在 Oracle 数据库运维中,ASM(Automatic Storage Management)作为高效的存储管理方案,其稳定性直接决定了数据库服务的连续性。但在实际操作中,添加、更换 ASM 磁盘时若操作不当或忽视潜在风险,极易引发磁盘组异常、数据损坏甚至业务中断。本文将通过两个医院和一个银行,三个真实故障案例,分析ASM 磁盘故障的发生场景、诊断过程及解决思路,为运维人员提供可复用的经验参考。
案例一:某妇保医院------Oracle Bug 导致磁盘组挂载失败
故障背景与现象
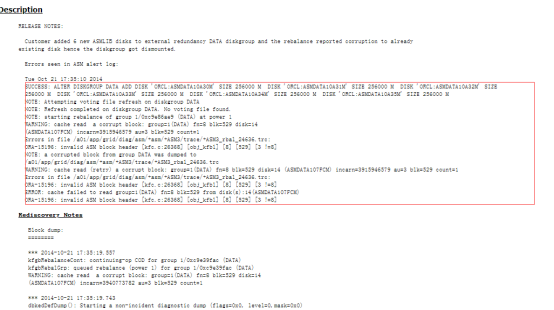
某医院在为 ASM 磁盘组(DB)新增磁盘(/dev/asm-diskm)时,初期操作看似顺利:磁盘添加命令执行成功,系统启动 Rebalance(重平衡)进程(ARB0),但半小时后故障突发:
-
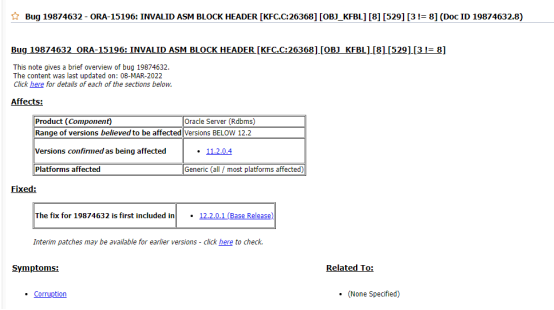
磁盘头异常:ASM 告警日志显示 "invalid ASM block header"(无效 ASM 块头),错误代码 ORA-15196,提示块头校验值不匹配(2359874717 != 2235620521);
-
磁盘组强制卸载:系统检测到元数据损坏后,自动将 DB 磁盘组标记为 "de-assignment"(待移除),并执行强制卸载(ALTER DISKGROUP DB dismount force);
-
业务中断:依赖该磁盘组的数据库实例无法访问,业务暂停。
故障诊断:定位 Oracle Bug
通过对比 Oracle 官方故障库及告警日志细节,确认故障根源为Oracle 已知 Bug:当为外部冗余磁盘组添加新 ASMLIB 磁盘时,Rebalance 过程中会误报已有磁盘的元数据损坏,触发磁盘组卸载机制。关键证据如下:
-
告警日志中 "ORA-15335: ASM metadata corruption detected"(检测到 ASM 元数据损坏)与 Oracle Bug 描述完全吻合;
-
同类案例如官方文档中显示,bug导致磁盘组无法挂载,且无临时修复方案。
-
解决方案:切换容灾 + 重建磁盘组
由于磁盘组元数据损坏无法修复,需通过容灾切换与磁盘组重建恢复业务,步骤如下:
-
关闭冗余服务:先禁用并停止 Scan 监听、VIP 服务,避免切换过程中客户端误连故障节点:
禁用服务
srvctl disable scan_listener
srvctl disable scan
srvctl disable listener -n test1 # test1/test2为RAC节点名
srvctl disable vip -n test1
停止服务
srvctl stop scan_listener
srvctl stop scan
srvctl stop listener -n test1
srvctl stop vip -n test1
-
清理故障磁盘 :通过
select * from v$asm_disk确认故障磁盘路径,使用dd命令清空磁盘头(避免残留元数据干扰重建):dd if=/dev/zero of=/dev/asm-diskm bs=1024k count=100
-
重建磁盘组:创建新的 DB 磁盘组,指定外部冗余与兼容版本:
create diskgroup DB external redundancy
disk '/dev/asm-diskl','/dev/asm-diskm' # 所有正常磁盘路径
attribute 'compatible.asm'='11.2.0.0.0';
-
恢复业务:单独启动 DB 监听,搭建 Data Guard 容灾链路,确保数据同步后切换业务至新磁盘组。
案例二:某医院 ------ 误将在用磁盘添加致空间撑满与实例宕机
故障背景与时间线
某医院 HIS 系统数据库因归档日志异常增长,导致 ASM 磁盘组(DATA)空间耗尽。运维团队先删除部分归档应急,计划夜间新增 2 块 1T 磁盘扩容,却引发更严重故障:
-
2025-05-31 07:59:新增磁盘划分完成并挂载;
-
2025-05-31 20:00:启动 DATA 磁盘组扩容;
-
2025-05-31 22:33:业务突然中断,数据库实例宕机;
-
2025-05-31 22:38:排查发现 DATA 磁盘组无法挂载。
故障诊断:磁盘复用冲突
通过三层排查,定位核心问题为磁盘资源重复使用:把本地文件系统/rman的磁盘加入到asm磁盘中了,当rman备份发起后,导致asm磁盘头损坏。
-
ASM 告警日志分析:日志显示 "ORA-15196: invalid ASM block header",且指向新增磁盘 newdata03(DATA_0000),提示其 AU(Allocation Unit,分配单元)块损坏;
-
磁盘权限与 AU 块检查 :使用
kfed工具读取 newdata03 的 AU 块(aun=5 blkn=17),发现块类型为 "Unknown Enum"(未知类型),校验值全为 0xff,确认磁盘已被篡改; -
系统磁盘挂载检查 :通过
lsblk与df -h发现,newdata03 实际为 RMAN 备份的逻辑卷(vg_rmanbak-lv_rmanbak),且已挂载至/rman目录(使用空间 753G),新增磁盘时未排查占用状态,导致 ASM 与文件系统争抢磁盘资源,破坏元数据。
解决方案:临时备库支撑 + 生产环境修复
由于生产磁盘组元数据损坏,且仅存前一天(5 月 30 日)的备份,需分两步恢复:
- 临时业务支撑:
-
启用 Data Guard 备库,强制打开后扩容资源、更换 IP,作为临时库承接院内业务;
-
通过
alter system set events '15195 trace name context forever, level 604'强制挂载故障磁盘组,提取残留归档日志,补充备份数据。
- 生产环境修复:
-
清理冲突磁盘:卸载
/rman挂载点,删除 RMAN 逻辑卷,确保 newdata03 仅归 ASM 使用; -
重建 DATA 磁盘组,恢复 5 月 30 日备份并应用归档日志;
-
搭建临时单机库与修复后的生产库的 Data Guard,于 6 月 4 日业务空闲时切换,回归 RAC 环境。
案例三:某银行 ------Rebalance 未完成强制删盘致冗余不足
故障背景与现象
某银行在更换存储时,计划将 ASM 磁盘组(DATA)的老磁盘替换为新磁盘,操作步骤为 "添加新磁盘→删除老磁盘",但删除老磁盘后故障发生:
-
Rebalance 报错:系统提示 "ORA-59048: Insufficient failure groups to restore redundancy"(故障组数量不足,无法恢复冗余);
-
磁盘状态异常 :查询
v$asm_disk发现,被删除的老磁盘(_DROPPED_0000_DATA)状态为 "FORCING"(强制移除),且新磁盘未配置故障组(FAILGROUP),导致磁盘组冗余度不满足要求。
故障诊断:Rebalance 中断与故障组配置缺失
问题根源在于操作时序错误 与故障组配置遗漏:
-
Rebalance 未完成:删除老磁盘时,ASM 仍处于 Rebalance 的第二阶段(extent relocation,数据块迁移),此时强制删盘导致数据块未完全迁移至新磁盘,触发冗余检查;
-
故障组配置缺失:老磁盘属于故障组 DATA1,而新增磁盘未指定 FAILGROUP,导致磁盘组故障组数量从 1 变为 0,无法满足冗余策略(如 Normal Redundancy 需至少 2 个故障组)。
解决方案:恢复老磁盘 + 补全故障组配置
需先恢复磁盘组冗余,再完成存储更换:
-
恢复老磁盘 :将已删除的老磁盘重新添加至 DATA 磁盘组,等待 Rebalance 完成(通过
v$asm_operation查看状态,直至 EST_MINUTES=0); -
补全故障组:删除新磁盘后重新添加,明确指定故障组:
alter diskgroup DATA drop disk '/dev/mapper/newdata2';
alter diskgroup DATA add disk '/dev/mapper/newdata2' failgroup DATA1;
-
正常替换磁盘 :待新磁盘 Rebalance 完成后,再删除老磁盘,确保每一步操作间隔足够长,通过
alert.log确认无异常。
三大案例总结:ASM 磁盘操作核心风险与规避策略
通过三个案例的复盘,可提炼出 ASM 磁盘运维的 3 个核心风险点与对应规避方案,帮助减少故障概率:
| 风险类型 | 典型场景 | 规避策略 |
|---|---|---|
| Oracle Bug 风险 | 添加磁盘触发 Rebalance,误报元数据损坏 | 1. 操作前查询 Oracle 官方 Bug 库,确认当前 ASM 版本无相关 Bug;2. 优先创建新磁盘组,避免在生产磁盘组直接添加;3. 操作前验证备份与容灾有效性,确保可快速恢复 |
| 磁盘资源冲突 | 新增磁盘已被文件系统、逻辑卷占用 | 1. 新增磁盘前,通过lsblk检查分区状态、df -h检查挂载情况;2. 使用kfod di=all(grid 用户)确认 ASM 已识别磁盘,且无其他进程占用;3. 标记 ASM 磁盘(如命名前缀 asm-),与其他磁盘区分 |
| Rebalance 操作时序错误 | 未完成 Rebalance 强制删盘,或故障组配置缺失 | 1. 删盘前通过v$asm_operation确认 Rebalance 状态,仅当无操作时执行删除;2. Rebalance 分三阶段:Planning(短)→Extent Relocation(耗时久,alert.log 显示 "relocating file")→Compacting(EST_MINUTES=0,alert.log 显示 "stopping process ARB0"),需等待三阶段完成;3. 添加磁盘时明确指定故障组,确保冗余度满足磁盘组策略 |
ASM 磁盘运维的核心在于 "谨慎操作 + 全面预检":每一次添加、删除磁盘前,都需验证磁盘状态、版本兼容性与容灾有效性,避免因小疏忽导致业务中断。希望本文的案例与策略,能为运维人员提供实战参考,提升 ASM 存储管理的稳定性。