前言
我是[提前退休的java猿](https://juejin.cn/user/465848660928872 "https://juejin.cn/user/465848660928872"),一名7年java开发经验的开发组长,分享工作中的各种问题!(抖音、公众号同号)
25年12月25日上午,数据库服务器CPU 100%,最终导致某个物品领取业务损失1万块。如果之前有看过我文章的应该就知道 CPU 100% 已经不是第一出现了。
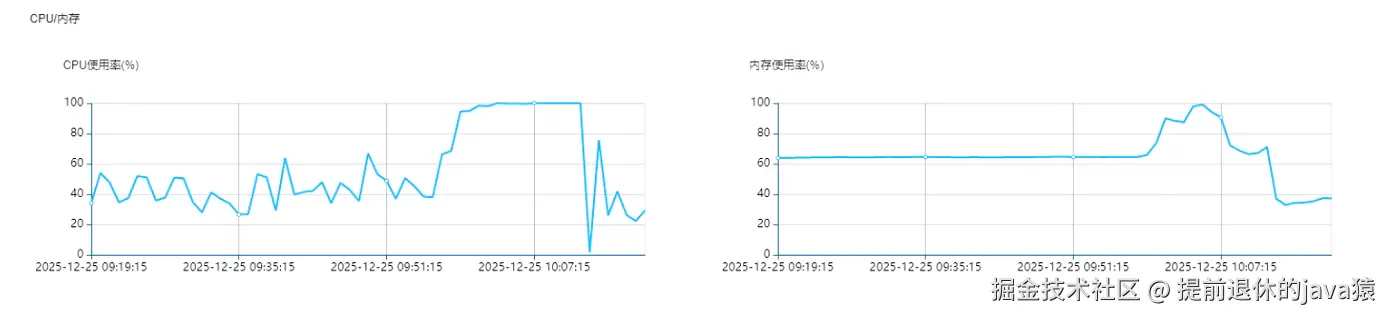 今天先从代码上复盘一下,为什么数据库
今天先从代码上复盘一下,为什么数据库CPU100% 之后,物品就超领了❓ 首先想到的肯定是代码存在问题,今天就先看看代码上是否存在问题。
🔈负责的同事这样说反馈的:同一个事务中先库存扣减(A操作):update t set num = num -1 where num >0 然后插入领取记录(B操作):insert xx。
❗最终数据结果就是insert 的领取数量,大于了库存总数。所以同事就反馈A没执行,B却执行成功了非常的诡异。
说实话到现在为止我还是有点怀疑他写的代码,数据库的原子性都被破坏了还是很恐怖的😨,今天的文章主要看看排查出事务的原子性破坏坏的问题。
(ps:🧛🏾♀️这是一篇没有找到答案的技术博客)
抽奖超领复盘
CUP为什么飙高的这个问题今天就不是我们要排查的问题,所以代码的性能今天就不讨论了。今天主要分析物品超领的问题,到底是代码问题导致的事务失效,还是有其他地方在插入领取记录或者是做了库存回滚(插入记录又回滚)。还是真的是事务的原子性被破坏了。
🔊环境介绍:数据库使用的国产的人大金仓,使用的是主从架构
一、核心代码分析
从controller 到service 的代码我都看了,本来要把这部分代码贴出来的还是算了。无限简化之后就是下面的逻辑
controller 层代码:
java
@RedisRateLimiter(value = 100,limit = 1)
@PostMapping(value = "/grabCoupon")
public Res<?> equityClaim(@RequestBody GrabCouponReqEx req) {
.........
return service.grabCouponTrans(req);
}service 层代码:
java
@Transactional(propagation = Propagation.REQUIRED,rollbackFor = RuntimeException.class)
@Override
public Result<?> grabCouponTrans(GrabCouponReqEx req) {
// 对所有代码进行 try,然后抛出RuntimException 让框架回滚
try{
//💦当然事务中还有很多查询校验的逻辑这儿就省略了
.............................
//✅ A操作:库存扣减,这个地方对库存-1,如果更新行数大与0返回true
//UPDATE t SET num = num -1 WHERE id = #{id} AND num > 0;
boolean isok = xxDao.reduceInventoryNoCompleted(id);
if (isok) {
// ✅B操作:插入领取记录,插入成功返回 true
Boolean insetSuc = insert(record);
// ...................... ❌HTTP 写在事务中
Result<?> result1 = XXHttpUtils.preExamination(claimReq);
//同步更新核销数据
if (!isokDetail) {
logger.error("【反馈数据更新同步异常】");
XXHttpUtils.saveLogsNoSupp(xx);
}
return result;
}
throw new RuntimeException("更新配置权益核销状态失败!");
}catch (Exception e){
// ❗这也是一个问题代码呀,还是用log.error("ss",e)
e.printStackTrace();
//........ redis 信息回滚操作.........
throw e;
}
}基础稍微扎实一点的可以看出上面的代码逻辑是不会出现库存被扣成负数的情况,即使在高并发下,因为update By id 操作本身会进行行锁。所以在库存 =1的情况下,多个请求更新也只有一个能更新成功(更新行数=1)。
事务失效?
- 捕捉
RuntimeException事务导致失效:注解上面捕捉的是RuntimeException,但是捕捉了Exceptioon 又抛出了。如果抛出去的异常没有继成RuntimeException,事务就会失效,也不会出现 A没执行、B却执行成功的情况。 - ❌
this调用insert导致事务失效:这个观点我在抖音评论下面看到好几个人都这么说。这个观点是不对的,首先调用insert方法外层方法(grabCouponTrans)是被@Transactional标记的,并且也是通过spring管理的容器对象管理的,所以不会因为在事务方法内部进行了this调用导致这个this调用方法不在事务内。只是这个this调用的方法没有被代理,默认加入到外层方法的事务里面了。
主从读写不一致?
这个问题正常来说开启了非只读事务之后,应该读写都走的是主库。但是我debug了一下 事务的读取居然是走的从库??
js
[2026-01-04 23:32:42] [230] [com.kingbase8.dispatcher.executor.DispatchAbstractStatement-->executeTemplet]
Send to slave session: (session={com.kingbase8.dispatcher.entity.DispatchConnection@e3cc839}
url={jdbc:kingbase8://从库IP:从库port/ghbase}
st={SELECT id,..... FROM xx_table WHERE id = 5099} _sqlType={select})然后写库又是用主库
js
[2026-01-04 23:39:23] [230] [com.kingbase8.dispatcher.executor.DispatchAbstractStatement-->executeTemplet]
Send to master session: (session={com.kingbase8.dispatcher.entity.DispatchConnection@e3cc839}
url={jdbc:kingbase8://主库iP:port/ghbase?_hostLoadRate=0} st={INSERT INTO xx_table (id....) VALUES (...........)
RETURNING "id"} _sqlType={insert or delete or update})我以为这就是问题源头了😱,事务里面得查询会走从库。当我继续debug得时候,发现在执行事务注解标记得方法时候,如果没有执行
更新SQL(DML)那么查询就一直走从库,直到执行更新数据SQL(DML)的时候,后面的查询也都走主库了。
二、异常日志分析
1.偶尔出现任何业务: Couldn't commit jdbc connection. FATAL: terminating connection due to conflict with recovery
这个异常时还没到业务高峰的时候,这个问题就是Quartz在维护内部状态的时候出现的报错。
js
2025-12-25 01:01:01.581 [QuartzScheduler_MyScheduler-cdszgh-szhpt-41766404430759_ClusterManager] ERROR o.s.s.q.LocalDataSourceJobStore - [manage,3941] - ClusterManager: Error managing cluster: Couldn't commit jdbc connection. FATAL: terminating connection due to conflict with recovery
Detail: User was holding a relation lock for too long.
Hint: In a moment you should be able to reconnect to the database and repeat your command.
org.quartz.JobPersistenceException: Couldn't commit jdbc connection. FATAL: terminating connection due to conflict with recovery
Detail: User was holding a relation lock for too long.
Hint: In a moment you should be able to reconnect to the database and repeat your command.
at org.quartz.impl.jdbcjobstore.JobStoreSupport.commitConnection(JobStoreSupport.java:3749)
at org.quartz.impl.jdbcjobstore.JobStoreSupport.doCheckin(JobStoreSupport.java:3331)
at org.quartz.impl.jdbcjobstore.JobStoreSupport$ClusterManager.manage(JobStoreSupport.java:3935)
at org.quartz.impl.jdbcjobstore.JobStoreSupport$ClusterManager.run(JobStoreSupport.java:3972)✔原因分析
PostgreSQL 数据库因为检测到 "relation lock 持有时间过长" 而主动终止了连接。这是 PostgreSQL 在主从复制(流复制)或恢复模式下的一种保护机制。
💦引发这个问题的原因可能是:PostgreSQL 备机恢复压力大、网络延迟 导致复制缓慢、数据库服务器资源不足
-
PostgreSQL 恢复冲突处理
- 当 PostgreSQL 备机正在执行 WAL 恢复时
- 如果有长时间的事务锁定了某些表(relation lock)
- 主从同步可能会被阻塞
- 为了确保数据一致性,PostgreSQL 会强制终止持有锁过长的会话
-
Quartz 集群管理机制
ClusterManager线程定期检查集群状态(默认每 15-30 秒)- 需要获取数据库锁来维护集群一致性
- 如果这个操作耗时过长,就会触发 PostgreSQL 的保护机制
2.(各业务频繁出现)org.apache.catalina.connector.ClientAbortException: java.io.IOException: 断开的管道
这个问题出现在了数据库服务器CPU已经是拉满的状态了,应该是用户的请求已经开始阻塞了
js
org.apache.catalina.connector.ClientAbortException: java.io.IOException: 断开的管道
at org.apache.catalina.connector.OutputBuffer.realWriteBytes(OutputBuffer.java:342)
at org.apache.catalina.connector.OutputBuffer.flushByteBuffer(OutputBuffer.java:777)
at org.apache.catalina.connector.OutputBuffer.append(OutputBuffer.java:674)
at org.apache.catalina.connector.OutputBuffer.writeBytes(OutputBuffer.java:377)
at org.apache.catalina.connector.OutputBuffer.write(OutputBuffer.java:355)
at org.apache.catalina.connector.CoyoteOutputStream.write(CoyoteOutputStream.java:101)
at .......................
at......................... com.fasterxml.jackson.databind.ser.std.BeanSerializerBase.serializeFields(BeanSerializerBase.java:774)
at com.fasterxml.jackson.databind.ser.BeanSerializer.serialize(BeanSerializer.java:178)
at com.fasterxml.jackson.databind.ser.DefaultSerializerProvider._serialize(DefaultSerializerProvider.java:480)
at com.fasterxml.jackson.databind.ser.DefaultSerializerProvider.serializeValue(DefaultSerializerProvider.java:319)
at com.fasterxml.jackson.databind.ObjectWriter$Prefetch.serialize(ObjectWriter.java:1518)
at com.fasterxml.jackson.databind.ObjectWriter.writeValue(ObjectWriter.java:1007)✔原因分析
这是正常的用户行为导致的异常,不是程序bug。应该优雅处理而不是报ERROR日志,避免日志文件被这类无关紧要的错误信息淹没。
3.(各业务频繁出现)Cause: java.sql.SQLException: Send to master from switch slave retry failare maxtimes still SQLException: FATAL: terminating connection due to administrator command
这个报错也是集中出现在CPU拉满的情况,导致很多查询就直接报错了
js
Cause: java.sql.SQLException: Send to master from switch slave retry failare maxtimes still SQLException: FATAL: terminating connection due to administrator command
; Send to master from switch slave retry failare maxtimes still SQLException: FATAL: terminating connection due to administrator command; nested exception is java.sql.SQLException: Send to master from switch slave retry failare maxtimes still SQLException: FATAL: terminating connection due to administrator command
at org.springframework.jdbc.support.SQLStateSQLExceptionTranslator.doTranslate(SQLStateSQLExceptionTranslator.java:107)
at org.springframework.jdbc.support.AbstractFallbackSQLExceptionTranslator.translate(AbstractFallbackSQLExceptionTranslator.java:70)
at org.springframework.jdbc.support.AbstractFallbackSQLExceptionTranslator.translate(AbstractFallbackSQLExceptionTranslator.java:79)
at org.springframework.jdbc.support.AbstractFallbackSQLExceptionTranslator.translate(AbstractFallbackSQLExceptionTranslator.java:79)
at org.mybatis.spring.MyBatisExceptionTranslator.translateExceptionIfPossible(MyBatisExceptionTranslator.java:91)
at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:441)
at com.sun.proxy.$Proxy177.selectList(Unknown Source)
at org.mybatis.spring.SqlSessionTemplate.selectList(SqlSessionTemplate.java:224)
at com.baomidou.mybatisplus.core.override.MybatisMapperMethod.executeForMany(MybatisMapperMethod.java:166)
at com.baomidou.mybatisplus.core.override.MybatisMapperMethod.execute(MybatisMapperMethod.java:77)
at com.baomidou.mybatisplus.core.override.MybatisMapperProxy$PlainMethodInvoker.invoke(MybatisMapperProxy.java:148)
at com.baomidou.mybatisplus.core.override.MybatisMapperProxy.invoke(MybatisMapperProxy.java:89)
at com.sun.proxy.$Proxy386.findStatisticsVoByActivityIdList(Unknown Source)
at
...................业务代码方法的一些方法栈信息(省略).............................................✔原因分析
- 从库延迟严重,查询超时
- 主库负载过高,无法处理请求
- 网络问题导致连接不稳定
- 数据库管理员执行了维护操作(如:重启、kill连接、数据库自动kill长时间运行的查询)
❗错误:"terminating connection due to administrator command" → DBA可能执行了:SELECT pg_terminate_backend(pid); → 或数据库自动kill了长时间运行的查询
4. (各业务频繁出现)java.net.SocketTimeoutException: Read timed out
在CPU拉满的情况下出现大量的read timed out读取数据库响应的时候就超时了。 在业务低峰的时候commit 事务的时候也出现过这个问题,增加socket超时时间可以降低这个错误的发生。
下面的select语句也是 领取事务中的 更新数据前的一些前置查询SQL
js
2025-12-25 10:50:12.101 [http-nio-8077-exec-78] ERROR druid.sql.Statement - [statementLogError,148] - {conn-10567, pstmt-277353} execute error.
SELECT * from 待领取的物品数据
com.kingbase8.util.KSQLException: An I/O error occurred while sending to the backend.
at com.xx.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:428)
at com.xx.jdbc.KbStatement.executeInternal_(KbStatement.java:784)
at com.xx.jdbc.KbStatement.execute(KbStatement.java:676)
at com.kingbase8.jdbc.KbPreparedStatement.executeWithFlags(KbPreparedStatement.java:286)
at com.xx.jdbc.KbPreparedStatement.execute(KbPreparedStatement.java:265)
Caused by: java.net.SocketTimeoutException: Read timed out
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
at java.net.SocketInputStream.read(SocketInputStream.java:171)
at java.net.SocketInputStream.read(SocketInputStream.java:141)
at com.xx.core.VisibleBufferedInputStream.readMore(VisibleBufferedInputStream.java:210)✔原因分析
这个问题以前也是一直都存在的,CPU空闲的也会出现这个问题,现在CPU打满之后就出现大量的请求
5.💢(各业务频繁出现)om.kingbase8.util.KSQLException: This _connection has been closed.
这个错是比较关键的错误了!涉及报错的SQL基本就是我们领取物品事务中的SQL了。在日志文件中在CPU打满这段时间内出现得非常之多。
js
2025-12-25 10:49:56.569 [http-nio-8077-exec-41] ERROR druid.sql.Statement -
[statementLogError,148] - {conn-10529, pstmt-276494} execute error.
INSERT INTO xx_lottery_xx (xx, xx, xx,) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
com.xx.util.KSQLException: This _connection has been closed.
at com.xx.jdbc.KbConnection.checkIsClosed(KbConnection.java:1401)
at com.xx.jdbc.KbConnection.getAutoCommit(KbConnection.java:1329)
at com.xx.jdbc.KbStatement.executeInternal_(KbStatement.java:735)
at com.xx.jdbc.KbStatement.execute(KbStatement.java:676)
at com.xx.jdbc.KbPreparedStatement.executeWithFlags(KbPreparedStatement.jav
........insert 领取记录..............................
ERROR c.a.d.p.DruidDataSource - [recycle,2146] - recycle error
com.xx.util.KSQLException: This _connection has been closed.
at com.xx.jdbc.KbConnection.checkIsClosed(KbConnection.java:1401)
at com.xx.jdbc.KbConnection.setAutoCommit(KbConnection.java:1288)
at com.xx.dispatcher.entity.DispatchConnection.setAutoCommit(DispatchConnection.java:1115)
at com.alibaba.druid.filter.FilterChainImpl.connection_setAutoCommit(FilterChainImpl.java:699)
at com.alibaba.druid.filter.logging.LogFilter.connection_setAutoCommit(LogFilter.java:467)
at com.alibaba.druid.filter.FilterChainImpl.connection_setAutoCommit(FilterChainImpl.java:694)
at com.alibaba.druid.filter.FilterAdapter.connection_setAutoCommit(FilterAdapter.java:964)
at com.alibaba.druid.filter.FilterChainImpl.connection_setAutoCommit(FilterChainImpl.java:694)
at com.alibaba.druid.proxy.jdbc.ConnectionProxyImpl.setAutoCommit(ConnectionProxyImpl.java:416)
at com.alibaba.druid.pool.DruidConnectionHolder.reset(DruidConnectionHolder.java:387)
at com.alibaba.druid.pool.DruidDataSource.recycle(DruidDataSource.java:2053)
at com.alibaba.druid.pool.DruidPooledConnection.recycle(DruidPooledConnection.java:343)
at com.alibaba.druid.filter.FilterChainImpl.dataSource_recycle(FilterChainImpl.java:5047)
2025-12-25 10:44:22.908 [http-nio-8077-exec-149] ERROR o.s.t.i.TransactionInterceptor -
[completeTransactionAfterThrowing,680] - Application exception overridden by rollback exception✔原因分析
和上面的报错很类似,只是在插入数据的时候发现连接断开了,这时候回滚也是没办法的。
三、数据库日志分析
这个日志文件是我们部门经理发出来的,什么级别的日志咱也不知道,应该是记录的慢SQL的吧或者报错SQL日志的吧。
直接看业务高峰时数据库的异常日志,就只看领取事务中相关SQL的日志
情况一:
【1817689】数据库后端进程ID ,当前事务的就只有库存扣减的日志,执行完扣减之后就 直接出现 unexpected EOF (没有@Transactional 方法 中更新库存前的查询的日志说明查询是走了从库)
而且这个【1817689】进程在抛错之后,在日志文件中的下文就没有收到这个进程了(执行了库存扣减然后就直接报错被销毁了❓)
js
2025-12-25 10:26:08.825 CST [1817689] LOG:duration: 3538.580 ms execute <unnamed>:
UPDATE xx SET ...(库存扣减SQL)
2025-12-25 10:26:08.825 CST [1817689] DETAIL: parameters: $1 = '12783'
2025-12-25 10:26:08.825 CST [1817689] LOG:
unexpected EOF on client connection with an open transaction情况二:
1872365 日志中搜索1872365进程,只有下面两行🌚,就很奇怪,也没有报错也没有insert记录的日志。
当时1872365 进程前后都有其他日志(是不是代表这个进程进行了多次会话,对应的领取业务也是走通了的❓)
js
2025-12-25 10:26:31.591 CST [1872365] LOG: duration: 3236.489 ms execute <unnamed>:
UPDATE xx SET ...(库存扣减SQL)
2025-12-25 10:26:31.591 CST [1872365] DETAIL: parameters: $1 = '12786'🎃完全看不懂这个日志了,被@Transactional 标记的方法正常逻辑是 库存扣减、然后插入领取记录。但是这个数据库日志只有库存扣减的日志。
四、错误日志归纳总结分析
应用程序的错误日志(库存扣减出现两次报错):
js
1. 2025-12-25 10:26:51.730 库存扣减异常(This _connection has been closed.)程序发起回滚失败( [completeTransactionAfterThrowing,680] - Application exception overridden by rollback exception)
2. 2025-12-25 10:28:28.297 库存扣减异常同上数据库日志(库存扣减出现两次日志)一次:
js
1. 2025-12-25 10:26:08.825 CST [1817689] LOG:duration: 3538.580 ms execute <unnamed>:
UPDATE xx SET ...(库存扣减SQL) 出现:unexpected EOF on client connection with an open transaction
2. 2025-12-25 10:26:31.591 CST [1872365] duration: 3236.489 ms❌数据库的日志库存扣减的日志只有两条,但是数据库中的领取记录有很多,说明这个日志应该是只记录了部分日志。可能是记录的慢SQL😂
📢但是超领的数据远不止两条数据,说明这些超领的数据在执行代码的时候,也是没有抛错的,所以想要通过日志去定位问题。暂时是不行的
总结
下面的代码,正常来讲不管有没有加事务,都不可能出现 库存扣减数量 大于插入记录数量。
java
//✅ A操作:库存扣减,这个地方对库存-1,如果更新行数大与0返回true
//UPDATE t SET num = num -1 WHERE id = #{id} AND num > 0;
boolean isok = xxDao.reduceInventoryNoCompleted(id);
if (isok) {
// ✅B操作:插入领取记录,插入成功返回
true Boolean insetSuc = insert(record);从日志上应用上的日志来看,确实有事务报错,阻塞,以及不能回滚的问题,好像也不能够解释 领取的记录量大于库存总数的问题。
我在代码中也没有找到库存回滚+1 的代码,所以目前为止我从代码层面和日志上都不能找到到底什么问题引起的。
之前抖音上有网友说遇到过这个问题,因为主从延迟的问题。
Couldn't commit jdbc connection. FATAL: terminating connection due to conflict with recovery
这个问题,我也问了一下deepSeek,说的可能会破坏事务的原子性(可信度有待考证)
🙈抱歉这是一篇没有答案的技术博客,后续如果我也会持续跟进这个问题