1. 关系型数据库主要考点
关系型数据库:
- 架构
- 索引
- 锁
- 语法
- 理论规范
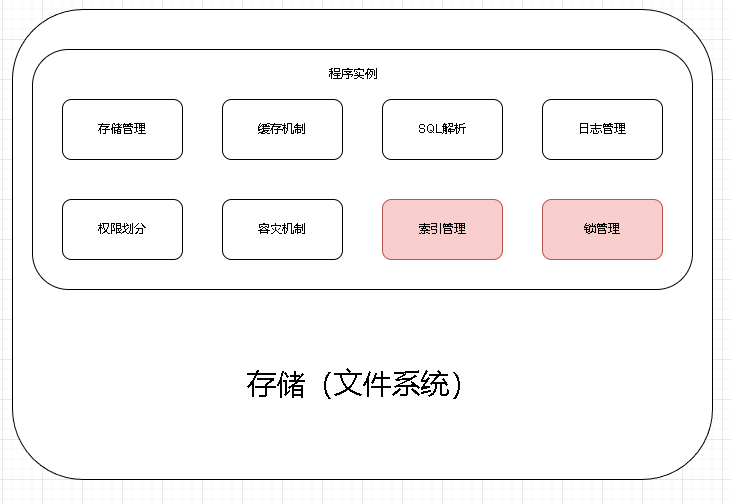
2. 如何设计一个关系型数据库
设计即模块划分。
数据库最主要的功能是存储我们的数据,所以需要一个存储的文件系统。
我们要把涉及到的物流数据提供逻辑的形式给组织和表示出来,这是我们就用到了程序的存储管理模块。
为了更快更好的提升我们程序的效率,我们普遍的做法是引入缓存机制,把取出来的数据放入缓存当中,这样我们就可以减少从数据库读取IO消耗,加快效率。
我们还需要给外界提供可以读取我们数据库指令和可读的SQL语句,这样我们就需要一个SQL解析器。
这时候为了进一步去提升SQL执行效率,我们将SQL缓存到缓存里面,将编译好的SQL放入缓存中。
此外我们还需要注意设计的缓存不宜过大,算法里面还需要有淘汰机制,淘汰了一些不常用的数据。执行的SQL操作也需要记录下来,方便我们做数据库的主从同步或灾难恢复。还需要给用户数据管理的私密空间和权限划分。还需要考虑异常的发生处理,因此引入了容灾机制。当我们数据库挂了,这时候应该怎么办?要恢复到什么程度?这些都需要设计。而且为了进一步提升查询效率,以及让数据库支持并发,我们还需要引入最能突出数据库特性的锁和索引这两个模块。
注意:
如何优化存储效能,我们都知道处理数据肯定不可以在磁盘中去执行,而是让程序其加载到程序空间的内存去做。此外,为了执行效率,我们需要尽可能减少IO,如果频繁的去数据库逐行查找并放回,那么频繁的IO会让数据库执行效率低下,同时一次IO读取一行或多行数据所花费的时间没有区别。所以为了提升效率,一次去读取多行,这样来看行就失去了它的意义,所以数据库中把块或页作为存储数据的单元格。
3. 为什么需要使用索引?
首先我们需要做一个调研,用最简单的方法进行对数据库的查询,即对数据库进行全表扫描,对整个数据库表全部或分批次的进行扫描并加载到内存中,逐个去加载,轮询直到找到我们的目标,这种方法普遍被认为十分慢,但是是在所有情况下都这么慢吗?
存在即是合理,当我们的数据库里面的数据只有很少比如几十行作用,使用全表扫描肯定比通过索引来的快。
对于绝大多数情况来说,我们都需要避免全表扫描,提升我们的效率,这时候索引就诞生了。索引就类型于字典,通过索引来大幅度提升查询效率。
那什么是索引呢?通过上面的分析,我们知道索引即是把记录限定到一定查询范围内的字段。那么主键对我们来说就是一个很好的切入点,包括唯一键和普通键也是可以的。
那么怎么才可以让我们的查找更加高效呢?这时候就应该引入数据结构来帮助我们了。可以是二叉树,平衡二叉树,红黑树,B树,B+树,一些hash结构。而Mysql里面主要是通过B+数实现的。