Gradio全解11------Streaming:流式传输的视频应用(5)------RT-DETR:实时端到端检测模型
-
- [11.5 RT-DETR:实时端到端检测模型](#11.5 RT-DETR:实时端到端检测模型)
-
- [11.5.1 模型技术与架构](#11.5.1 模型技术与架构)
-
- [1. 模型技术突破](#1. 模型技术突破)
- [2. 模型架构与目标](#2. 模型架构与目标)
- [11.5.2 训练细节与性能表现](#11.5.2 训练细节与性能表现)
- [11.5.3 最新版本:RT-DETRv2](#11.5.3 最新版本:RT-DETRv2)
- [11.5.4 图像目标识别示例及学习资源](#11.5.4 图像目标识别示例及学习资源)
-
- [1. 示例代码](#1. 示例代码)
- [2. 后续学习资源](#2. 后续学习资源)
本章目录如下:
- 《Gradio全解11------Streaming:流式传输的视频应用(1)------FastRTC:Python实时通信库》
- 《Gradio全解11------Streaming:流式传输的视频应用(2)------Twilio:网络服务提供商》
- 《Gradio全解11------Streaming:流式传输的视频应用(3)------YOLO系列模型技术架构与实战》
- 《Gradio全解11------Streaming:流式传输的视频应用(4)------基于Gradio.WebRTC+YOLO的实时目标检测》
- 《Gradio全解11------Streaming:流式传输的视频应用(5)------RT-DETR:实时端到端检测模型》
- 《Gradio全解10------Streaming:流式传输的视频应用(6)------基于RT-DETR模型构建目标检测系统》
- 《Gradio全解11------Streaming:流式传输的视频应用(7)------多模态Gemini模型及其思考模式》
- 《Gradio全解11------Streaming:流式传输的视频应用(8)------Gemini Live API:实时音视频连接》
- 《Gradio全解11------Streaming:流式传输的视频应用(9)------使用FastRTC+Gemini创建沉浸式音频+视频的艺术评论家》
11.5 RT-DETR:实时端到端检测模型
在使用RT-DETR模型构建视频流目标检测系统之前,先了解下RT-DETR模型。先讲解模型的技术与架构,然后着眼于训练细节与性能表现,接着介绍其最新版本RT-DETRv2,之后通过图像目标识别示例演示其用法,最后列出下一步的学习资源。
11.5.1 模型技术与架构
本节首先介绍RT-DETR实现的技术突破,然后讲解模型架构与目标
1. 模型技术突破
RT-DETR(Real-Time DEtection TRansformer)模型在论文《DETRs Beat YOLOs on Real-time Object Detection》(🖇️链接11-29)中提出,它是一种专注于实现实时性能同时保持高精度的目标检测模型。该模型基于Transformer架构(该架构在深度学习多个领域已展现出显著优势),通过对图像进行处理来识别并定位其中的多个目标。
近年来,基于Transformer的端到端检测器(DETRs)已取得显著性能突破。然而,DETRs计算成本高的问题尚未得到有效解决,这限制了其实际应用,也阻碍了其充分发挥无需后处理的优势,如非极大值抑制NMS(non-maximum suppression)。鉴于现代实时目标检测器中NMS对推理速度的延迟影响,原论文建立了端到端速度基准并提出了首个实时端到端目标检测器RT-DETR。具体而言,RT-DETR模型在以下方面实现了突破:
- 设计了高效混合编码器,通过解耦尺度内交互与跨尺度融合来高效处理多尺度特征。
- 提出IoU(Intersection over Union,交并比)感知查询选择机制,以优化目标查询的初始化。
- 提出的检测器支持通过灵活调整解码器层数(无需重新训练)来调节推理速度,提升了实时检测器的实用性。
2. 模型架构与目标
模型架构如图11-6所示,RT-DETR系统首先采用预训练的卷积神经网络(基于原始代码中的ResNet-D改进架构)对输入图像进行处理,然后将主干网络的特征输入最后三个阶段。第一阶段,高效混合编码器通过基于注意力的AIFI(Intra-scale Feature Interaction,尺度内特征交互)和基于CNN的CCFF(Cross-scale Feature Fusion,跨尺度特征融合),将多尺度特征转换为图像特征序列。第二阶段,不确定性最小化查询选择机制会选取固定数量的编码器特征作为解码器查询的初始对象。第三阶段,带有辅助预测头的解码器通过迭代优化对象查询,生成目标类别与边界框信息。
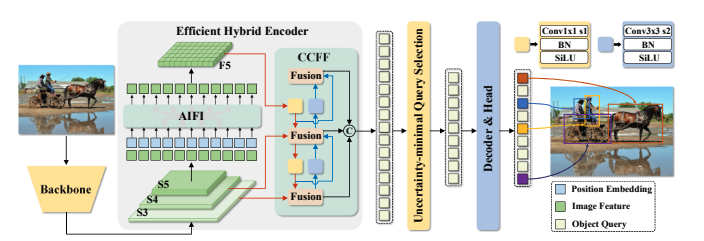
图11-6
11.5.2 训练细节与性能表现
训练开始时,首先对图像预处理,统一缩放至640x640像素,并使用image_mean=0.485, 0.456, 0.406和image_std=0.229, 0.224, 0.225进行像素值归一化。然后RT-DETR在Objects365上进行预训练,它是用于对象检测的大规模高质量数据集。最后在COCO 2017目标检测数据集进行微调训练:使用COCO train2017训练集进行训练,并在COCO val2017验证集上进行评估。COCO 数据集分别包含用于训练的11.8万和用于验证的5千张标注图像。采用评估指标包括:标准AP指标(在0.50-0.95范围内,以0.05为步长,均匀采样IoU阈值的平均值)、AP50、AP75,以及不同尺度下的指标:APS(小尺度)、APM(中尺度)、APL(大尺度)。
实验表明:
- 在使用Objects365进行预训练后,RT-DETR-R50/R101达到了55.3%/56.2%的AP,从而带来了惊人的性能提升。
- RT-DETR-L在COCO val2017上达到53.0% AP(Average Precision),使用T4 GPU实现114 FPS(Frame Per Second);RT-DETR-X达到54.8% AP与74 FPS。同规模下,两项指标均超越所有YOLO检测器;
- 此外,RT-DETR-R50以53.1% AP和108 FPS的表现,在精度上超越DINO-Deformable-DETR-R50达2.2% AP,速度提升约21倍。
与之前先进的实时目标检测模型YOLO系列相比,RT-DETR系列模型达到更好的性能,对比如图11-7所示:
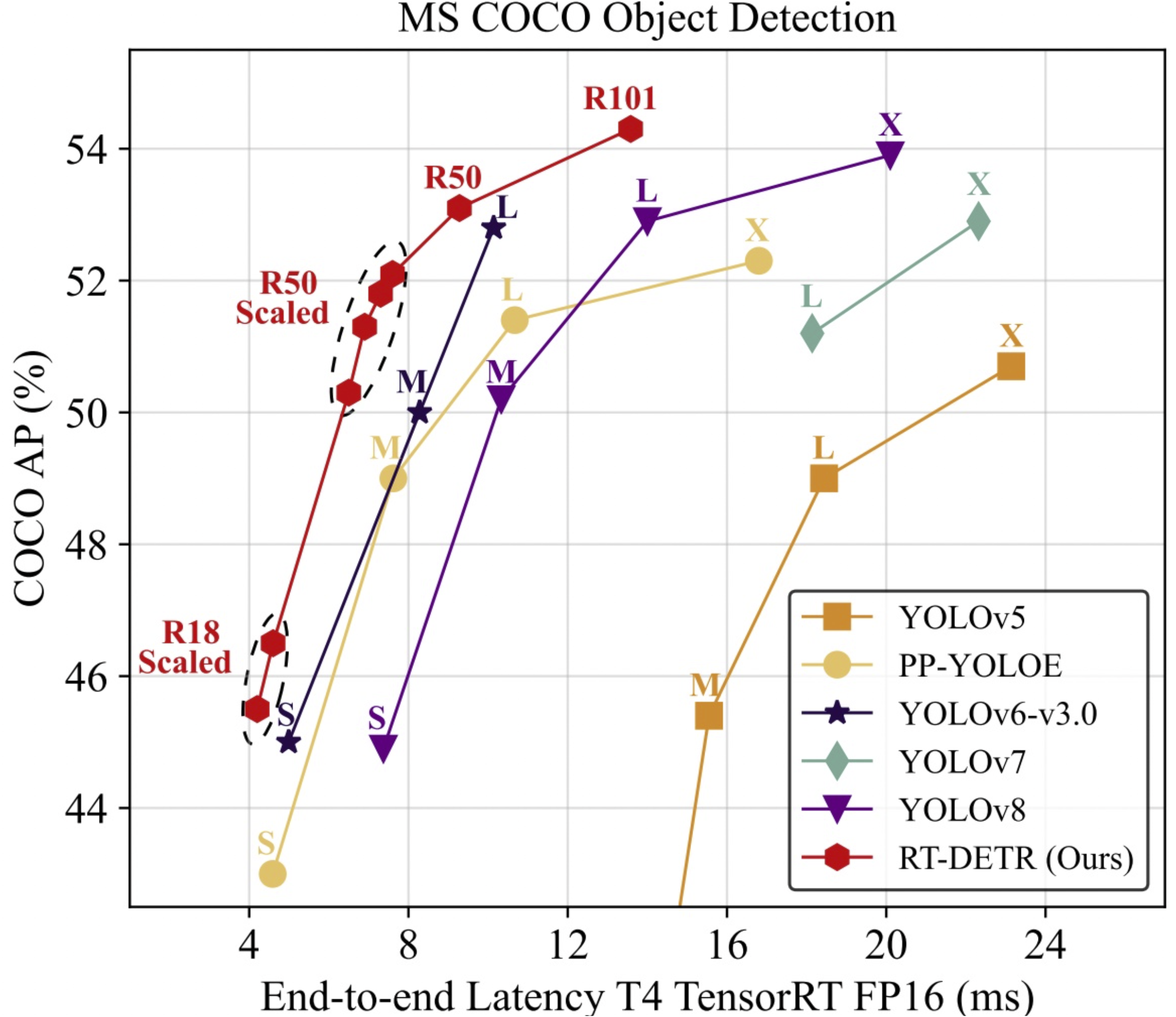
图11-7
关于RT-DETR的更多信息请参阅:PekingU/rtdetr_r101vd_coco_o365🖇️链接11-30。
11.5.3 最新版本:RT-DETRv2
RT-DETR系列的最新版本是RT-DETRv2模型,它在论文《RT-DETRv2: Improved Baseline with Bag-of-Freebies for Real-Time Detection Transformer 》(🖇️链接11-31)中提出。RT-DETRv2通过以下改进优化了RT-DETR:引入可选择的多尺度特征提取,采用离散采样算子提升部署兼容性,以及改进训练策略(包括动态数据增强和尺度自适应超参数)。这些改进在保持实时性能的同时,显著增强了模型的灵活性和实用性。
训练过程:RT-DETRv2模型基于COCO train2017训练集进行训练,并在COCO val2017验证集上进行性能验证,并采用标准AP指标以及实际场景中广泛使用的APval50作为评估标准。
应用场景:RT-DETRv2非常适合需要实时目标检测的多种应用场景,包括自动驾驶、监控系统、机器人技术和零售分析。其增强的灵活性和部署友好型设计,使其既适用于边缘设备也能满足大规模系统需求,确保在动态真实环境中实现高精度与高速检测。
使用RT-DETRv2的代码也很简单,只需导入RT-DETRv2并替换模型名称即可,代码如下所示:
python
from transformers import RTDetrV2ForObjectDetection, RTDetrImageProcessor
image_processor = RTDetrImageProcessor.from_pretrained("PekingU/rtdetr_v2_r101vd")
model = RTDetrV2ForObjectDetection.from_pretrained("PekingU/rtdetr_v2_r101vd")关于RT-DETRv2的更多信息请参阅:PekingU/rtdetr_v2_r101vd🖇️链接11-32。
11.5.4 图像目标识别示例及学习资源
本节展示使用RT-DETR进行图标目标识别的代码,然后列出后续学习的资源。
1. 示例代码
使用RT-DETR进行图标目标识别的代码如下所示:
python
import torch
import requests
from PIL import Image
from transformers import RTDetrForObjectDetection, RTDetrImageProcessor
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
image_processor = RTDetrImageProcessor.from_pretrained("PekingU/rtdetr_r50vd")
model = RTDetrForObjectDetection.from_pretrained("PekingU/rtdetr_r50vd")
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
results = image_processor.post_process_object_detection(outputs, target_sizes=torch.tensor([(image.height, image.width)]), threshold=0.3)
for result in results:
for score, label_id, box in zip(result["scores"], result["labels"], result["boxes"]):
score, label = score.item(), label_id.item()
box = [round(i, 2) for i in box.tolist()]
print(f"{model.config.id2label[label]}: {score:.2f} {box}")代码比较简单,不再解释。输出如下所示:
bash
sofa: 0.97 [0.14, 0.38, 640.13, 476.21]
cat: 0.96 [343.38, 24.28, 640.14, 371.5]
cat: 0.96 [13.23, 54.18, 318.98, 472.22]
remote: 0.95 [40.11, 73.44, 175.96, 118.48]
remote: 0.92 [333.73, 76.58, 369.97, 186.99]可使用以下代码进行可视化:
python
from PIL import ImageDraw
draw = ImageDraw.Draw(image)
for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
box = [round(i, 2) for i in box.tolist()]
x, y, x2, y2 = tuple(box)
draw.rectangle((x, y, x2, y2), outline="red", width=1)
draw.text((x, y), model.config.id2label[label.item()], fill="white")2. 后续学习资源
以下是由Hugging Face官方及Github社区提供的资源列表,可以帮助我们快速入门RT-DETR:
- 更全面信息请参阅Transformers库的目标检测任务指南:Transformers - Tasks - Object detection🖇️链接11-33;
- 关于RT-DETR及RT-DETRv2的更多成员函数及其它详细信息请参阅: Transformers - Vision Models - RT-DETR🖇️链接11-34。
- 使用Trainer和Accelerate微调RTDetrForObjectDetection的脚本可在此处获取: Transformers - Pytorch - Object detection examples🖇️链接11-35。
- 关于RT-DETR在自定义数据集上进行推理和微调的Notebook可在此处查看: How to Train RT-DETR on a Custom Dataset with Transformers🖇️链接11-36。