最近团队在做边缘场景的向量数据库选型及测试。
过往在非正式场景里,我使用过的向量数据库不少,qdrant、milvus、weaviate、es、oceanbase 等等,都能解决基础的向量检索问题,但是都并不深入,也没有了解过其底层的一些原理。
前段时间在团队内做了 Embedding、RAG 的分享后,也趁着这次业务中的实际落地使用,找一个向量库来测试看看。
最终,从众多向量库里选择了 qdrant 来进行测试。
主要 milvus、weaviate、es、ob 都用过了,想着找一个我自己没有使用过的来试试,实测一下效果。
业务场景
这次是在边缘场景,即在极小规模的服务器集群里(1~3 台 ,平均配置 32C 64GB)稳定运行多个业务服务。
我们在边缘场景的特点是,
(1)资源受限。运行整套服务运行所需要的全部内容,包含业务服务、数据库、各类中间件、网关等等(CPU、内存),同时边缘内容会随着持续运行不断堆积(磁盘),因此需要关注每个下沉服务/组件的资源消耗情况;
(2)内存资源紧张。我们自身的业务服务基本都是 Java,且是按云上微服务架构平移到边缘,短期内无法改变现状,这也就意味着一个业务可能包含多个服务,每个服务都是容器化部署,运行在一个独立的 JVM 中,JVM 运行本身就很吃内存,更进一步加剧了边缘资源紧张程度;
(3)低并发。我们在边缘侧往往服务中小规模项目/团队,不会有太大的并发;
因此,综上来看在测试向量数据库时,需要关注 CPU/GPU、内存、磁盘:
- 在保持中低并发时的 CPU/GPU使用率;(边缘用户量小,且不会集中使用,只按 10 并发计算)
- 在保证基础性能要求的情况下,更小的内存占用;(P99 200ms,拍的大腿,经验预估)
- 在一定规模数据量时的磁盘占用;(百万量级,内容持续本地存储,考虑向量存储及索引)
向量检索
既然关注重点在CPU/GPU、内存、磁盘,那么从向量检索的角度来看,哪些部分会消耗这些资源呢?
rust
文本 -> 向量化 -> 存储 -> 检索文本 -> 向量化
这个过程主要是Embedding。
在我们的边缘场景里,这个过程会有热点峰值,在某个时间点左右集中提交任务,边缘场景任务量可控,且业务是离线异步处理(通用 RAG 流程前半段,ASR+分段+Embedding),逐步跑完所有任务即可。
在这个过程中,核心使用的资源是CPU/GPU、内存。在边缘场景资源有效,即使是离线异步进行写入处理,也需要考虑资源使用情况,避免异步任务占用资源较高导致其他服务功能异常。
因此,团队算法同学也进行了测试。
测试环境

CPU 是16C 32线程,单核心2.9GHz(应该没睿频)
GPU 是 3090 24GB 内存版本
Embedding 模型选择的是bge-m3
CPU+GPU
测试数据 :文本长度 512,批处理大小 16,并发为 2 的场景下。


P99 在 190ms 左右,RPS 5.8,CPU 在 118%,GPU 在 68%,内存上涨 1.39GB,显存占用 1.4GB。
纯 CPU
测试数据:文本长度 64,批处理大小 1,并发为 1 的场景下。

P99 在 200ms 左右,RPS 6,CPU 在 3035%,内存上涨 0.7GB。
可以看到在纯 CPU 、低并发、短文本的场景下,已经基本将 CPU 跑满。
向量化 -> 存储
向量入库,需要考虑向量类型,同时结合查询场景判断是否需要携带额外信息辅助查询。
向量类型
在 Qdrant中,向量存储支持不同的向量类型:稠密向量、稀疏向量及多向量。
其中稠密向量、稀疏向量比较常见,而多向量指的是针对单个数据点,可以存储多个相同类型的向量,用于描述同一个对象的不同状态。
(官方的多向量例子) 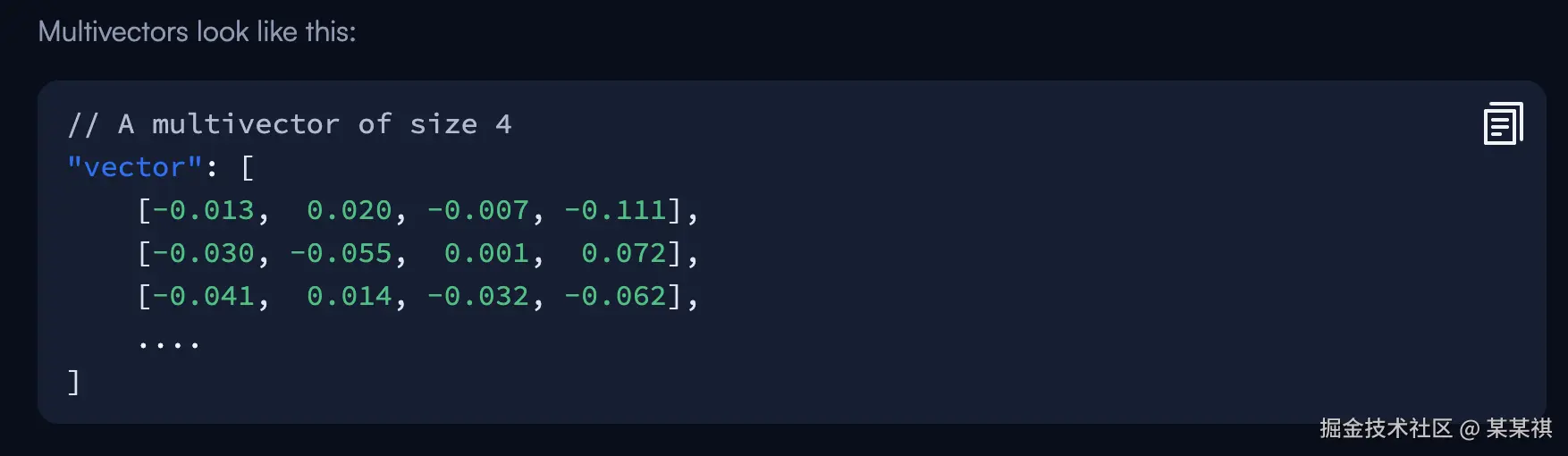
payload
简单理解,就是对于存储的每个向量,都可以额外存储一些信息,并基于这些额外信息构建索引及查询。

其中,payload 支持的类型包括Integer、Float、Keyword、Geo、Datetime、UUID。
存储结构
在 Qdrant中,一个数据集合会有 N 个shard,单个 shard被拆分成多个段segment。
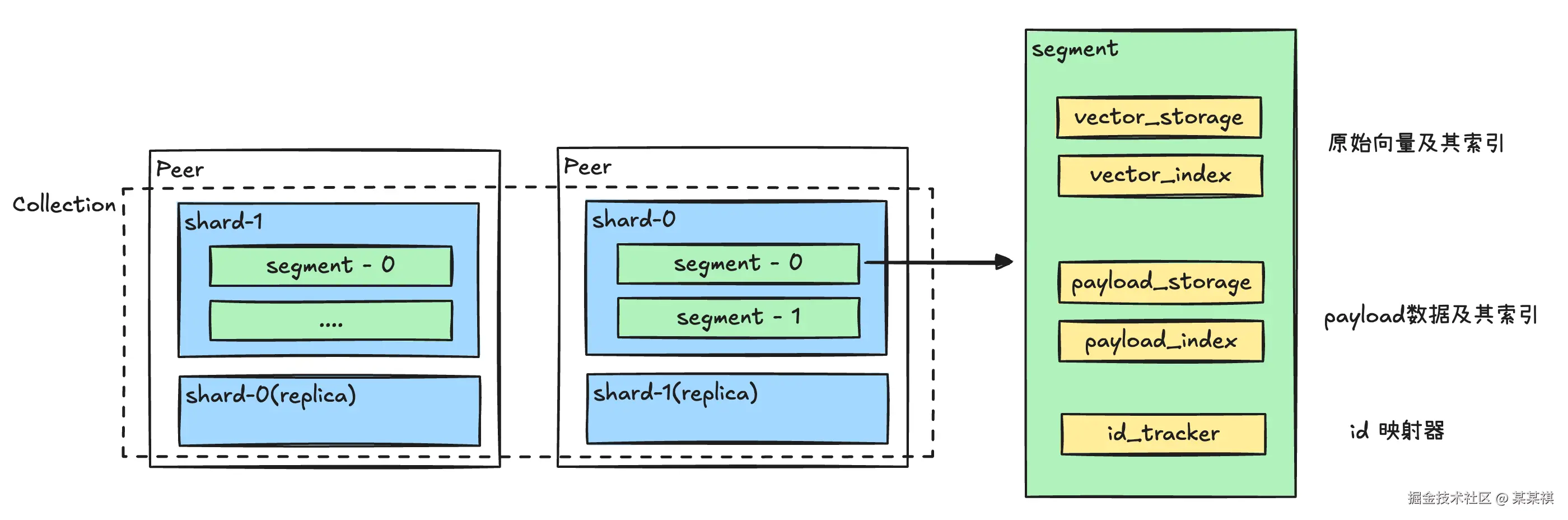
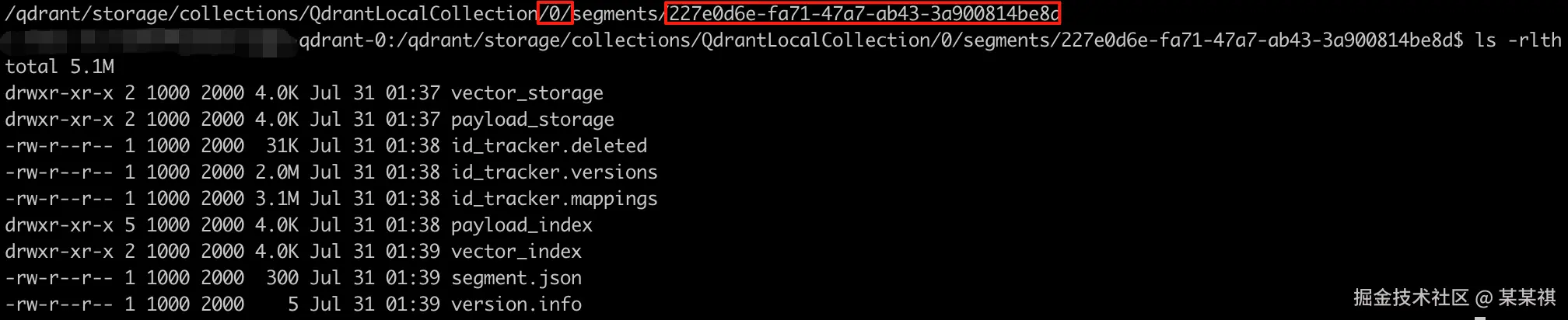
0为 shard 编号,该 collection 的 shard_number 为 1; 后面的 uuid 是 segment ,segment 下有向量及索引、id 映射器等。
存储形式
Qdrant 支持 In-Memory 和 Memmap 两种存储形式,分别对应存储在内存和磁盘中。
原始 vector及payload,都是保存在磁盘中的,在 segment目录下可以看到两者的目录。
 同时,vector、vector_index、payload、paylaod_index也都支持加载到内存,以提升查询速度。
同时,vector、vector_index、payload、paylaod_index也都支持加载到内存,以提升查询速度。
 (图中均未加载到内存中,只保存在磁盘里)
(图中均未加载到内存中,只保存在磁盘里)
存储实测
实测一下向量存储的情况,此时我们主要关注磁盘、内存占用。
测试数据集 :数据量 = 1 百万,单向量维度 = 1024,无 vector_index,payload 为 interger,且开启payload_index
测试工具 :vectordbbench
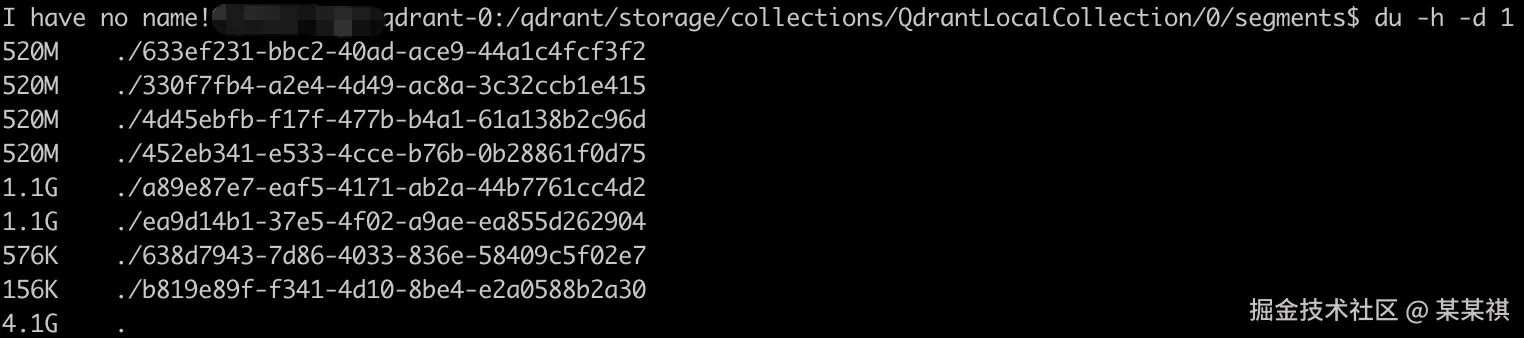
- 整体磁盘占用大小
包含 payload、payload_index、vector 及 id_tracker 等,共计 4.1GB。
- 整体加载内存占用大小
加载 vector、payload、payload_index 到内存后,内存增长到 4.9GB。
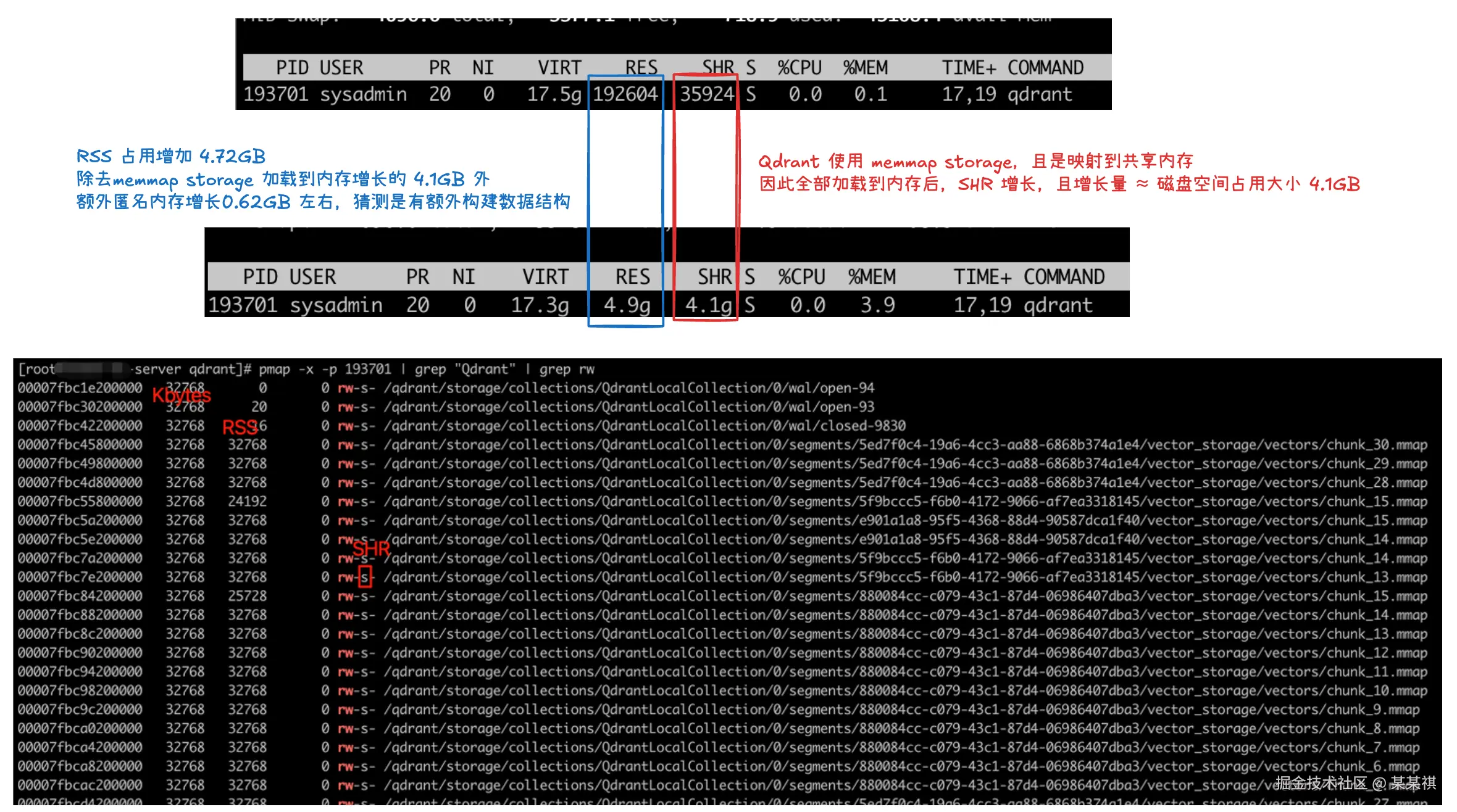
- 磁盘占用拆分
| 类型 | 占用大小 | 备注 |
|---|---|---|
| payload | 142MB | 单 payload字段,类型 integer,数据量 100W |
| payload_index | 88MB | integer payload index 默认开启 lookup 和 range |
| vector | 3910MB | 1024D,数据量 100W |
可以分别计算 payload_storage、payload_index以及 vector_storage 目录来得到磁盘空间占用大小
存储 -> 检索
到了检索这一步,关注的就是CPU及检索性能,而为了保证查询性能,一般首先想到的就是索引。
HNSW
全名:分层可导航小世界图(Hierarchical Navigable Small World) 是一种 ANN 算法,核心思想是跳表 + 可导航小世界。  (图片来源,可参考原文Hierarchical Navigable Small Worlds (HNSW))
(图片来源,可参考原文Hierarchical Navigable Small Worlds (HNSW))
这里不具体介绍索引原理,感兴趣的同学可以查看图片原文。
HNSW 无论从场景适配、召回率表现以及性能表现来上看,都是比较适合我们场景。
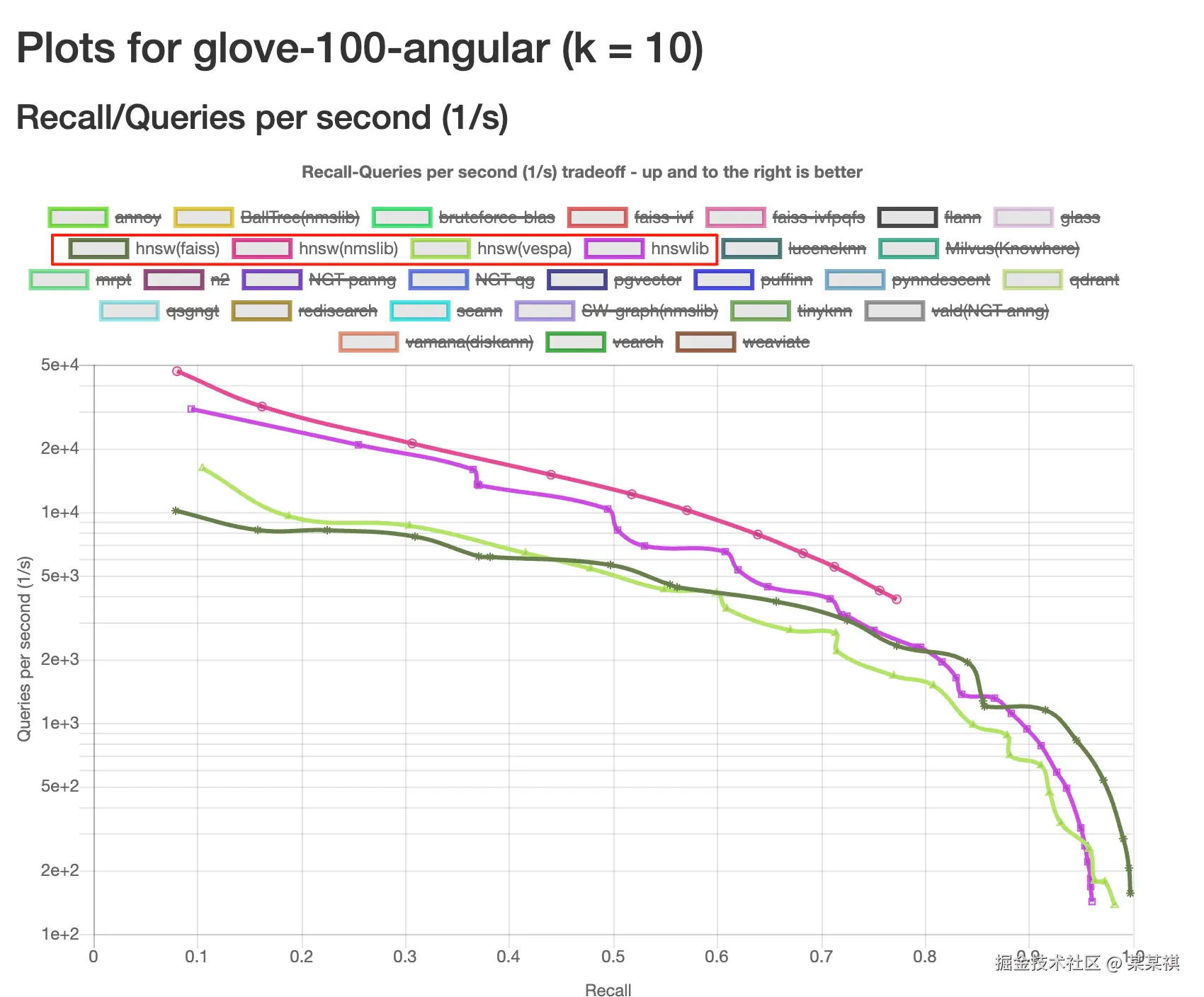 (上图是 ANN Benchmarks 中,基于召回率、QPS 的数据测试)
(上图是 ANN Benchmarks 中,基于召回率、QPS 的数据测试)
索引实测
在实测时,主要关注索引的磁盘、内存占用,同时对比索引前后的性能变化。
测试环境:cpu limit 8,memory limit 32GB
测试工具:vectordbbench
测试数据集:数据量 = 1 百万,单向量维度 = 1024
测试并发数:10(--num-concurrency)
HNSW 索引参数:m = 50、ef_construct = 200
查询线程池大小 = {cpu 核数} - 1,源码在
/lib/common/common/src/default.rs中的fn search_thread_count()中,测试机为 8C。
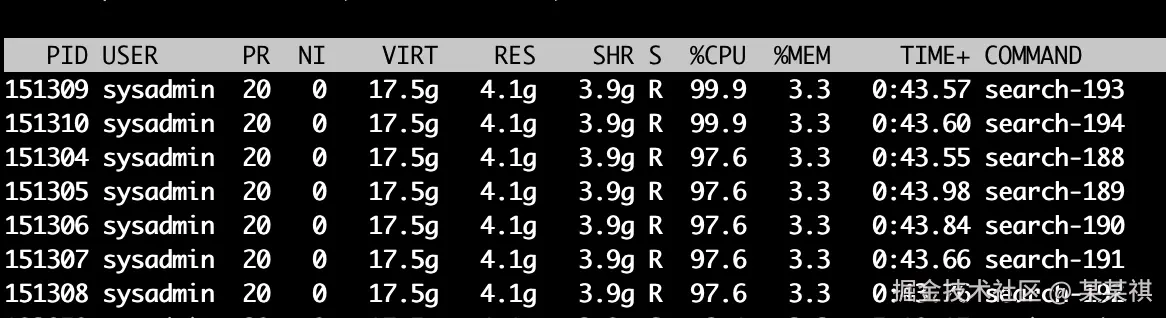
- 无 HNSW 索引
查询线程池基本跑满,qps ≈ 7.7,p99 ≈ 0.18,召回率 = 1 。
召回率 = 1,是因为无索引的的情况下,做的是全量检索。


- 有 HNSW 索引
索引构建完成后,可统计索引大小总计160MB。

在实际查询测试中,核心关键参数是hnsw_ef,决定了查询过程中 hnsw 每层的候选邻近节点数,也直接影响查询性能及召回率。
hnsw_ef = 20 
hnsw_ef = 50 
hnsw_ef = 100 
对比之下,召回率虽然达不到全量检索的 1,但是也能达到 0.97,切 qps 从 7 -> 174 。
QPS 174 不一定是上限,只是保持了无索引场景下的发压配置做对比。
总结
以上就是一些基础的测试,并不是很严谨,但是对Qdrant及向量检索能有一个基础了解。
内容的时间跨度有点长,持续了一个月,可能过程有点乱。