随着业务逻辑的堆积,代码劣化加重,浏览器会时而出现崩溃的情况。即浏览器进程直接崩溃或页面被强制终止,用户通常会看到 "Aw, Snap!"(喔唷,崩溃啦!)等提示。这类崩溃会导致页面完全不可用,所有未保存的数据丢失,用户只能刷新或关闭页面,会极大影响用户体验。为了及时发现和定位这些问题,前端埋点上报成为了必不可少的手段。本文将介绍如何通过浏览器原生的 Reporting API,实现高效、可靠的崩溃埋点上报,助力前端崩溃治理。

如上图,用户常见的浏览器崩溃提示页面。
前端常见的崩溃类型
在前端开发实践中,浏览器崩溃(crash)并非偶发事件,而是由多种复杂因素叠加导致的结果。随着业务复杂度提升,页面承载的数据量、交互频率和第三方依赖不断增加,浏览器进程面临更高的稳定性挑战。常见的崩溃类型包括:
- 内存泄漏 :对象未被及时释放,内存持续增长,最终可能触发浏览器 crash。
- 例:组件频繁创建销毁但事件监听未解绑,内存不断增长,最终浏览器崩溃。
- 页面无响应 :主线程被长时间阻塞,浏览器可能判定页面失去响应,强制终止页面进程。
- 例:死循环或大量同步计算,页面卡死,最终被浏览器终止。
浏览器 crash 通常意味着页面主进程被浏览器强制终止,所有 JavaScript 代码立即停止执行,页面上下文被销毁。此时,常规的埋点逻辑(如 fetch、XMLHttpRequest、navigator.sendBeacon 等)都无法运行或完成数据上报,导致关键的崩溃信息丢失。因此,只有专门设计的崩溃埋点机制,才能在极端情况下保障异常信息的可靠上报。
崩溃埋点的常见实现方式
前端崩溃埋点的实现方式主要有以下几种,每种方式适用的场景和覆盖的崩溃类型各有不同:
1. 常规埋点方式
- 原理 :在全局异常处理(如
window.onerror、window.addEventListener('error')、window.addEventListener('unhandledrejection'))中捕获错误,上报到服务端。 - 优点:实现简单,适用于大部分 JavaScript 运行时错误和资源加载失败。
- 局限:对于浏览器 crash、主线程阻断等致命异常,常规埋点代码无法执行或上报,存在数据丢失风险。
2. 利用 Service Worker
- 原理:通过主线程(页面)定期向 Service Worker 发送心跳消息(如 postMessage),Service Worker 维护最近一次收到心跳的时间。如果在设定时间内未收到新的心跳,则推测主线程可能已崩溃、卡死或被强制终止。此时,Service Worker 可尝试独立上报异常信息。
- 优点:即使主线程失去响应,Service Worker 仍可独立运行,有一定能力检测主线程是否"失联"并进行上报。
- 局限 :
- 误判率较高,主线程长时间卡顿、网络波动、系统休眠等也会导致心跳中断,无法准确区分卡顿与崩溃。
- 检测时机依赖心跳间隔,间隔短影响性能,间隔长则检测不及时。
3. 本地状态存储对比
- 原理:在本地(如 localStorage、IndexedDB)周期性记录页面运行状态(如最后活跃时间、页面关闭标记等)。下次页面加载时对比上次状态,若发现异常(如无正常关闭标记),可推测上次为异常退出或 crash,并进行补偿性上报。
- 优点:可一定程度上检测到 crash 或异常关闭。
- 局限:无法精确定位 crash 原因,存在误报(如强制关机、浏览器崩溃、系统休眠等场景均可能被判定为异常退出)。
4. 借助浏览器原生 Reporting API
- 原理:利用浏览器的 Reporting API,由浏览器底层在检测到崩溃、内存溢出等异常时自动上报。
- 优点:即使主进程崩溃,浏览器也能在底层完成异常数据的可靠上报,适用于捕获致命 crash。
- 局限 :
- 兼容性有限,部分老旧浏览器不支持,且需要服务端配合接收 report。
- 上报的报告内容较少,通常只包含崩溃类型、原因等基础信息。
使用 Reporting API 实现崩溃埋点
上述方案进行对比,最终选择 Reporting API,主要是因为它能在主线程崩溃等极端情况下依然准确上报异常信息,并且无需在业务代码中频繁插入埋点逻辑,对正常业务流程零侵入,兼顾了准确性和性能。
Reporting API 简介
Reporting API 是浏览器提供的一种原生机制,用于自动收集和上报页面运行中的各类异常信息(如崩溃、资源加载失败、内容安全策略违规等)。它通过浏览器底层监控,无需依赖业务代码即可实现异常数据的可靠上报,适用于高可靠性埋点和异常监控场景。
Reporting API 主要包括以下能力:
-
ReportingObserver 接口:允许开发者在 JavaScript 中监听和处理浏览器生成的报告(如崩溃、内容安全策略(CSP)违规、Deprecation 报告等)。
示例:监听报告
jsconst observer = new ReportingObserver((reports, observer) => { console.log(reports); }, { types: ['deprecation'], buffered: true }); observer.observe(); -
Reporting-Endpoints 响应头:用于声明浏览器异常报告的接收端点,是当前推荐的标准方式。通过该响应头,浏览器可在检测到异常时自动将报告发送到指定的服务端地址,无需依赖前端代码执行。例如:
httpReporting-Endpoints: default="https://your-report-endpoint.example.com"
Reporting API 目前仅在 Chrome、Edge 等 Chromium 浏览器支持较好,其他浏览器支持有限。 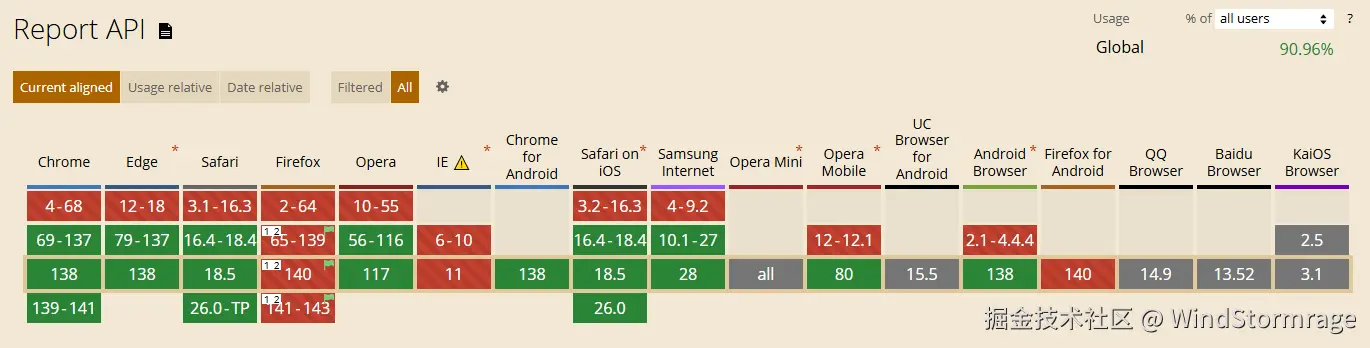 如上图,Reporting API 兼容性(caniuse 截图)
如上图,Reporting API 兼容性(caniuse 截图)
代码实现示例
ReportingObserver 适合开发者在前端主动监听和处理报告,但如果希望浏览器自动上报崩溃等异常,需要通过 Reporting-Endpoints 响应头声明上报端点。 这种方式下,前端业务代码无需改动,只需配置响应头即可。
1. 配置 Reporting-Endpoints 响应头(以 Node.js/Express 为例)
示例:Express 配置响应头
js
// 静态资源服务,带上 Reporting-Endpoints 响应头
app.use('/', express.static(path.join(__dirname, '../frontend/build'), {
setHeaders: (res) => {
res.setHeader('Reporting-Endpoints', 'default="https://crash-report.free.beeceptor.com"');
}
}));由于崩溃(crash)报告没有专门的端点配置,必须通过 default 端点统一接收。这意味着 default 端点还会收到其他类型的报告(如 deprecation、intervention 等),因此在服务端处理时,需要根据报告类型进行过滤和分类,确保只针对崩溃报告做相应处理。
2. 配置后端接收端点
- 你可以使用 beeceptor、httpbin 等在线服务快速接收和查看上报内容。
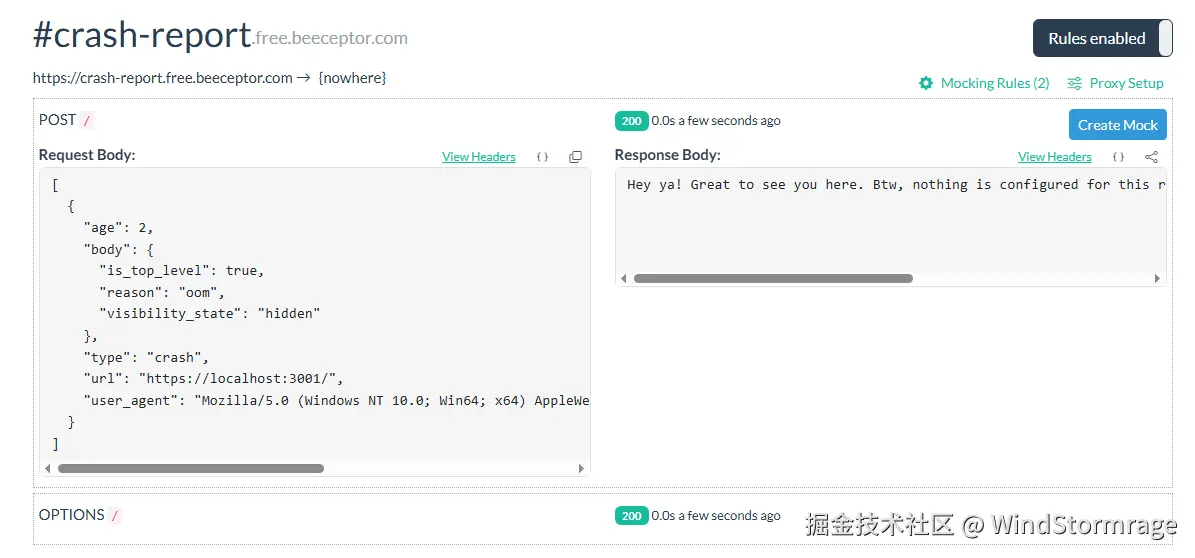 如上图,beeceptor 平台收到的崩溃上报请求示例
如上图,beeceptor 平台收到的崩溃上报请求示例 - 也可以自建接口,接收 POST 请求。
3. 报告内容示例
浏览器自动上报 crash 时,服务端收到的报告内容如下:
json
[
{
"age": 8,
"body": {
"reason": "oom"
},
"type": "crash",
"url": "https://localhost:3001/",
"user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36"
}
]type: 报告类型(如 crash)body.reason: 崩溃原因有两种:oom:页面内存溢出unresponsive:页面长时间无响应被浏览器强制终止
url: 崩溃发生的页面地址user_agent: 用户浏览器信息age: 报告生成到上报的延迟(秒)
完整demo效果可以见下面的录屏gif
注意事项
Reporting API 仅在 https 环境下生效,http 网站无法自动上报,本地开发和测试时,也需要使用 https 服务。
Node.js 本地 https 服务与自签名证书生成
本地开发推荐使用 npm 包 selfsigned 自动生成自签名证书,并直接用于 Node.js 启动 https 服务,无需手动操作。
示例:自动生成自签名证书并启动 https 服务
js
const express = require('express');
const https = require('https');
const selfsigned = require('selfsigned');
const app = express();
const port = 3001;
const pems = selfsigned.generate([{ name: 'commonName', value: 'localhost' }], { days: 365 });
const credentials = { key: pems.private, cert: pems.cert };
https.createServer(credentials, app).listen(port, () => {
console.log(`Backend server (HTTPS) listening at https://localhost:${port}`);
});崩溃上报优化方案
- 服务端补充用户信息和上报时间:收到崩溃报告后,服务端可结合用户的登录信息、会话标识、上报时间等进行补充,便于后续定位具体用户和还原崩溃发生的上下文。
- 细化 URL 内容:在页面 URL 中增加业务参数、路由状态等信息,确保收到报告后能准确还原用户出问题时的具体页面、模块和操作场景。
- 结合 rrweb 等工具录制用户操作:通过集成 rrweb 等前端录屏工具,自动录制用户关键操作和页面状态,在崩溃发生前后保存操作轨迹,便于开发和测试人员回放还原问题现场。
- 配置自动告警与用户访谈机制:崩溃报告触发后,自动推送告警给相关负责人,必要时可第一时间联系用户进行访谈,获取更多细节信息,提升问题定位和修复效率。
- 建设通用的 crash 上报服务:建议团队统一建设通用的崩溃上报服务,提供标准化的接入方式和数据结构,方便多系统、多个前端项目快速集成,降低接入和维护成本。
总结
前端崩溃埋点是保障用户体验和提升产品稳定性的关键手段。Reporting API 作为浏览器原生的崩溃上报方案,具备高可靠性和低侵入性的优势,但也存在兼容性和报告内容有限等局限。实际应用中,建议结合多种埋点方式、完善数据采集和告警机制,并建设通用的上报服务,持续优化崩溃治理体系,从而更高效地发现、定位和解决前端崩溃问题。