参考论文https://arxiv.org/pdf/2303.17651
引言:为什么我们关注这个方法?
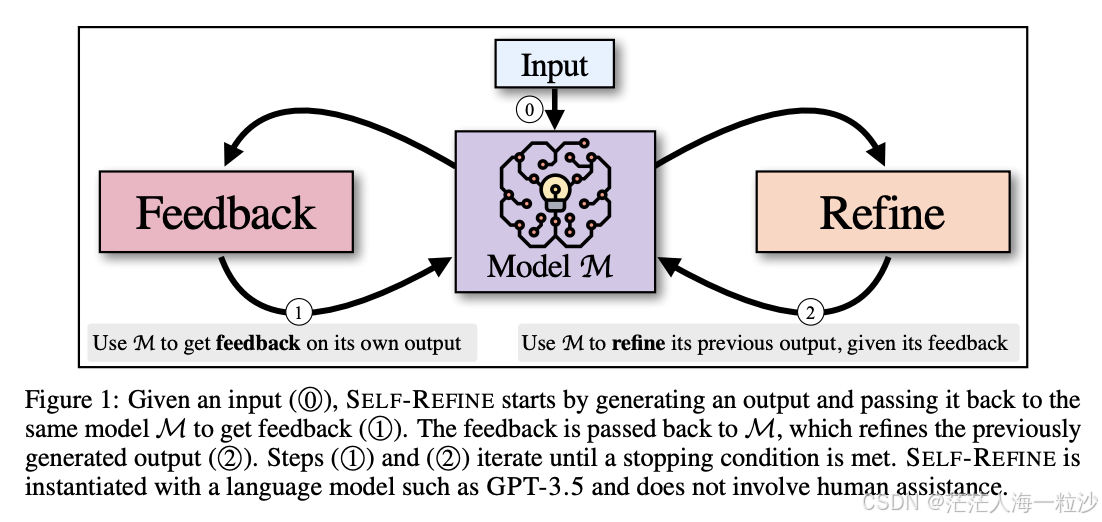
语言模型(LLMs)生成的内容常常很智能,但"一次生成"往往不是最优解。就像人写作文,即使思路清晰,也会经过反复修改才更好。论文作者 A. Madaan 等人正是受此启发,提出了一种无需额外训练、全凭模型自我反馈与自我改进的策略------Self-Refine 。
核心理念:模型自我打反馈,再自我修正
Self-Refine 的流程其实非常直观:
-
初始生成:用模型生成一个初稿(Output₀)。
-
自我反馈:让同一个模型对自己的初稿进行评估,指出可以改进之处(Feedback₁)。
-
自我改进:再一次由模型根据反馈生成改进版本(Output₁)。
-
迭代过程:重复反馈---改进,直到满足停止条件,比如达到质量、迭代次数或无显著改进为止 。
亮点是:这个过程 不需要额外的数据、训练,也不涉及强化学习,完全依赖原模型在测试阶段进行自改进。
实验设计:广泛任务验证有效性
作者在 7 项任务 上验证了 Self-Refine,包括:
-
对话生成
-
情感逆转(sentiment reversal)
-
数学推理
-
评论改写
等多种类型任务 (summarizepaper.com, ResearchGate)。
他们使用了 GPT-3.5、ChatGPT 和 GPT-4 等主流 LLM 做对比实验。
论文中提到的示例
示例 1:写邮件
普通生成(一次性输出)
"Dear Manager, I want to apply for vacation next week. Please approve. Thanks."
Self-Refine 过程
-
反馈:邮件语气过于生硬,缺少礼貌和细节。
-
改进后输出:
"Dear Manager, I hope this message finds you well. I would like to request vacation leave from September 12th to 16th. Please let me know if this works for the team schedule. Thank you for your consideration."
结果:更专业、更礼貌。
示例 2:数学解题
问题:解方程 2x+3=112x + 3 = 11。
模型初稿:
"答案是 x=5x=5。"
反馈:检查后发现计算错误,2x+3=11⇒2x=8⇒x=42x + 3 = 11 \Rightarrow 2x = 8 \Rightarrow x = 4。
改进结果:
"正确答案是 x=4x=4。"
结果:通过自我反馈修正了逻辑错误。
示例 3:文本润色
输入:
"This restaurant food good, but service bad."
第一次输出:
"The food at this restaurant is good, but the service is bad."
反馈:表达清楚了,但风格不够自然,可以更优雅。
改进后输出:
"The food at this restaurant is delicious, though the service could be improved."
结果:表达更自然,语气更贴近母语者习惯。
示例 4:对话生成
场景:用户问客服 "我忘记密码了,怎么办?"
普通回复:
"你可以重置密码。"
Self-Refine 改进:
-
反馈:回答过于简略,缺少具体步骤。
-
改进结果:
"您可以点击登录页面的'忘记密码',输入邮箱并按照提示重置。如果遇到问题,我们的客服团队也可以帮您操作。"
结果:更完整、更贴心。
成果:性能显著提升,用户更喜欢 Self-Refine 生成内容
-
客观评价指标 :所有任务 Self-Refine 的输出,比起传统一步生成方式,平均提升约 20%(绝对值) 。
-
用户体验:在人工偏好实验中,人类评价者更倾向于选择 Self-Refine 的产出版本作为优质答案。
-
对 GPT-4 的意义:即便是 GPT-4 这类已接近 SOTA 的模型,也能通过 Self-Refine 获取进一步提升,说明其具备非凡的应用价值 。
亮点总结:为什么这方法值得关注?
| 特性 | 说明 |
|---|---|
| 通用性强 | 只要是支持语言生成的 LLM,都可立即使用,无需再训练 |
| 无需额外数据 | 纯粹测试时操作,不依赖额外标签或训练样本 |
| 简单有效 | 通过反馈---修正的闭环流程,提升模型输出质量 |
| 可扩展性好 | 理论上适用于各种任务类型,比如生成、理解、推理等 |
面向未来:你可以怎么用它?
-
集成到应用中:客服机器人、文章摘要、代码生成工具等可以调用 Self-Refine 以提高文本质量。
-
搭配 Chain-of-Thought:组合推理步骤,再让模型自检自动改进中间结果提高准确性。
-
任务定制反馈策略:例如对于数学题,反馈可以是"哪里算错了?",增强模型逻辑推理。
-
研究方向:如何设定稳定的迭代终止条件?未来可以探索将多模型结合互评,进一步优化。
小结
Self-Refine 向我们展示了一种 "语言模型可以自己看自己,自己修正自己" 的技术路线,既简洁又高效。通过在测试阶段引入自反馈与迭代修正,它显著提升了生成质量,且无需额外资源。这种思路既启发性强又实用性高,非常值得在更多应用场景中推广和探索。