背景
在使用flink的过程中,多次遇到过反压(backpressure)的问题,这通常是因为数据处理的速率超过了数据源或下游系统的处理能力导致。
反压的底层剖析
网络流控

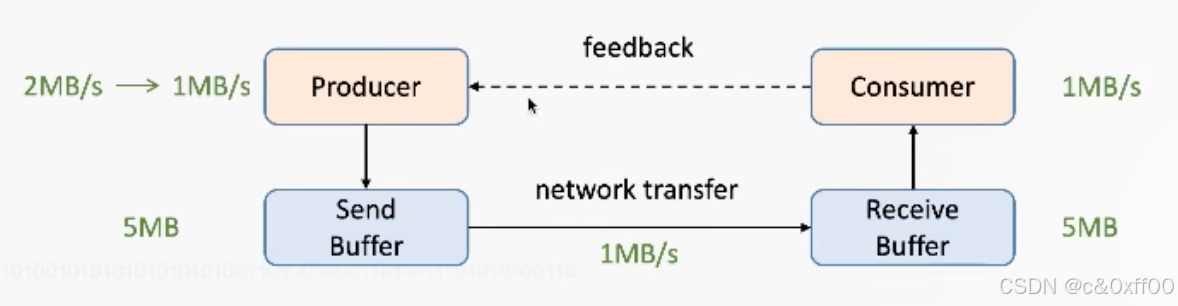
一个重要的概念是网络流控,如上图,不同的Consumer和Producer的消费和生产速率不一样,那么一定时候后,receive buffer和send buffer就肯定会满,导致生产端瘫痪。
为了能提前感知这一问题,引入了反压机制,增加了一个feedback:
在设计的过程中,会包含正反馈和负反馈,在反压的场景下,就是负反馈,让生产端降低发送速率,甚至停止发送。
 Flink1.5以前的流控方式
Flink1.5以前的流控方式
在1.5以前,Flink基于TCP实现流控,如图:
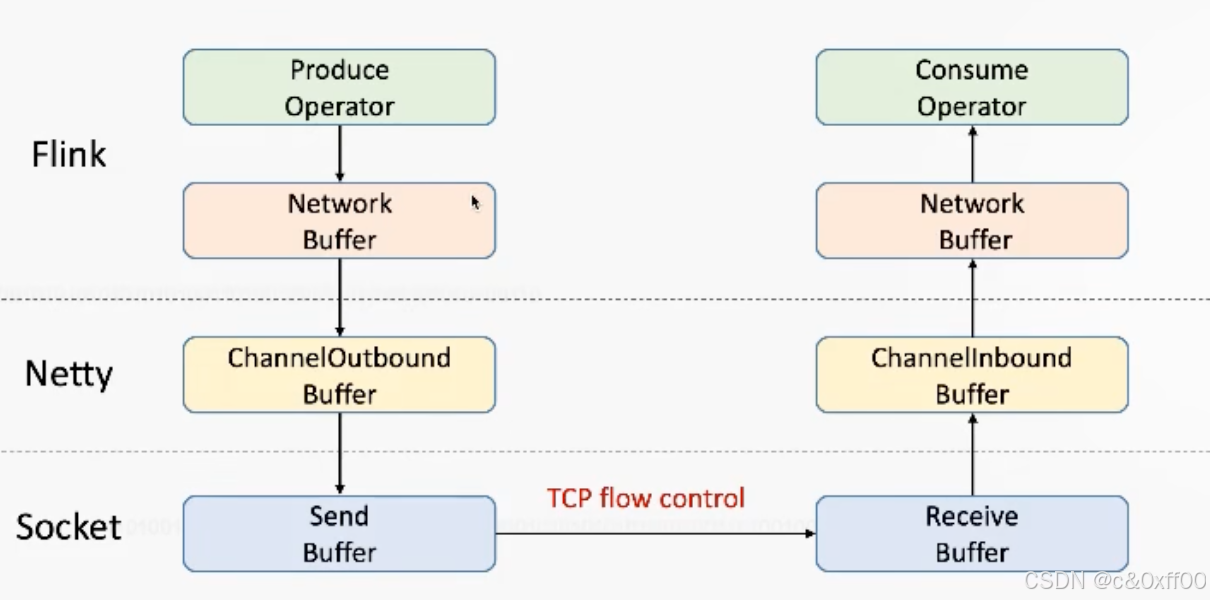 我们知道TCP通过滑动窗口ack机制实现了流量控制,简单来说就是TCP接收端会在每次收到数据包后给发送端返回两个主要信息:
我们知道TCP通过滑动窗口ack机制实现了流量控制,简单来说就是TCP接收端会在每次收到数据包后给发送端返回两个主要信息:
ACK=下次从哪个index继续发送
window=最多发送多少个字节
ack=8
window=1
如上表示从第8个字节继续发送,但只能发送1个,从而控制发送端的发送速度
拓展:如果返回window=0,代表接收端buffer已满,发送端会停止发送。为了知道什么时候可以继续发送,发送端会发送一个探测信号zeroWindowProbe来检测接收端的buffer情况。
Flink反压如何传播
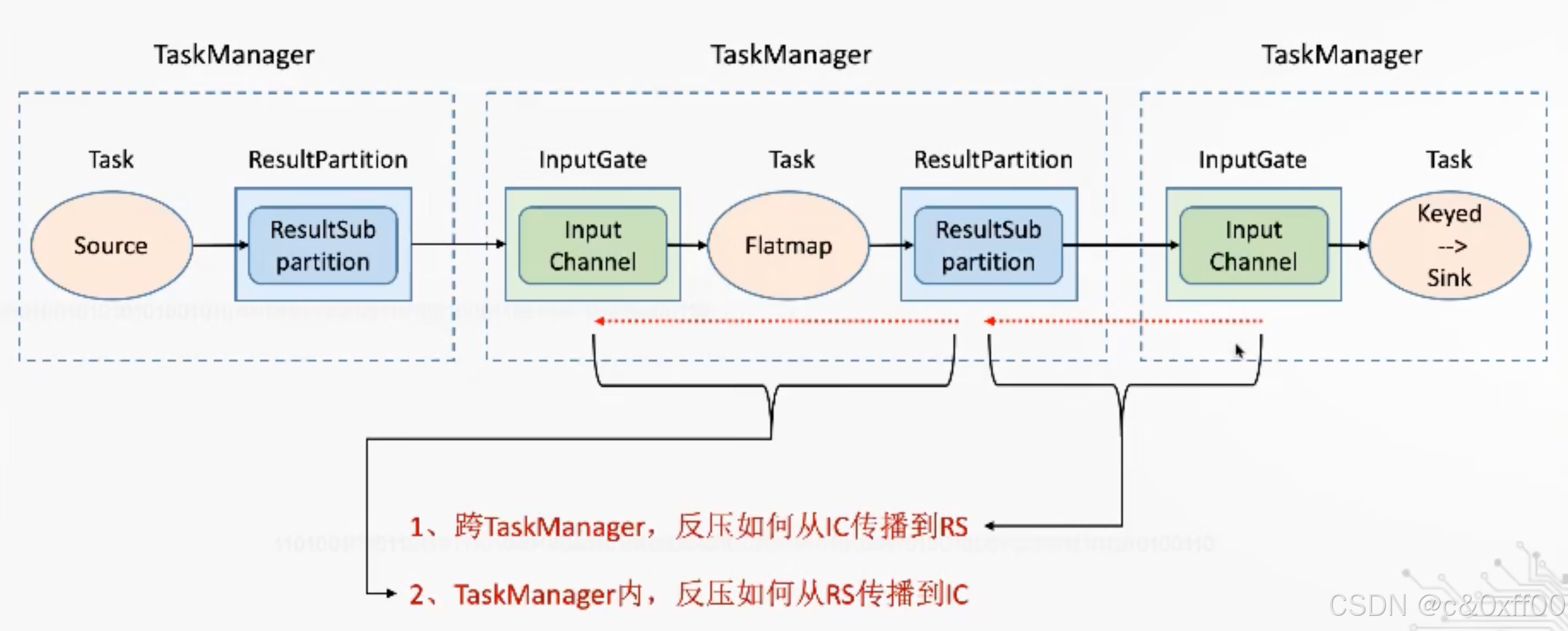
简单来说,基于对接收缓冲区的剩余大小感知,如果下游的缓存区满了,信号会从下游不断传递给上游,直到所有算子的所有缓存区均打满。
至于是跨TaskManager还是TaskManager内部,反压的机制是同理的,主要关注不同边界的缓冲区情况。
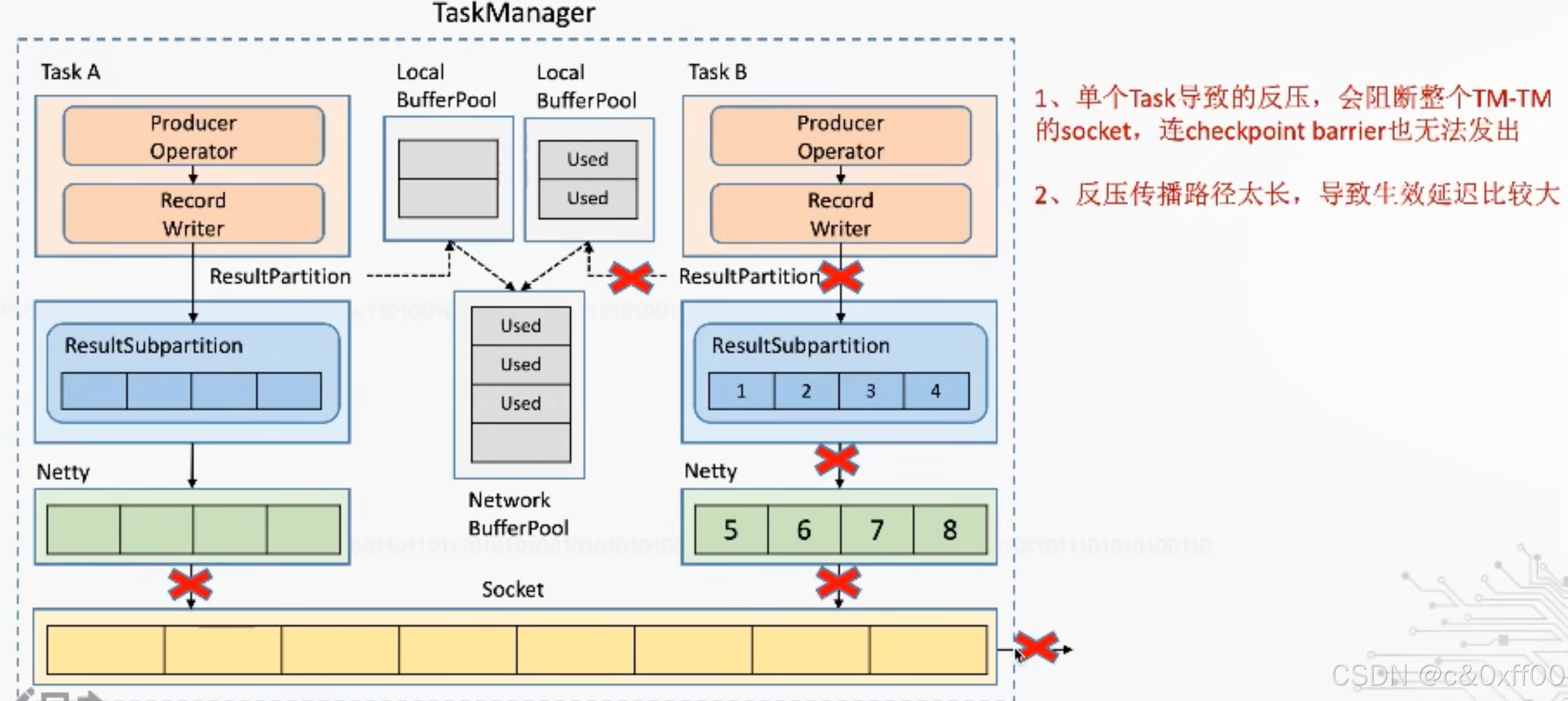
跨taskManager的反压示意
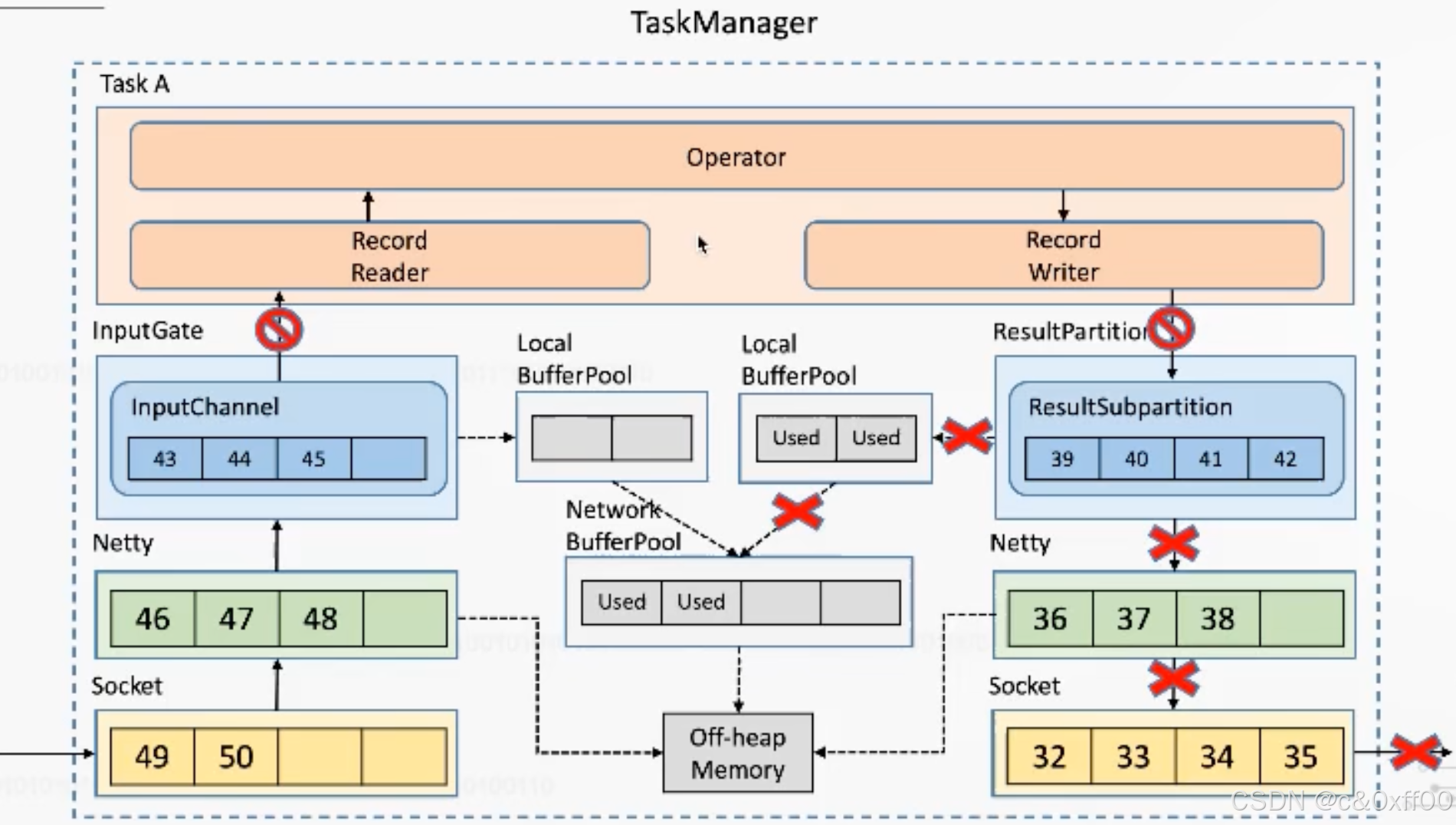
taskManager内反压示意
基于TCP的反压机制的弊端
虽然通过TCP可以实现反压机制,但是因为过于通用,还是产生了一些牺牲,因为一个taskManager内可能会有多个Task进行,而多个Task会复用一个socket进行传送(多路复用),如果某个task把tcp打满,会导致Task间相互影响
Flink1.5之后基于Credit-based的反压机制
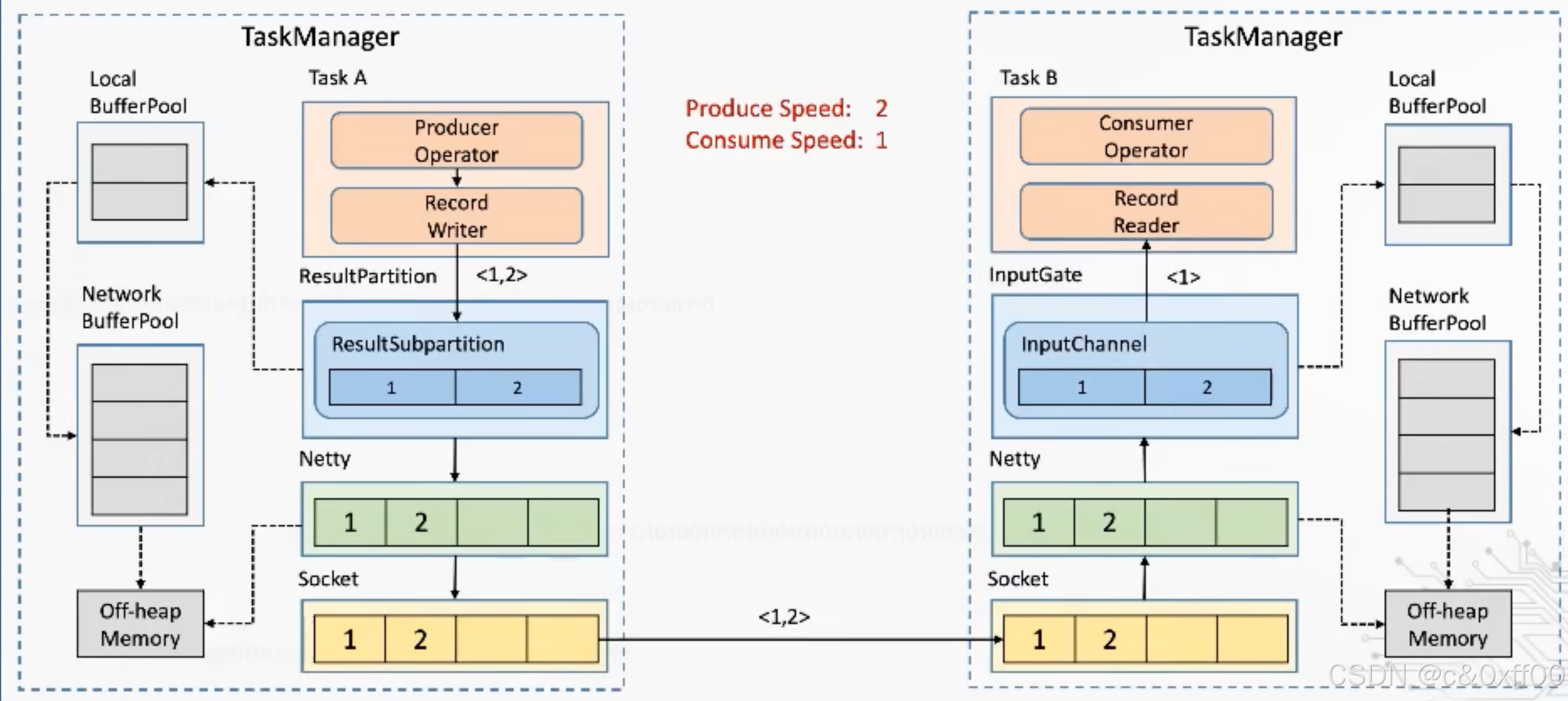
核心是通过Flink应用层来实现TCP流控的机制,避免影响底层tcp网络
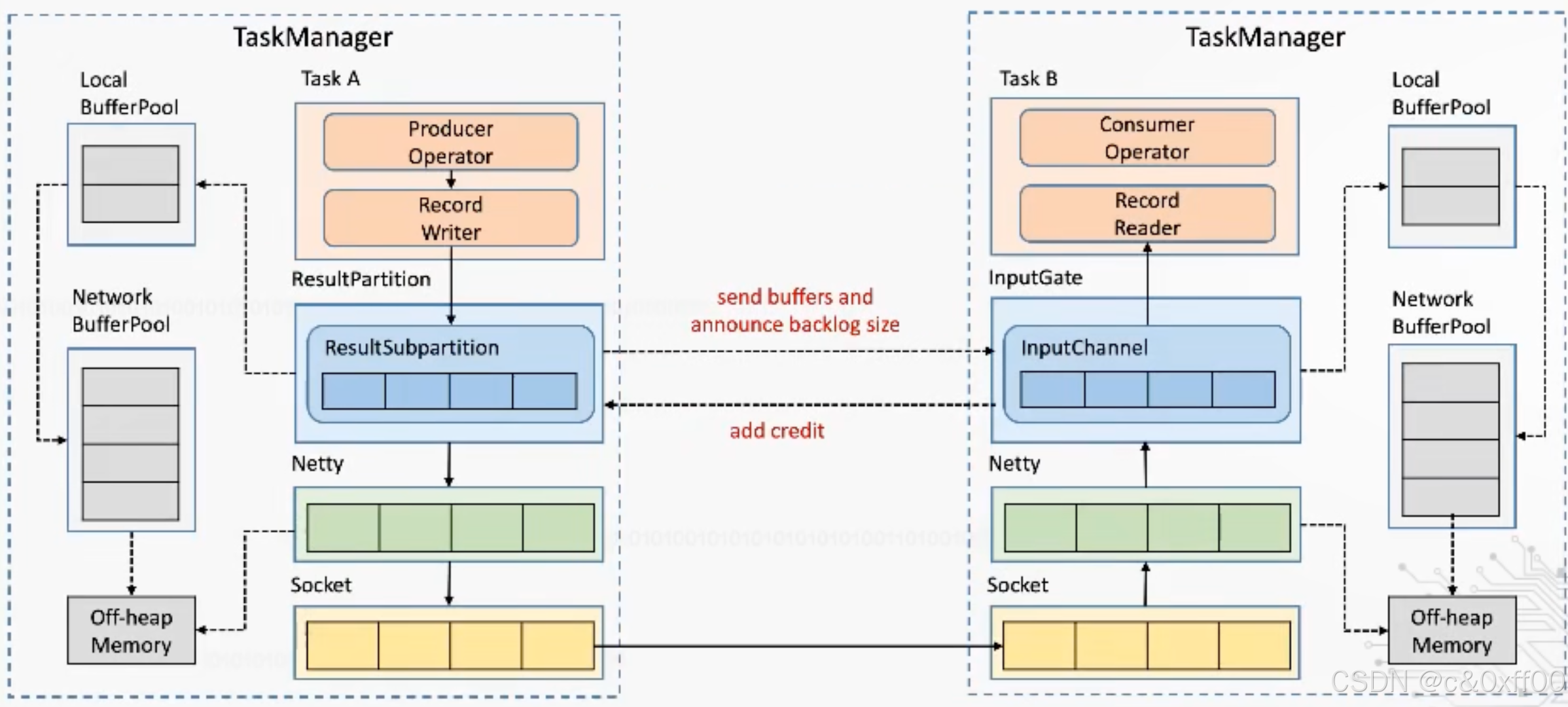
如上图,通过ResultSubpartition这一层来控制,在每次发送内容的时候,发送端会带上自己剩余的内容大小,而接收端收到后也会反馈inputChannel的剩余大小。这样就可以跨过TCP、Netty这两层,也就可以避免一个TaskManager中多个Task的相互影响。
反压场景解决
了解的反压的原理后,在面对Flink反压时,我们核心要分析出哪个环节慢了,然后通过调整并行度,资源分配、性能优化等手段进行解决。

具体case
后续补充