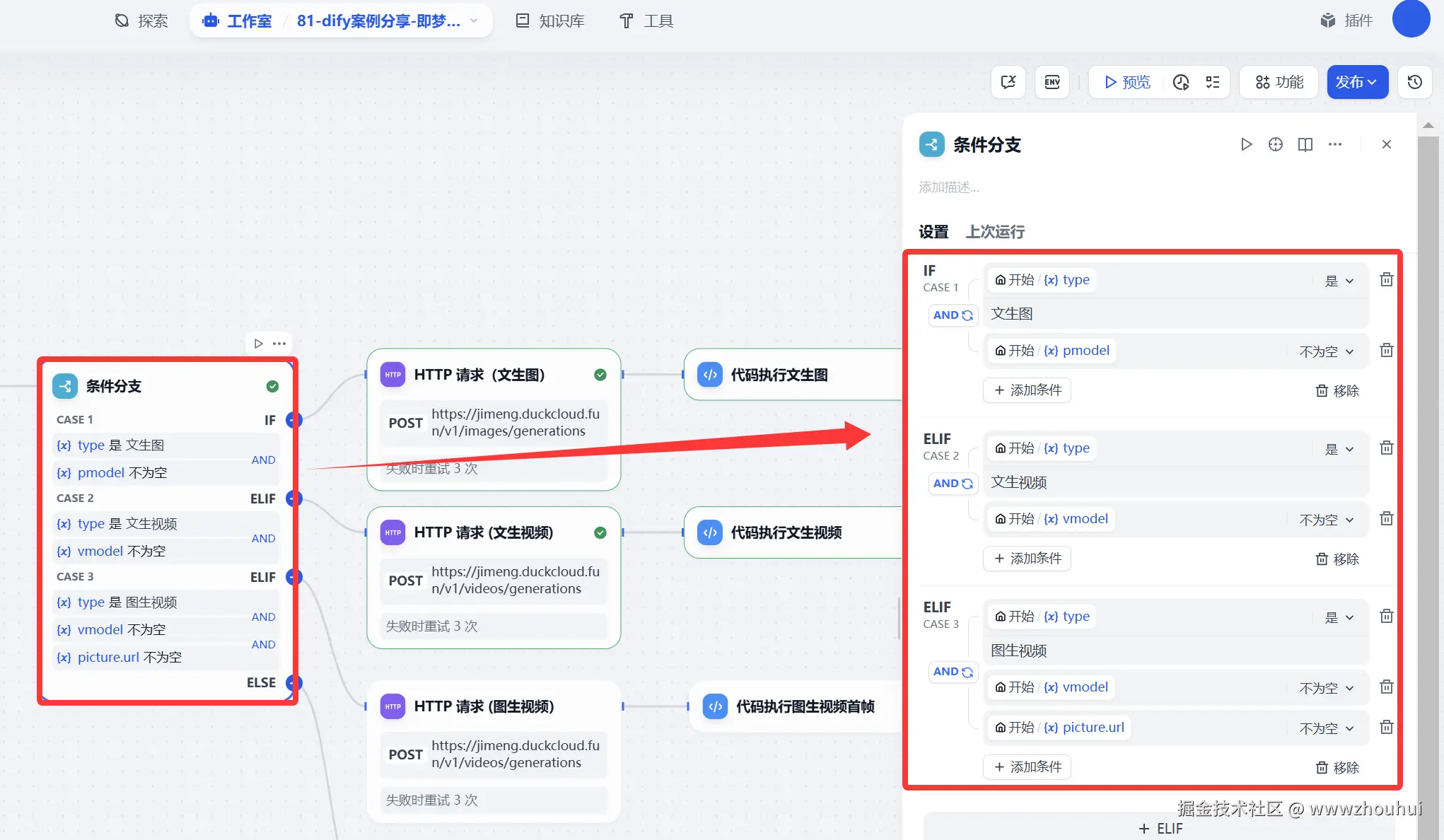
条件分支
这个条件分支主要是目的根据用户选择(文生图、文生视频、图生视频等流程判断)
HTTP请求
这个HTTP请求是调用一个后端一个接口服务,这个接口服务可以实现即梦AI文生图、文生视频、图生视频的逆向。大家可以使用即梦每天送的积分来使用。服务端部署这里就不做详细展开。
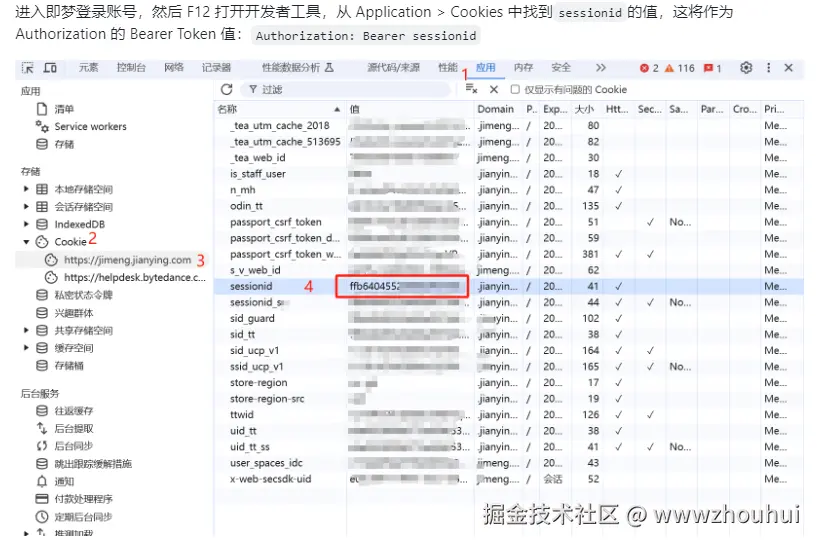
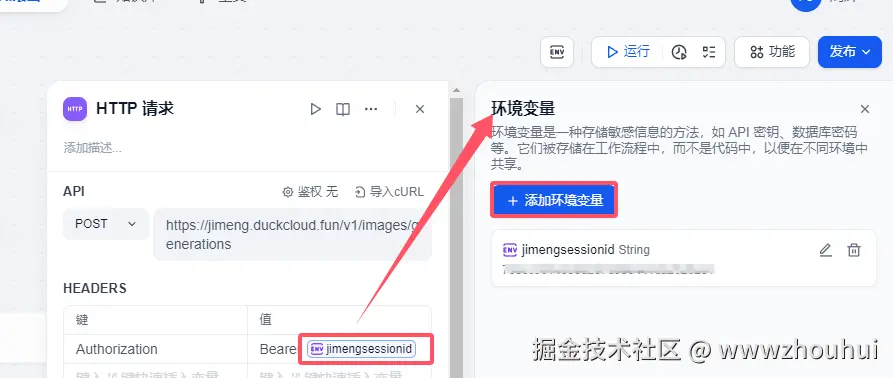
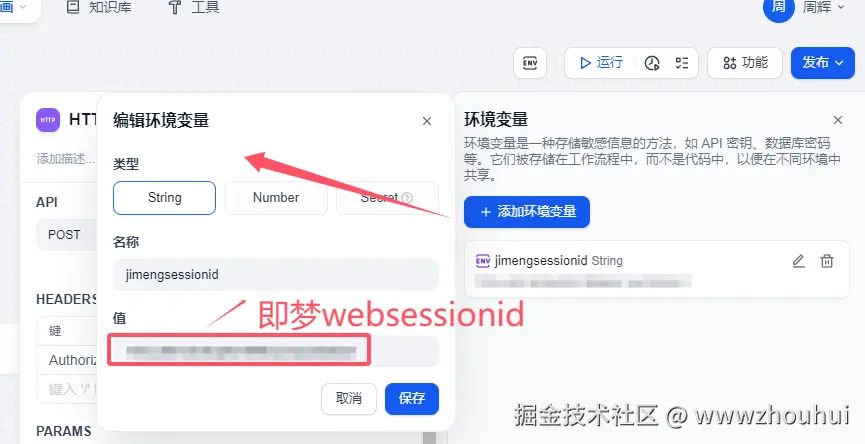
使用这个接口是需要获取你即梦AI 平台sessionid,这个sessionid如何获取呢?
http请求配置
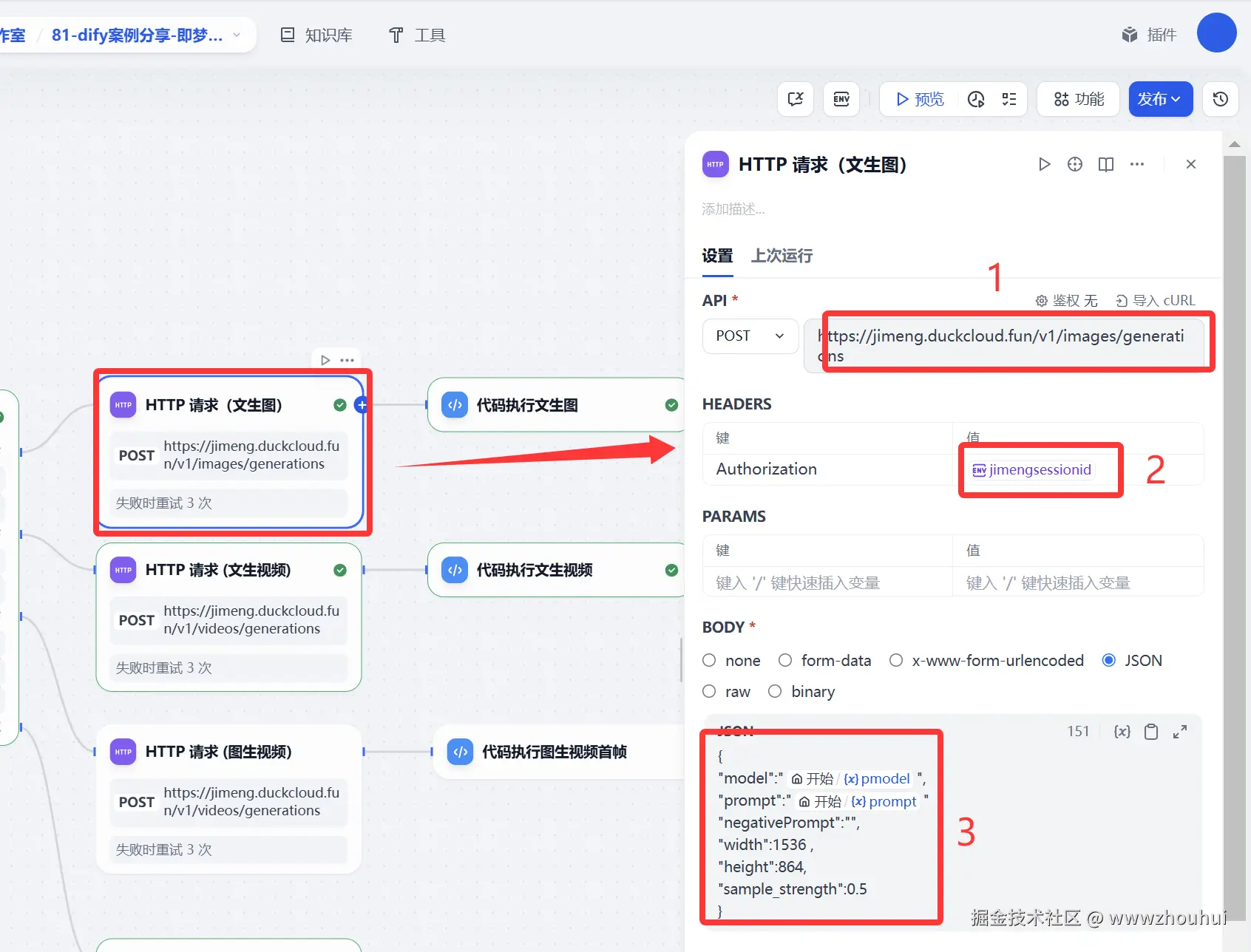
请求地址 jimeng.duckcloud.fun/v1/images/g... 这个是nas部署 使用cloudfare 映射的一个带域名公网api接口地址
请求方式 post 请求
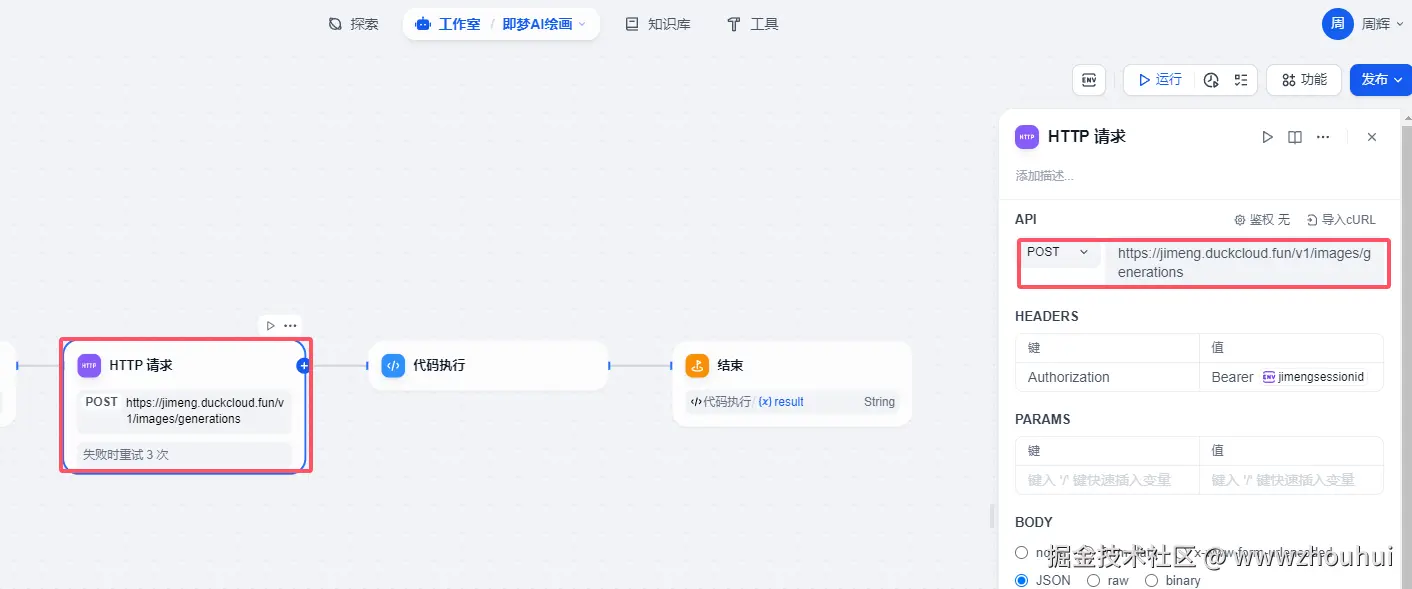
heards部署 主要是接口请求的鉴权的配置。其实你也可以理解就是调用openai接口输入的api key 这个API 其实就是你登录即梦web网站产生的sessionid,我这里使用到环境变量的方式来实现的。
http 请求body部分如下:
文生图
json
{
"model":"{{#1756864683426.pmodel#}}",
"prompt":"{{#1756864683426.prompt#}}"
"negativePrompt":"",
"width":1536 ,
"height":864,
"sample_strength":0.5
}文生视频
json
{
"model":"{{#1756864683426.vmodel#}}",
"prompt":"{{#1756864683426.prompt#}}"
"negativePrompt":"",
"width":1536 ,
"height":864,
"resolution": "720p"
}图生视频
json
{
"model":"{{#1756864683426.vmodel#}}",
"prompt":"{{#1756864683426.prompt#}}"
"negativePrompt":"",
"width":1536 ,
"height":864,
"resolution": "720p",
"filePaths": ["{{#1756864683426.picture.url#}}"]
}文生图的接口请求地址jimeng.duckcloud.fun/v1/images/g... 文生视频和图生视频请求地址 jimeng.duckcloud.fun/v1/videos/g... 其他配置基本是一样的。这里就以文生图截图为案例
代码执行
代码执行的目的就是对HTTP请求返回的信息做一下处理,大体功能 是一样。
文生图代码
python
def main(arg1: str) -> str:
import json
# 解析输入的 JSON 数据
try:
data = json.loads(arg1)
except json.JSONDecodeError:
return "输入的字符串不是有效的 JSON 格式,请检查输入数据。"
# 确保解析后的数据包含 'data' 键
if not isinstance(data, dict) or 'data' not in data:
return "输入的数据格式不正确,请确保输入是一个包含 'data' 键的 JSON 对象。"
# 获取 'data' 键对应的数组数据
image_data = data.get('data', [])
# 确保 'data' 键的值是一个列表
if not isinstance(image_data, list):
return "输入的数据中 'data' 键的值不是一个数组,请确保其值是一个 JSON 数组对象。"
# 初始化结果字符串
markdown_result = ""
# 遍历每条图片数据
for index, item in enumerate(image_data, start=1):
# 检查每条数据是否是字典,并且包含 'url' 字段
if not isinstance(item, dict) or 'url' not in item:
markdown_result += f"图片第{index}条内容:无法提取 URL(缺少 'url' 字段)\n"
continue
# 提取 URL 并生成 Markdown 格式的图片链接
url = item['url']
markdown_result += f"\n"
# 返回最终的 Markdown 字符串
return {"result": markdown_result}文生视频和图生视频代码
python
def main(arg1: str) -> dict:
import json
# 解析输入的 JSON 数据
try:
data = json.loads(arg1)
except json.JSONDecodeError:
return {"result": "输入的字符串不是有效的 JSON 格式,请检查输入数据。"}
# 确保解析后的数据包含 'data' 键
if not isinstance(data, dict) or 'data' not in data:
return {"result": "输入的数据格式不正确,请确保输入是一个包含 'data' 键的 JSON 对象。"}
# 获取 'data' 键对应的数组数据
video_data = data.get('data', [])
# 确保 'data' 键的值是一个列表
if not isinstance(video_data, list):
return {"result": "输入的数据中 'data' 键的值不是一个数组,请确保其值是一个 JSON 数组对象。"}
# 初始化结果字符串
video_html = ""
# 遍历每条视频数据
for index, item in enumerate(video_data, start=1):
# 检查每条数据是否是字典,并且包含 'url' 字段
if not isinstance(item, dict) or 'url' not in item:
video_html += f"<p>视频第{index}条内容:无法提取 URL(缺少 'url' 字段)</p>\n"
continue
# 提取 URL
url = item['url']
# 生成 HTML5 video 标签(Dify支持HTML显示)
video_html += f'''
<div style="margin-bottom: 20px;">
<h3>视频 {index}</h3>
<video width="400" controls>
<source src="{url}" type="video/mp4">
您的浏览器不支持视频播放。
</video>
**视频链接:** {url}
</div>
'''
# 返回最终的视频显示内容
return {"result": video_html}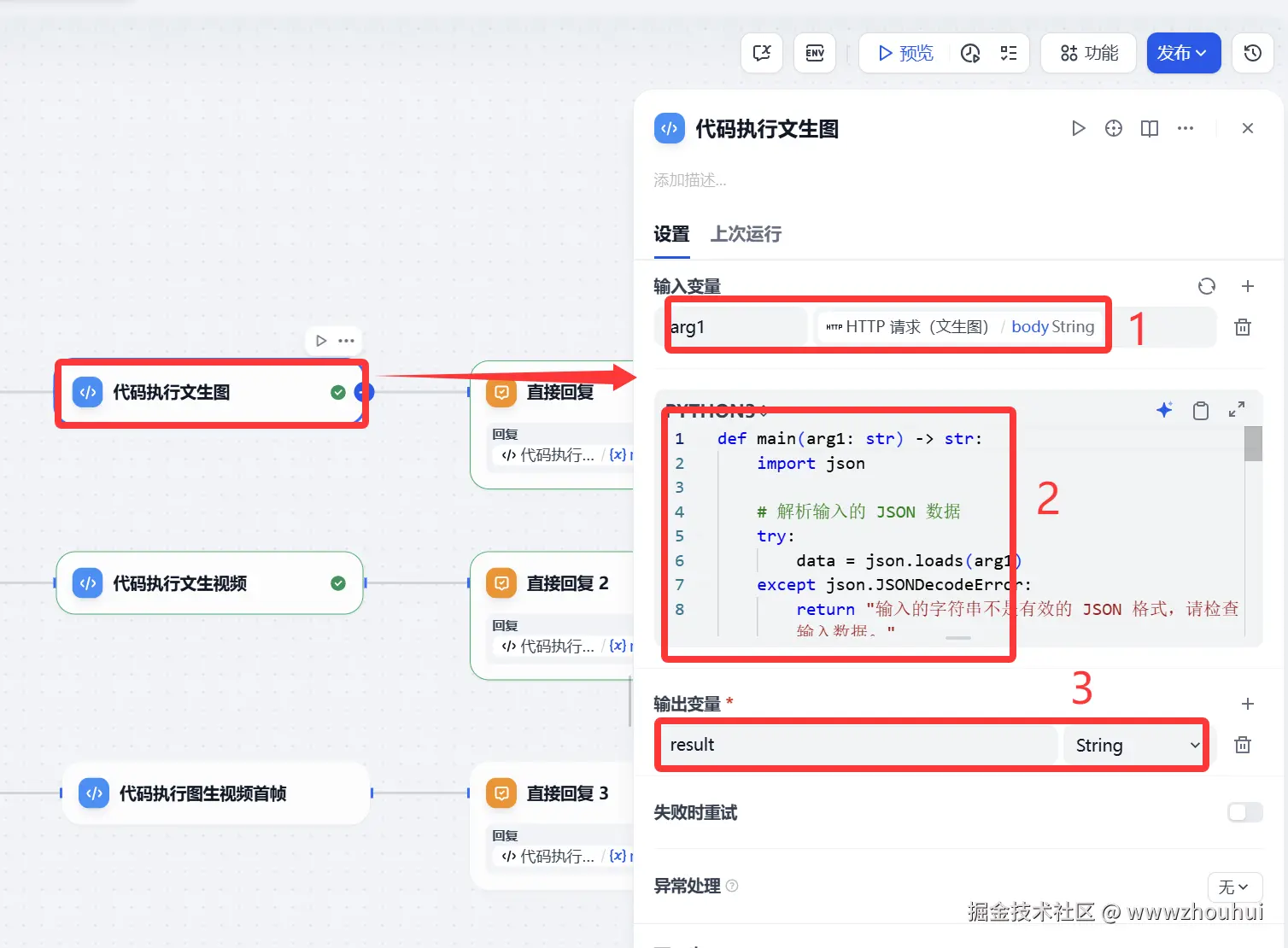
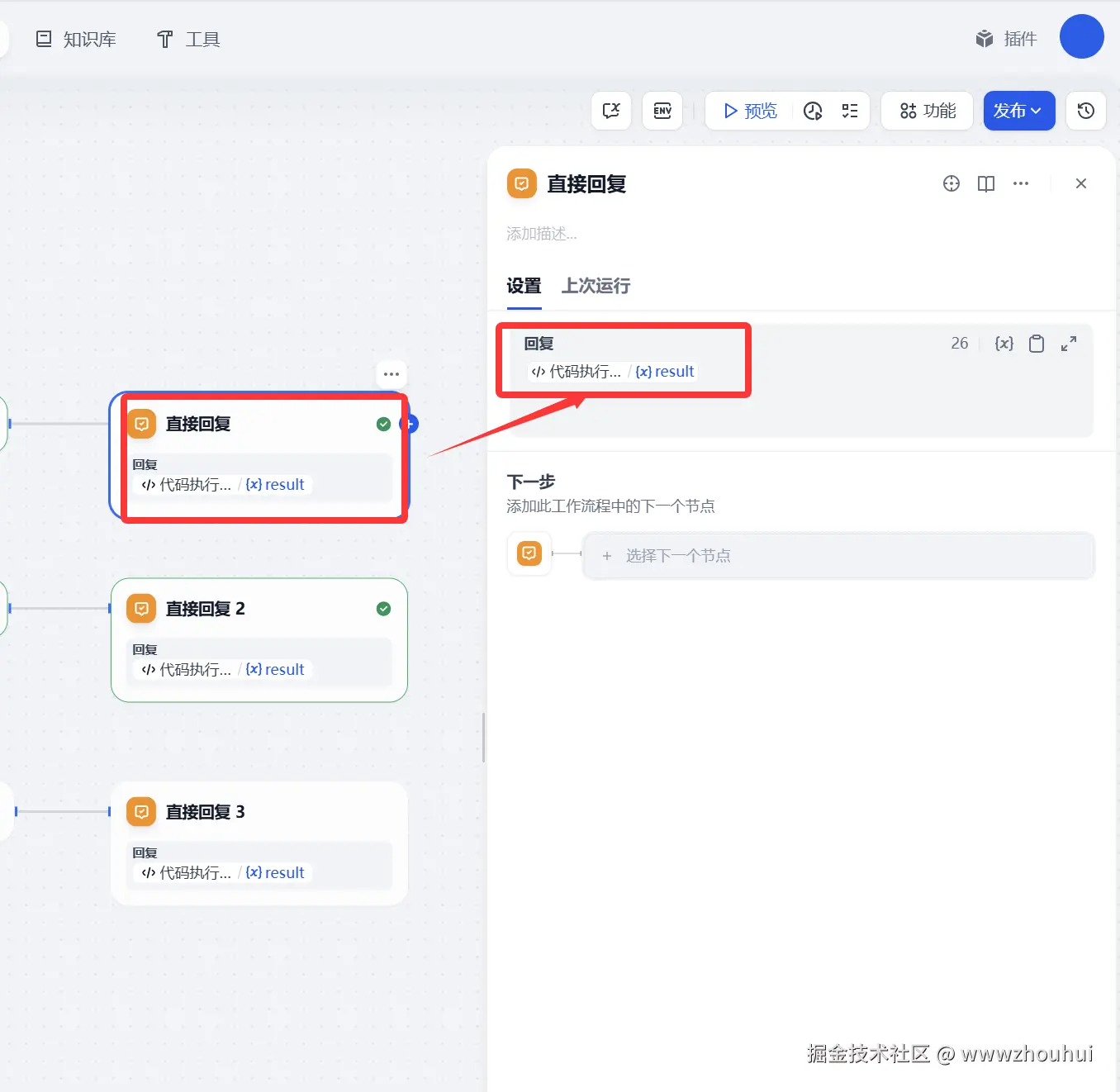
直接回复
这个也比较简单,主要的目的就是文生图、文生视频、图生视频返回信息给客户展示。
另外两个配置和上面一样这里就不做展开。
以上我们就完成了工作流的搭建,是不是比较简单。
3.使用
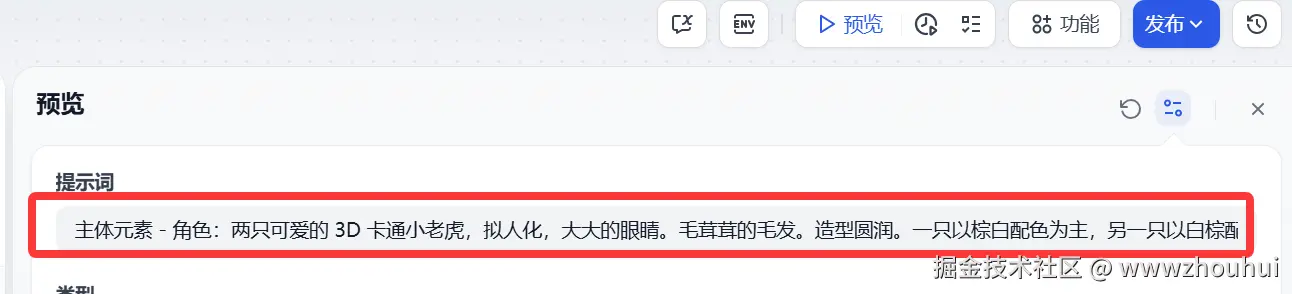
提示词:用户填写提示词就可以了, 因为即梦AI 绘画中文提示词比较友好,这里就没有用大模型做提示词优化了。
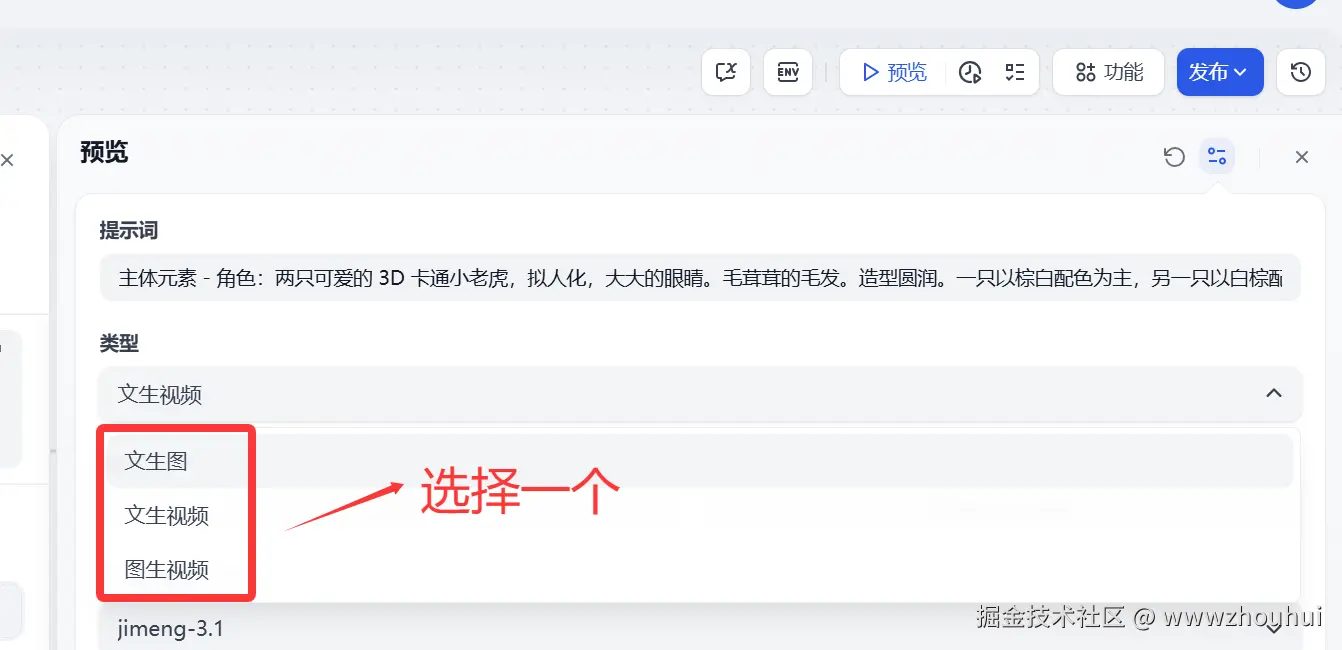
类型
这个类型下拉选项可以选择(文生图、文生视频、图生视频)这个比较好理解,大家根据自己需要选择一个就可以了。
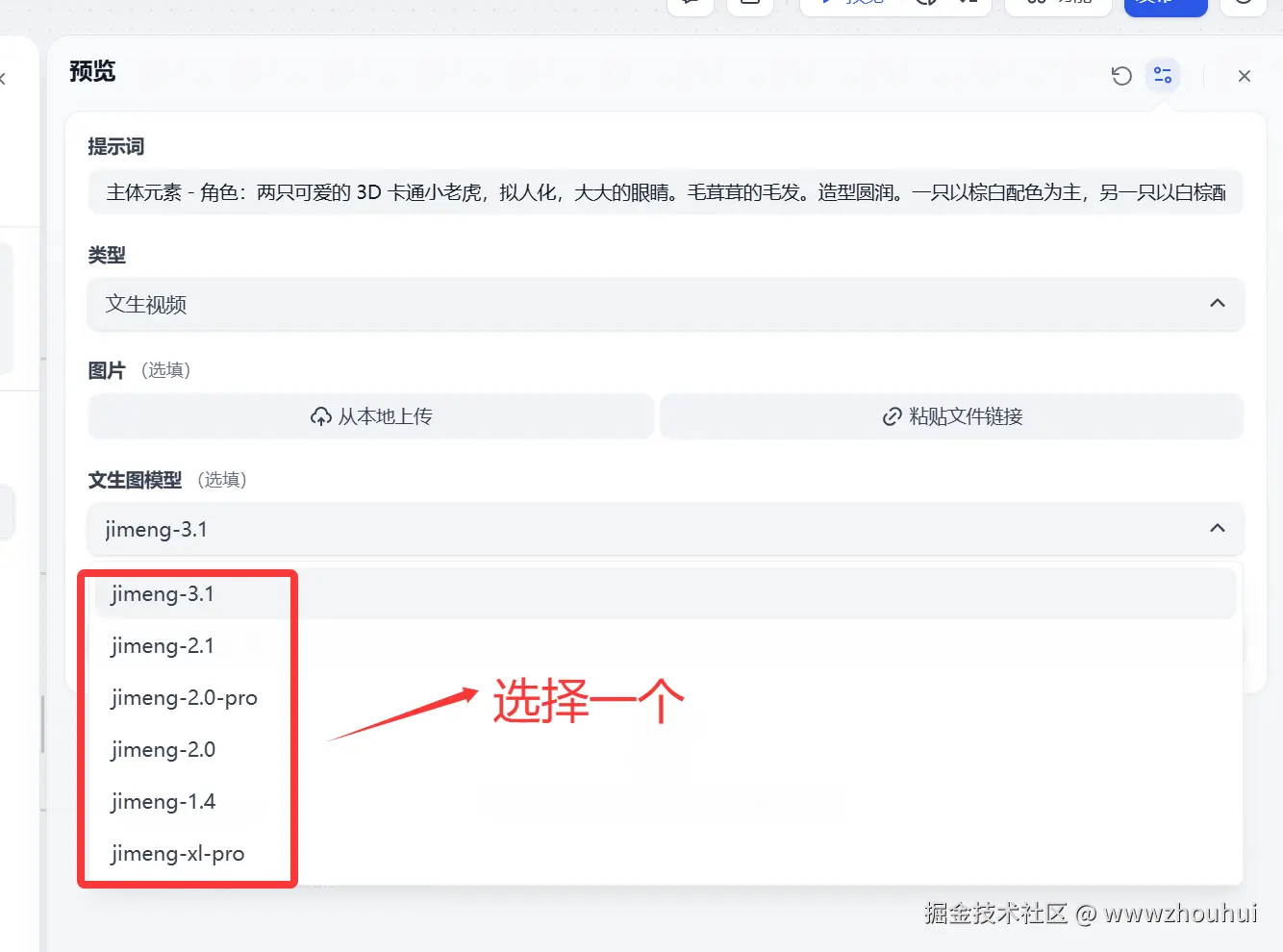
图片这里如果需要图生图的 就上传,如果没有用到这块可以不用管。

文生图模型 提供即梦AI 平台上主要的几个模型(jimeng-3.1、jimeng-2.1、jimeng-2.0-pro、jimeng-2.0、jimeng-1.4、jimeng-xl-pro)
大家根据自己需要选择模型,当然模型越新模型能力越强。默认可以选择jimeng-3.1
视频模型 和上面类似,主要提供即梦AI 平台上的视频模型(jimeng-video-3.0、jimeng-video-2.0)
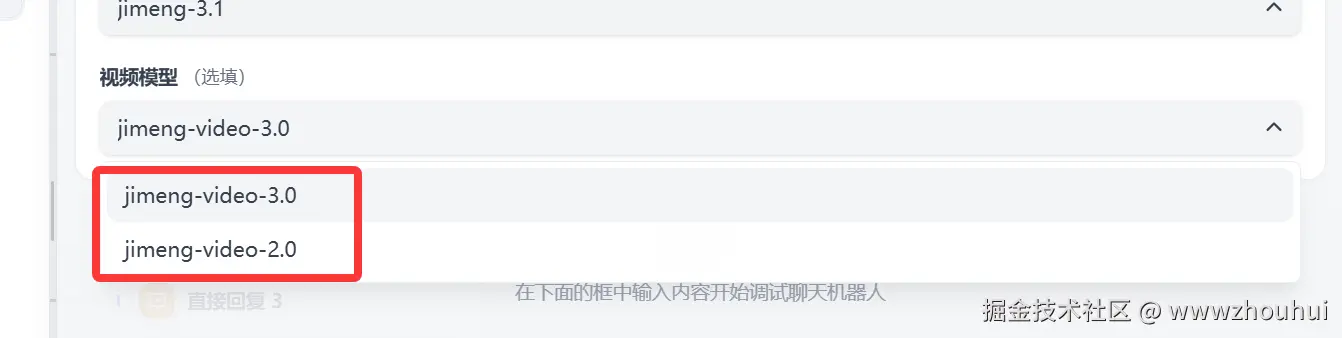
这里有一个地方需要解释下,如果大家对生成的视频尺寸有要求,比如想要9:16 的 这里需要修改http请求的 width":1536 ,"height":864。 我这里也有一个比较常见的配置说明:常用的文生图、文生视频比例提供如下三种
1:1 width:1024,height:1024
16:9 width:1536,height:864
9:16 width:864,height:1536
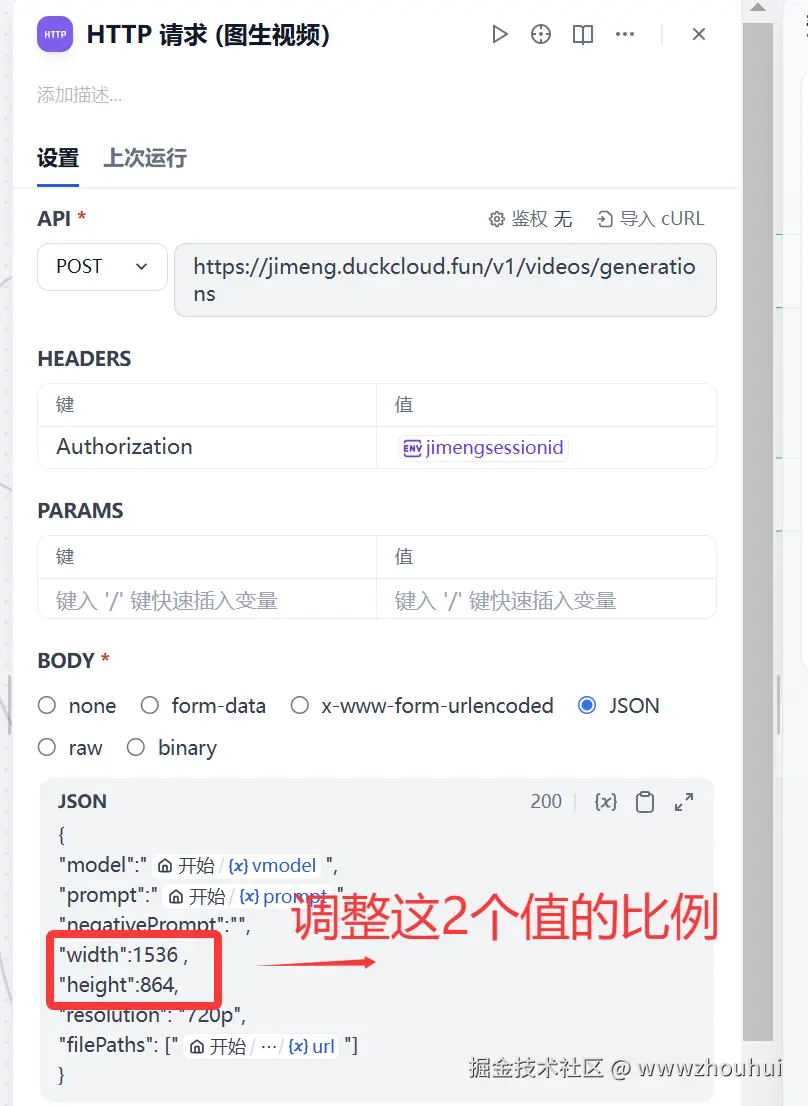
调整完成后 需要多工作流点击保存并发布才能生效。
dify工作流体验地址
工作流地址:dify.duckcloud.fun/chat/rx8PtS...
由于我账号不是会员号,每天送80积分,文生图每次消耗1积分。文生视频消耗比较多3.0的视频大概一次10积分,积分消耗完大家就等明天吧。
4.总结
今天主要带大家了解并实现了基于 Dify 工作流构建即梦 AI 3.0 多模态生成系统的完整流程,该系统以即梦 AI 最新的文生图 3.1 模型、视频 3.0 模型为核心,结合 Dify 平台的工作流逻辑和灵活的节点配置能力,形成了一套覆盖文生图、文生视频及图生视频的全场景生成方案。
通过这套实践方案,用户能够低成本体验即梦 AI 的高级生成能力 ------ 借助平台每日赠送的免费积分,无需复杂的后端开发,就能快速生成具备影视质感的图像和动作、镜头遵循能力优异的视频,极大降低了 AI 创作的技术门槛和使用成本。在实际验证中,该工作流能够稳定响应不同类型的生成需求,无论是通过中文提示词直接创作,还是上传图片进行二次视频生成,都能产出符合预期的高质量内容,有效解决了普通用户调用即梦最新模型流程繁琐、专业参数配置复杂的问题。同时,工作流具备良好的扩展性 ------ 小伙伴们可以基于此框架扩展更多实用功能,如短视频平台的批量素材生成、广告创意的多版本快速迭代、教育场景的动态内容制作等,进一步丰富 Dify 平台的多模态创作应用场景。
感兴趣的小伙伴可以按照这份指南尝试搭建自己的即梦 AI 生成工作流,甚至结合其他 AI 工具拓展更多创意玩法。今天的分享就到这里结束了,我们下一篇文章见。