TDS数据治理深度实践:从标准化到智能化的演进之路
TDS(Turing Data Studio)是专注于数据开发和治理的平台。其架构涵盖了从基础设施到用户功能的各个层次,包括数据开发、数仓管理、监控运维和资源管理等模块,支持高效的任务调度、资源管理和数据血缘分析。
上一代大数据产品在实际运行中仍存在以下关键问题:
- 开发阶段风险控制不足:
- 数据开发任务经过修改调试后,会直接用于处理线上数据,存在误操作直接影响线上数据的隐患。
- 产出阶段质量保障滞后:
-
数据产出质量。需要等数据完全产出后,通过人工校验或下游反馈发现,无法在数据产出过程中实时拦截空值、异常值等问题。
-
数据产出时效性。任务执行达到重试失败上限或触发延迟产出报警后,数据RD才能收到通知,难以有效维持数据时效性。
- 运维阶段处理低效:
-
日志分析有时需要值班同学帮助查看定位原因排查问题,依赖人工经验,处理问题效率较低。
-
数据产出异常时,由于涉及的类型和层级较多,难以快速准确识别下游受损范围,并导致未及时回溯数据。
为了解决上述问题,TDS建设了体系化的数据治理方案。
流程标准化(规范开发)→ 质量可控化(主动防控)→ 运维智能化(降本提效)。
从多环节入手进行数据治理的深度实践,覆盖数据开发全流程,确保数据资产的健康与可信。
本章节将详细阐述TDS平台在构建这一数据治理体系中的核心理念、技术实践与显著成效,为业界提供一套可借鉴的深度治理方案。
01 流程标准化:构建数据开发的"交通规则"体系------百度MEG TDS平台实践
在百度移动生态事业群组(MEG)的复杂数据开发生态中,日均处理超过40万个任务实例。
面对"环境混用、配置失控、协作低效"这三大长期痛点,我们基于TDS平台构建了一套四级流程控制引擎,将开发规范体系化落地。
本文将深入解析该体系中的三大核心机制:代码强制留档与评审 、测试环境自动化构建与管理 、智能配置管理的实践与成效。
1.1 全链路规范化设计:精密控制开发生命周期
数据治理的起点在于规范开发流程。我们认为,只有在开发阶段就将规则融入工具链,才能真正实现"零门槛"的合规。
1.1.1 开发阶段:环境隔离与自动化验证
混乱的开发环境是导致生产事故的常见原因。TDS平台通过自动化技术,为每个任务创建了一个安全、隔离的沙盒环境,确保开发与生产互不干扰。
- 自动化测试环境构建与管理:当开发人员在数仓管理模块创建生产表(如
user_behavior)时,系统会自动构建与之对应的完整测试环境体系。
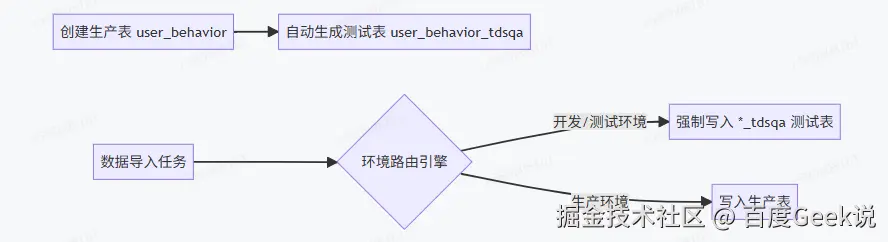
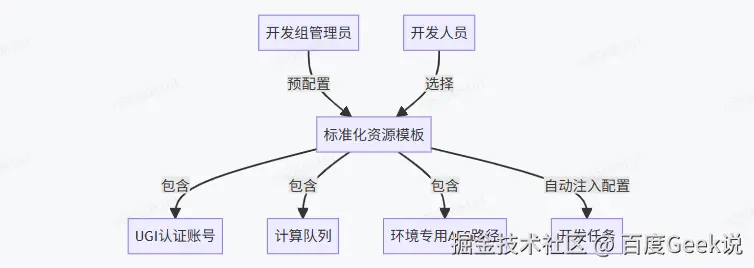
- 配置中心标准化管理:
通过预置标准化资源模板,实现配置的零接触管理和自动注入,从根本上杜绝了因手动配置错误导致的生产问题。
- 实施效果:
配置错误率从实施前的18.7%显著下降至0.4%。
新成员环境配置和基础任务上手时间从平均3天缩短至2小时以内。
-
分钟级任务验证加速:
基于TDS内置的TDE调试优化引擎,开发人员在编辑任务时可以随时提交SQL调试任务,大幅缩短验证周期。
-
核心技术支撑:
智能数据采样:自动抽取极小比例(如0.1%)的样本数据进行快速验证。
测试表直连:调试结果直接输出到对应的测试表(如 user_behavior_tdsqa)。
资源隔离:使用专用调试队列,避免与生产任务争抢资源。
1.2 上线阶段:代码留档、智能防护与强审批
任务上线是数据生产流程中的关键环节,任何疏漏都可能引发严重的生产事故。TDS平台通过代码强制留档、智能变更识别 和核心任务审批,构筑了三重安全防线。
1.2.1 上线单完整流程

1.2.2 自动化代码治理流水线
建立强制性的代码评审与归档流程,确保变更可追溯、可审计。
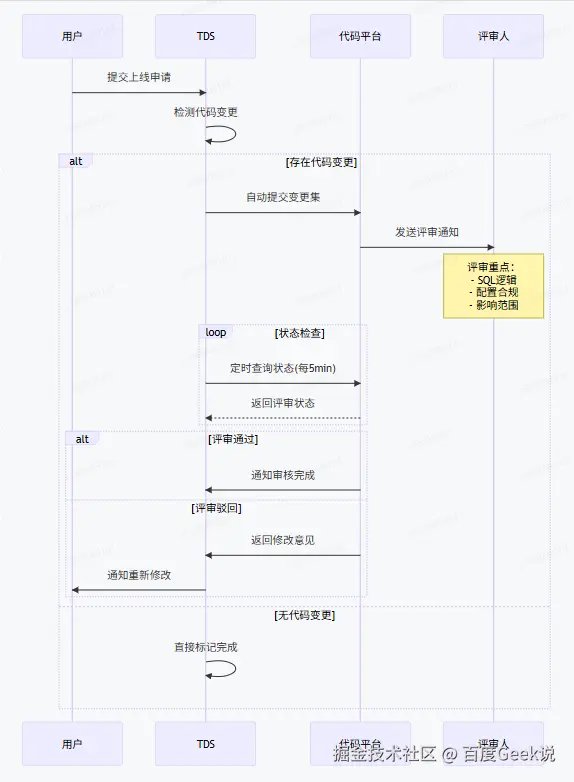
- 核心控制机制与价值:
强制代码提交:深度集成icode API,实现100%变更可追溯。
评审硬卡点:TDS流程引擎与iCode状态强同步,杜绝未经评审的代码进入生产。
版本快照绑定:任务版本与icode Commit ID 绑定,秒级精准定位任意历史任务版本。
1.2.3 智能变更识别引擎与核心任务审批
采用双轨检测技术(配置比对 + AST语法树分析)精准识别变更风险,并对核心任务实施严格审批。
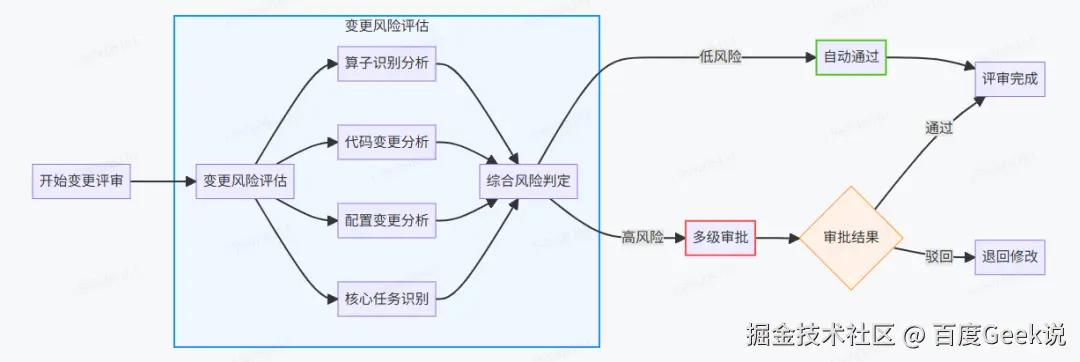
- MD5比对关键字段:
输出目标:生产环境AFS路径、ClickHouse表名等。
数据来源:输入表、文件路径。
计算逻辑指纹:SQL语句/Python代码核心片段的哈希值。
-
核心任务标识与审批强化: 对于平台标记为"核心任务"的任务(通常涉及关键业务数据、高流量或具有广泛下游依赖),任何配置或代码的变更,无论风险评估等级高低,均强制触发完整的三级审批流程。此流程需业务负责人、技术负责人及平台负责人共同确认。
-
拦截成效:
平均每月成功拦截可能导致数据污染、服务中断的高危操作超过50次。
生产环境配置误变更率降至0.1%。
02 质量可控化------数据可信度的保障
数据质量是数据价值实现的前提。在流程标准化建立起开发规范后,如何确保流经平台的数据本身是可靠、可信的,成为下一个核心挑战。
TDS平台构建了一套"预防为主、监控为辅、治理兜底"的三层防护体系,覆盖数据任务从设计、执行到故障处理的全生命周期。
2.1 三层防护体系:构建全流程数据治理监控屏障
2.1.1 事前防控:从源头规避数据风险
事前防控是数据治理监控的第一道防线。我们通过建立数仓 Schema 强约束,在数据任务开发与设计阶段就规避潜在风险,减少后续环节的异常。
-
字段类型预校验 :确保数据类型的一致性和准确性,防止因类型不匹配导致的计算错误或数据截断。例如,如果源字段是
STRING类型,而目标字段是INT类型,系统会发出警告或直接阻止任务创建。 -
分区规则预校验:确保分区字段、分区格式与命名规范统一,避免因分区不一致导致的数据查询不完整或任务失败。
2.1.2 事中监控:实时捕捉异常并快速响应
事中监控是数据治理的核心环节,旨在实时发现数据质量与任务进度的异常,并触发告警。
2.1.2.1 数据质量校验:多维度保障数据可靠性
数据质量校验通过构建多维度的评估指标体系,对数据进行实时检测。架构图如下:
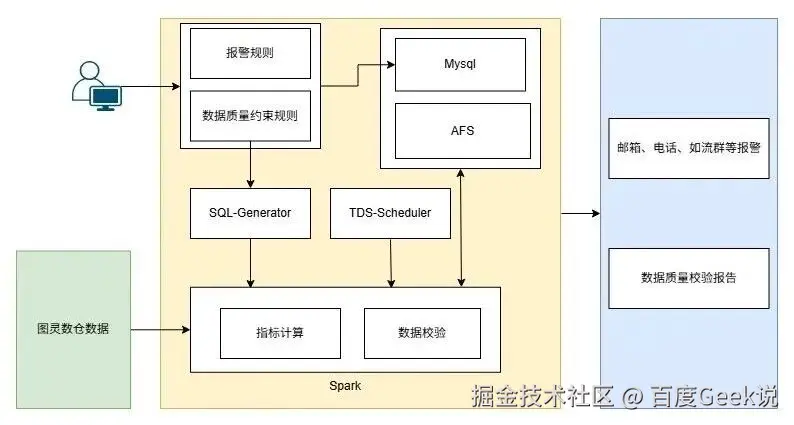
- 架构:
外部输入层:用户在TDS平台配置数据质量校验规则,指定数据源为图灵数仓表。
- 核心架构层:
数据质量约束(Data Quality Constraints):涵盖行数、重复值、空值、异常值、表字段等多种规则,从精确度、完整性、唯一性、有效性、一
致性等多维度进行校验。
SQL-Generator:根据用户配置的校验规则生成Spark SQL。
TDS-Scheduler:在数据加工过程中,调度数据质量校验算子进行数据校验。
指标计算:利用Spark从图灵数仓读取数据源,计算各项质量指标。
数据校验:将计算结果与预设规则进行比对,判断是否存在质量问题。
- 输出层:
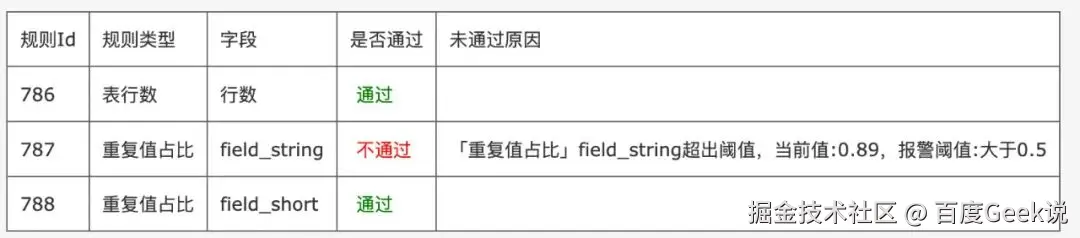
数据质量报告:生成可视化、结构化的报告,汇总约束验证结果。报告样例如下:
- 异常报警:采用分级报警机制(警告、严重、紧急),支持邮箱、如流、短信、电话等多种报警方式,确保异常能被及时处理。
2.1.2.2 SLA 风险监控:保障任务执行时效性
SLA(服务等级协议)是衡量任务执行效率的重要标准。TDS平台的SLA实时追踪功能,通过对任务执行进度的实时监控,及时发现超时或失败的任务,确保任务按时完成。架构图如下:
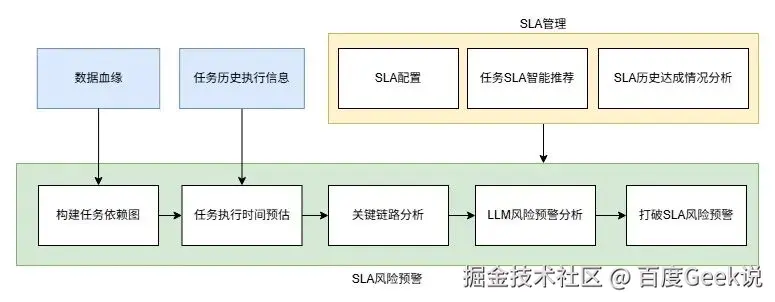
- 基础信息输入层:
数据血缘:记录数据从产生到使用的全链路关系,为后续构建任务依赖图提供关联依据。
任务历史执行信息:存储任务过往执行的开始/结束时间、时长、状态等记录,是任务执行时间预估的核心依据。
- SLA 管理模块(策略与分析层):
SLA 配置:手动设置任务的服务级别协议,定义任务完成时限。
任务 SLA 智能推荐:结合历史执行信息和数据血缘,利用算法自动推荐合理的SLA,减少人工配置的盲目性。
SLA 历史达成情况分析:复盘过往SLA达成情况,为优化配置提供数据支撑。
- 任务流程与风险预警层(核心执行与分析):
构建任务依赖图:依据数据血缘梳理任务上下游关系,形成可视化图谱。
任务执行时间预估:基于历史数据预测任务本次执行所需时间。
关键链路分析:识别对整体SLA影响最大的关键路径,优先保障其资源和监控力度。
LLM 风险预警分析:通过大语言模型分析SLA达成的潜在风险。
打破 SLA 风险预警:综合以上分析结果,一旦识别到风险,立即发出预警,让负责人员提前介入,降低SLA打破的概率。
通过数据质量校验与SLA实时追踪的协同作用,事中监控能够实现对数据任务执行过程的全方位、实时化管控,将异常发现与响应的时间大幅缩短,有效减少异常对业务的影响。
2.1.3 事后治理:基于血缘实现故障快速溯源与修复
尽管事前防控与事中监控已大幅降低异常发生概率,但面对突发故障,事后治理仍至关重要。
其核心目标是快速定位根源、修复问题,并总结经验优化前序环节。
基于数据血缘的故障溯源是事后治理的关键技术手段。
如第三章"基于血缘的智能运维"所言,数据血缘指的是数据从源头到消费端的流转关系:每一个数据表、任务或文件从何而来,被谁消费,形成怎样的依赖链路。
在事后治理场景中,血缘的价值尤为突出:一旦出现数据异常,运维人员可以基于血缘快速定位到上游影响范围和下游受影响对象,避免盲目排查,大幅缩短故障定位与修复的时间。
当上游任务或表修复后,可以利用基于血缘的批量回溯能力,一键触发所有受影响的下游任务,实现自动化修复。
同时,通过分析故障原因并结合血缘,能够反向优化事前防控与事中监控的规则,形成"发现问题 - 定位根源 - 修复问题 - 优化规则"的闭环治理流程。
03 智能化运维
智能化运维旨在利用自动化分析与智能决策技术,提升数据开发平台的运维效率与问题处理速度。
TDS平台在该领域融合了任务日志分析 与基于血缘的智能运维两大能力,旨在构建一个高效、稳定、自愈的数据生产体系。
3.1 任务日志分析
任务日志是诊断问题的核心依据。TDS平台通过智能化的日志分析,帮助用户快速定位并解决问题。架构图如下:
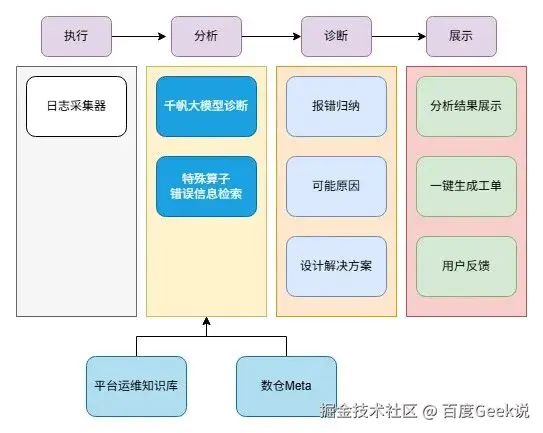
3.1.1 依赖检测算子日志分析
依赖检测类算子用于在任务执行前,判断上游数据是否已按时产出,避免因数据缺失导致的下游计算异常。平台通过结合任务执行日志与数仓元数据,提供清晰直观的依赖检测结果提示:
-
平均产出时间提示:基于历史数据预估任务最早可启动时间,帮助用户合理安排调度。
-
当前产出细节展示:以列表形式展示所有上游依赖的产出信息,包括产出状态(已到位/未到位)和具体时间,支持细化到分区/分表级别。
3.1.2 通用报错智能诊断
对于非依赖检测类的通用错误,平台引入大模型辅助诊断能力,结合内部知识库与外部信息,为用户提供智能化的错误分析与修复建议。
-
执行日志解析:实时采集算子运行日志并结构化处理,将关键错误片段作为诊断输入。
-
知识库 + 千帆大模型服务:
内部知识库:沉淀平台运维团队的常见错误模式、处理经验和最佳实践。
互联网查询:当内部知识库无匹配方案时,系统会通过联网搜索补充诊断依据。
千帆大模型分析:大模型对日志、知识库与检索结果进行综合推理,生成针对性诊断结论。
-
输出结果:提供错误信息归纳、可能原因分析和可行的解决方案,并支持一键生成问题工单。
-
效果与价值:
运维效率提升:自动化的依赖检测和智能诊断减少人工排查时间。
问题定位更精准:日志与血缘关系的结合帮助快速锁定问题。
经验可持续沉淀:错误分析结果自动回流知识库,形成正向闭环。
3.2 基于血缘的智能运维
数据血缘是连接数据链路的核心,它的价值在于让数据流转可见、可控、可回溯。
-
问题溯源与定位:一旦数据异常,可快速定位到上游影响范围和下游受影响对象。
-
变更影响分析:修改某个表字段时,可提前评估下游影响,降低风险。
-
回溯与修复:当发现上游数据有问题时,可以一键触发下游任务的批量回溯。
3.2.1 血缘架构图
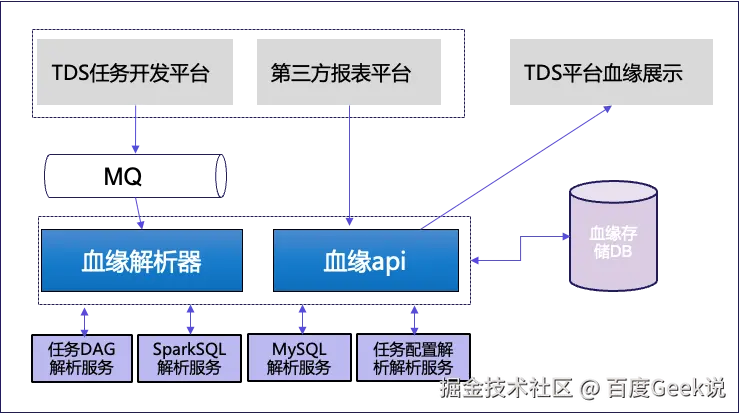
上图展示了TDS血缘治理系统的整体架构,涵盖从信息采集、解析、存储到对外展示的全流程。
- 血缘数据来源:
TDS任务开发平台:自动提取任务依赖信息。
第三方报表平台:采集分析报表与底层表的关系。
任务配置和脚本:作为解析器的输入来源。
-
血缘解析器:将各类任务、SQL和配置转化为结构化的血缘依赖,整合了任务DAG、SparkSQL、MySQL等多个解析服务。
-
全链路血缘数据:设计了分层血缘视图,满足不同用户需求,包括:
任务层血缘:展示任务DAG。
数据表层血缘:支持多种存储引擎。
AFS(文件系统)层血缘:跟踪文件上下游关系。
报表层血缘:第三方报表数据源配置信息。
3.2.2 血缘查看能力
平台提供了快捷易用的血缘查看能力,包括交互式血缘图、节点展开、时间筛选和数据导出。更重要的是,通过实例状态聚合能力,用户可以实时查看上下游任务实例状态,快速定位数据延迟的根因,大幅提升排障效率。
3.2.3 基于血缘的批量回溯能力
在数仓开发中,经常出现上游任务或表修复后,需要让下游数据重新跑一次的场景。例如:
-
上游任务补数据后,需要让下游任务重新消费。
-
某张表发现历史分区错误,需要让下游衍生表重新计算。
手动逐一触发下游任务效率低下且容易遗漏。基于血缘解析能力,我们实现了批量回溯:用户选定一个起始任务节点和时间范围,平台自动遍历血缘图,计算受影响的所有下游节点,并支持批量回溯回溯策略,用户可自行勾选需要回溯的多个任务节点,完成任务的批量回溯。该能力让回溯从"全靠经验"变为"半自动",减少了人为失误和漏回溯风险。
3.2.4 基于血缘的回溯通知
回溯只是第一步,及时通知相关负责人同样关键。平台会:
-
基于血缘关系定位所有受影响节点的下游负责人;
-
自动生成受影响范围清单,并推送给下游任务的 Owner;
-
在通知中附带关键信息:回溯触发原因、影响范围(任务清单)。
这样,数据团队可以在第一时间获知回溯任务情况,及时跟进并降低数据事故影响。
04 总结:价值闭环与未来展望
TDS平台的数据治理实践,从根本上改变了百度MEG的数据生产模式。我们不再是被动地应对数据问题,而是主动地通过技术手段进行预防、监控与治理。
首先,流程标准化将散乱的开发行为转变为有序的"交通规则",显著降低了人为错误的发生率,极大地提升了协作效率。通过环境隔离、配置注入和强制审批,我们将数据生产的风险前置化,让开发者能够专注于业务逻辑本身,而不是纠缠于繁琐的环境配置。
其次,质量可控化为数据资产构建了坚实的"防护衣"。事前约束从源头确保数据质量,事中监控实时捕获异常,事后治理则通过血缘快速溯源,形成了一个持续优化的闭环。这不仅保障了数据的可信度,也为业务决策提供了可靠的依据。
最终,运维智能化是整个体系的升华。通过任务日志的智能诊断与基于血缘的自动化运维,我们实现了对数据生产链路的"自愈"。问题排查不再依赖人工经验,而是由机器自动完成;数据修复不再需要繁琐的手动操作,而是一键批量回溯。这极大地释放了运维团队的生产力,让数据生产体系更加健壮、高效。
展望未来,我们的数据治理之路仍将继续。我们将进一步探索AI技术的深度融合,例如利用机器学习模型预测潜在的数据质量问题,或是基于大模型自动生成更精确的任务修复方案。我们相信,随着技术的不断演进,数据治理将从"可控"走向"自治",最终实现一个真正意义上的"数据自愈工厂",为业务发展提供源源不断、高可信度的数据燃料。