我们先来看一个常见的现象,大家也可以看下当前是否也遇到这类情况。
某大型制造企业在推进数字化转型过程中,面临一个典型的困境:生产系统的实时工单数据存于MySQL,仓储物流使用SAP HANA,客户行为日志流经Kafka,而集团BI分析依赖的却是每月手动导出的Excel报表。多个团队尝试用脚本拼接数据,结果导致数据延迟严重、口径不一,甚至出现财务对账偏差。更棘手的是,当安全审计要求追溯某条销售记录的来源路径时,技术团队无法提供完整的血缘链路。
这一场景背后,是企业数据环境日益复杂的缩影。随着业务系统解耦、微服务架构普及、云原生部署成为主流,企业往往同时运行着数十种数据源:关系型数据库、NoSQL、API接口、日志文件、IoT设备流......这些数据分布在私有云、公有云乃至边缘节点,格式各异、更新频率不一,形成了典型的"多源异构"格局。若缺乏统一的数据集成策略,不仅数据资产难以沉淀,连最基本的报表准确性都难以保障。
一、数据集成的战略意义:不止于技术整合
数据集成早已不是"把数据从A搬到B"的初级阶段,其核心价值在于打通数据资产流动的主动脉。通过统一治理的数据管道,企业能够实现:
打破孤岛:将分散在CRM、ERP、MES等系统中的数据打通,形成360°客户视图或端到端供应链洞察;
支撑高阶应用:为BI分析、机器学习模型训练、实时风控决策提供高质量、低延迟的数据供给;
提升组织敏捷性:新业务上线时,无需重复开发数据对接逻辑,复用已有集成能力即可快速响应。
然而,错误的工具选型可能带来高昂代价。某金融客户曾因选用封闭式ETL工具,在迁移到混合云架构时遭遇严重兼容问题,项目延期8个月,额外投入运维人力超20人月。更普遍的风险包括:许可证成本失控、扩展性不足导致性能瓶颈、缺乏元数据管理引发合规风险等。
二、需求拆解:从业务目标到技术场景的映射
在启动选型前,必须明确"我们到底要解决什么问题"。这需要从三个维度协同思考:
1.视角分层:不同角色关注点不同
管理者关心投资回报率(ROI)、交付周期与合规性;
CIO关注架构兼容性、安全性与长期可维护性;
技术团队则聚焦开发效率、调试体验与故障排查能力。
2.场景分类:按数据流动模式划分
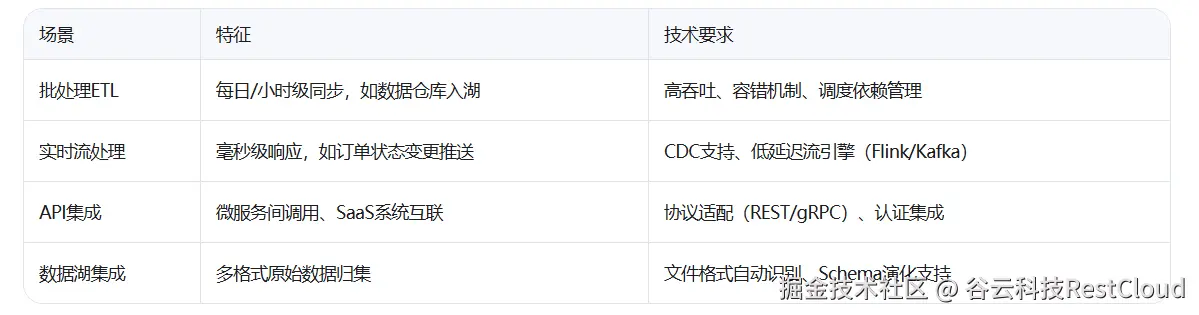
3.关键需求清单(Checklist)
一个完整的评估框架应涵盖:
-
支持的数据源类型(是否覆盖老旧系统如DB2、ODBC?)
-
吞吐量与延迟指标(能否支撑每秒万级事件处理?)
-
元数据自动采集与血缘追踪能力
-
安全合规特性(字段级权限、GDPR脱敏、审计日志)
三、核心能力评估框架:构建系统性判断标准
面对市场上这么多的数据集成工具选项,需建立多维评估模型,避免陷入"功能对比表陷阱"。
1.架构与部署模式
现代集成平台应支持混合部署能力,既能运行在Kubernetes集群中实现弹性伸缩,也能对接本地数据中心。容器化部署已成为标配,能与Kubernetes等现代容器编排技术接轨。
2.连接性与扩展性
连接器的质量远比数量重要。某些平台宣称支持100+连接器,但实际对SAP ECC或Oracle EBS等复杂系统的支持仅限基础读写。理想方案应提供标准化SDK,允许开发者基于JDBC、REST API快速封装私有系统适配器,并具备版本管理能力。
3.数据处理范式支持
传统ETL已难以满足现代需求。领先的平台应同时支持:
ELT模式:将原始数据先加载至目标端(如Snowflake),再利用其计算资源进行转换;
Reverse ETL:将分析结果反向写回业务系统(如将客户分群结果同步至CRM);
可视化+代码混合开发:允许在图形化流程中嵌入Python或Spark脚本,处理复杂逻辑。
4.实时性与性能
真正的实时集成依赖于变更数据捕获(CDC) 技术。基于日志解析的CDC(如Debezium)比轮询方式减少90%以上的数据库负载。同时,平台需内置流处理引擎或无缝对接Flink/Kafka,确保事件流的有序性和 Exactly-Once 语义。
5.数据治理与可观测性
缺乏治理的集成等于制造新的技术债。必须具备:
自动化元数据采集(表结构、字段含义、更新频率)
端到端血缘分析(从源系统到报表字段的追溯)
内建数据质量规则引擎(如空值率阈值告警)
6.安全与合规
身份认证应支持企业级标准(SAML、OAuth2.0、LDAP),并能与云IAM系统集成。敏感字段需支持动态脱敏,且所有操作行为应记录审计日志,便于等保或SOC2审查。
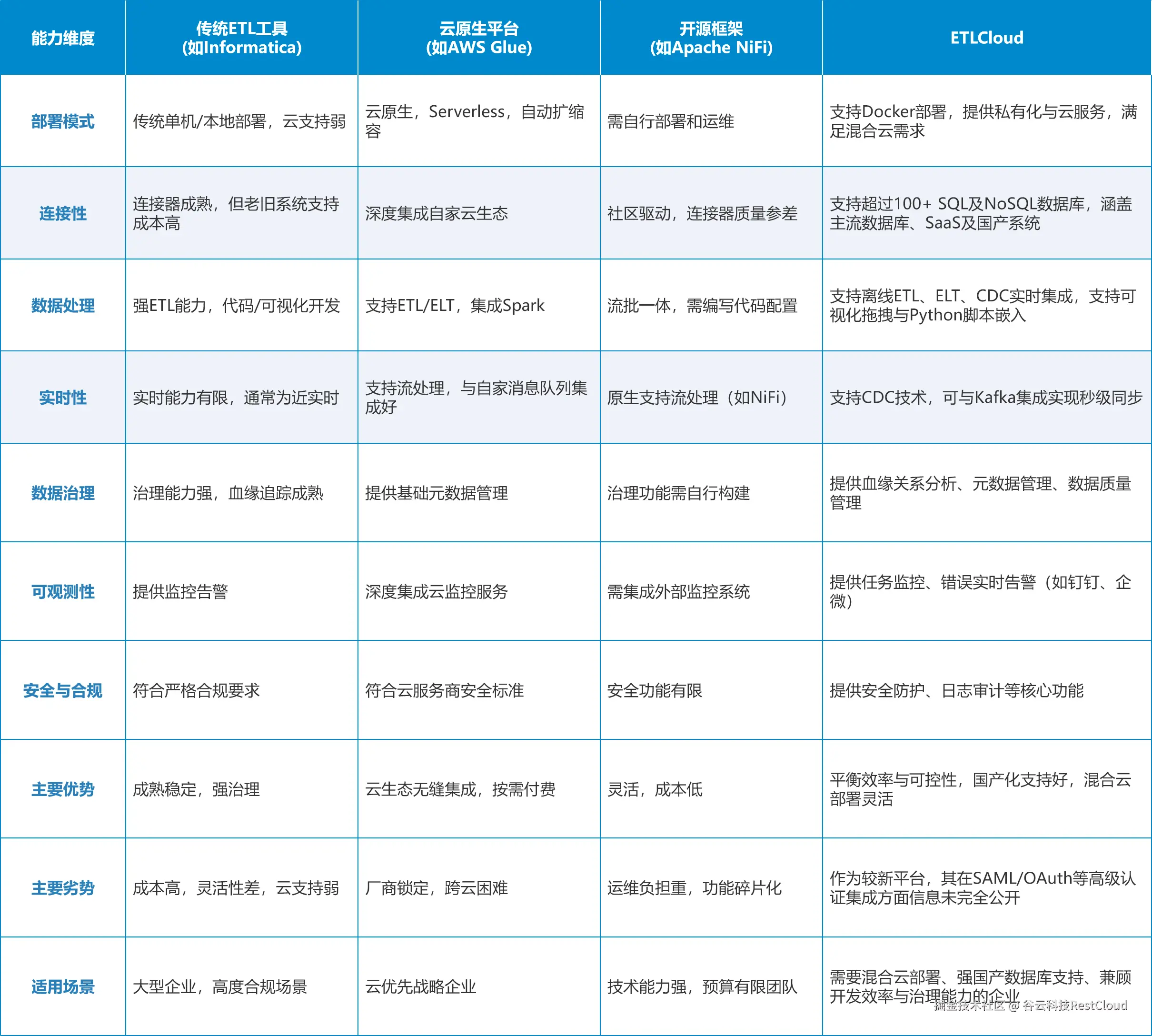
四、主流工具对比与适用场景
1.传统ETL工具(Informatica、DataStage)
优势在于成熟稳定、治理能力强,适合对合规要求极高的金融、医疗行业。但其单机架构难以适应云环境,许可费用高昂,且开发效率偏低。
2.云原生平台(AWS Glue、Azure Data Factory)
深度集成各自云生态,支持Serverless执行与自动扩缩容,适合"云优先"战略企业。但跨云迁移成本高,存在厂商锁定风险。
3.开源框架(Apache NiFi、Airbyte)
灵活性高、成本低,适合技术能力强的团队。但需自行搭建监控、高可用、权限体系,运维负担重,功能碎片化明显。
4.国产免费ETL工具(ETLCloud)
提供全托管云服务的同时,也支持私有化部署,满足混合云需求;
内置超过100个高质量连接器,涵盖主流数据库、SaaS应用;
支持可视化编排+SQL/Python脚本嵌入,兼顾开发效率与处理灵活性;
元数据模块可自动构建数据血缘图谱,显著降低治理成本。
更重要的是,其架构设计预留了对数据网格(Data Mesh) 和 语义层集成 的演进路径,避免未来二次重构。
五、集成是能力,而非工具采购
数据集成的本质,是一场组织级的数据流通基础设施建设。工具只是载体,真正的竞争力来自清晰的架构设计、统一的元数据标准、跨团队的协作机制。
建议企业从"项目思维"转向"平台思维":不再为每个需求单独搭建管道,而是构建可复用、可治理、可观测的集成平台。未来,随着AI在模式识别、异常检测、自动映射中的深入应用,"智能集成"将成为新趋势------而今天的选型决策,将决定企业能否顺利迈入这一阶段。