1. HTTP协议概述
什么是HTTP协议?
HTTP(超文本传输协议,HyperText Transfer Protocol)是用于浏览器与服务器之间传输超文本的协议。 它是万维网(WWW)中最为基础和常用的通信协议之一。HTTP协议通常运行在应用层,它是建立在TCP/IP协议之上的,负责在客户端(通常是浏览器)与服务器之间传输信息。
HTTP协议有多个版本,其中1.0、1.1、2.0等版本均是基于TCP协议实现的,而HTTP/3则是基于UDP协议实现的。当前,HTTP1.0和HTTP/3广泛应用。
协议 ,是指在网络通信中,参与方必须遵循的一套规则,以确保信息的正确传输。可以将它比作两人传递信件时所使用的暗号和规矩。
HTTPS 则是HTTP协议的安全版本,增加了加密机制以保证通信的安全性。
HTTP协议的工作原理
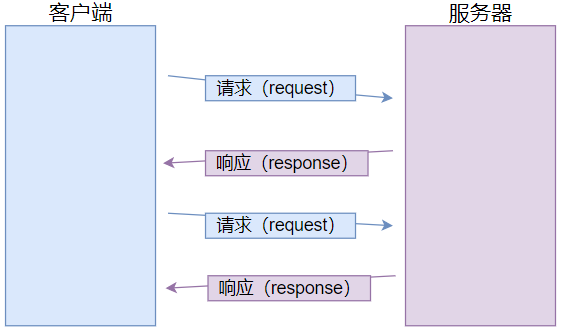
当用户在浏览器中输入网址时,浏览器会发出一个HTTP请求,服务器接收到请求后进行处理,然后返回一个HTTP响应。用户访问网站时,往往会涉及多次请求和响应的交互。
基本术语:
-
客户端:发起请求的设备(例如用户的浏览器)。
-
服务器:接收请求并返回响应的设备。
-
请求:客户端发往服务器的数据。
-
响应:服务器返回给客户端的数据。
HTTP协议的特点可以总结为"一问一答,一发一收",即客户端向服务器发送请求,服务器返回响应。
网络通信中的其他模式
除了基本的"一问一答"模式外,网络通信中还可能出现:
-
多发一收:例如上传大文件时,客户端多次发送数据,服务器一次接收。
-
一发多收:例如观看直播时,客户端发起请求后,服务器返回多个视频源。
-
多发多收:如流媒体传输(例如Steam Link)中,双方不断交互数据。
2. 使用Fiddler抓包工具分析HTTP请求
什么是抓包工具?
当浏览器与服务器交互时,往往会发送和接收多次HTTP请求。为了更清楚地了解这些请求和响应,我们可以使用抓包工具来观察它们的交换过程。HTTP协议是纯文本协议,抓包工具能够帮助我们捕捉并查看这些请求和响应的详细数据。
使用Fiddler工具
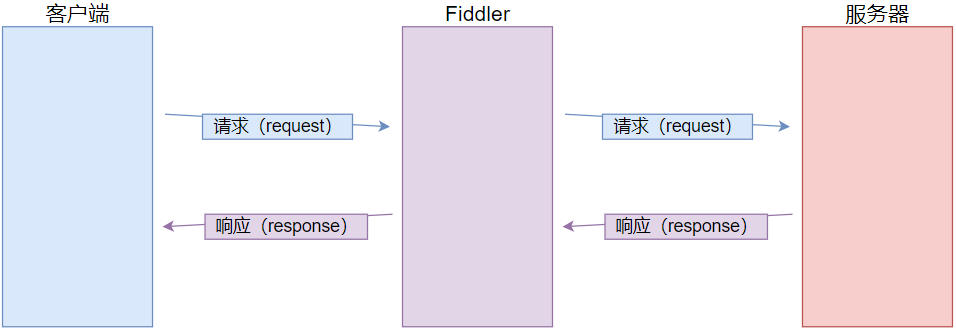
Fiddler是一款强大的抓包工具,它能够通过代理的方式捕捉到您计算机网络上的所有HTTP和HTTPS请求。通过Fiddler,您可以查看每一次HTTP请求和响应的详细内容,进行数据分析。
Fiddler的基本使用
-
打开Fiddler后,访问您想要抓取请求的网页。
-
Fiddler会显示该网站的所有HTTP请求和响应。
-
点击每一条请求记录,右侧显示该请求的详细数据。响应数据也会在右侧显示。
需要注意的是,直接安装的Fiddler无法捕捉HTTPS请求,您需要做一些配置才能让它支持HTTPS流量的抓取。
抓包的基本原理
Fiddler充当代理服务器的角色。当客户端(浏览器)发出请求时,它首先向Fiddler发送请求,Fiddler再将该请求转发到目标服务器。服务器响应后,Fiddler再次接收并转发该响应给浏览器。
3. HTTP请求和响应格式
HTTP请求格式
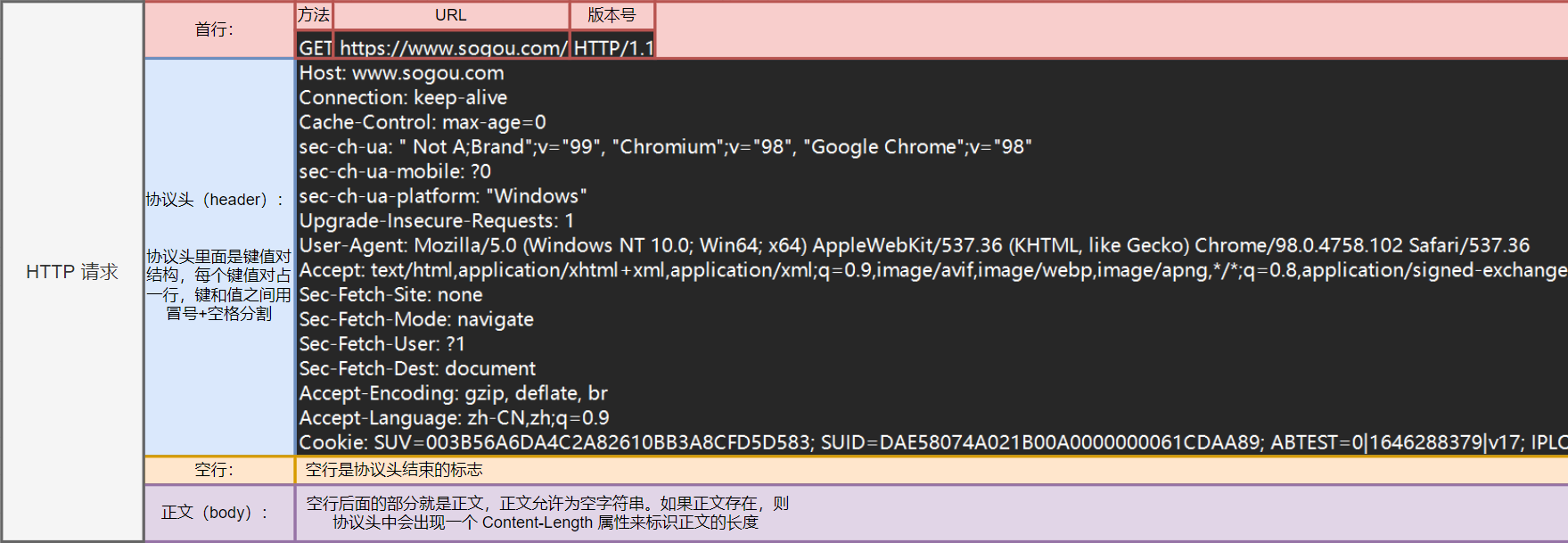
每一次HTTP请求都包含几个重要部分:
-
请求行:包括请求方法(如GET、POST)和目标URL。
-
请求头:包含有关请求的附加信息,如浏览器信息、支持的语言等。
-
请求体:通常用于POST请求,用于传递用户提交的数据。
HTTP响应格式
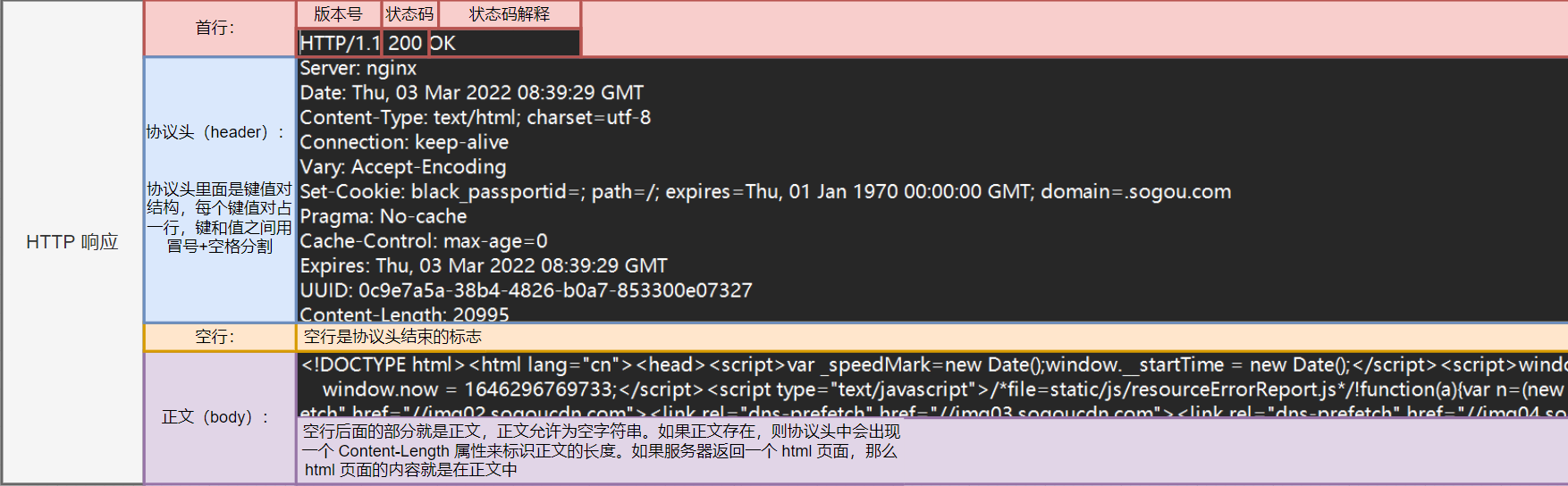
HTTP响应包含:
-
响应状态行:包括响应状态码(如200表示成功)。
-
响应头:包含关于响应的附加信息。
-
响应体:服务器返回给客户端的实际内容,如HTML页面、图片等。
为什么HTTP协议中需要空行?
空行是HTTP协议中的分隔符,用于区分头部信息和正文内容。如果没有空行,可能会发生"粘包"现象,导致数据混乱。
4. URL统一资源定位符
URL基础
URL(统一资源定位符),通常被称为"网址",它指定了互联网上资源的位置。URL不仅仅包括资源的路径,还包括如何访问该资源的信息。每个URL由以下几个部分组成:
协议类型://[用户名:密码@]服务器地址[:端口号][/路径]文件名[?查询字符串][#片段标识符]
组成部分:
-
协议类型 :常见的有HTTP和HTTPS(安全版HTTP),它们指示了访问资源时使用的协议。
-
服务器地址 :资源所在服务器的IP地址或域名。域名需要通过DNS解析成IP地址,才能确保能够正确连接到目标服务器。
-
端口号 :指示服务器上的特定端口。HTTP通常使用80端口,HTTPS使用443端口。如果没有指定端口号,浏览器会根据协议类型自动选择默认端口。
-
路径 :指定资源在服务器上的具体位置。
-
查询字符串 :通常以
?开始,后面跟着参数,用&连接多个键值对,用于向服务器传递额外的数据。(键值对其实也是传递的参数) -
片段标识符 :以
#开始,通常用来表示页面内部的某一部分(例如跳转到页面的某个章节)。
例如:
https://www.sogou.com/web?query=%E8%9B%8B%E7%B3%95&_asf=www.sogou.com 在上面的例子中:
协议类型:HTTPS
服务器地址 :
www.sogou.com路径 :
/web查询字符串 :
query=蛋糕
DNS域名解析
在访问一个URL时,服务器地址通常是域名(例如www.sogou.com),而非直接的IP地址 。计算机和其他网络设备理解的是IP地址,域名是为方便人类记忆而创建的。所以,在访问一个域名时,首先需要通过DNS(域名系统)将域名解析成对应的IP地址。
DNS解析过程:
当用户输入一个URL(例如
https://www.sogou.com)时,浏览器首先会向本地DNS缓存查找该域名是否已经解析过。如果缓存中没有对应的IP地址,浏览器会向DNS服务器发起请求。DNS服务器会通过一系列查询,找到域名对应的IP地址。
DNS服务器返回IP地址后,浏览器使用该IP地址连接到目标服务器,发起HTTP请求。
这种域名解析的过程通常是透明的,用户并不需要直接干预,系统会自动完成这些步骤。
示例:如何查找域名的IP地址
可以通过ping命令来查看某个域名的IP地址:
cpp
ping www.sogou.com执行结果可能会显示出类似以下的IP地址:
cpp
PING www.sogou.com (121.229.91.101) 56(84) bytes of data.此时,浏览器就会使用39.156.69.79这个IP地址来访问Sogou的服务器。
URLencode 介绍
当我们通过浏览器进行搜索时,URL中可能会包含一些特殊字符,这些字符在URL中有特殊的含义,如/、?、=等,不能直接出现在查询参数中。因此,为了确保这些字符能够安全地传输,我们需要对它们进行URL编码(URL Encoding)。
例如,当我们在搜狗搜索"蛋糕"时,抓包工具捕获到的URL可能如下所示:
cpp
GET https://www.sogou.com/web?query=%E8%9B%8B%E7%B3%95&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=1129&sst0=1646360982664&lkt=0%2C0%2C0&sugsuv=003B56A6DA4C2A82610BB3A8CFD5D583&sugtime=1646360982664 HTTP/1.1在上面的URL中,我们可以看到**query=%E8%9B%8B%E7%B3%95这** 一部分。%E8%9B%8B%E7%B3%95是URL编码后的"蛋糕"一词。 通过**urldecode解码,%E8%9B%8B%E7%B3%95就能还原为"蛋糕"。**
为什么需要URLencode?
URL编码是为了避免URL中出现与URL结构冲突的特殊字符。例如,/、?、=、&等字符已经在URL中有特殊用途,因此如果查询字符串中包含这些字符,就必须对它们进行转义,以确保它们能够正确传递。
编码规则
URL编码的规则很简单:任何不能直接出现在URL中的字符都会被转换为以%符号开头的十六进制表示。例如:
空格(
)会被编码为%20
&(用于分隔查询参数)会被编码为%26
?(用于开始查询字符串)会被编码为%3F中文字符
蛋糕的编码就是%E8%9B%8B%E7%B3%95
URL编码的步骤
URL编码的核心步骤如下:
将需要转码的字符转换为其对应的UTF-8编码(对于非ASCII字符如中文)。
将UTF-8编码的字节转换为对应的十六进制值。
每个十六进制字符前加上
%,形成%XY的格式。
示例:
假设我们有一个带有中文的字符串"蛋糕",我们想将其作为URL的一部分。通过URL编码,中文字符会被转换成UTF-8编码,然后转化为相应的百分号编码。
-
中文字符 "蛋糕"对应的UTF-8编码是
E8 9B 8B E7 B3 95。 -
URL编码 后的结果是
%E8%9B%8B%E7%B3%95。
因此,搜索"蛋糕"的URL会变成:
cpp
https://www.sogou.com/web?query=%E8%9B%8B%E7%B3%95现在,网上有很多在线工具可以方便地进行URL编码和解码。开发者可以利用这些工具轻松完成URL转码操作,避免手动处理复杂的编码转换。
5.认识 HTTP 请求方法(Method)
HTTP 请求方法是指在 HTTP 请求报文中**,首行的第一个部分,表示客户端对资源的操作请求**。最初,HTTP 的设计者希望通过不同的请求方法来表达不同的语义,但实际使用中,这些方法的作用并未完全按照设计实现。下面介绍 HTTP 中几种常见的请求方法。
常见的 HTTP 请求方法
| 方法 | 说明 | 适用版本号 |
|---|---|---|
| GET | 获取资源 | HTTP/1.0, HTTP/1.1 |
| POST | 传输实体主体 | HTTP/1.0, HTTP/1.1 |
| PUT | 传输文件 | HTTP/1.0, HTTP/1.1 |
| HEAD | 获得报文首部 | HTTP/1.0, HTTP/1.1 |
| DELETE | 删除资源 | HTTP/1.0, HTTP/1.1 |
| OPTIONS | 查询支持的方法 | HTTP/1.1 |
| TRACE | 追踪请求路径 | HTTP/1.1 |
| CONNECT | 建立隧道协议连接代理 | HTTP/1.1 |
| LINK | 资源建立联系 | HTTP/1.1 |
| UNLINE | 断开连接关系 | HTTP/1.1 |
1. GET 方法
基本介绍:
GET 是 HTTP 中最常用的方法,主要用于从服务器获取某个资源。以下几种常见的场景都会触发 GET 请求:
-
在浏览器中输入 URL 地址并回车,浏览器会发送一个 GET 请求。
-
HTML 中的
<link>,<img>,<script>标签的src或href属性中的 URL,也会触发 GET 请求。 -
使用 JavaScript 的
ajax技术,也可以构造 GET 请求。 -
任何支持网络请求的编程语言(如 Python、Java 等)都可以使用 GET 方法。
特点:
-
请求行中的第一部分为
GET。 -
URL 中的查询字符串(query string)可以为空或包含参数。
-
GET 请求的 header 一般包含若干个键值对。
-
GET 请求的 body 一般为空。
GET 请求示例:
例如,访问搜狗首页时,浏览器会发送一个 GET 请求,URL 格式如下:
cpp
GET https://www.sogou.com/web?query=蛋糕 HTTP/1.12. POST 方法
基本介绍:
POST 方法常用于向服务器提交数据,例如表单提交或文件上传。POST 请求通常用于传输大量数据,尤其是用户输入的内容,比如登录页面的表单数据。
特点:
-
请求行中的第一部分为
POST。 -
URL 中的查询字符串通常为空。
-
POST 请求的 header 包含多个键值对。
-
POST 请求的 body 一般不为空,包含需要传输的数据。请求体的数据格式由
Content-Type定义,数据长度由Content-Length指定。
POST 请求示例:
例如,提交登录表单时,浏览器通过 POST 方法提交表单数据:
cpp
POST https://www.qq.com/login HTTP/1.1 Content-Type: application/x-www-form-urlencoded Content-Length: 29 username=user&password=1234563. GET 和 POST 的区别
GET 和 POST 是最常用的 HTTP 请求方法,尽管两者没有本质区别,但在使用场景上存在一些显著的差异。以下是两者的主要区别:
-
数据传输方式:
-
GET :数据通过 URL 的查询字符串传输(即 ?key=value 形式),适用于获取数据。
-
POST :数据通过请求体(body)传输,适用于提交数据。
-
-
幂等性:
-
GET 是幂等的,即同样的请求执行多次,其结果不会改变,也不会对服务器产生副作用。
-
POST 不是幂等的,同样的请求执行多次可能会导致不同的结果。
-
-
缓存性:
-
GET 请求可以被缓存,可以被浏览器保存到书签中。
-
POST 请求通常不会被缓存,也不能被保存为书签。
-
-
数据大小:
-
GET 请求有长度限制(由于 URL 长度限制),一般不适合传输大量数据。
-
POST 请求没有数据长度限制,适合上传较大数据。
-
幂等性说明:
"幂等"是指多次执行同样的操作,结果不会改变。例如:
-
GET 方法是幂等的,因为获取资源不会改变服务器的状态。
-
POST 方法通常不是幂等的,因为它可能改变服务器状态(例如,提交表单后改变数据库内容)。
4.关于 GET 请求的常见误解
URL 长度限制
有一种误解认为 GET 请求的 URL 有长度限制。实际上,HTTP 协议本身并没有对 URL 的长度作出限制,URL 长度的上限取决于浏览器和服务器的实现。例如,IE浏览器的URL最大长度为2048个字符,而其他浏览器通常支持更长的URL。
关于安全性
常见的误解认为 POST 比 GET 更安全 。实际上,GET 和 POST 都可能存在安全隐患,具体取决于是否采用加密机制。无论是通过 URL 传递的数据(GET)还是请求体中的数据(POST),都可以被抓包工具截取,因此,是否加密(如使用 HTTPS)才是决定请求安全性的关键。
关于数据类型
有误解认为 GET 只能传输文本数据,而 POST 可以传输文本和二进制数据 。实际上,GET 请求也可以传输二进制数据,只不过需要对二进制数据进行 URL 编码(urlencode)。例如,将文件转换为 Base64 格式后,可以通过 GET 请求传递二进制数据。
5. 其他 HTTP 方法
-
PUT:与 POST 类似,但具有幂等性,通常用于更新资源。
-
DELETE:用于删除指定的资源。
-
OPTIONS:查询服务器支持的请求方法。
-
HEAD:与 GET 类似,但响应体不返回,只返回响应头。
-
TRACE:用于诊断和调试,显示服务器端接收到的请求。
-
CONNECT:用于创建隧道连接,通常用于 HTTPS 代理。
-
LINK:表示资源之间的关系建立。
-
UNLINE:用于断开资源之间的联系。
6.认识 HTTP 请求报头(Header)
HTTP 请求报头(Header)是 HTTP 请求报文的重要部分,包含了很多关于请求的附加信息。这些信息以键值对的形式组织,每个键值对占据一行,并且键和值之间通过冒号加空格(: )进行分隔。接下来,我们将介绍一些常见的 HTTP 请求报头。
常见的 HTTP 请求报头
-
Host
-
作用:表示服务器的主机地址和端口号。
-
格式:
Host: [服务器地址][:端口号] -
说明:该字段用于指定请求的目标主机。地址可以是域名,也可以是 IP 地址;端口号通常是可选的,若省略则默认使用 80 端口(HTTP)或 443 端口(HTTPS)。
-
-
Content-Length
-
作用:表示请求体(body)的长度,单位为字节。
-
格式:
Content-Length: [字节数] -
说明:当请求包含数据(如 POST 请求)时,这个字段告诉服务器请求体的长度。这个值的单位是字节。
-
-
Content-Type
-
作用:表示请求体的数据格式。
-
格式 :
Content-Type: [数据格式] -
说明:该字段定义了请求体中的数据格式,常见的类型有以下几种:
-
application/x-www-form-urlencoded:这是表单提交的默认格式,键值对以&分隔,键和值之间使用=。 -
multipart/form-data:用于上传文件的表单格式,数据被分成多个部分,通常用在提交文件时。 -
application/json:表示请求体是 JSON 格式的数据,通常用于 API 请求。cppContent-Type: application/json
-
-
-
User-Agent (UA)
cpp
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36-
作用:表示客户端的浏览器和操作系统信息。
-
格式 :
User-Agent: [浏览器和操作系统信息] -
说明:这个字段帮助服务器了解请求来自的浏览器和操作系统的具体信息,网站可以根据 User-Agent 来提供兼容性调整。
其他常见请求报头
-
Referer
-
作用:表示当前页面是从哪个页面跳转过来的。
-
格式 :
Referer: [跳转页面的URL] -
说明:这个字段通常用于广告点击追踪等用途,例如广告主希望知道用户是从哪个页面点击过来的。
cppReferer: https://www.bing.com/search?q=%E8%9B%8B%E7%B3%95注意 :如果用户是直接输入 URL 或从书签访问页面时,
Referer字段是不会包含的。 -
-
Cookie
-
作用:用于存储和传递客户端数据的机制。
-
格式 :
Cookie: [键=值; 键=值; ...] -
说明:Cookie 是浏览器存储在客户端的数据,通常用于保存用户登录状态、偏好设置等信息。每次向同一域名发出的请求都会自动携带该域的所有 Cookie
cppCookie: session_id=abc123; user_id=xyz456
Cookie 的来源:
-
Cookie 可以由客户端通过 JavaScript 设置。
-
服务器可以通过 HTTP 响应中的
Set-Cookie字段设置 Cookie,然后客户端会保存它,并在随后的请求中携带该 Cookie。
Cookie 的作用:
-
用于保持用户的登录状态:如登录后服务器设置了
session_id,后续请求会携带该 Cookie,从而保持登录状态。 -
用于跟踪用户行为:广告公司使用 Cookie 来跟踪用户的浏览行为。
-
Cookie 的缺陷:
-
-
存储容量限制:每个浏览器对单个域名下的 Cookie 存储有一定的大小限制,通常为 4 KB 左右。
-
安全隐患 :Cookie 中存储的敏感数据如果未加密,可能会被盗用。
Cookie 工作流程
-
存储 Cookie:
-
客户端通过 JavaScript 可以设置 Cookie,例如:
cppdocument.cookie = "username=JohnDoe; expires=Fri, 31 Dec 2025 23:59:59 GMT"; -
服务器也可以通过响应头中的
Set-Cookie字段来告诉浏览器保存 Cookie:cppSet-Cookie: session_id=abc123; Path=/; HttpOnly
-
-
发送 Cookie:
-
当浏览器访问同一域名的页面时,浏览器会将该域名下存储的所有 Cookie 一并发送到服务器:
cppCookie: session_id=abc123; username=JohnDoe
-
7. HTTP 响应(Response)
7.1 理解"状态码"(Status Code)
状态码用于表示访问网页时的响应结果,例如访问成功、失败或其他情况等。它是一个三位数字,按照不同的含义分为五个主要类别:1xx、2xx、3xx、4xx 和 5xx。每个类别的状态码都具有不同的含义。以下是一些常见状态码的介绍及其解释:
-
200 OK
表示请求成功,服务器已返回所请求的页面内容。
-
404 Not Found
表示请求的资源在服务器上未找到。如果用户请求的 URL 无法在服务器上找到对应资源,则会返回此状态码。
-
403 Forbidden
表示访问被拒绝。某些页面可能需要特定的权限(如用户必须登录才能访问),若未满足权限条件,则会返回此状态码。
-
405 Method Not Allowed
表示服务器不支持请求的 HTTP 方法或该方法在当前情况下不可用。
-
500 Internal Server Error
表示服务器内部出现错误。通常是由于服务器在处理请求时发生异常,可能导致服务器崩溃。
-
504 Gateway Timeout
表示服务器未能及时响应,通常是因为服务器负载过重或处理请求时间过长,导致请求超时。
-
302 Found (临时重定向)
表示资源临时移到其他位置,浏览器会根据新的地址跳转到新的 URL。这个状态码通常用于页面临时改变位置。
-
301 Moved Permanently (永久重定向)
表示资源已经永久迁移到新位置,浏览器将自动将后续请求重定向到新地址。
7.2 理解响应"报头"(Header)
响应报头的格式与请求报头类似,以下介绍几种常见的响应报头参数:
-
Content-Type
Content-Type指定了响应体的数据格式。以下是几种常见的数据格式类型:-
text/html:表示响应数据为 HTML 格式。
-
text/css:表示响应数据为 CSS 格式。
-
application/javascript:表示响应数据为 JavaScript 格式。
-
application/json:表示响应数据为 JSON 格式。
7.3 理解
Connection: keep-aliveConnection: keep-alive是一个常见的响应报头,用于在 HTTP 长连接中保持连接活跃。它通常与HTTP/1.1一起使用,告诉客户端连接在多个请求和响应之间保持开启,直到明确关闭连接。 -
连接保持活跃:客户端和服务器之间的连接保持打开状态,以便可以复用同一个连接进行多个请求/响应的交换,而不需要每次都建立新的连接。
-
减少连接开销:避免了频繁的连接建立和断开,减少了网络延迟和服务器资源消耗。
-
例子:
如果服务器希望客户端保持连接并且允许多个请求共享同一连接,响应报头中会包含
Connection: keep-alive。例如:cppHTTP/1.1 200 OK Content-Type: text/html Connection: keep-alive Keep-Alive: timeout=5, max=100 -
Connection: keep-alive表示连接将在多个请求/响应之间保持活跃。 -
Keep-Alive: timeout=5, max=100进一步指示:-
timeout=5:连接保持活跃的最大时间为 5 秒。 -
max=100:在连接关闭之前,最多可以处理 100 个请求。
-
-
当客户端通过代理访问 HTTPS 网站时,代理服务器可能会使用
CONNECT方法建立隧道连接。如果需要保持此连接活跃,代理服务器的响应也可能包含Connection: keep-alive,指示该隧道连接在多个请求中保持有效。
cppHTTP/1.1 200 Connection Established Connection: keep-alive -