* Cond(通常只用于频繁的 Broadcast 通知)
对于需要重复调用 Broadcast 的场景,比如 Kubernetes 的例子,每次往队列中成功增加了元素后就需要调用 Broadcast 通知所有的等待者,使用 Cond 非常合适
但真正使用 Cond 的场景比较少,因为一旦遇到需要使用 Cond 的场景,我们更多地会使用 Channel 的方式
- Signal 方法,允许调用者 Caller 唤醒一个等待此 Cond 的 goroutine。
- Broadcast 方法,允许调用者 Caller 唤醒所有等待此 Cond 的 goroutine。
- Wait 方法,会把调用者 Caller 放入 Cond 的等待队列中并阻塞,直到被 Signal 或者 Broadcast 的方法从等待队列中移除并唤醒。
Once

单例对象:在整个应用程序的生命周期中,只有一个实例存在,并提供一个全局统一的访问点来获取这个唯一的实例
- 应用场景:数据库连接池 ,全局配置管理器 ,日志记录器 (Logger)
Once 是在 Go 语言中实现线程安全的单例模式的完美且最地道的工具
使用 Once 可能出现的 2 种错误
- 第一种错误:死锁
-
第二种错误:未正确初始化
即使一些资源没有在once.Do()中初始化成功,也不能再进行once.Do()了
解决办法:
- 实现一个类似 Once 的并发原语,既可以返回当前调用 Do 方法是否正确完成,还可以在初始化失败后调用 Do 方法再次尝试初始化,直到初始化成功才不再初始化了。
- singleflight:对于同一个任务,无论有多少个并发请求,都确保在同一时间内只有一个请求真正在执行,其他请求只会等待这个执行结果,不会继续尝试
Map
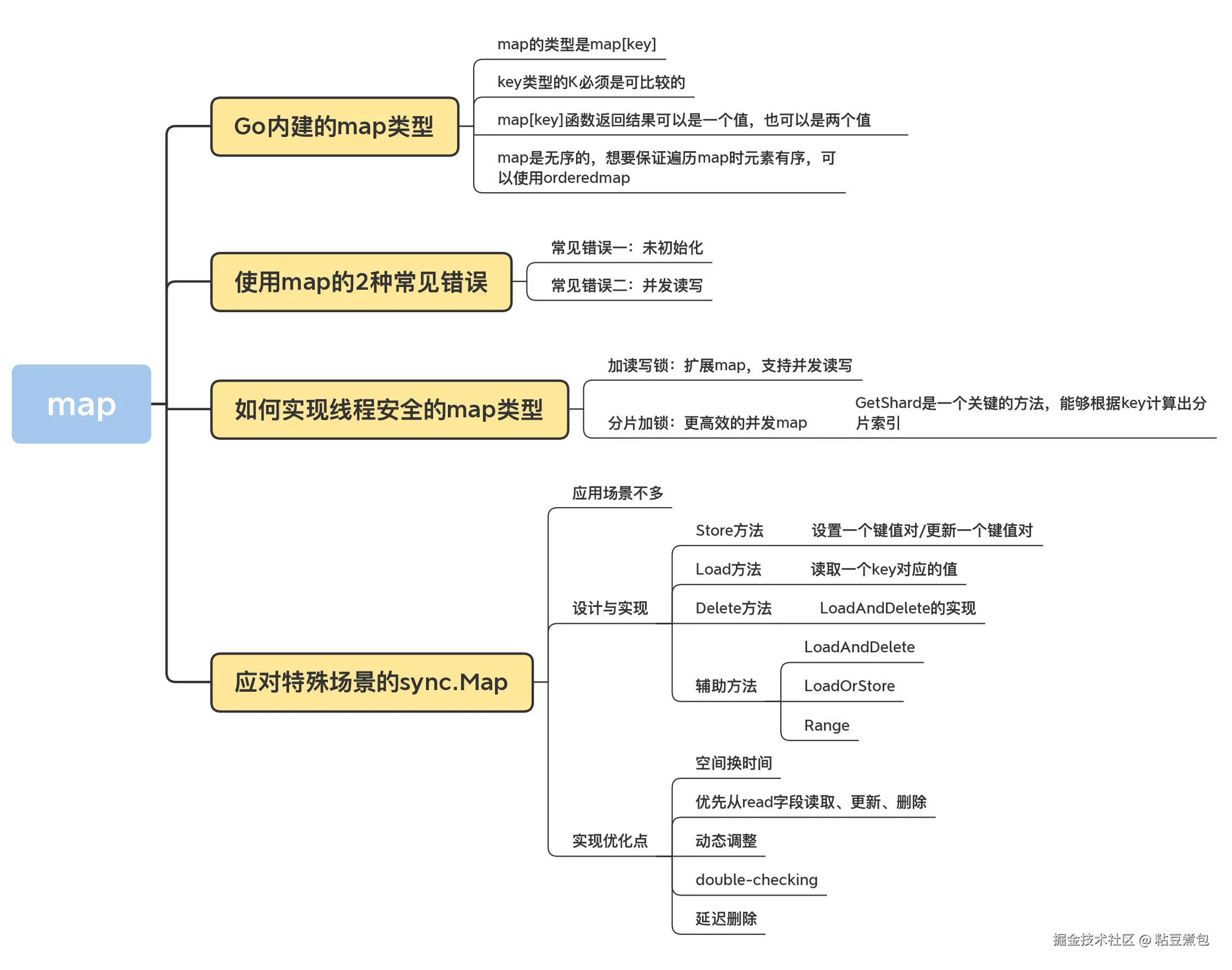
Add、Lookup、Delete
顺序获取 Map 的值
- 如果要按照 key 的顺序获取 map 的值,需要先取出所有的 key 进行排序,然后按照这个排序的 key 依次获取对应的值
orderedmap:可以记录插入顺序
使用 map 的 2 种常见错误
-
常见错误一:未初始化
map 对象必须在使用之前初始化,m := make(mapintint)
-
常见错误二:并发读写
Go 内建的 map 对象不是线程(goroutine)安全的,并发读写的时候运行时会有检查,遇到并发问题就会导致 panic。
加读写锁:扩展 map,支持并发读写(泛型版本)
泛型:代码复用 + 类型安全 + 代码更简洁、更易读
scss
// 引入了两个类型参数:
// K: 代表键(Key)的类型。它有一个约束 comparable,因为 map 的键必须是可比较的。
// V: 代表值(Value)的类型。它可以是任何类型 (any)。
type RWMap[K comparable, V any] struct {
sync.RWMutex
m map[K]V // m 的类型不再是写死的,而是由 K 和 V 决定
}
// 新建一个泛型的 RWMap
// 注意函数签名也需要声明类型参数
func NewRWMap[K comparable, V any](n int) *RWMap[K, V] {
return &RWMap[K, V]{
m: make(map[K]V, n),
}
}
// Get 方法的参数和返回值类型都变成了泛型
func (m *RWMap[K, V]) Get(k K) (V, bool) {
m.RLock()
defer m.RUnlock()
v, existed := m.m[k]
return v, existed
}
// Set 方法的参数类型也变成了泛型
func (m *RWMap[K, V]) Set(k K, v V) {
m.Lock()
defer m.Unlock()
m.m[k] = v
}
// Delete 方法的参数类型也变成了泛型
func (m *RWMap[K, V]) Delete(k K) {
m.Lock()
defer m.Unlock()
delete(m.m, k)
}
func (m *RWMap[K, V]) Len() int {
m.RLock()
defer m.RUnlock()
return len(m.m)
}
// Each 方法的回调函数 f 的参数类型也变成了泛型
func (m *RWMap[K, V]) Each(f func(k K, v V) bool) {
m.RLock()
defer m.RUnlock()
for k, v := range m.m {
if !f(k, v) {
return
}
}
}Map的分片
go
import (
"github.com/orcaman/concurrent-map/v2"
)Map 可以通过分片减少锁的颗粒度,从而追求更高的性能
应对特殊场景的 sync.Map(很少用)
- 只会增长的缓存系统中,一个 key 只写入一次而被读很多次
- 多个 goroutine 为不相交的键集读、写和重写键值对。
Store、Load 和 Delete 方法
- Store方法 :设置一个键值对
- Load 方法:读取一个 key 对应的值
- Delete 方法:根据键删
性能测试(实践出真知)
拓展
带有过期功能的timedmap,使用红黑树实现的 key 有序的treemap等
Pool
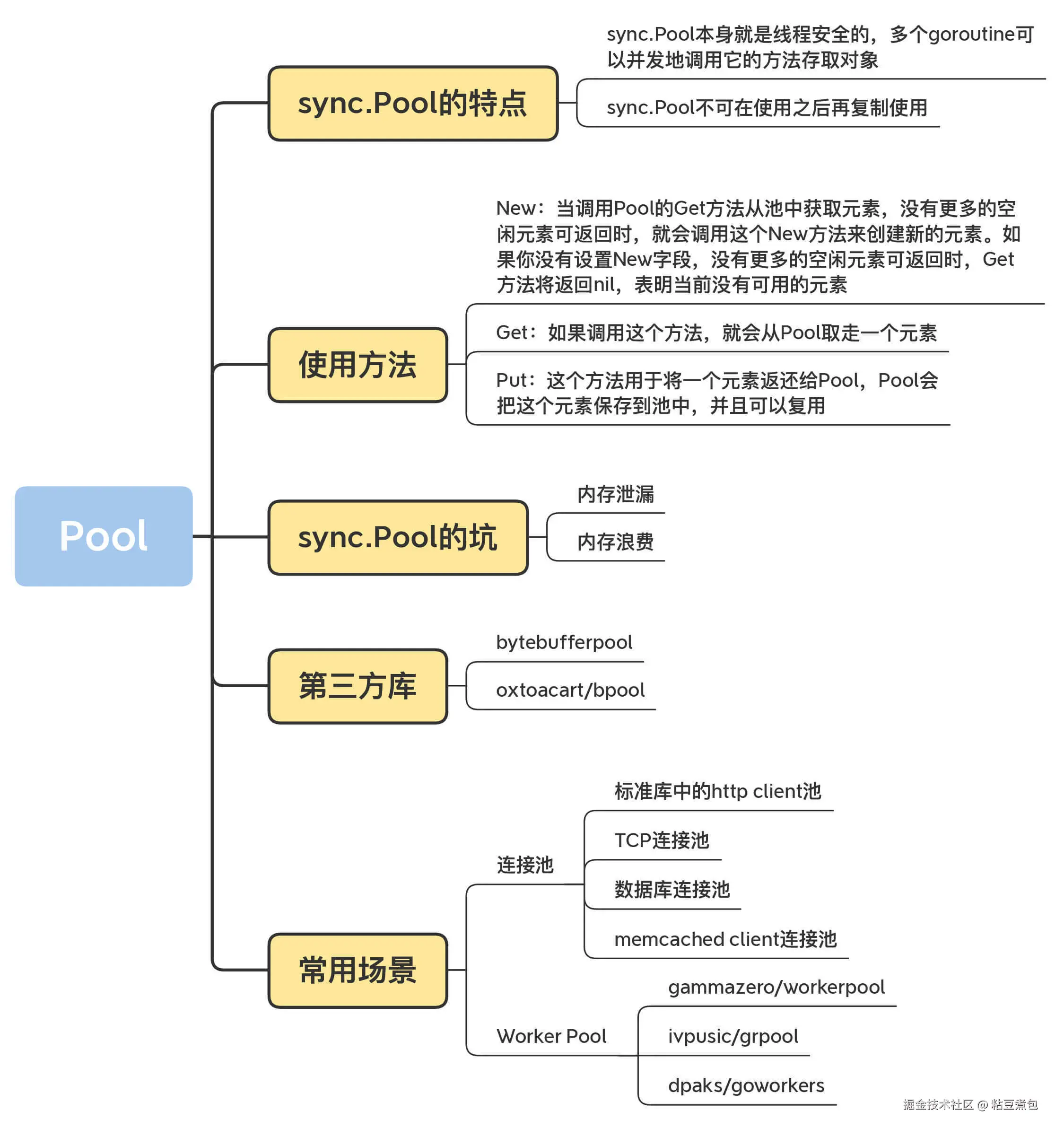
Go 的自动垃圾回收机制包含 STW :有时会节省空间,但有时会导致重复新建资源,特别是数据库连接、TCP 的长连接创建非常耗时
对象池:把不用的对象回收起来,避免被垃圾回收掉,就不必在堆上重新创建了
sync.Pool
- sync.Pool 本身就是线程安全的,多个 goroutine 可以并发地调用它的方法存取对象
- sync.Pool 不可在使用之后再复制使用。
New:创建新的元素
Get:取走一个元素
Put:将一个元素返还给 Pool
常用场景: 内存中的临时对象(缓冲池)
Go 1.13 之前的 sync.Pool 的实现的 2 大问题:
- 每次 GC 都会回收创建的对象
- 底层实现使用了 Mutex,对这个锁并发请求竞争激烈的时候,会导致性能的下降
Go 1.13
- private:极致性能,单P私有,无锁。
- shared:高性能,本地P优先,但可被其他P"窃取",有原子操作。
- local:是 private 和 shared 的组合,每个P独享一个,这是避免全局锁的关键。
- victim:是上一轮GC时的local,是对象的"复活区",用来应对流量波动,提升对象存活率。
- poolCleanup:就是一次"轮换",把victim扔掉,把local变成新的victim,再清空local。
Get 一个杯子(对象)的流程 (从快到慢)
一个 goroutine (在 P1 咖啡师上运行) 需要一个杯子:
- 先看私有小抽屉 (private) :P1 咖啡师先打开自己的 private 抽屉。如果有,直接拿走。这是最快的路径,无锁。
- 再看共享杯子架 (shared) :如果 private 是空的,P1 就从自己面前的 shared 杯子架上拿一个。这需要原子操作,稍慢。
- 去"偷"别人的 (work stealing) :如果自己的 shared 也空了,P1 会随机 看一眼隔壁 P2 咖啡师的 shared 杯子架,从上面"偷"一半的杯子过来。这是 sync.Pool 性能的第二个秘密,实现了负载均衡。
- 最后看备用区 (victim) :如果偷也偷不到,P1 就会去吧台角落的 "上一轮用剩的托盘" (victim) 上找一个。
- 实在没了就造新的:如果 victim 也没有,P1 只能调用 Pool.New 函数,从仓库里拿一个全新的杯子。
Put 一个用完的杯子回去的流程
- 先放回私有小抽屉 (private) :如果 P1 的 private 抽屉是空的,他就把杯子放进去。无锁,最快。
- 再放回共享杯子架 (shared) :如果 private 抽屉已经有杯子了,他就把这个新杯子放到自己面前的 shared 杯子架上。
sync.Pool 的坑
-
内存泄漏:如果装的是切片,如byte slice,那么使用之后会变大,放回来就大了,占很大空间
- 解决办法:检查回收的对象的大小,太大就不要了
-
内存浪费:池子中的 buffer 都比较大,用不上
- 解决办法:buffer 池分层 / 分桶(Bucketing)
第三方库
bytebufferpool、oxtoacart/bpool(容量控制)
使用场景(网络连接):
- 标准库中的 http client 池:访问 web 服务器
- TCP 连接池:fatih/pool、net.Conn
- 数据库连接池:sql.DB
- Memcached Client 连接池
Worker Pool / Goroutine Pool
- gammazero/workerpool:gammazero/workerpool 可以无限制地提交任务,提供了更便利的 Submit 和 SubmitWait 方法提交任务,还可以提供当前的 worker 数和任务数以及关闭 Pool 的功能。
- ivpusic/grpool:grpool 创建 Pool 的时候需要提供 Worker 的数量和等待执行的任务的最大数量,任务的提交是直接往 Channel 放入任务。
- dpaks/goworkers:dpaks/goworkers 提供了更便利的 Submit 方法提交任务以及 Worker 数、任务数等查询方法、关闭 Pool 的方法。它的任务的执行结果需要在 ResultChan 和 ErrChan 中去获取,没有提供阻塞的方法,但是它可以在初始化的时候设置 Worker 的数量和任务数。
总结:
场景一:我需要复用【内存对象】
-
默认选项:sync.Pool (标准库)
-
什么时候用?
- 当你需要复用的对象是固定大小的,或者大小变化不大的时候。
- 当你需要复用的对象有明确的 Reset 方法可以将其恢复到初始状态时。
- 最常见场景:复用 *bytes.Buffer, *json.Encoder, Protobuf 消息对象等。
-
优点:标准库自带,无需引入第三方依赖,经过大规模验证,性能极高。
-
缺点:如你总结,对可变大小的对象(尤其是 buffer)支持不佳,可能导致内存浪费或泄漏。
-
-
进阶选项:bytebufferpool (第三方分桶池)
-
什么时候用?
- 当你需要复用的对象是\[\]byte 或 bytes.Buffer,并且这些 buffer 的大小会频繁变化时。
- 最常见场景:网络编程中,读取或写入不定长的数据包;Web 框架中,渲染模板或构建 HTTP 响应体。
-
优点:通过分桶机制,极大地减少了内存浪费,避免了 buffer 的频繁扩容。
-
决策依据:如果你用 pprof 分析程序,发现大量内存在 bytes.Buffer 上,并且程序性能抖动,那么换用 bytebufferpool 可能会有奇效。
-
场景二:我需要复用【网络连接】
-
database/sql (标准库数据库连接池)
-
什么时候用?
- 只要你使用 Go 连接关系型数据库 (MySQL, PostgreSQL 等),你就必须使用它。它不是一个选项,而是一个标配。
- sql.DB 对象本身就是一个线程安全的连接池,你只需要在程序启动时初始化一次,然后在各处共享使用即可。
-
关键点:你不需要自己去实现数据库连接池。
-
-
第三方通用连接池 (如 fatih/pool)
-
什么时候用?
-
当你需要连接非数据库的服务,并且对方没有提供官方的连接池实现时。
-
最常见场景
- TCP 连接池:你需要和一个自定义的 TCP 服务进行高频、短时的通信。
- gRPC Client 连接池:虽然单个 gRPC client conn 内部可以处理并发,但在超高并发下,使用多个 conn 组成的池可以进一步提升吞吐量。
- Redis Client 连接池:大多数现代 Redis 客户端(如 go-redis)内部已经为你管理好了连接池,通常你也不需要自己再包一层。
-
-
场景三:我需要复用【Goroutine】
-
什么时候用?
-
当你有一个任务源源不断的场景,但你又不希望一有任务就启动一个 goroutine,导致瞬间并发数失控,最终压垮系统。
-
最常见场景:
- 一个爬虫系统,需要并发地抓取成千上万个 URL,但你希望最多只同时有 50 个抓取任务在运行。
- 一个数据处理服务,需要从消息队列(如 Kafka)中消费消息并处理,你希望控制处理消息的并发度。
- 一个图片处理服务,用户上传图片后需要进行多种处理(缩放、加水印),你希望用一个协程池来统一管理这些处理任务。
-
Context
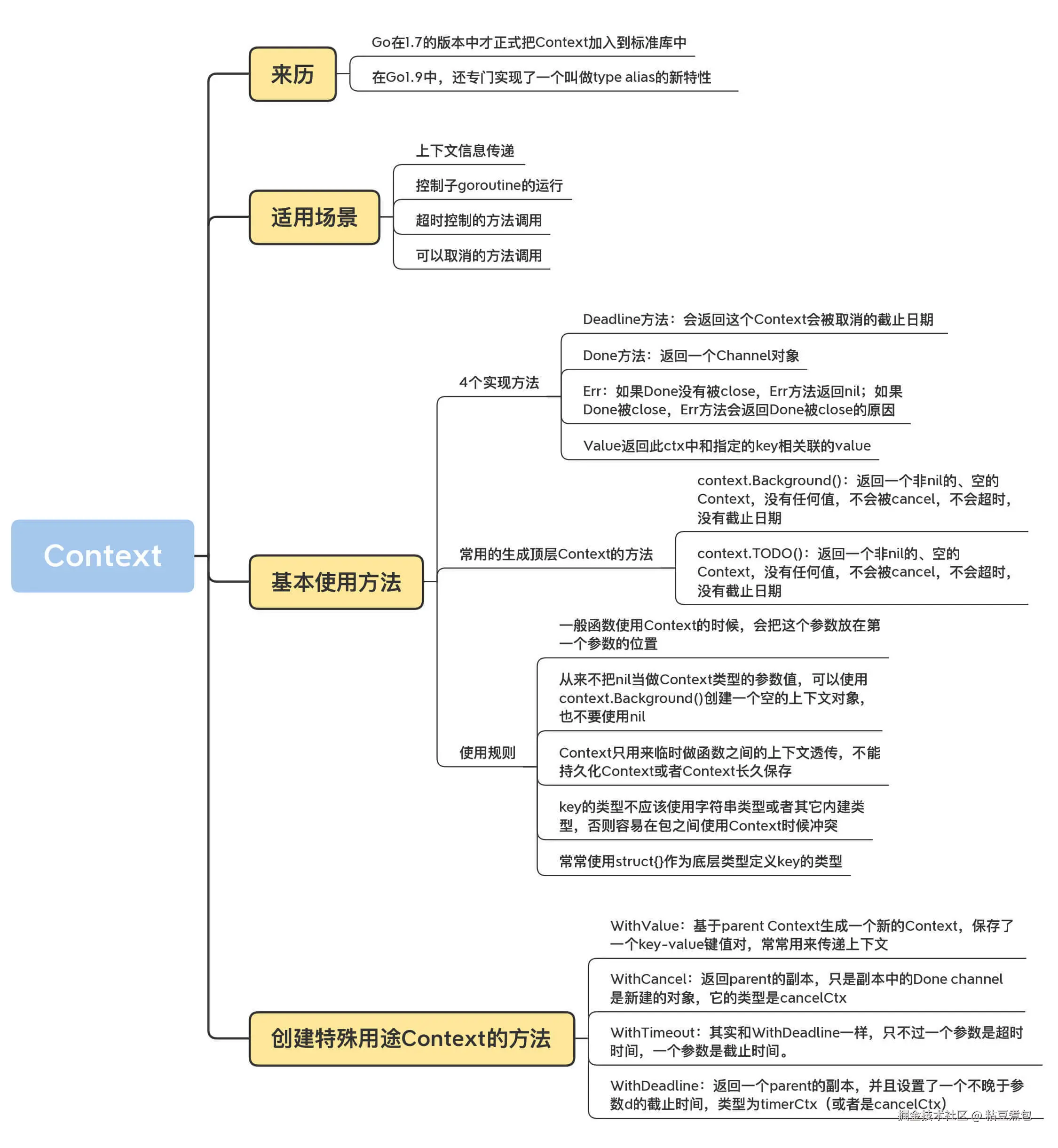
上下文:在 API 之间或者方法调用之间,所传递的除了业务参数之外的额外信息
- 上下文信息传递 (request-scoped),比如处理 http 请求、在请求处理链路上传递信息;
- 控制子 goroutine 的运行;
- 超时控制的方法调用;
- 可以取消的方法调用。
Deadline 方法:返回这个 Context 被取消的截止日期
Done 方法:返回一个 Channel 对象;如果 Done 没有被 close,Err 方法返回 nil;如果 Done 被 close,Err 方法会返回 Done 被 close 的原因
Value :返回此 ctx 中和指定的 key 相关联的 value
context.Background():返回一个非 nil 的、空的 Context,没有任何值,不会被 cancel,不会超时,没有截止日期。
context.TODO():(不咋用)
约定俗成的规则:
首参传 Context, 空值 Background。 切莫长久存, 传值不传形。 Key 用自定义, 安全不冲突。
特殊用途 Context
- context.WithValue:可以携带额外的信息(KV对)
- context.WithCancel:可以被手动喊停
- context.WithTimeout:指定时间自动取消
- context.WithDeadline:具体的未来时间点会自动取消(更适合跨多个节点、有统一截止时间的分布式任务)
应用场景
场景一:优雅地控制 Goroutine 的"生死"
scss
func main() {
ctx, cancel := context.WithCancel(context.Background())
go func(ctx context.Context) {
for {
select {
case <-ctx.Done(): // 监听到取消信号
fmt.Println("任务已取消,正在退出...")
return
default:
// 正常执行任务...
fmt.Println("正在工作中...")
time.Sleep(1 * time.Second)
}
}
}(ctx)
// 让子goroutine运行3秒
time.Sleep(3 * time.Second)
// 主任务决定取消子任务
fmt.Println("通知子任务取消!")
cancel()
// 等待子任务退出
time.Sleep(1 * time.Second)
}场景二:为"慢操作"设定"最后期限" (超时控制)
go
func fetchUserData(userID string) (string, error) {
// 最多给这次请求 50 毫秒的时间
ctx, cancel := context.WithTimeout(context.Background(), 50*time.Millisecond)
defer cancel() // 释放资源
// 创建一个带 context 的 HTTP 请求
req, err := http.NewRequestWithContext(ctx, "GET", "http://api.example.com/users/"+userID, nil)
if err != nil {
return "", err
}
// 执行请求
resp, err := http.DefaultClient.Do(req)
if err != nil {
// 如果是因为超时,这里的 err 就是 context.DeadlineExceeded
if errors.Is(err, context.DeadlineExceeded) {
fmt.Println("请求下游服务超时了!")
}
return "", err
}
// ... 处理响应
defer resp.Body.Close()
return "some data", nil
}场景三:在请求调用链中"秘密"传递信息 (元数据传递)
go
// 定义一个私有的 key 类型,防止冲突
type traceIDKey struct{}
// 中间件:将 trace_id 注入 context
func TracingMiddleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
traceID := r.Header.Get("X-Request-ID") // 假设从请求头获取
if traceID == "" {
traceID = "generate-a-new-one"
}
// 注入 context
ctx := context.WithValue(r.Context(), traceIDKey{}, traceID)
// 将新的 context 传入下一个处理器
next.ServeHTTP(w, r.WithContext(ctx))
})
}
// 业务逻辑处理器:从 context 中读取 trace_id
func GetUserHandler(w http.ResponseWriter, r *http.Request) {
// 读取 context
ctx := r.Context()
if traceID, ok := ctx.Value(traceIDKey{}).(string); ok {
fmt.Printf("处理请求,Trace ID: %s\n", traceID)
}
// ... 业务逻辑
}