目录
本篇我们直接使用ImageNet竞赛第一名何凯明训练好的经典的ResNet模型来改进我们的食物分类案例
而何凯明训练的18层残差网络模型输出是用来分类1000种物体而不是我们食物分类案例的20所以我们是需要再最后的输出层进行调整,这里我们有两种方法:①直接修改最后一层网络的输出②再添加一层网络
一.直接修改最后一层
1.导入模型
torchvision库中有大量的优秀的视觉方面的已经训练好的模型,torch.nn则倾向于自己搭建网络
python
import torchvision.models as models我们直接导入何凯明的resnet18模型,注意这里的模型是需要网络下载的
python
resnet_model=models.resnet18(weights=models.ResNet18_Weights.DEFAULT)2.冻结模型所有参数
然后我们需要冻结模型的所有参数,避免我们后续训练改变它们
require_grad属性设置为False即可
python
for param in resnet_model.parameters():#冻结模型所有参数
param.requires_grad=False3.修改最后一层
fc.in_features属性可以获得最后一层全连接层的输入个数
然后我们直接把这个fc层赋值成一个新的全连接层并把输出设置为20
python
in_feature=resnet_model.fc.in_features
resnet_model.fc=nn.Linear(in_feature,20)4.获取需要更新的参数
遍历模型所有的参数,由于我们之前已经冻结了所有参数,所以只有我们上一步重新赋值的fc层是可以修改参数的,将fc的所有权重参数放入一个列表中,方便我们后续优化器进行反向传播优化
python
params_to_update=[]
for param in resnet_model.parameters():
if param.requires_grad==True:
params_to_update.append(param)5.创建模型
由于我们这里是迁移学习,所以我们不用向像之前再创建类的的对象,我们已经有了模型的对象
python
model=resnet_model.to(device)6.优化器和调整学习率
优化器我们要注意传入的参数是我们需要更新的最后一层的参数
调整学习率我们采用有序的等间隔调整
python
optimizer=torch.optim.Adam(params_to_update,lr=0.001)
scheduler=torch.optim.lr_scheduler.StepLR(optimizer,5,0.5)其余代码并未做任何的修改完整代码如下:
7.完整代码
python
import torch
from torch import nn
from torch.utils.data import Dataset,DataLoader
import numpy as np
from PIL import Image
from torchvision import transforms
import torchvision.models as models
import os
dire={}
def train_test_file(root,dir):
f_out=open(dir+'.txt','w')
path=os.path.join(root,dir)
for root,directories,files in os.walk(path):
if len(directories)!=0:
dirs=directories
else:
now_dir=root.split('\\')
for file in files:
path=os.path.join(root,file)
f_out.write(path+' '+str(dirs.index(now_dir[-1]))+'\n')
dire[dirs.index(now_dir[-1])]=now_dir[-1]
f_out.close()
root=r'.\food_dataset2'
train_dir='train'
test_dir='test'
train_test_file(root,train_dir)
train_test_file(root,test_dir)
resnet_model=models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
for param in resnet_model.parameters():#冻结模型所有参数
param.requires_grad=False
in_feature=resnet_model.fc.in_features
resnet_model.fc=nn.Linear(in_feature,20)
params_to_update=[]
for param in resnet_model.parameters():
if param.requires_grad==True:
params_to_update.append(param)
data_transforms={
'train':
transforms.Compose([
transforms.Resize([300,300]),
transforms.RandomRotation(45),#随机旋转
transforms.CenterCrop(224),#保持与迁移的模型一致
transforms.RandomHorizontalFlip(p=0.5),#随机水平旋转,概率p=0.5
transforms.RandomVerticalFlip(p=0.5),#随机垂直旋转,概率p=0.5
transforms.ColorJitter(brightness=0.2,contrast=0.1,saturation=0.1,hue=0.1),#brightness(亮度)contrast(对比度)saturation(饱和度)hue(色调)
transforms.RandomGrayscale(p=0.1),#p的概率转换为灰度图,但任然是三个通道,不过三个通道相同
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])#标准化,设置通用的均值和标准差
]),
'valid':#测试集只用标准化
transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
])
}
class food_dataset(Dataset):#能通过索引的方式返回图片数据和标签结果
def __init__(self,file_path,transform=None):
self.file_path=file_path
self.imgs_paths=[]
self.labels=[]
self.transform=transform
with open(self.file_path) as f:
samples=[x.strip().split(' ') for x in f.readlines()]
for img_path,label in samples:
self.imgs_paths.append(img_path)
self.labels.append(label)
def __len__(self):
return len(self.imgs_paths)
def __getitem__(self, idx):
image=Image.open(self.imgs_paths[idx])
if self.transform:
image=self.transform(image)
label=self.labels[idx]
label=torch.from_numpy(np.array(label,dtype=np.int64))#label也转化为tensor
return image,label
train_data=food_dataset(file_path='./train.txt',transform=data_transforms['train'])
test_data=food_dataset(file_path='./test.txt',transform=data_transforms['valid'])
train_loader=DataLoader(train_data,batch_size=32,shuffle=True)
test_loader=DataLoader(test_data,batch_size=32,shuffle=True)
device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
print(f'Using {device} device')
model=resnet_model.to(device)
def train(dataloader,model,loss_fn,optimizer):
model.train()
batch_size_num=1
for X,y in dataloader:
X,y=X.to(device),y.to(device)
pred=model(X)
loss=loss_fn(pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_value=loss.item()
if batch_size_num % 100 == 0:
print(f'loss:{loss_value:>7f} [number:{batch_size_num}]')
batch_size_num += 1
best_acc=0
def test(dataloader,model,loss_fn):
global best_acc
model.eval()
len_data=len(dataloader.dataset)
correct,loss_sum=0,0
num_batch=0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss_sum += loss_fn(pred, y).item()
correct+=(pred.argmax(1)==y).type(torch.float).sum().item()
num_batch+=1
loss_avg=loss_sum/num_batch
accuracy=correct/len_data
if accuracy>best_acc:
best_acc=accuracy
print(f'Accuracy:{100 * accuracy}%\nLoss Avg:{loss_avg}')
return pred.argmax(1)
loss_fn=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(params_to_update,lr=0.001)
scheduler=torch.optim.lr_scheduler.StepLR(optimizer,5,0.5)
epochs=10
for i in range(epochs):
print(f'==========第{i + 1}轮训练==============')
train(train_loader, model, loss_fn, optimizer)
test(test_loader, model, loss_fn)
scheduler.step()
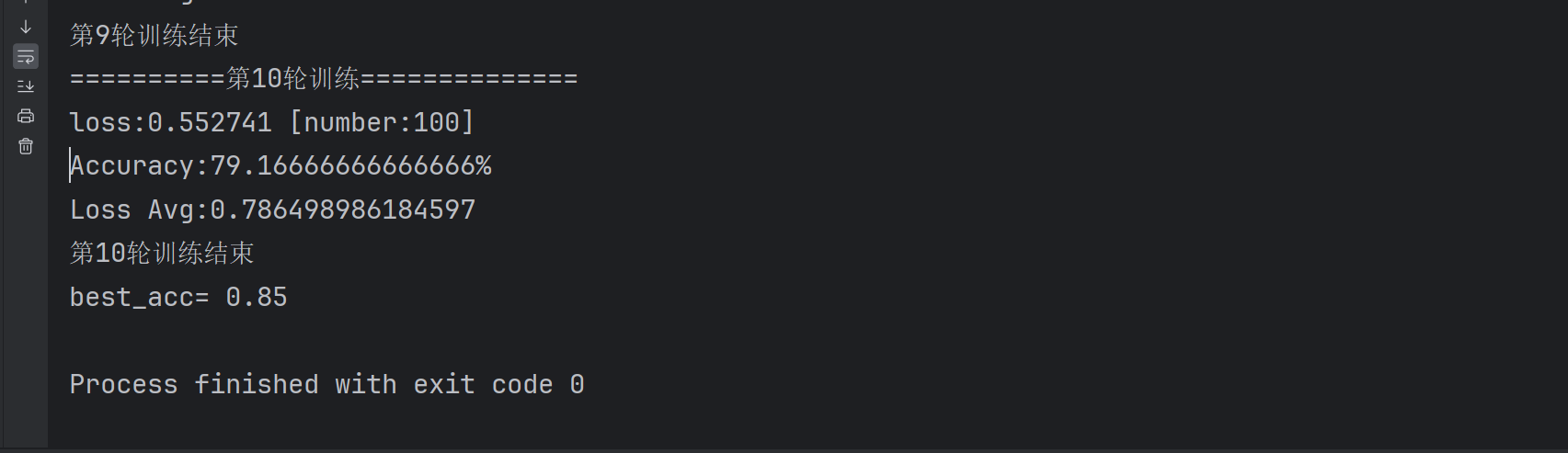
print(f'第{i + 1}轮训练结束')
print('best_acc=',best_acc)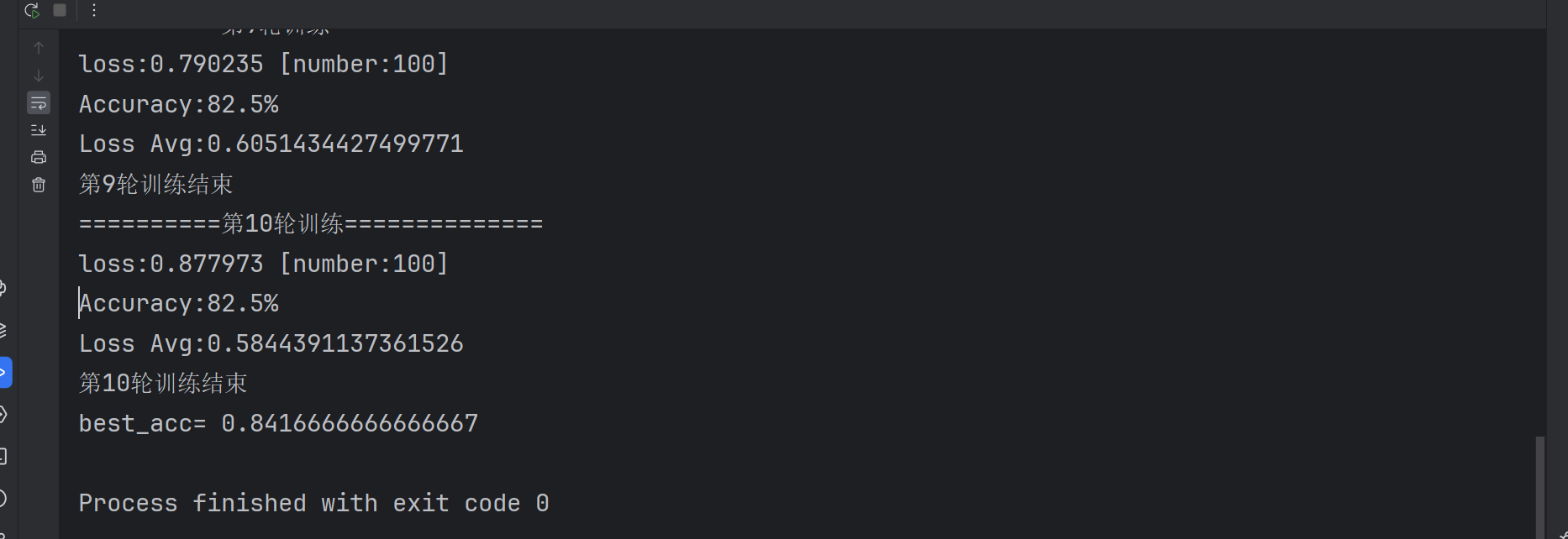
二.增加一层
我们如何在最后添加一层是通过定义一个类来实现的原理如下:
我们是通过类将迁移学习的模块和新的fc层组合在一起实现在残差网络中添加一层网络

1.模型获取和冻结参数
python
resnet_model=models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
for param in resnet_model.parameters():#冻结模型所有参数
param.requires_grad=False2.定义新的网络类
python
class ResNet(nn.Module):
def __init__(self):
super().__init__()
self.resnet_=resnet_model
self.fc=nn.Linear(1000,20)
def forward(self,x):
out=self.resnet_(x)
out=self.fc(out)
return out3.创建模型
这里创建模型我们又用到了类的创建
python
model=ResNet().to(device)4.获取需要更新的参数
python
params_to_update=[]
for param in model.parameters():
if param.requires_grad==True:
params_to_update.append(param)5.优化器和调整学习率
这里的调整学习率我们采用自适应调整
python
optimizer=torch.optim.Adam(params_to_update,lr=0.001)
# scheduler=torch.optim.lr_scheduler.StepLR(optimizer,5,0.5)
scheduler=torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer=optimizer,mode='min',factor=0.5,patience=2,verbose=False,threshold=0.0001,
threshold_mode='rel',cooldown=0,min_lr=0,eps=1e-08)6.完整代码
其余代码并无修改,只是train()方法做了一个返回平均损失值的改进用来作为学习率调整的根据指标,完整代码如下:
python
import torch
from torch import nn
from torch.utils.data import Dataset,DataLoader
import numpy as np
from PIL import Image
from torchvision import transforms
import torchvision.models as models
resnet_model=models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
for param in resnet_model.parameters():#冻结模型所有参数
param.requires_grad=False
class ResNet(nn.Module):
def __init__(self):
super().__init__()
self.resnet_=resnet_model
self.fc=nn.Linear(1000,20)
def forward(self,x):
out=self.resnet_(x)
out=self.fc(out)
return out
data_transforms={
'train':
transforms.Compose([
transforms.Resize([300,300]),
transforms.RandomRotation(45),#随机旋转
transforms.CenterCrop(224),#保持与迁移的模型一致
transforms.RandomHorizontalFlip(p=0.5),#随机水平旋转,概率p=0.5
transforms.RandomVerticalFlip(p=0.5),#随机垂直旋转,概率p=0.5
transforms.ColorJitter(brightness=0.2,contrast=0.1,saturation=0.1,hue=0.1),#brightness(亮度)contrast(对比度)saturation(饱和度)hue(色调)
transforms.RandomGrayscale(p=0.1),#p的概率转换为灰度图,但任然是三个通道,不过三个通道相同
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])#标准化,设置通用的均值和标准差
]),
'valid':#测试集只用标准化
transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
])
}
class food_dataset(Dataset):#能通过索引的方式返回图片数据和标签结果
def __init__(self,file_path,transform=None):
self.file_path=file_path
self.imgs_paths=[]
self.labels=[]
self.transform=transform
with open(self.file_path) as f:
samples=[x.strip().split(' ') for x in f.readlines()]
for img_path,label in samples:
self.imgs_paths.append(img_path)
self.labels.append(label)
def __len__(self):
return len(self.imgs_paths)
def __getitem__(self, idx):
image=Image.open(self.imgs_paths[idx])
if self.transform:
image=self.transform(image)
label=self.labels[idx]
label=torch.from_numpy(np.array(label,dtype=np.int64))#label也转化为tensor
return image,label
train_data=food_dataset(file_path='./train.txt',transform=data_transforms['train'])
test_data=food_dataset(file_path='./test.txt',transform=data_transforms['valid'])
train_loader=DataLoader(train_data,batch_size=32,shuffle=True)
test_loader=DataLoader(test_data,batch_size=32,shuffle=True)
device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
print(f'Using {device} device')
model=ResNet().to(device)
params_to_update=[]
for param in model.parameters():
if param.requires_grad==True:
params_to_update.append(param)
def train(dataloader,model,loss_fn,optimizer):
model.train()
batch_size_num=1
loss_sum=0
total_batches = len(dataloader) # 获取总批次数量
for X,y in dataloader:
X,y=X.to(device),y.to(device)
pred=model(X)
loss=loss_fn(pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_value=loss.item()
loss_sum+=loss_value
if batch_size_num % 100 == 0:
print(f'loss:{loss_value:>7f} [number:{batch_size_num}]')
batch_size_num += 1
return loss_sum/total_batches
best_acc=0
def test(dataloader,model,loss_fn):
global best_acc
model.eval()
len_data=len(dataloader.dataset)
correct,loss_sum=0,0
num_batch=0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss_sum += loss_fn(pred, y).item()
correct+=(pred.argmax(1)==y).type(torch.float).sum().item()
num_batch+=1
loss_avg=loss_sum/num_batch
accuracy=correct/len_data
if accuracy>best_acc:
best_acc=accuracy
print(f'Accuracy:{100 * accuracy}%\nLoss Avg:{loss_avg}')
return pred.argmax(1)
loss_fn=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(params_to_update,lr=0.001)
# scheduler=torch.optim.lr_scheduler.StepLR(optimizer,5,0.5)
scheduler=torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer=optimizer,mode='min',factor=0.5,patience=2,verbose=False,threshold=0.0001,
threshold_mode='rel',cooldown=0,min_lr=0,eps=1e-08)
epochs=10
for i in range(epochs):
print(f'==========第{i + 1}轮训练==============')
loss=train(train_loader, model, loss_fn, optimizer)
scheduler.step(loss)
test(test_loader, model, loss_fn)
print(f'第{i + 1}轮训练结束')
print('best_acc=',best_acc)