以下所有内容仅供学习使用; 好项目大家一起分享; 在RAG文档解析的时候发现了于Doc2X这个项目,仅供参考。 企业项目用还可以,毕竟是要投入的,但个人用还是看个人实力了。
1 Doc2X是什么?
Doc2X是一个高精度文档识别与智能解析平台,提供从PDF、扫描图像到可编辑文本的精准转换,轻松应对多栏排版、复杂表格、学术论文、财报报告和代码片段等多元场景,为信息获取与重利用提供高效解决方案。
2 核心特点
- 高精度OCR识别;
- 多栏与复杂排版解析;
- 表格与图表解析;
- 公式与代码段识别;
- 批量处理与多格式输出。

3 齐全格式转换
轻松将PDF转换为Word、HTML、LaTeX、Markdown等。转换前可与原PDF进行对照跳转编辑,确保准确性。 
4 大模型加持的双语对照PDF翻译
多种AI引擎:支持GPT、Deepseek、GLM等模型,提供精确翻译。双语对照的沉浸式翻译体验,快速理解。 
5 多模型对照图片公式识别编辑
Doc2X 图片识别集成 Doc2X,Mathpix 多个模型,高效实现图片公式识别,支持对照编辑与转换,提供丰富模板,满足学术与办公需求。 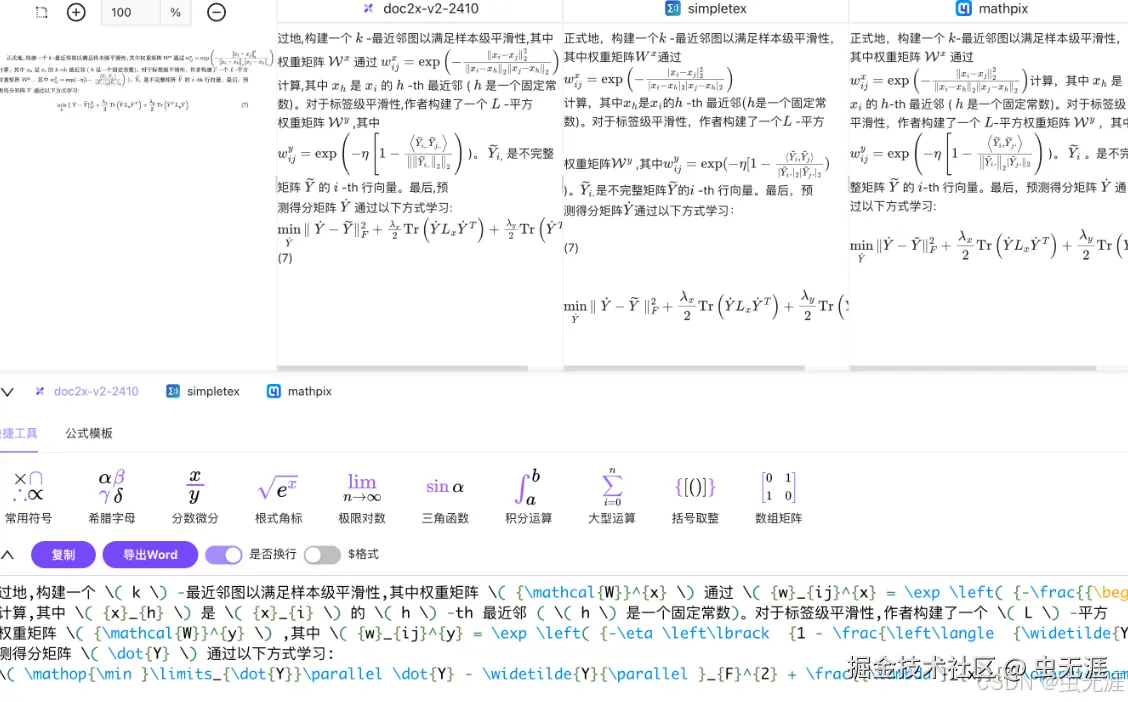
6 效果展示

7 适用体验
- 可以使用Doc2X 开放平台;
- 注册并获取 API 密钥。然后,按照文档中的说明,将 Doc2X 集成到您的项目中;
- 这种方式使用企业层面,个人层面看自己能力了。
- 另外可以使用下他们提供的体验地址:智能文档识别翻译;
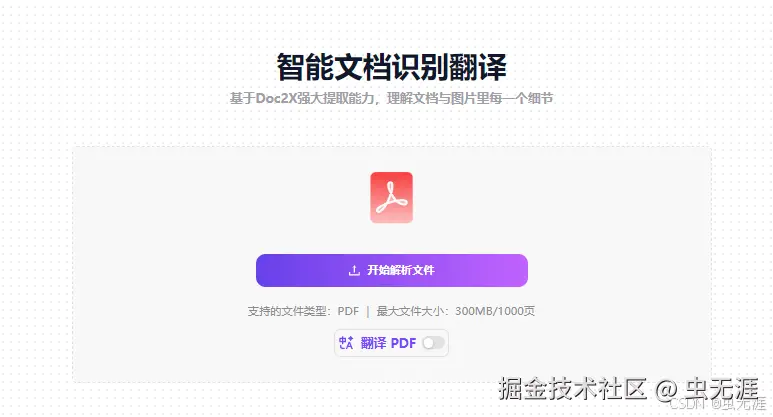
- 主要步骤是:
① 上传文档:通过 FastGPT 或其他集成了 Doc2X 的平台上传 PDF/图片格式的文档; ② Doc2X 解析:平台调用 Doc2X API 对文档进行深度解析,转换为 Markdown 或其他目标格式; ③ 内容入库与向量化:解析后的结构化内容被送入知识库,并进行向量化处理; ④ 智能问答/检索:通过自然语言进行提问,大模型基于 Doc2X 解析的高质量数据进行理解和回答。