注:本系列源码分析基于XxlJob 2.3.0,gitee仓库链接:gitee.com/funcy/xxl-j....
本文我们将分析xxl-job-admin的启动流程。xxl-job-admin 是一个springboot项目,直接启动com.xxl.job.admin.XxlJobAdminApplication就可以了,但是在启动过程中,xxl-job相关功能是如何初始化的呢?
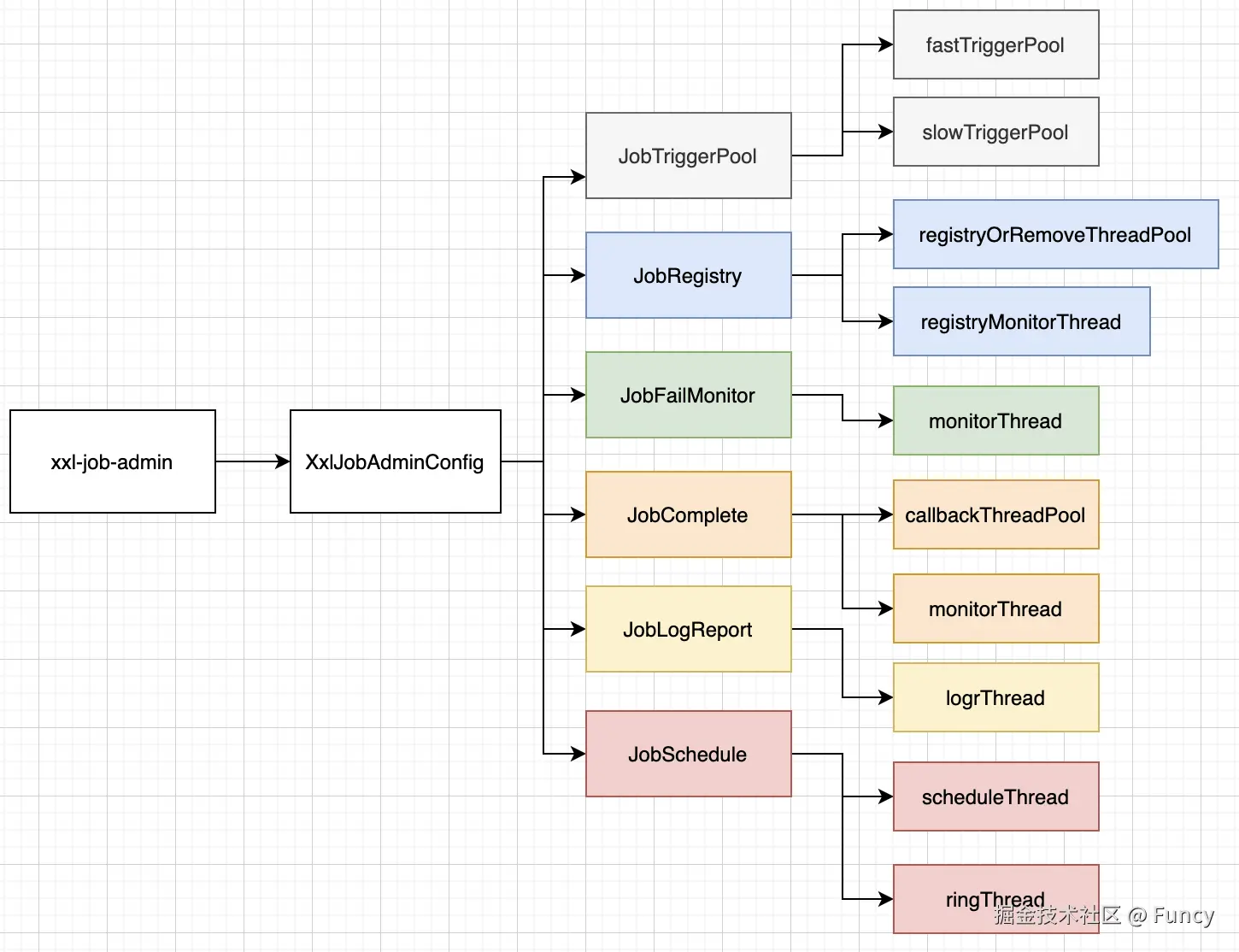
spring 配置类: XxlJobAdminConfig
经过本人的一番探索,发现xxl-job 相关组件的启动类为com.xxl.job.admin.core.conf.XxlJobAdminConfig:
java
@Component
public class XxlJobAdminConfig implements InitializingBean, DisposableBean {
private XxlJobScheduler xxlJobScheduler;
@Override
public void afterPropertiesSet() throws Exception {
adminConfig = this;
xxlJobScheduler = new XxlJobScheduler();
xxlJobScheduler.init();
}
@Override
public void destroy() throws Exception {
xxlJobScheduler.destroy();
}
...
// 省略了属性以及setter、getter方法
}关于这个类,几点说明如下:
- 该类被
@Component标记,表明这是个spring bean,享有spring bean的生命同期; - 该类实现了
InitializingBean与DisposableBean两个接口,提供了spring bean在初始化及销毁阶段的一些操作,对应的两个方法如下:afterPropertiesSet:来自InitializingBean接口,用来处理bean在初始化时的一些操作destroy:来自DisposableBean接口,用来处理bean在销毁时的一些操作
而实际上,XxlJobAdminConfig的afterPropertiesSet与destroy两个方法就是xxl-job启动与关闭的关键所在,而这两个方法都是调用的xxlJobScheduler的方法,接下来我们就来分析XxlJobScheduler#init与XxlJobScheduler#destroy方法。
这两个方法代码如下:
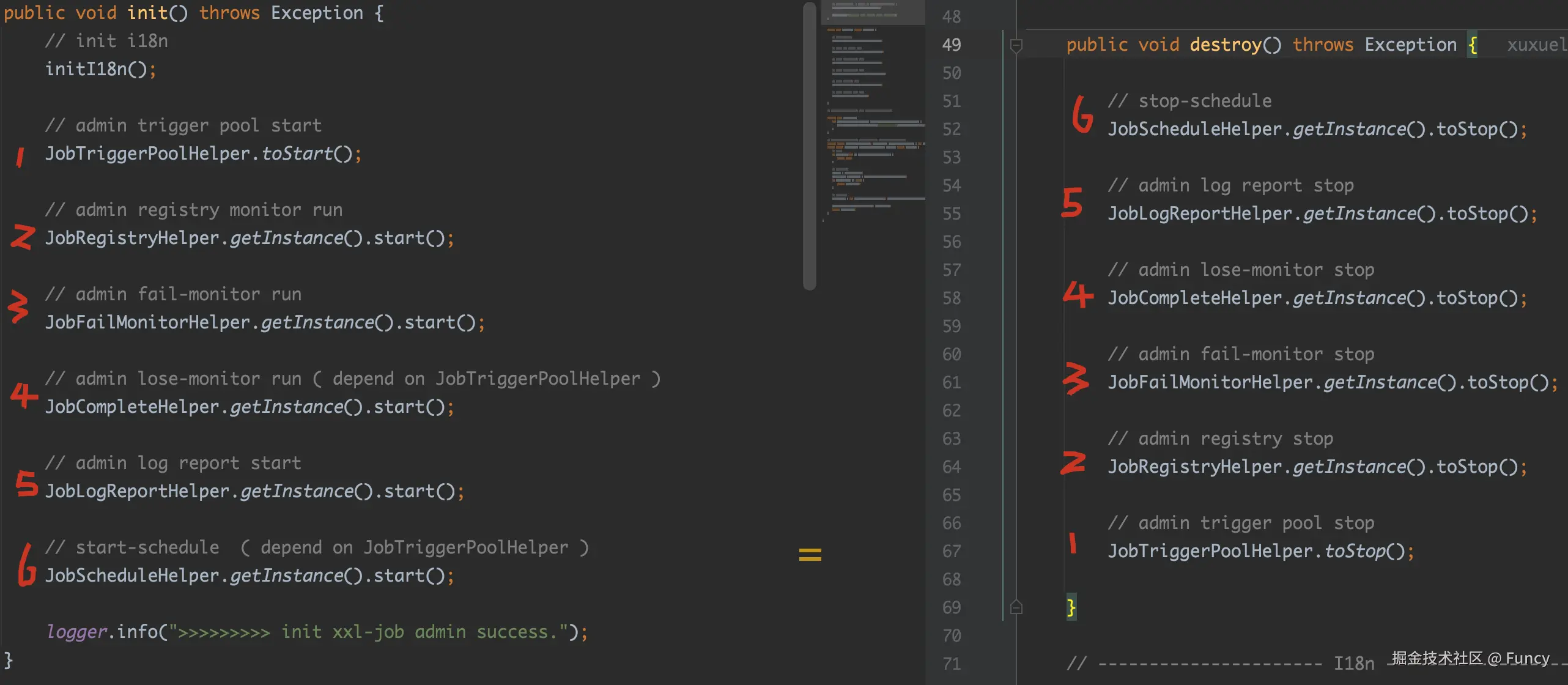
两个方法对比下可以看到,init方法正序启动了一系列组件,而destroy方法逆序关闭了一系列组件,正所谓"先启动的后关闭"。他们启动或关闭的组件如下:
JobTriggerPool:任务的触发线程,用来把需要执行的任务提交到执行器JobRegistry:任务执行器注册监听,用来监听执行器注册操作,及时移除无效的执行器JobFailMonitor:失败任务监听,用来监听失败任务,发送告警,对于重试次数大于0的失败任务会发再次触发执行JobComplete:任务完成监听,用来监听任务是否完成,把长时间处于运行中的任务标记为失败JobLogReport:任务报表,用来汇总任务的整体执行情况,也是管理后台"运行报表"菜单的数据来源JobSchedule:任务调度,用来获取接下来要执行的任务,将这些任务提交给触发线程
接下来我们就来看下这些组件的实现。
触发线程池:JobTriggerPoolHelper
触发线程池的处理类为JobTriggerPoolHelper,我们来看看它的启动方法JobTriggerPoolHelper.toStart():
java
public class JobTriggerPoolHelper {
// fast/slow thread pool
private ThreadPoolExecutor fastTriggerPool = null;
private ThreadPoolExecutor slowTriggerPool = null;
// 单例对象
private static JobTriggerPoolHelper helper = new JobTriggerPoolHelper();
// toStart() 方法
public static void toStart() {
// 往下调用
helper.start();
}
// toStop() 方法
public static void toStop() {
// 往下调用
helper.stop();
}
/**
* 创建了两个线程池
*/
public void start() {
// 创建 fastTrigger 线程池
fastTriggerPool = new ThreadPoolExecutor(
10,
// 在application.proerties中配置,默认 200
XxlJobAdminConfig.getAdminConfig().getTriggerPoolFastMax(),
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(1000),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "xxl-job, admin "
+ "JobTriggerPoolHelper-fastTriggerPool-" + r.hashCode());
}
});
// 创建 slowTrigger 线程池
slowTriggerPool = new ThreadPoolExecutor(
10,
// 在application.proerties中配置,默认 100
XxlJobAdminConfig.getAdminConfig().getTriggerPoolSlowMax(),
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(2000),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "xxl-job, admin "
+ "JobTriggerPoolHelper-slowTriggerPool-" + r.hashCode());
}
});
}
public void stop() {
//triggerPool.shutdown();
fastTriggerPool.shutdownNow();
slowTriggerPool.shutdownNow();
logger.info(">>>>>>>>> xxl-job trigger thread pool shutdown success.");
}
// 省略其他代码
...
}以上代码还是比较简单的,start()仅仅创建了两个线程池,从名称上来讲,fastTriggerPool用来处理耗时较短的任务的,slowTriggerPool用来处理耗时较长的任务的,这样分开是为了避免耗时长的任务挤满了线程池从而阻塞其他任务的执行。而stop()方法也简单,就是用来关闭这两个线程池。
这两个线程池启动成后,任务的触发就是由这两个线程池来处理的,不过这块内容本文就先不分析了,在后面分析任务的调度过程时再重点分析。
执行器注册监测:JobRegistryHelper
执行器的注册类为JobRegistryHelper,所谓的执行器,就是具体执行任务的服务,如xxl-job提供的示例执行器xxl-job-executor-sample-springboot,注意到xxl-admin与执行器处于不同进程,那么如何快速监测执行器的注册、下线呢?这就是JobRegistryHelper所做的工作,进入JobRegistryHelper#start方法:
java
public void start(){
// for registry or remove
registryOrRemoveThreadPool = new ThreadPoolExecutor(
2,
10,
30L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(2000),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "xxl-job, admin "
+ "JobRegistryMonitorHelper-registryOrRemoveThreadPool-"
+ r.hashCode());
}
},
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 拒绝策略,如果线程池已满,则直接执行任务(谁添加谁执行)
r.run();
logger.warn(">>>>>>>>>>> xxl-job, registry or remove too fast, "
+ "match threadpool rejected handler(run now).");
}
});
// for monitor
registryMonitorThread = new Thread(new Runnable() {
// 线程池内容
...
});
// 设置线程的一些属性,如:名称,设置为守护线程
registryMonitorThread.setDaemon(true);
registryMonitorThread.setName("xxl-job, admin "
+ "JobRegistryMonitorHelper-registryMonitorThread");
// 真正地启动线程
registryMonitorThread.start();
}以上方法比先是创建了一个线程池,然后创建了一个线程并启动,代码比较清晰,关键注释已经在代码中了,就不多说了。
注意到上面的代码其实省略了registryMonitorThread的run()方法,了解java多线程的小伙伴应该明白,Thread的run()方法就是线程运行的核心所在,下面我们就来看下registryMonitorThread的run()方法:
java
public void run() {
while (!toStop) {
try {
// 1. 查找自动注册的执行器
List<XxlJobGroup> groupList = XxlJobAdminConfig.getAdminConfig()
.getXxlJobGroupDao().findByAddressType(0);
if (groupList!=null && !groupList.isEmpty()) {
// 2. 找到心跳超时的执行器
List<Integer> ids = XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao()
.findDead(RegistryConfig.DEAD_TIMEOUT, new Date());
if (ids!=null && ids.size()>0) {
// 移除操作,就是数据库的删除操作
XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().removeDead(ids);
}
// 3. 处理在线的执行器,用HashMap<String,List<String>>保存,key为appName,value为ip
HashMap<String, List<String>> appAddressMap
= new HashMap<String, List<String>>();
// 找到有效的执行器
List<XxlJobRegistry> list = XxlJobAdminConfig.getAdminConfig()
.getXxlJobRegistryDao().findAll(RegistryConfig.DEAD_TIMEOUT, new Date());
if (list != null) {
for (XxlJobRegistry item: list) {
if (RegistryConfig.RegistType.EXECUTOR.name()
.equals(item.getRegistryGroup())) {
String appname = item.getRegistryKey();
List<String> registryList = appAddressMap.get(appname);
if (registryList == null) {
registryList = new ArrayList<String>();
}
if (!registryList.contains(item.getRegistryValue())) {
registryList.add(item.getRegistryValue());
}
// 将执行器的ip按appName分类,并保存到map中
appAddressMap.put(appname, registryList);
}
}
}
for (XxlJobGroup group: groupList) {
List<String> registryList = appAddressMap.get(group.getAppname());
String addressListStr = null;
if (registryList!=null && !registryList.isEmpty()) {
Collections.sort(registryList);
StringBuilder addressListSB = new StringBuilder();
// 多个服务器ip使用,连接
for (String item:registryList) {
addressListSB.append(item).append(",");
}
addressListStr = addressListSB.toString();
addressListStr = addressListStr.substring(0, addressListStr.length()-1);
}
group.setAddressList(addressListStr);
group.setUpdateTime(new Date());
// 4. 更新组的执行器ip
XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().update(group);
}
}
} catch (Exception e) {
if (!toStop) {
logger.error(">>>>>>>>>>> xxl-job, job registry monitor thread error:{}", e);
}
}
try {
// 5. 休眠,时间为30s,等于心跳超时时间
TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT);
} catch (InterruptedException e) {
if (!toStop) {
logger.error(">>>>>>>>>>> xxl-job, job registry monitor thread error:{}", e);
}
}
}
logger.info(">>>>>>>>>>> xxl-job, job registry monitor thread stop");
}对于该方法的关键之处,注释已经标明了,下面来一一看看这些操作。
1. 查找自动注册的执行器
代码如下:
scss
List<XxlJobGroup> groupList = XxlJobAdminConfig.getAdminConfig()
// addressType 指定为0,表示注册方式为自动注册
.getXxlJobGroupDao().findByAddressType(0);在执行器注册时,可以选择注册方式(自动注册与手动录入):
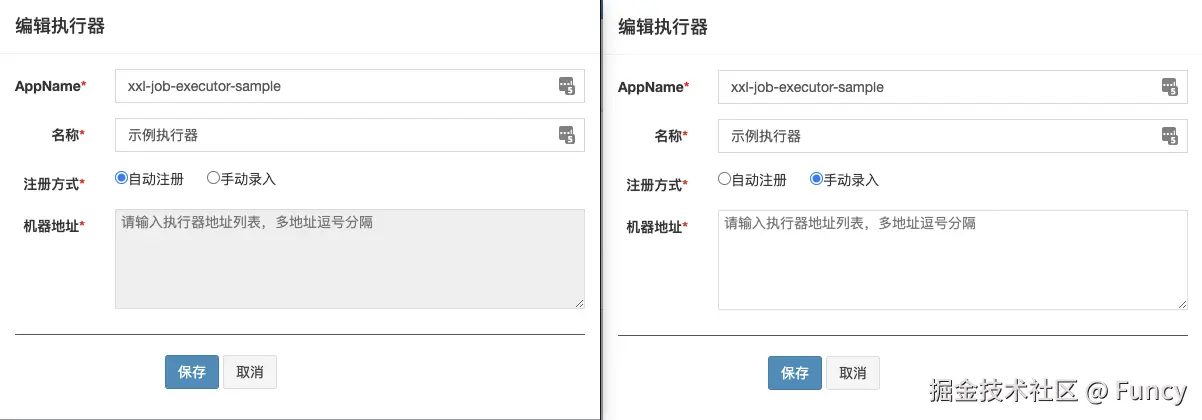
从上述代码的findByAddressType(0)可知,该线程只关注注册方式为自动注册的执行器。
跟进.findByAddressType(0)方法,最终进入mybatis的xml文件,执行的sql如下:
xml
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group AS t
WHERE t.address_type = #{addressType}
ORDER BY t.app_name, t.title, t.id ASC查询的是xxl_job_group表,语句比较简单,就不多分析了。
2. 查找心跳超时的执行器并移除
查到自动注册的执行器列表后,接下来就是找到各执行器下的有哪个服务挂了,并将其移除,代码如下:
java
// 找到心跳超时的执行器
List<Integer> ids = XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao()
.findDead(RegistryConfig.DEAD_TIMEOUT, new Date());
if (ids!=null && ids.size()>0) {
// 移除操作,就是数据库的删除操作
XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().removeDead(ids);
}这段代码有两个关键的方法:
- 查找无效的执行器:
.findDead(RegistryConfig.DEAD_TIMEOUT, new Date()) - 移除无效的执行器:
.removeDead(ids)
先来看.findDead(RegistryConfig.DEAD_TIMEOUT, new Date())方法,这里的RegistryConfig.DEAD_TIMEOUT为90,即执行器最近一次的注册时间与当时时间超时了90秒,就认为该执行器无效。进入该方法,最终执行的sql如下:
xml
SELECT t.id
FROM xxl_job_registry AS t
WHERE t.update_time <![CDATA[ < ]]> DATE_ADD(#{nowTime},INTERVAL -#{timeout} SECOND)可以看到这次操作的表是xxl_job_registry,该表保存的是执行器的注册记录,sql语句用到了mysql的时间计算函数,这块就不多说了。
继续来看看.removeDead(ids)方法,参数中的id就是上面找到的无效的执行器id,进入该方法,最终执行的sql语句如下:
xml
DELETE FROM xxl_job_registry
WHERE id in
<foreach collection="ids" item="item" open="(" close=")" separator="," >
#{item}
</foreach>所做的工作就是把无效的执行器从xxl_job_registry表中删除。
3. 查找有效的执行器
处理完无效的执行器后,觉得就是处理有效的执行器了,代码如下:
java
// 找到有效的执行器
List<XxlJobRegistry> list = XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao()
.findAll(RegistryConfig.DEAD_TIMEOUT, new Date());
// 将执行器的ip按appName分类,并保存到map中
HashMap<String, List<String>> appAddressMap = new HashMap<String, List<String>>();
if (list != null) {
for (XxlJobRegistry item: list) {
if (RegistryConfig.RegistType.EXECUTOR.name().equals(item.getRegistryGroup())) {
String appname = item.getRegistryKey();
List<String> registryList = appAddressMap.get(appname);
if (registryList == null) {
registryList = new ArrayList<String>();
}
if (!registryList.contains(item.getRegistryValue())) {
registryList.add(item.getRegistryValue());
}
// 将执行器的ip按appName分类,并保存到map中
appAddressMap.put(appname, registryList);
}
}
}这块代码关键就两处:
- 查找有效的执行器:
.findAll(RegistryConfig.DEAD_TIMEOUT, new Date()) - 得到有效执行器列表:
HashMap<String, List<String>> appAddressMap,key是执行器的appName,value是一个列表,存放的是执行器列表,支持多个执行器
先看 .findAll(RegistryConfig.DEAD_TIMEOUT, new Date())方法,这里的RegistryConfig.DEAD_TIMEOUT同样为90,与无效的执行器相反,最近一次的注册时间与当时时间小于90秒,就认为该执行器有效,执行的sql如下:
java
SELECT <include refid="Base_Column_List" />
FROM xxl_job_registry AS t
WHERE t.update_time <![CDATA[ > ]]> DATE_ADD(#{nowTime},INTERVAL -#{timeout} SECOND)拿到有效的执行器之后该如何处理呢?关键就是HashMap<String, List<String>> appAddressMap这个map了,上面的代码虽然看着好几行,其实所做的事就只有一点:将执行器的ip按appName分类,并保存到map中,map的key是执行器的appName,value是一个列表,存放的是执行器列表。
到这里,有效执行的查找流程就完成了。
4. 更新有效的执行器ip
继续,接着来看有效执行器的更新:
java
// 遍历第1步得到的 groupList
for (XxlJobGroup group: groupList) {
// 根据`group`的`appName`从`appAddressMap`中得到对应的执行器列表
List<String> registryList = appAddressMap.get(group.getAppname());
String addressListStr = null;
if (registryList!=null && !registryList.isEmpty()) {
Collections.sort(registryList);
StringBuilder addressListSB = new StringBuilder();
// 多个服务器ip使用,连接
for (String item:registryList) {
addressListSB.append(item).append(",");
}
addressListStr = addressListSB.toString();
addressListStr = addressListStr.substring(0, addressListStr.length()-1);
}
group.setAddressList(addressListStr);
group.setUpdateTime(new Date());
// 更新组的执行器ip
XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().update(group);
}这块代码所做的工作如下:
- 遍历第1步得到的
groupList,针对每个group进行操作 - 根据
group的appName从appAddressMap中得到对应的执行器地址列表addressList - 第2步得到的
addressList是一个List,接下来会把这个List转换成String,地址之间使用","分隔 - 更新组的执行器ip
我们直接进入.update(group)方法,看看更新组的执行器ip是如何处理的:
sql
UPDATE xxl_job_group
SET `app_name` = #{appname},
`title` = #{title},
`address_type` = #{addressType},
`address_list` = #{addressList},
`update_time` = #{updateTime}
WHERE id = #{id}这次操作的是xxl_job_group表,主要是将addressList更新到表中,这块就不多说了。
为了看下多个执行器的数据,本人特地开了两个xxl-job-executor-sample-springboot实例,数据如下:
xxl_job_registry 表:

xxl_job_group表:

5. 休眠,等待下次唤醒
更新完有效的执行器后,本次监测任务就完成了,接下来就是休息了:
java
try {
// 5. 休眠,时间为30s,等于心跳超时时间
TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT);
} catch (InterruptedException e) {
if (!toStop) {
logger.error(">>>>>>>>>>> xxl-job, job registry monitor thread error:{}", e);
}
}这块就是Thread.sleep操作,即线程休眠,没啥好说的。
分析到这里,该线程似乎有个缺陷:如果有两个xxl-job-admin实例,那么两个实例上都会运行该线程,这样就导致了两台机器上都会执行"查找无效的执行器-->移除"、"查找有效的执行器-->更新"两个操作。按道理讲,同一时间内这两个操作只需要在其中一台机器上执行就可以了,而代码中并无限制,频繁操作数据库无疑会造成资源浪费。
6. JobRegistryHelper#toStop 方法
分析完线程的启动后,接下来看看线程的停止操作,进入JobRegistryHelper#toStop方法:
java
public void toStop(){
// 修改线程运行标识
toStop = true;
// 关闭线程池
// stop registryOrRemoveThreadPool
registryOrRemoveThreadPool.shutdownNow();
// 打断线程的执行,主要针对于休眠的线程
// stop monitir (interrupt and wait)
registryMonitorThread.interrupt();
try {
// 等待线程终结
registryMonitorThread.join();
} catch (InterruptedException e) {
logger.error(e.getMessage(), e);
}
}可以说,这个方法的每一步操作都是关键,我们一步步来看:
-
关闭下一次执行:
toStop = ture在registryMonitorThread的run方法中,有这样的操作:javapublic void run() { while (!toStop) { ... } }将
toStop设置为true之后,下次while循环开始时,就不会再执行while循环体的代码了,在这里就跳出while循环了。 -
关闭线程池:
shutdownNow(),这个是立即关闭registryOrRemoveThreadPool,没啥好说的。 -
打断线程:
interrupt()前面已经将toStop设置为true了,还需求"打断"线程吗?注意到线程有休眠操作:javatry { TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT); } catch (InterruptedException e) { ... }如果调用
toStop()方法时,线程正好在休眠中,此时即时将toStop设置为true了,线程在漫长的休眠间唤醒后才会终结,因此interrupt()方法就是为了让线程立即结束休眠操作的。 -
等待线程终结:
join()这里就是一个小细节了,在一开始设置线程的属性时,会这样的设置:registryMonitorThread.setDaemon(true),即把registryMonitorThread设置成了"守护线程",区别于非守护线程,主线程在结束的时候不管守护线程的死活(主线程要等到非守护线程结束时才会结束),join()方法的注释如下: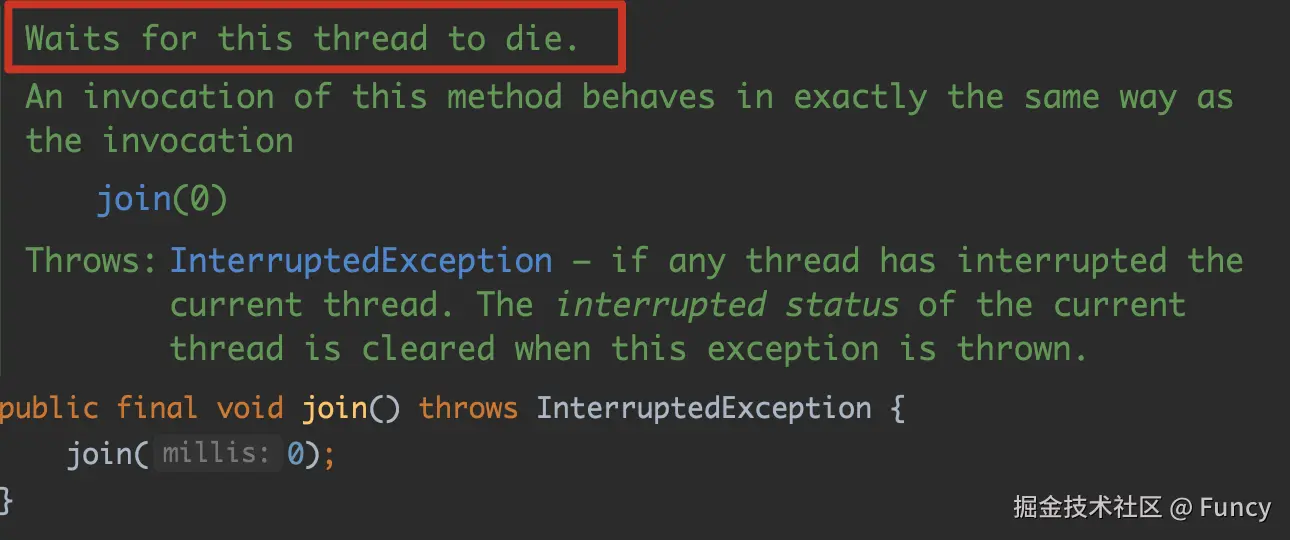 注释的第一句就表明了,当前线程会在等待直到
注释的第一句就表明了,当前线程会在等待直到registryMonitorThread终结。
失败任务监测:JobFailMonitorHelper
接着来看看失败任务的监测,代码如下:
java
private Thread monitorThread;
private volatile boolean toStop = false;
/**
* start 方法
*/
public void start(){
monitorThread = new Thread(new Runnable() {
// 先省略线程执行的内容
...
});
monitorThread.setDaemon(true);
monitorThread.setName("xxl-job, admin JobFailMonitorHelper");
monitorThread.start();
}
/**
* stop 方法
*/
public void toStop(){
toStop = true;
// interrupt and wait
monitorThread.interrupt();
try {
monitorThread.join();
} catch (InterruptedException e) {
logger.error(e.getMessage(), e);
}
}可以看到,JobFailMonitorHelper的start()/toStop()方法与JobRegistryHelper形式上几乎一致,而事实上,后面几个组件的代码形式上也基本一致,start()方法都是创建线程、设置属性、启动,toStop()方法也都是设置停止标识、打断线程、等待线程终结,考虑到篇幅原因,后面的分析中,我们将重点关注每个组件不同的部分,也就是各线程的run()方法。
monitorThread的run()方法如下:
java
@Override
public void run() {
// monitor
while (!toStop) {
try {
// 1. 查找失败的任务,失败任务的定义:运行日志中,code非200
List<Long> failLogIds = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao()
.findFailJobLogIds(1000);
if (failLogIds!=null && !failLogIds.isEmpty()) {
for (long failLogId: failLogIds) {
// 2. lock log,简单的加锁操作,利用mysql行锁,更新成功表示加锁成功
int lockRet = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao()
.updateAlarmStatus(failLogId, 0, -1);
if (lockRet < 1) {
continue;
}
XxlJobLog log = XxlJobAdminConfig.getAdminConfig()
.getXxlJobLogDao().load(failLogId);
XxlJobInfo info = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao()
.loadById(log.getJobId());
// 3、fail retry monitor:失败重试次数大于0
if (log.getExecutorFailRetryCount() > 0) {
// 触发执行
JobTriggerPoolHelper.trigger(log.getJobId(), TriggerTypeEnum.RETRY,
(log.getExecutorFailRetryCount()-1),
log.getExecutorShardingParam(),
log.getExecutorParam(), null);
String retryMsg = "<br><br><span style=\"color:#F39C12;\" > >>>>>>>>>>>"
+ I18nUtil.getString("jobconf_trigger_type_retry")
+"<<<<<<<<<<< </span><br>";
log.setTriggerMsg(log.getTriggerMsg() + retryMsg);
XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao()
.updateTriggerInfo(log);
}
// 4、fail alarm monitor 失败告警
// 告警状态:0-默认、-1=锁定状态、1-无需告警、2-告警成功、3-告警失败
int newAlarmStatus = 0;
if (info!=null && info.getAlarmEmail()!=null
&& info.getAlarmEmail().trim().length()>0) {
boolean alarmResult = XxlJobAdminConfig.getAdminConfig()
.getJobAlarmer().alarm(info, log);
newAlarmStatus = alarmResult?2:3;
} else {
newAlarmStatus = 1;
}
XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao()
.updateAlarmStatus(failLogId, -1, newAlarmStatus);
}
}
} catch (Exception e) {
if (!toStop) {
logger.error(">>>>>>>>>>> xxl-job, job fail monitor thread error:{}", e);
}
}
try {
// 5. 休眠10s
TimeUnit.SECONDS.sleep(10);
} catch (Exception e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
}
logger.info(">>>>>>>>>>> xxl-job, job fail monitor thread stop");
}这个方法所做的工作如下:
- 查找失败的任务
- 更新XxlJobLog的告警状态
- 失败重试
- 发送告警邮件
- 休眠操作
接着我们就逐一看下这几个操作。
1. 查找失败的任务
这块代码如下:
java
List<Long> failLogIds = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao()
.findFailJobLogIds(1000);方法findFailJobLogIds(1000)中的1000,表示的是查询的最大记录数,这方法执行的sql语句如下:
sql
SELECT id FROM `xxl_job_log`
WHERE !(
(trigger_code in (0, 200) and handle_code = 0)
OR
(handle_code = 200)
)
AND `alarm_status` = 0
ORDER BY id ASC
LIMIT #{pagesize}sql语句的关键在于where后面的条件,trigger_code与handle_code含义如下: trigger_code:调度状态,初始状态为0,成功状态为200 handle_code:执行状态,初始状态为0,成功状态为200
由此,可以推断出两个条件含义:
trigger_code in (0, 200) and handle_code = 0:调度状态为初始状态或成功,且执行状态为初始状态handle_code = 200:执行行状态为成功
trigger_code与handle_code的状态机流转如下(关于源码的实现细节在后面分析调度流程时再详细展开):
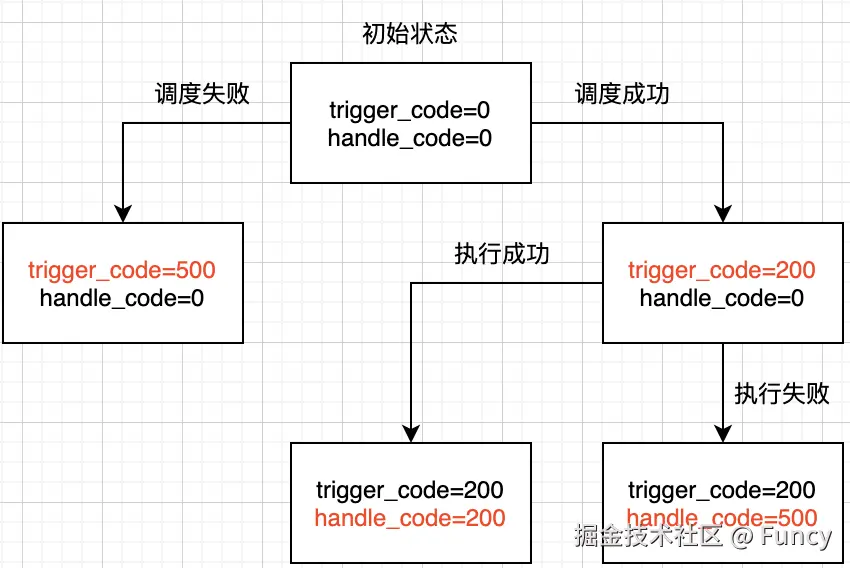
由此,该sql得到的结果为除以上两种情况并且alarm_status为0的所有任务记录,即为失败任务。
2. 更新XxlJobLog的告警状态
得到失败的任务后,接下来就是对任务的进一步操作,代码如下:
java
// 更新任务运行日志的状态
int lockRet = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao()
.updateAlarmStatus(failLogId, 0, -1);
if (lockRet < 1) {
continue;
}
// 获取日志信息,以及任务信息
XxlJobLog log = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().load(failLogId);
XxlJobInfo info = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao()
.loadById(log.getJobId());首先来看下.updateAlarmStatus(failLogId, 0, -1)方法,执行的sql如下:
sql
UPDATE xxl_job_log
SET
`alarm_status` = #{newAlarmStatus}
WHERE `id`= #{logId} AND `alarm_status` = #{oldAlarmStatus}结合sql语句与方法来看,该方法的功能是将指定任务日志的告警状态(alarm_status)由0更新到-1,这里的alarm_status含义如下:
- 0:默认
- -1:锁定状态
- 1:无需告警
- 2:告警成功
- 3:告警失败
熟悉mysql的执行机制的小伙伴会知道,这条sql语句的执行会触发mysql的行锁,例如,当两个线程同时对logId的任务日志更新时,最终只会有一个线程执行成功,执行成功后.updateAlarmStatus(failLogId, 0, -1)方法的返回值会大于0。因此多个xxl-job-admin实例的情况下,该方法的执行结果可以当作分布式锁来使用,即只有.updateAlarmStatus(failLogId, 0, -1)方法的返回值大于0时,才能继续往下执行,这也对应了如下的判断:
java
if (lockRet < 1) {
continue;
}在线程得到继续往下执行的资格后,接着就是加载详细的日志信息(XxlJobLog)与任务信息(XxlJobInfo)了,这块就是根据id查询记录的操作,就不多说了。
3. 失败重试
线程获得执行资格后,继续往下执行,就到了失败重试的处理,代码如下:
java
if (log.getExecutorFailRetryCount() > 0) {
// 触发执行
JobTriggerPoolHelper.trigger(log.getJobId(), TriggerTypeEnum.RETRY,
(log.getExecutorFailRetryCount()-1), log.getExecutorShardingParam(),
log.getExecutorParam(), null);
// 更新任务,重新设置了 retryMsg 的值
String retryMsg = "<br><br><span style=\"color:#F39C12;\" > >>>>>>>>>>>"
+ I18nUtil.getString("jobconf_trigger_type_retry") +"<<<<<<<<<<< </span><br>";
log.setTriggerMsg(log.getTriggerMsg() + retryMsg);
XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().updateTriggerInfo(log);
}对于重试次数大于0的失败,会调用JobTriggerPoolHelper.trigger(xxx)重新触发任务,然后再更新XxlJobLog的retryMsg字段,关于JobTriggerPoolHelper.trigger(xxx)的具体操作,我们在分析触发器时再详细展开,在这里只需要知道该方法是用来触发任务的就可以了。
对于以上代码,略一思考,发现有两个问题:
executorFailRetryCount的值最初从哪里来?- 执行完成后,
executorFailRetryCount的值并没有减1,之后会不会重复执行?
对于第一个问题,经过一番探索,发现来自于任务信息,可以管理后台界面配置,截图如下:
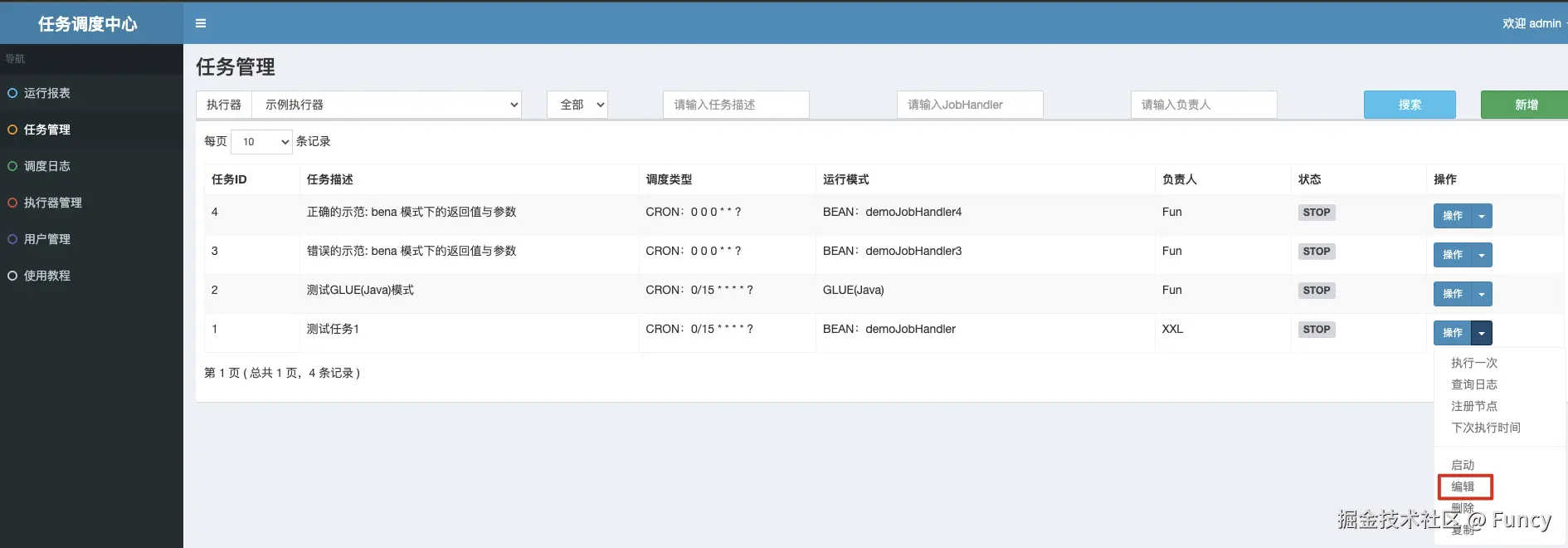
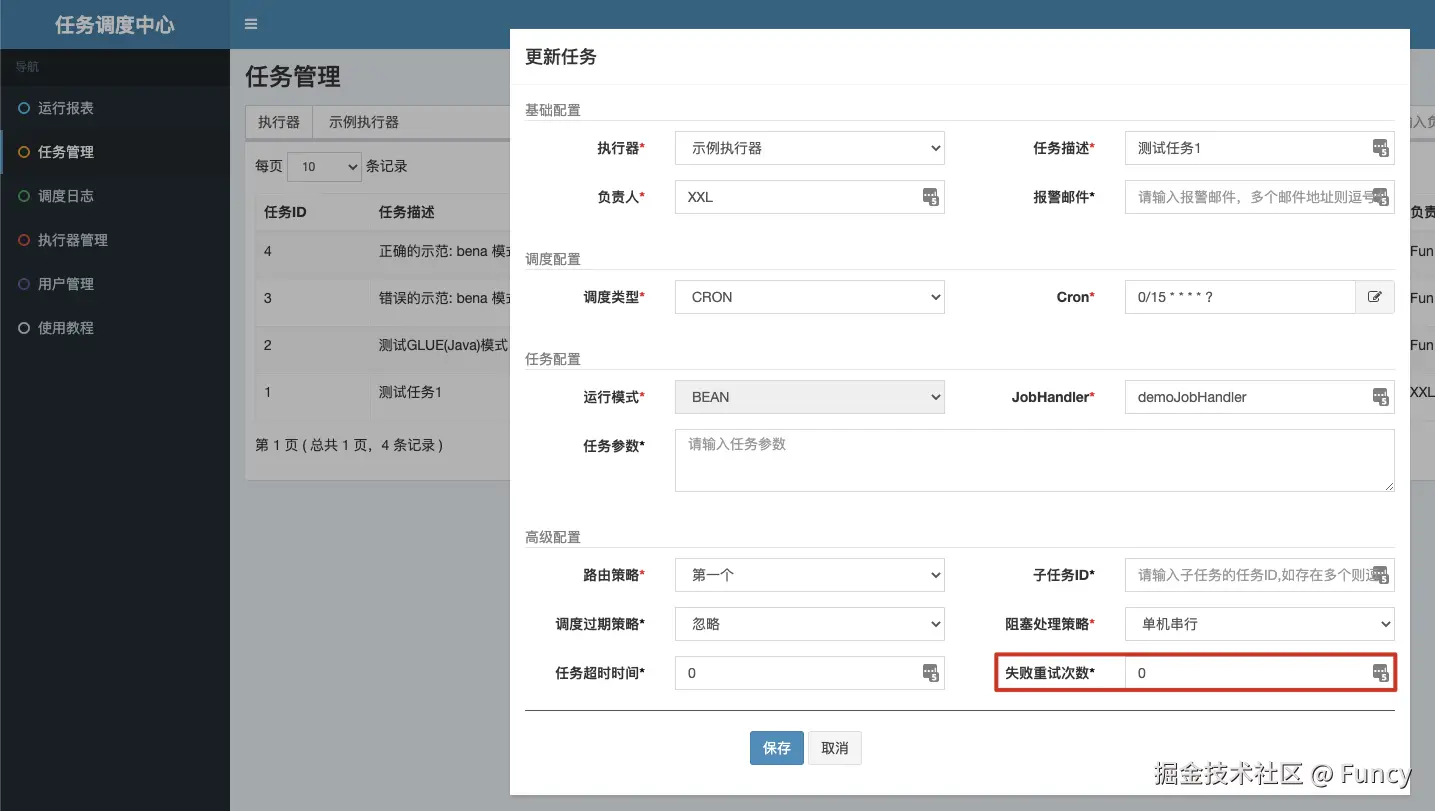
对于第二个问题,再往下看看的话,就会发现表中该记录的alarm_status的最终值并不是0,这就表示在下一次线程的执行中,该失败记录并不会查询出来(即上面第1步查询失败任务的操作),观察到JobTriggerPoolHelper.trigger(xxx)方法的参数(log.getExecutorFailRetryCount()-1),即该任务再一次执行时,重试次数就会减1,这样如果后续的执行一直失败,后一次执行记录的重试次数就会比前一次的重试次数少1,直到最后一次执行记录的重试次数为0即止。
比如,现在有id为100的任务,重试次数指定为3,且一直执行失败,执行1次后,所产生的执行记录与重试记录如下:
| 日志id | 任务id | 重试次数 | trigger_code | handle_code | alarm_status |
|---|---|---|---|---|---|
| 1 | 100 | 3 | 200 | 500 | 1 |
| 2 | 100 | 2 | 200 | 500 | 1 |
| 3 | 100 | 1 | 200 | 500 | 1 |
| 4 | 100 | 0 | 200 | 500 | 1 |
4. 发送告警邮件
发送告警邮件的代码如下:
java
// 4、fail alarm monitor 失败告警
// 告警状态:0-默认、-1=锁定状态、1-无需告警、2-告警成功、3-告警失败
int newAlarmStatus = 0;
if (info!=null && info.getAlarmEmail()!=null
&& info.getAlarmEmail().trim().length()>0) {
boolean alarmResult = XxlJobAdminConfig.getAdminConfig()
.getJobAlarmer().alarm(info, log);
newAlarmStatus = alarmResult?2:3;
} else {
newAlarmStatus = 1;
}收件人的配置了是在管理后台界面配置:
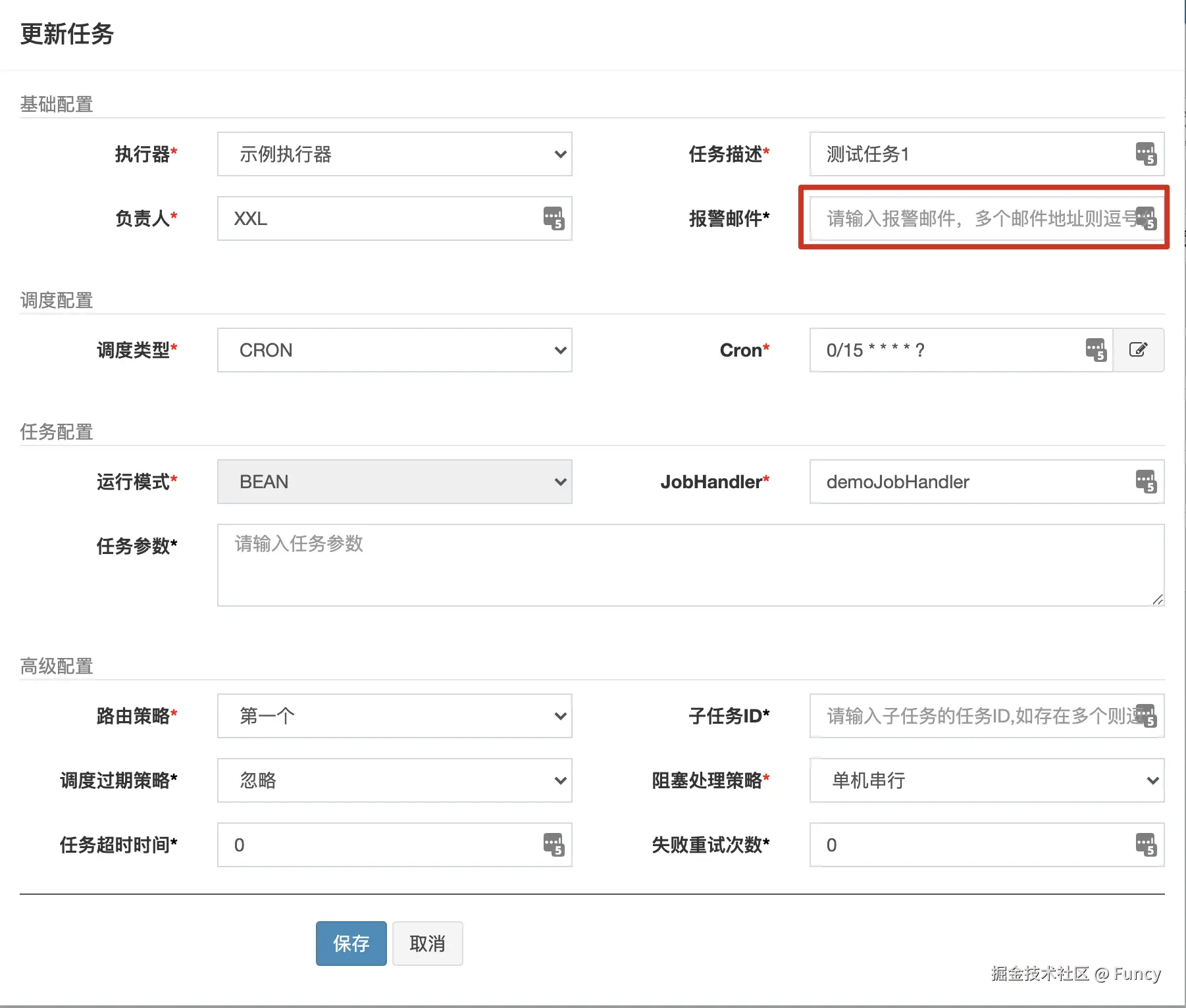
5. 休眠操作
执行完一波操作之后,接下来线程要休息了,这个线程的休息时间是10s,就不多作介绍了。
任务完成监听:JobCompleteHelper
继续来看下任务完成监听的处理,进入JobCompleteHelper#start方法:
java
public void start(){
// 创建线程池
callbackThreadPool = new ThreadPoolExecutor(
2,
20,
30L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(3000),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "xxl-job, admin "
+"JobLosedMonitorHelper-callbackThreadPool-" + r.hashCode());
}
},
// 拒绝策略:直接使用当前线程处理
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
r.run();
logger.warn(">>>>>>>>>>> xxl-job, callback too fast, match threadpool "
+ "rejected handler(run now).");
}
});
// 创建监听线程
monitorThread = new Thread(new Runnable() {
...
});
monitorThread.setDaemon(true);
monitorThread.setName("xxl-job, admin JobLosedMonitorHelper");
monitorThread.start();
}这个方法就做了两件事:
- 创建了一个线程池
- 创建了一个线程,并启动
关于线程池的作用这里就先不分析了,这里我们重点来看monitorThread所做的工作,其run()方法如下:
java
@Override
public void run() {
// 1. 休眠,为了等待 JobTriggerPoolHelper 的初始化
try {
TimeUnit.MILLISECONDS.sleep(50);
} catch (InterruptedException e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
// monitor
while (!toStop) {
try {
// 2. 任务结果丢失处理:调度记录停留在 "运行中" 状态超过10min,
// 且对应执行器无效,则将本地调度主动标记失败
Date losedTime = DateUtil.addMinutes(new Date(), -10);
List<Long> losedJobIds = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao()
.findLostJobIds(losedTime);
if (losedJobIds!=null && losedJobIds.size()>0) {
// 3. 遍历更新,将任务状态更新为失败
for (Long logId: losedJobIds) {
XxlJobLog jobLog = new XxlJobLog();
jobLog.setId(logId);
jobLog.setHandleTime(new Date());
// FAIL_CODE 就是失败的状态
jobLog.setHandleCode(ReturnT.FAIL_CODE);
jobLog.setHandleMsg( I18nUtil.getString("joblog_lost_fail") );
XxlJobCompleter.updateHandleInfoAndFinish(jobLog);
}
}
} catch (Exception e) {
if (!toStop) {
logger.error(">>>>>>>>>>> xxl-job, job fail monitor thread error:{}", e);
}
}
try {
// 4. 休眠,每60s检测一次
TimeUnit.SECONDS.sleep(60);
} catch (Exception e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
}
logger.info(">>>>>>>>>>> xxl-job, JobLosedMonitorHelper stop");
}该方法所做工作如下:
- 休眠,为了等待 JobTriggerPoolHelper 的初始化
- 获取需要处理的任务列表
- 遍历列表,更新状态
- 休眠,这次的休眠时间为 60s
关于两个休眠操作没啥好讲的,这里我们重点关注第2与第3步的操作。
获取需要处理的任务列表
获取任务列表的代码如下:
java
Date losedTime = DateUtil.addMinutes(new Date(), -10);
List<Long> losedJobIds = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao()
.findLostJobIds(losedTime);可以看到,代码中先是使用了一个Date实例,表示前10分钟的时候,然后调用 .findLostJobIds(losedTime)方法来查询任务列表,该方法执行的sql语句如下:
sql
-- 查找执行时间超过10分钟,且执行器不存在的执行记录(执行器可能下线了)
SELECT
t.id
FROM
xxl_job_log t
LEFT JOIN xxl_job_registry t2 ON t.executor_address = t2.registry_value
WHERE
t.trigger_code = 200
AND t.handle_code = 0
AND t.trigger_time <![CDATA[ <= ]]> #{losedTime}
AND t2.id IS NULL;从sql语句来看,xxl-job对失败任务的定义为执行时间超过10分钟,且执行器不存在的任务执行记录。
更新任务状态
获取到失败的任务记录后,接着就是更新任务状态了,代码如下:
java
for (Long logId: losedJobIds) {
XxlJobLog jobLog = new XxlJobLog();
jobLog.setId(logId);
jobLog.setHandleTime(new Date());
// FAIL_CODE 就是失败的状态
jobLog.setHandleCode(ReturnT.FAIL_CODE);
jobLog.setHandleMsg( I18nUtil.getString("joblog_lost_fail") );
XxlJobCompleter.updateHandleInfoAndFinish(jobLog);
}上述代码比较简单,就是一个简单的按id更新的操作,最终会将jobLog的handleCode更新为ReturnT.FAIL_CODE,即失败(500)。
任务报表处理:JobLogReportHelper
所谓的报表处理,就是汇总任务的执行情况(总数、成功数、失败数等),然后在管理后台首页进行展示:
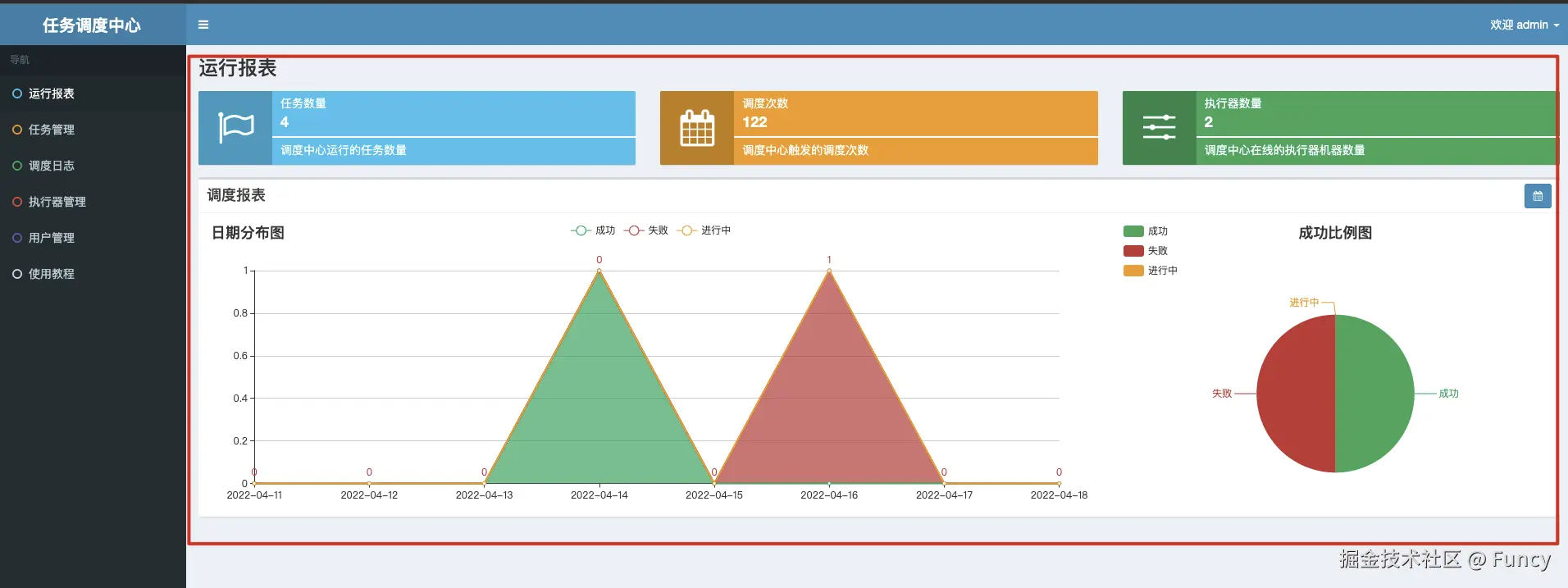
代码如下:
java
public void start(){
// 三天内的任务日志会以每分钟一次的频率异步同步至报表中
logrThread = new Thread(new Runnable() {
@Override
public void run() {
...
}
});
logrThread.setDaemon(true);
logrThread.setName("xxl-job, admin JobLogReportHelper");
logrThread.start();
}关于报表处理这块,由于非任务调试的主流程,因此本文就不深入了,代码不复杂,想了解的小伙伴可自行进入JobLogReportHelper类分析。
调度线程:JobScheduleHelper
调度器是xxl-job的三大核心组件之一(另外两个核心组件分别是触发器、执行器),处理调度操作的类是JobScheduleHelper,它的start()方法如下:
java
public void start(){
// schedule thread
scheduleThread = new Thread(new Runnable() {
@Override
public void run() {
...
}
});
scheduleThread.setDaemon(true);
scheduleThread.setName("xxl-job, admin JobScheduleHelper#scheduleThread");
scheduleThread.start();
// ring thread
ringThread = new Thread(new Runnable() {
@Override
public void run() {
...
}
});
ringThread.setDaemon(true);
ringThread.setName("xxl-job, admin JobScheduleHelper#ringThread");
ringThread.start();
}可以看到,在start()方法中启动了两个线程:
- 调度线程:
scheduleThread - 时间轮处理线程:
ringThread
这两个线程至关重要,正是由于这两个线程的相互配合,才使得xxl-job能准时无误地执行任务。由于本文重点介绍admin的启动流程,对JobScheduleHelper#start方法就介绍这么多了,本文只需要知道JobScheduleHelper#start方法启动了两个线程就可以了,关于这两个线程的具体功能,后面分析任务的调度流程时再重点分析。
总结
本文介绍了xxl-job-admin的启动流程,xxl-job-admin是一个springboot项目,启动时初始化其spring配置类,XxlJobAdminConfig,这个类就是xxl-job-admin启动的关键,在这个类里启动了如下组件:
JobTriggerPool:任务的触发线程,用来把需要执行的任务提交到执行器JobRegistry:任务执行器注册监听,用来监听执行器注册操作,及时移除无效的执行器JobFailMonitor:失败任务监听,用来监听失败任务,发送告警,对于重试次数大于0的失败任务会发再次触发执行JobComplete:任务完成监听,用来监听任务是否完成,把长时间处于运行中的任务标记为失败JobLogReport:任务报表,用来汇总任务的整体执行情况,也是管理后台"运行报表"菜单的数据来源JobSchedule:任务调度,用来获取接下来要执行的任务,将这些任务提交给触发线程
由于本文的重点在于分析xxl-job-admin的启动流程,因此对于部分组件未深入其中,组件与组件之间如果相互配合工作的也未深究,这些内容在分析具体功能在一一探索。
限于作者个人水平,文中难免有错误之处,欢迎指正!原创不易,商业转载请联系作者获得授权,非商业转载请注明出处。