菜鸟与老鸟的对话:轻松搞懂前端大文件上传的核心原理与实现
菜鸟小陈正盯着一个上传进度条卡在50%已经十分钟了,忍不住向旁边的高级工程师老王求助。

小陈:王哥,我这有个2GB的大文件上传,传了一半总是失败,用户得重新传,这体验太差了!
老王 :(推了推眼镜)小陈啊,你这是遇到大文件上传的经典问题了。知道分片上传和断点续传吗?
小陈:听说过,但不清楚具体怎么实现。是把文件切成小块吗?
老王:没错!就像搬家时大家具要拆开运输一样。前端把大文件切成小块,逐一上传。
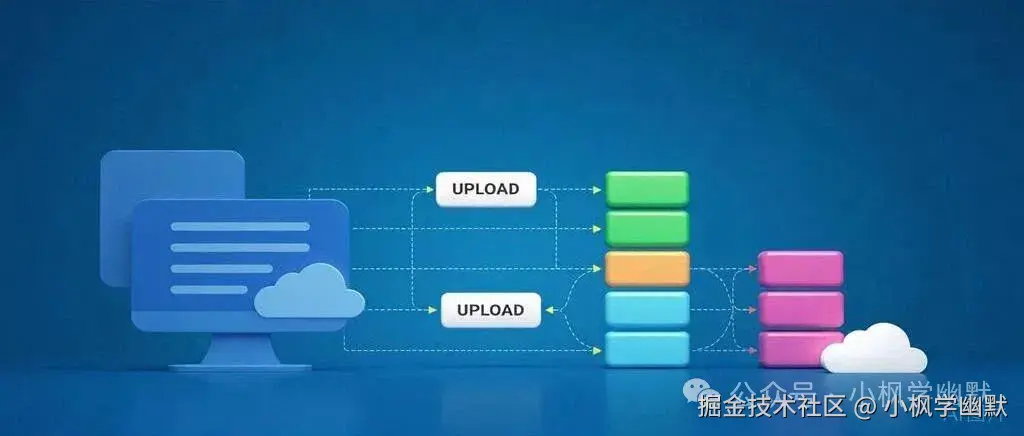
一个大的文件被分割成多个小块的视觉示意图,展示分片上传的概念
小陈:那具体怎么切呢?用JavaScript操作文件?
老王 :对!HTML5的File API提供了File和Blob对象,我们可以用Blob.prototype.slice方法来切割文件。
js
// 比如把文件切成1MB的小块
const chunkSize = 1024 * 1024; // 1MB
const totalChunks = Math.ceil(file.size / chunkSize);
let chunkIndex = 0;
// 切割文件
function createChunk(file, index) {
return new Blob([file.slice(index * chunkSize, (index + 1) * chunkSize)]);
}小陈:哦!那切完之后呢?直接一个个上传吗?
老王:基本上是这样,但要注意几个关键点:
- 每个分片需要有一个唯一标识,方便服务端重组
- 需要控制并发数,避免同时上传太多分片
- 要实现进度追踪和暂停/继续功能
小陈:并发数控制?为什么需要这个?
老王:好问题!如果同时上传所有分片,可能会触发浏览器的HTTP请求并发限制(通常是6个),还会导致网络拥堵和内存占用过高。
小陈:那怎么控制并发呢?
老王:我们可以使用一个队列系统,限制同时进行的上传任务数量。这里是一个简单实现:
js
class ConcurrentUploader {
constructor(maxConcurrent = 3) {
this.maxConcurrent = maxConcurrent; // 最大并发数
this.queue = []; // 任务队列
this.activeCount = 0; // 当前活跃任务数
}
// 添加任务到队列
addTask(task) {
this.queue.push(task);
this.run();
}
// 执行任务
async run() {
// 如果队列为空或已达到最大并发数,则返回
if (this.activeCount >= this.maxConcurrent || this.queue.length === 0) {
return;
}
this.activeCount++;
const task = this.queue.shift();
try {
await task();
} catch (error) {
console.error('Upload error:', error);
} finally {
this.activeCount--;
this.run(); // 继续执行下一个任务
}
}
// 清空队列
clear() {
this.queue = [];
}
}
// 使用示例
const uploader = new ConcurrentUploader(3); // 最大并发数为3
for (let i = 0; i < totalChunks; i++) {
const chunk = createChunk(file, i);
uploader.addTask(() => uploadChunk(fileId, chunk, i, totalChunks));
}小陈:这个并发控制很清晰!那暂停和继续呢?这就是断点续传吧?
老王:聪明!断点续传的核心是记录上传状态。简单实现可以用LocalStorage:
js
// 记录上传进度
function saveProgress(fileId, uploadedChunks) {
localStorage.setItem(`upload_${fileId}`, JSON.stringify(uploadedChunks));
}
// 获取上传进度
function getProgress(fileId) {
const data = localStorage.getItem(`upload_${fileId}`);
return data ? JSON.parse(data) : [];
}
``
**小陈**:那服务端怎么知道这些分片属于同一个文件呢?
**老王**:问得好!前端需要为每个文件生成唯一ID,并在上传每个分片时带上这个ID和分片序号:`` // 生成唯一文件ID
function generateFileId(file) {
return `${file.name}-${file.size}-${file.lastModified}-${Math.random().toString(16).slice(2)}`;
}
// 上传分片
async function uploadChunk(fileId, chunk, index, totalChunks) {
const formData = new FormData();
formData.append('file', chunk);
formData.append('fileId', fileId);
formData.append('chunkIndex', index);
formData.append('totalChunks', totalChunks);
const response = await fetch('/upload-chunk', {
method: 'POST',
body: formData
});
if (!response.ok) {
throw new Error(`Upload failed for chunk ${index}`);
}
return response.json();
}小陈:如果上传中途网络断了怎么办?
老王:这就是为什么要记录上传状态。重新连接后,先向服务端查询已上传的分片,然后只上传缺失的部分:
js
async function resumeUpload(fileId, file, totalChunks) {
// 查询服务端已上传的分片
const uploaded = await checkUploadedChunks(fileId);
const uploader = new ConcurrentUploader(3);
for (let i = 0; i < totalChunks; i++) {
if (!uploaded.includes(i)) {
const chunk = createChunk(file, i);
uploader.addTask(async () => {
await uploadChunk(fileId, chunk, i, totalChunks);
// 更新本地进度
const currentProgress = getProgress(fileId);
saveProgress(fileId, [...currentProgress, i]);
});
}
}
// 等待所有分片上传完成
await uploader.waitForCompletion();
// 所有分片上传完成后,通知服务端合并
await mergeChunks(fileId, file.name);
}小陈:原来如此!那服务端合并分片时,怎么保证顺序正确呢?
老王:服务端应该按照分片序号进行合并。前端所有分片上传完成后,需要发送一个合并请求:
js
async function mergeChunks(fileId, fileName) {
const response = await fetch('/merge-chunks', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
fileId,
fileName,
// 还可以传递其他元数据,如文件类型等
})
});
if (!response.ok) {
throw new Error('Merge failed');
}
return response.json();
}小陈:这个方案真不错!但有没有现成的库可以用呢?
老王 :当然有!比如tus-js-client、resumable.js等,它们已经实现了这些逻辑。但在理解原理的基础上使用库会更得心应手。
小陈:还有一个问题,如果用户换了浏览器或者清除了本地数据,断点续传不就失效了吗?
老王:很好的观察!这种情况下,我们可以通过"秒传"和"哈希校验"来优化体验。前端计算文件哈希值作为唯一标识:
js
// 计算文件哈希(使用Web Crypto API)
async function calculateFileHash(file) {
const arrayBuffer = await file.arrayBuffer();
const hashBuffer = await crypto.subtle.digest('SHA-256', arrayBuffer);
const hashArray = Array.from(new Uint8Array(hashBuffer));
return hashArray.map(b => b.toString(16).padStart(2, '0')).join('');
}这样即使换了浏览器,只要文件相同,哈希值就相同,服务端识别后可以实现"秒传"(所谓秒传,其实就是后端服务器发现这个文件已经上传过了,直接返回已上传成功)。
小陈:太感谢了王哥!我这就去重构上传逻辑。
老王:等等,还有几点要注意:
- 分片大小要合理,太小会增加请求次数,太大会失去分片的意义
- 考虑上传失败的重试机制
- 提供清晰的上传进度反馈
- 注意内存管理,尤其上传超大文件时
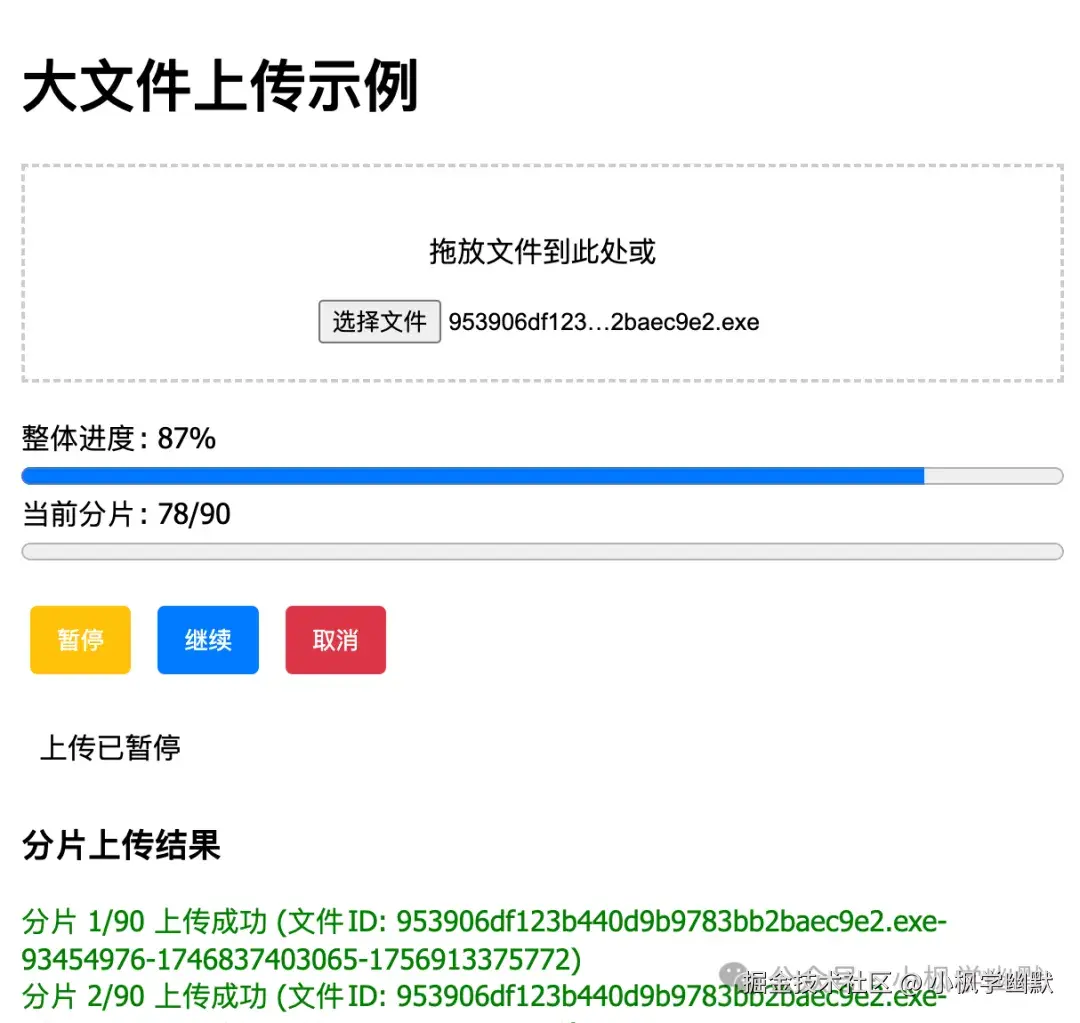
完整代码见:
总结
大文件分片上传和断点续传是现代Web应用的重要特性,通过:
- 前端文件分片
- 并发控制(避免HTTP请求限制)
- 上传状态持久化
- 服务端分片重组
- 哈希校验等优化手段
可以显著提升大文件上传的体验和成功率。理解了这些原理,你就能更好地选择和实现适合自己项目的上传方案了。
欢迎关注我的个人公众号「「小枫学幽默」」一起成长,一起分享生活!!