🏗️ 线程池深度解析:ThreadPoolExecutor底层实现与CompletableFuture异步编程实战
📚 文章导读
🎯 想象一下 :你正在管理一个大型餐厅,每天有成千上万的订单需要处理。如果每来一个订单就招聘一个新厨师,那成本得多高啊!但如果有了 线程池这个"智能厨师管理系统",就能让有限的厨师高效处理大量订单,既控制成本又保证服务质量。
今天我们将深入探索Java并发编程中的核心工具------线程池和异步编程。这些技术就像是高并发系统的"效率引擎" ,掌握它们的使用和原理,将大大提升我们的系统性能和开发效率。
💡 今天你将学到:
- 🏗️ 如何用ThreadPoolExecutor打造"永不拥堵"的任务处理中心
- 🚀 如何用CompletableFuture实现"异步魔法"
- ⚡ 如何像调音师一样精准调优线程池性能
- 🛠️ 如何设计企业级的"线程池帝国"
🎯 技术深度预览
本文将从源码层面深入分析线程池实现,结合JVM调优和性能监控,为读者提供企业级并发编程解决方案。**准备好进入并发编程的奇妙世界了吗? ** 🚀
1. 线程池核心原理与底层实现
1.1 线程池的本质:资源池化模式
线程池本质上是一种资源池化模式,就像是一个"智能员工管理系统"。想象一下:
🏢 传统方式:每来一个任务就招聘一个新员工(创建线程)
- 成本高:每个员工需要办公桌、电脑等资源
- 效率低:招聘过程耗时,员工培训需要时间
- 管理难:员工数量无法控制,容易导致办公室拥挤
🎯 线程池方式:预招聘固定数量的员工,让他们轮流处理任务
- 成本低:员工复用,资源利用率高
- 效率高:员工随时待命,任务到达立即处理
- 管理易:可以精确控制员工数量,防止过载
让我们从底层实现角度深入理解这个"智能管理系统":
1.1.1 传统线程创建的问题
csharp
// 问题示例:资源浪费的线程创建方式
public class ResourceWasteExample {
public static void main(String[] args) {
// 创建1000个线程处理任务 - 内存消耗约1GB
for (int i = 0; i < 1000; i++) {
new Thread(() -> {
try {
Thread.sleep(1000); // 模拟任务处理
System.out.println("任务完成: " + Thread.currentThread().getName());
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}).start();
}
}
}核心问题(就像招聘1000个临时工):
- 内存开销:每个线程栈空间约1MB,1000个线程消耗1GB内存 💸
- 创建成本:线程创建涉及系统调用,成本高昂 ⏰
- 上下文切换:过多线程导致频繁的上下文切换 🔄
- 资源竞争:无法控制并发度,容易导致系统崩溃 💥
💡 思考题:如果让你管理一个呼叫中心,每来一个电话就招聘一个新员工,会发生什么?
1.1.2 线程池的底层优势
scss
// 线程池解决方案:资源复用与并发控制
public class ThreadPoolSolution {
public static void main(String[] args) {
// 核心线程数5,最大线程数10,内存消耗仅50MB
ExecutorService executor = Executors.newFixedThreadPool(5);
// 提交1000个任务,复用5个线程处理
for (int i = 0; i < 1000; i++) {
executor.submit(() -> {
try {
Thread.sleep(1000);
System.out.println("任务完成: " + Thread.currentThread().getName());
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
executor.shutdown();
}
}核心优势(就像有了智能员工管理系统):
- 内存效率:从1GB降低到50MB,提升20倍效率 🚀
- 性能优化:线程复用避免创建销毁开销 ⚡
- 并发控制:精确控制并发度,防止系统过载 🎯
- 资源管理:统一管理线程生命周期和状态 📊
🎉 效果对比:就像从"每来一个客户就招聘一个新员工"变成了"5个专业员工轮流服务1000个客户"!
2. ThreadPoolExecutor底层实现深度解析
2.1 核心参数与状态管理机制
ThreadPoolExecutor就像是一个智能餐厅管理系统 ,基于AQS(AbstractQueuedSynchronizer)实现,通过CAS操作 和状态位 来管理线程池状态。
🍽️ 餐厅比喻:想象线程池就是一个餐厅,有固定员工(核心线程)、临时员工(非核心线程)、订单队列(工作队列)和经理(拒绝策略)。
2.1.1 核心参数与底层实现
arduino
public ThreadPoolExecutor(
int corePoolSize, // 核心线程数
int maximumPoolSize, // 最大线程数
long keepAliveTime, // 线程存活时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 工作队列
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 拒绝策略
)底层状态管理:
java
// ThreadPoolExecutor内部状态位(简化版)
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// 状态位定义
private static final int RUNNING = -1 << COUNT_BITS; // 运行中
private static final int SHUTDOWN = 0 << COUNT_BITS; // 关闭中
private static final int STOP = 1 << COUNT_BITS; // 停止
private static final int TIDYING = 2 << COUNT_BITS; // 整理中
private static final int TERMINATED = 3 << COUNT_BITS; // 已终止2.1.2 参数调优策略与性能影响
| 参数 | 餐厅比喻 | 底层实现 | 性能影响 | 调优策略 |
|---|---|---|---|---|
| corePoolSize | 固定员工数👨🍳 | 通过CAS操作维护核心线程数 | 影响线程创建频率和内存使用 | CPU密集型=CPU核心数,IO密集型=CPU核心数×2 |
| maximumPoolSize | 最大员工数👥 | 限制最大线程数,防止资源耗尽 | 影响并发处理能力和系统稳定性 | 根据业务峰值和系统资源设置 |
| keepAliveTime | 临时员工试用期⏰ | 非核心线程空闲超时机制 | 影响内存回收和线程复用效率 | 60-300秒,根据任务特点调整 |
| workQueue | 订单队列📋 | 不同队列实现影响任务调度策略 | 影响任务排队延迟和内存使用 | 根据任务特点选择合适队列类型 |
| threadFactory | 人事部门👥 | 控制线程创建过程和属性 | 影响线程命名、优先级和异常处理 | 自定义线程名称便于监控和调试 |
| handler | 满员处理策略🚫 | 队列满时的降级策略 | 影响系统可用性和任务丢失率 | 根据业务容忍度选择合适的拒绝策略 |
💡 小贴士:就像餐厅需要根据客流量调整员工数量一样,线程池也需要根据任务特点调整参数!
2.2 线程池工作流程与底层实现
2.2.1 任务提交流程的源码分析
scss
// ThreadPoolExecutor.execute()方法的核心逻辑
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// 步骤1:如果运行线程数 < 核心线程数,创建新线程
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 步骤2:如果线程池运行中且任务成功加入队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 双重检查:如果线程池已关闭,移除任务并拒绝
if (!isRunning(recheck) && remove(command))
reject(command);
// 如果线程数为0,创建新线程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 步骤3:如果队列已满,尝试创建非核心线程
else if (!addWorker(command, false))
reject(command); // 创建失败,执行拒绝策略
}2.2.2 工作线程的生命周期管理
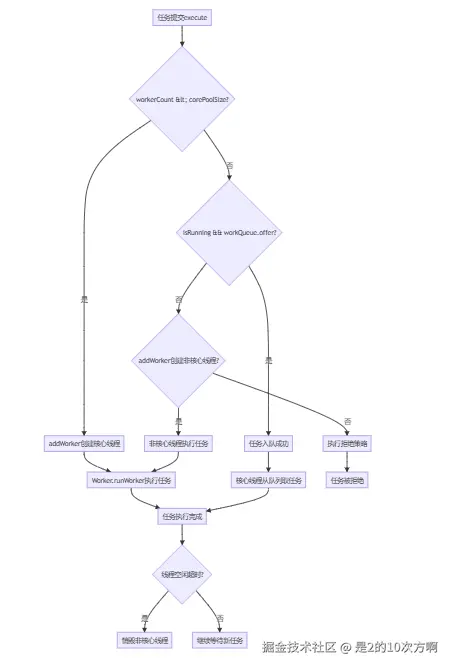
2.3 工作队列底层实现与性能分析
2.3.1 队列类型底层实现对比
| 队列类型 | 底层实现 | 并发控制 | 内存使用 | 性能特点 | 适用场景 |
|---|---|---|---|---|---|
| ArrayBlockingQueue | 数组+ReentrantLock | 单锁+条件变量 | 固定内存 | 中等性能,FIFO保证 | 任务量可控,需要内存控制 |
| LinkedBlockingQueue | 链表+双锁分离 | 双锁分离(putLock/takeLock) | 动态增长 | 高并发性能好 | 任务量不可控,高吞吐场景 |
| SynchronousQueue | 无存储,直接传递 | CAS+自旋 | 零内存 | 最高性能,零延迟 | 高并发低延迟,任务不积压 |
| PriorityBlockingQueue | 堆+ReentrantLock | 单锁+条件变量 | 动态增长 | 性能较低,支持优先级 | 任务有优先级差异 |
| DelayedWorkQueue | 堆+ReentrantLock | 单锁+条件变量 | 动态增长 | 性能较低,支持延迟 | 定时任务,延迟执行 |
2.3.2 队列选择的性能考量
java
// 线程池工厂类:根据业务场景选择最优队列
public class ThreadPoolFactory {
// 高并发Web服务:使用SynchronousQueue实现零延迟
public static ThreadPoolExecutor createWebServicePool() {
int coreCount = Runtime.getRuntime().availableProcessors();
return new ThreadPoolExecutor(
coreCount * 2, coreCount * 4, 60L, TimeUnit.SECONDS,
new SynchronousQueue<>(), // 零延迟,高并发
new NamedThreadFactory("web-service"),
new ThreadPoolExecutor.CallerRunsPolicy()
);
}
// 批处理任务:使用LinkedBlockingQueue实现高吞吐
public static ThreadPoolExecutor createBatchProcessingPool() {
int coreCount = Runtime.getRuntime().availableProcessors();
return new ThreadPoolExecutor(
coreCount, coreCount * 2, 60L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1000), // 有界队列,防止内存溢出
new NamedThreadFactory("batch-processing"),
new ThreadPoolExecutor.AbortPolicy()
);
}
// 定时任务:使用DelayedWorkQueue支持延迟执行
public static ScheduledThreadPoolExecutor createScheduledPool() {
int coreCount = Runtime.getRuntime().availableProcessors();
return new ScheduledThreadPoolExecutor(
coreCount,
new NamedThreadFactory("scheduled-task"),
new ThreadPoolExecutor.AbortPolicy()
);
}
}
// 自定义线程工厂
class NamedThreadFactory implements ThreadFactory {
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
NamedThreadFactory(String namePrefix) {
this.namePrefix = namePrefix;
}
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r, namePrefix + "-" + threadNumber.getAndIncrement());
t.setDaemon(false);
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}2.4 拒绝策略与降级机制
2.4.1 拒绝策略性能对比与选择
| 拒绝策略 | 底层实现 | 性能影响 | 业务影响 | 适用场景 |
|---|---|---|---|---|
| AbortPolicy | 直接抛出异常 | 最高性能 | 任务丢失,系统不稳定 | 快速失败,需要快速发现问题 |
| CallerRunsPolicy | 调用者线程执行 | 中等性能,可能阻塞 | 不丢失任务,但影响调用者 | 需要保证任务执行,可容忍延迟 |
| DiscardPolicy | 静默丢弃 | 高性能 | 任务丢失,无感知 | 可容忍任务丢失,追求高吞吐 |
| DiscardOldestPolicy | 移除队列头任务 | 中等性能 | 可能丢失重要任务 | 优先处理新任务,可容忍部分丢失 |
2.4.2 企业级拒绝策略实现
java
// 企业级拒绝策略:支持重试、降级和监控
public class EnterpriseRejectedExecutionHandler implements RejectedExecutionHandler {
private static final Logger logger = LoggerFactory.getLogger(EnterpriseRejectedExecutionHandler.class);
private final MeterRegistry meterRegistry;
private final int maxRetries;
public EnterpriseRejectedExecutionHandler(MeterRegistry meterRegistry, int maxRetries) {
this.meterRegistry = meterRegistry;
this.maxRetries = maxRetries;
}
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 记录拒绝指标
meterRegistry.counter("threadpool.rejected.tasks").increment();
if (r instanceof RetryableTask) {
RetryableTask retryableTask = (RetryableTask) r;
if (retryableTask.getRetryCount() < maxRetries) {
// 指数退避重试
long delay = (long) Math.pow(2, retryableTask.getRetryCount()) * 100;
scheduleRetry(executor, retryableTask, delay);
return;
}
}
// 降级处理
handleDegradation(r, executor);
}
private void scheduleRetry(ThreadPoolExecutor executor, RetryableTask task, long delay) {
CompletableFuture.delayedExecutor(delay, TimeUnit.MILLISECONDS)
.execute(() -> {
try {
executor.execute(task);
} catch (RejectedExecutionException e) {
// 重试失败,执行降级
handleDegradation(task, executor);
}
});
}
private void handleDegradation(Runnable r, ThreadPoolExecutor executor) {
logger.warn("任务执行降级处理: {}", r.toString());
// 可以发送到死信队列、持久化存储等
meterRegistry.counter("threadpool.degraded.tasks").increment();
}
}
// 可重试任务接口
interface RetryableTask extends Runnable {
int getRetryCount();
void incrementRetryCount();
}3. 线程池监控与性能调优
3.1 企业级监控体系
3.1.1 核心监控指标与JVM调优
java
// 企业级线程池监控系统
@Component
public class ThreadPoolMonitor {
private final MeterRegistry meterRegistry;
private final Map<String, ThreadPoolExecutor> monitoredPools = new ConcurrentHashMap<>();
@PostConstruct
public void startMonitoring() {
// 注册核心指标
registerCoreMetrics();
// 启动实时监控
startRealTimeMonitoring();
}
private void registerCoreMetrics() {
// 线程池核心指标
Gauge.builder("threadpool.core.size")
.description("核心线程数")
.register(meterRegistry, this, ThreadPoolMonitor::getCorePoolSize);
Gauge.builder("threadpool.active.count")
.description("活跃线程数")
.register(meterRegistry, this, ThreadPoolMonitor::getActiveCount);
Gauge.builder("threadpool.queue.size")
.description("队列大小")
.register(meterRegistry, this, ThreadPoolMonitor::getQueueSize);
// 性能指标
Timer.builder("threadpool.task.execution.time")
.description("任务执行时间")
.register(meterRegistry);
}
// 线程池健康检查
public ThreadPoolHealthStatus checkHealth(String poolName) {
ThreadPoolExecutor executor = monitoredPools.get(poolName);
if (executor == null) {
return ThreadPoolHealthStatus.UNKNOWN;
}
double queueUsage = (double) executor.getQueue().size() /
Math.max(executor.getQueue().remainingCapacity(), 1);
double threadUsage = (double) executor.getActiveCount() / executor.getMaximumPoolSize();
if (queueUsage > 0.9 || threadUsage > 0.95) {
return ThreadPoolHealthStatus.CRITICAL;
} else if (queueUsage > 0.7 || threadUsage > 0.8) {
return ThreadPoolHealthStatus.WARNING;
}
return ThreadPoolHealthStatus.HEALTHY;
}
}
// 线程池健康状态枚举
enum ThreadPoolHealthStatus {
HEALTHY, WARNING, CRITICAL, UNKNOWN
}3.2 性能调优与JVM优化
3.2.1 基于业务场景的参数调优
typescript
// 智能线程池配置器
public class SmartThreadPoolConfigurer {
// 根据系统负载动态调整线程池参数
public static ThreadPoolExecutor createAdaptivePool(TaskType taskType) {
int coreCount = Runtime.getRuntime().availableProcessors();
SystemMetrics metrics = SystemMetricsCollector.getCurrentMetrics();
return switch (taskType) {
case CPU_INTENSIVE -> createCpuIntensivePool(coreCount, metrics);
case IO_INTENSIVE -> createIoIntensivePool(coreCount, metrics);
case MIXED -> createMixedTaskPool(coreCount, metrics);
case BATCH_PROCESSING -> createBatchProcessingPool(coreCount, metrics);
};
}
private static ThreadPoolExecutor createCpuIntensivePool(int coreCount, SystemMetrics metrics) {
// CPU密集型:线程数=CPU核心数,避免上下文切换
return new ThreadPoolExecutor(
coreCount, coreCount, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(),
new NamedThreadFactory("cpu-intensive"),
new ThreadPoolExecutor.CallerRunsPolicy()
);
}
private static ThreadPoolExecutor createIoIntensivePool(int coreCount, SystemMetrics metrics) {
// IO密集型:线程数=CPU核心数×2-4,根据IO等待时间调整
int threadMultiplier = calculateIoThreadMultiplier(metrics);
return new ThreadPoolExecutor(
coreCount * threadMultiplier,
coreCount * threadMultiplier * 2,
60L, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(1000),
new NamedThreadFactory("io-intensive"),
new ThreadPoolExecutor.CallerRunsPolicy()
);
}
// JVM调优建议
public static JvmTuningRecommendations getJvmTuningRecommendations() {
return JvmTuningRecommendations.builder()
.heapSize("-Xms4g -Xmx8g") // 根据线程池规模调整堆大小
.gcAlgorithm("-XX:+UseG1GC") // 使用G1GC减少停顿时间
.threadStackSize("-Xss256k") // 减少线程栈大小
.metaspaceSize("-XX:MetaspaceSize=256m")
.build();
}
}
// 任务类型枚举
enum TaskType {
CPU_INTENSIVE, IO_INTENSIVE, MIXED, BATCH_PROCESSING
}
// JVM调优建议
record JvmTuningRecommendations(
String heapSize,
String gcAlgorithm,
String threadStackSize,
String metaspaceSize
) {
static Builder builder() {
return new Builder();
}
static class Builder {
private String heapSize;
private String gcAlgorithm;
private String threadStackSize;
private String metaspaceSize;
Builder heapSize(String heapSize) {
this.heapSize = heapSize;
return this;
}
Builder gcAlgorithm(String gcAlgorithm) {
this.gcAlgorithm = gcAlgorithm;
return this;
}
Builder threadStackSize(String threadStackSize) {
this.threadStackSize = threadStackSize;
return this;
}
Builder metaspaceSize(String metaspaceSize) {
this.metaspaceSize = metaspaceSize;
return this;
}
JvmTuningRecommendations build() {
return new JvmTuningRecommendations(heapSize, gcAlgorithm, threadStackSize, metaspaceSize);
}
}
}3.2.2 动态调整线程池
ini
// 动态调整线程池参数
public class DynamicThreadPoolAdjuster {
private final ThreadPoolExecutor executor;
private final ScheduledExecutorService scheduler;
public DynamicThreadPoolAdjuster(ThreadPoolExecutor executor) {
this.executor = executor;
this.scheduler = Executors.newSingleThreadScheduledExecutor();
startMonitoring();
}
private void startMonitoring() {
scheduler.scheduleAtFixedRate(() -> {
adjustThreadPool();
}, 0, 10, TimeUnit.SECONDS);
}
private void adjustThreadPool() {
int activeCount = executor.getActiveCount();
int queueSize = executor.getQueue().size();
int corePoolSize = executor.getCorePoolSize();
int maxPoolSize = executor.getMaximumPoolSize();
// 如果队列积压严重,增加核心线程数
if (queueSize > 50 && corePoolSize < maxPoolSize) {
int newCoreSize = Math.min(corePoolSize + 2, maxPoolSize);
executor.setCorePoolSize(newCoreSize);
System.out.println("增加核心线程数到: " + newCoreSize);
}
// 如果线程空闲过多,减少核心线程数
if (activeCount < corePoolSize / 2 && corePoolSize > 2) {
int newCoreSize = Math.max(corePoolSize - 1, 2);
executor.setCorePoolSize(newCoreSize);
System.out.println("减少核心线程数到: " + newCoreSize);
}
}
public void shutdown() {
scheduler.shutdown();
}
}4. CompletableFuture响应式编程深度解析
4.1 CompletableFuture底层实现原理
CompletableFuture就像是异步编程的魔法师 🧙♂️,基于ForkJoinPool 和CAS操作实现,提供了强大的响应式编程能力:
🎭 魔法比喻:想象CompletableFuture就像一个魔法师,可以同时施展多个魔法(异步任务),并且能够将魔法的结果组合成更强大的魔法!
4.1.1 底层实现机制
typescript
// CompletableFuture核心实现原理(简化版)
public class CompletableFuture<T> implements Future<T>, CompletionStage<T> {
// 结果存储
volatile Object result;
// 等待线程栈
volatile Completion stack;
// 异步执行,使用ForkJoinPool.commonPool()
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier) {
return asyncSupplyStage(ASYNC, supplier);
}
// 链式调用实现
public <U> CompletableFuture<U> thenApply(Function<? super T, ? extends U> fn) {
return uniApplyStage(null, fn);
}
// 组合操作实现
public <U, V> CompletableFuture<V> thenCombine(
CompletionStage<? extends U> other,
BiFunction<? super T, ? super U, ? extends V> fn) {
return biApplyStage(null, other, fn);
}
}4.1.2 响应式编程模式
typescript
// 响应式编程示例:异步任务链
public class ReactiveProgrammingExample {
public CompletableFuture<String> processUserRequest(String userId) {
return CompletableFuture
.supplyAsync(() -> fetchUserData(userId)) // 异步获取用户数据
.thenCompose(user -> validateUser(user)) // 异步验证用户
.thenCompose(user -> enrichUserData(user)) // 异步丰富用户数据
.thenApply(user -> formatResponse(user)) // 同步格式化响应
.exceptionally(this::handleError); // 异常处理
}
private CompletableFuture<User> fetchUserData(String userId) {
return CompletableFuture.supplyAsync(() -> {
// 模拟数据库查询
return userRepository.findById(userId);
});
}
private CompletableFuture<User> validateUser(User user) {
return CompletableFuture.supplyAsync(() -> {
if (user == null) {
throw new UserNotFoundException("User not found");
}
return user;
});
}
}4.2 高级异步编程模式
4.2.1 响应式编程模式
scss
// 响应式编程:事件驱动的异步处理
public class ReactiveAsyncProcessor {
// 背压控制:限制并发任务数量
private final Semaphore concurrencyLimiter = new Semaphore(10);
public CompletableFuture<ProcessResult> processWithBackpressure(ProcessRequest request) {
return CompletableFuture
.supplyAsync(() -> {
try {
concurrencyLimiter.acquire(); // 获取信号量
return processRequest(request);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("Process interrupted", e);
} finally {
concurrencyLimiter.release(); // 释放信号量
}
})
.handle((result, throwable) -> {
if (throwable != null) {
return ProcessResult.error(throwable);
}
return ProcessResult.success(result);
});
}
// 超时控制:防止任务无限等待
public CompletableFuture<String> processWithTimeout(String input, Duration timeout) {
return CompletableFuture
.supplyAsync(() -> processInput(input))
.completeOnTimeout("timeout_result", timeout.toMillis(), TimeUnit.MILLISECONDS)
.orTimeout(timeout.toMillis(), TimeUnit.MILLISECONDS);
}
}4.2.2 企业级异步处理模式
kotlin
// 企业级异步处理:支持重试、熔断、监控
@Component
public class EnterpriseAsyncProcessor {
private final CircuitBreaker circuitBreaker;
private final RetryTemplate retryTemplate;
private final MeterRegistry meterRegistry;
public CompletableFuture<ApiResponse> processWithResilience(ApiRequest request) {
return CompletableFuture
.supplyAsync(() -> {
// 熔断器保护
return circuitBreaker.executeSupplier(() -> {
// 重试机制
return retryTemplate.execute(context -> {
return callExternalApi(request);
});
});
})
.thenApply(this::transformResponse)
.whenComplete((result, throwable) -> {
// 监控指标
if (throwable != null) {
meterRegistry.counter("api.call.failure").increment();
} else {
meterRegistry.counter("api.call.success").increment();
}
});
}
}4.3 企业级异常处理与容错机制
4.3.1 分层异常处理策略
kotlin
// 企业级异常处理:分层容错机制
public class EnterpriseExceptionHandler {
// 业务异常处理
public CompletableFuture<BusinessResult> handleBusinessException(CompletableFuture<BusinessData> future) {
return future
.handle((data, throwable) -> {
if (throwable instanceof BusinessException) {
return BusinessResult.error((BusinessException) throwable);
} else if (throwable != null) {
return BusinessResult.error(new BusinessException("Unexpected error", throwable));
}
return BusinessResult.success(data);
})
.exceptionally(throwable -> {
// 最终兜底处理
logger.error("Unexpected error in business processing", throwable);
return BusinessResult.error(new BusinessException("System error"));
});
}
// 重试机制
public CompletableFuture<String> processWithRetry(String input) {
return CompletableFuture
.supplyAsync(() -> processInput(input))
.handle((result, throwable) -> {
if (throwable != null && isRetryable(throwable)) {
return retryProcess(input, 3);
}
return CompletableFuture.completedFuture(result);
})
.thenCompose(Function.identity());
}
}5. 企业级高并发系统架构设计
5.1 微服务线程池架构
kotlin
// 企业级微服务线程池管理
@Configuration
public class ThreadPoolConfiguration {
@Bean("webRequestPool")
public ThreadPoolExecutor webRequestPool() {
return ThreadPoolFactory.createWebServicePool();
}
@Bean("databasePool")
public ThreadPoolExecutor databasePool() {
return ThreadPoolFactory.createBatchProcessingPool();
}
@Bean("externalServicePool")
public ThreadPoolExecutor externalServicePool() {
return ThreadPoolFactory.createIoIntensivePool();
}
}
// 服务层使用示例
@Service
public class OrderService {
@Autowired
@Qualifier("webRequestPool")
private ThreadPoolExecutor webRequestPool;
@Autowired
@Qualifier("databasePool")
private ThreadPoolExecutor databasePool;
public CompletableFuture<OrderResponse> processOrder(OrderRequest request) {
return CompletableFuture
.supplyAsync(() -> validateOrder(request), webRequestPool)
.thenCompose(this::saveOrder)
.thenCompose(this::sendNotification)
.exceptionally(this::handleOrderError);
}
private CompletableFuture<Order> saveOrder(Order order) {
return CompletableFuture.supplyAsync(() -> {
return orderRepository.save(order);
}, databasePool);
}
}6. 企业级最佳实践与性能调优
6.1 核心最佳实践
6.1.1 线程池设计原则
- 资源隔离:不同业务使用独立线程池,避免相互影响
- 参数调优:基于业务特点和系统负载动态调整参数
- 监控告警:建立完善的监控体系,及时发现性能问题
- 优雅关闭:确保系统关闭时线程池能够正确释放资源
6.1.2 异步编程最佳实践
- 合理使用异步:不是所有任务都需要异步执行
- 异常处理:建立完善的异常处理和降级机制
- 资源管理:避免线程泄漏和资源浪费
- 性能监控:监控异步任务的执行时间和成功率
6.2 性能调优策略
6.2.1 JVM调优参数
ruby
# 生产环境JVM调优建议
-Xms4g -Xmx8g # 堆内存设置
-XX:+UseG1GC # 使用G1垃圾收集器
-XX:MaxGCPauseMillis=200 # 最大GC停顿时间
-Xss256k # 线程栈大小
-XX:MetaspaceSize=256m # 元空间大小
-XX:+HeapDumpOnOutOfMemoryError # OOM时生成堆转储6.2.2 监控指标
- 线程池指标:活跃线程数、队列大小、任务执行时间
- 系统指标:CPU使用率、内存使用率、GC频率
- 业务指标:请求响应时间、错误率、吞吐量
7. 总结
🎯 核心技术要点
- 底层原理:深入理解ThreadPoolExecutor的AQS实现和CAS操作
- 性能优化:掌握基于业务场景的参数调优和JVM优化
- 企业应用:学会设计高可用的线程池架构和监控体系
- 响应式编程:掌握CompletableFuture的响应式编程模式
🚀 进阶学习方向
- 源码分析:深入研究JDK并发包的源码实现
- 性能调优:学习JVM调优和系统性能优化技术
- 架构设计:掌握高并发系统的整体架构设计
- 新技术:关注Project Loom等新并发技术
掌握线程池和异步编程是企业级Java开发的核心技能,通过深入理解底层原理和最佳实践,能够构建高性能、高可用的并发系统。希望这篇文章能帮助你在并发编程的道路上更进一步! 🚀
本文使用 markdown.com.cn 排版