1.namenode 和 secondarynamenode 启动失败
执行 start-dfs.sh 脚本,发现 namenode 和 secondarynamenode 没有启动,之后使用 hdfs namenode 命令单独启动时,报错如下:/app/hadoop/hadoop-2.6.4/name/in_use.lock 权限不足
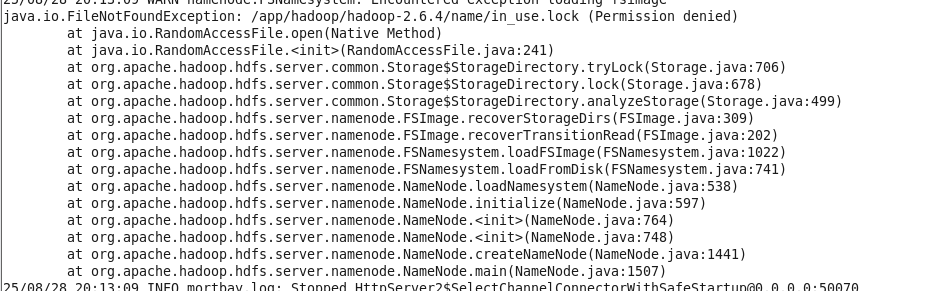
通过下面命令查到 in_use.lock 文件的所有者和所属组都为root(uid,gid=0),所以执行命令 chown 将其都改为hadoop。

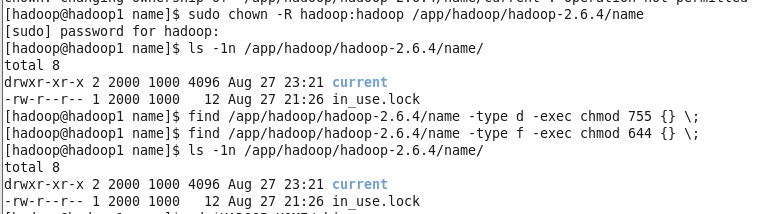
之后成功启动namenode,secondarynamenode同理。
2.主服务器上DataNode启动失败
使用hdfs datanode 命令启动后报错如下:clusterID 不匹配
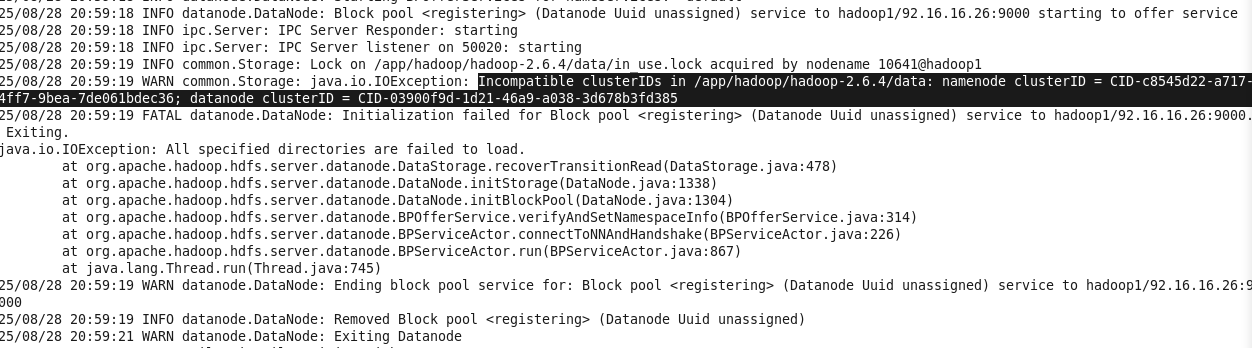
解决方案:停止所有hadoop进程,删除DataNode的旧数据目录(注意:此操作会清空 DataNode 存储的数据块,测试环境可放心执行),该目录在 hdfs-site.xml 中的 dfs.datanode.data.dir 配置,重新启动 HDFS 服务。
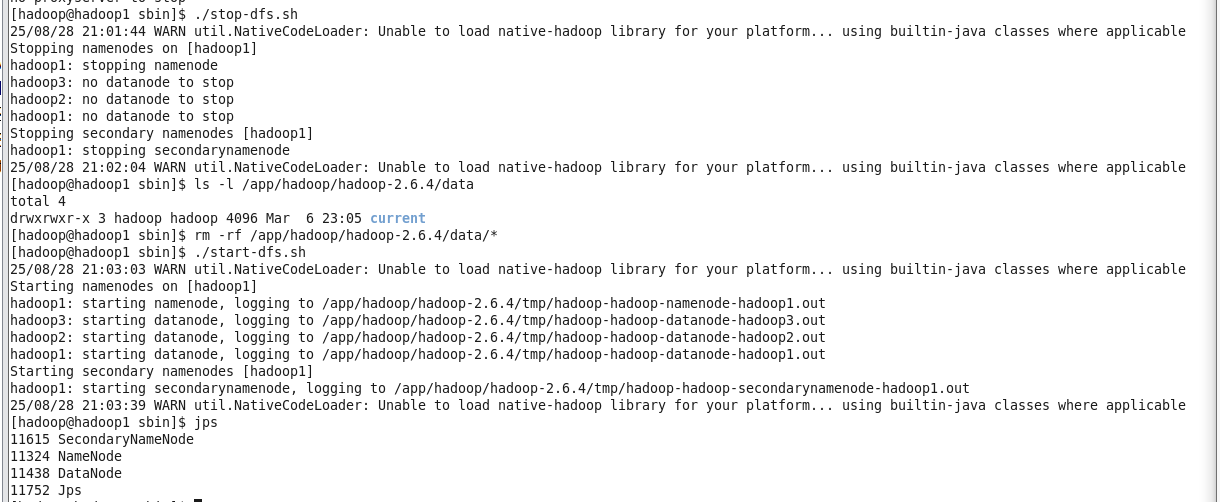
3.子服务器上DataNode报错
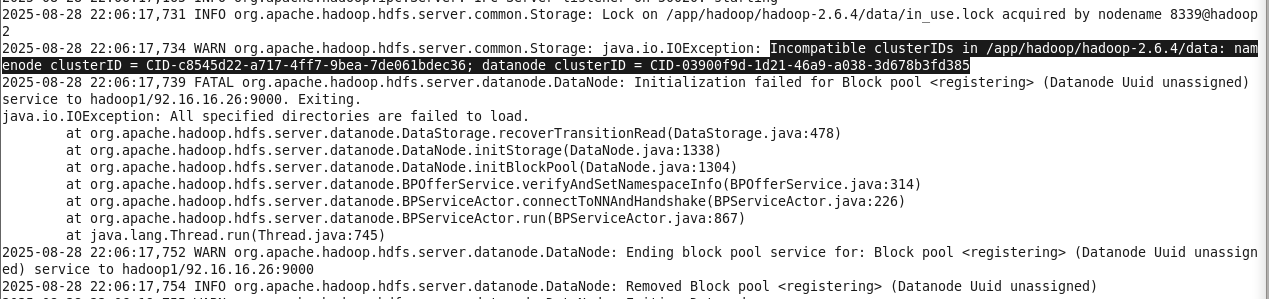
先找到主服务器上的clusterID值,保证子服务器的 $HADOOP_HOME/data/current/VERSION 文件中clusterID的值与主服务器一致。之后使用命令 ./hadoop-daemon.sh start datanode 启动datanode即可。

