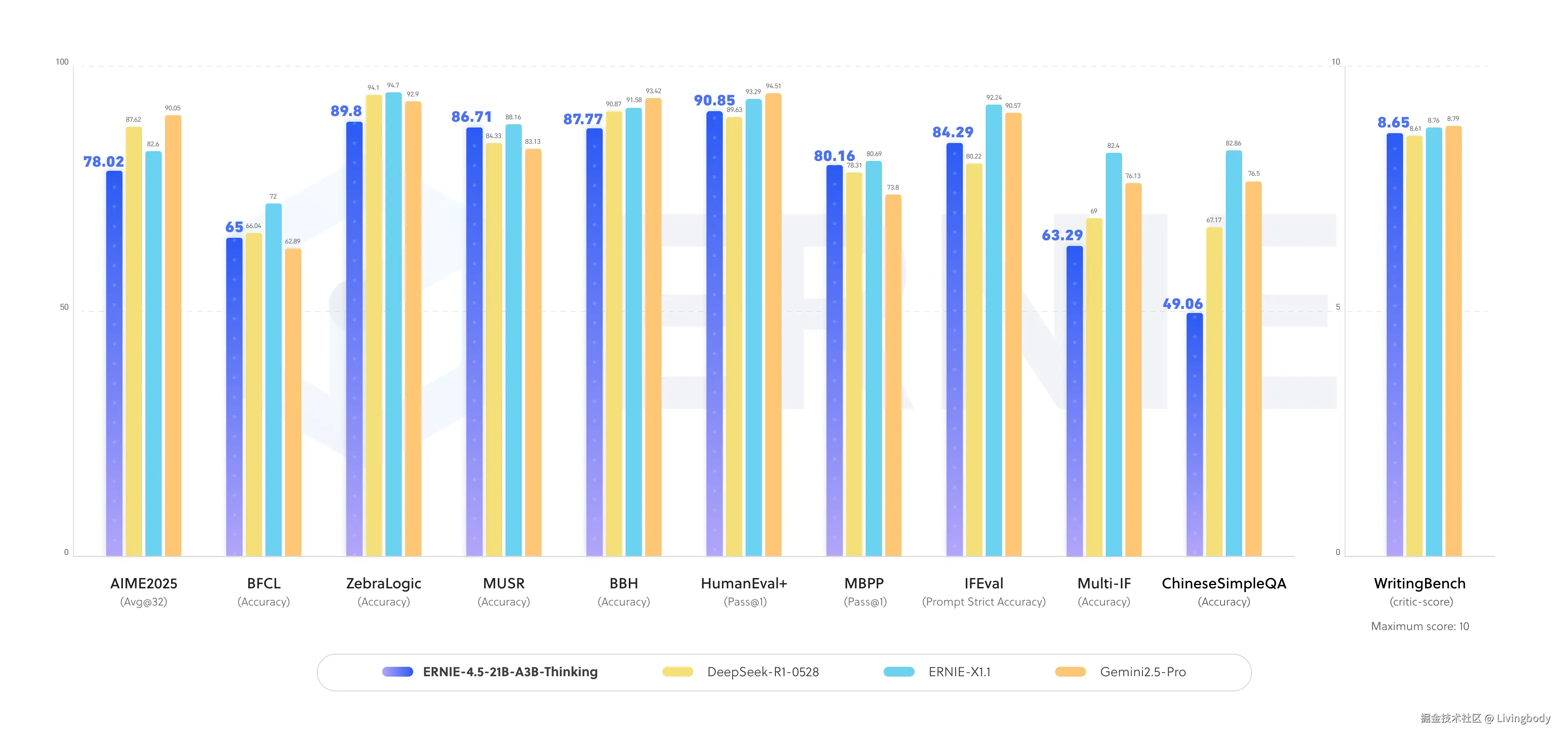
一、ERNIE-4.5-21B-A3B-Thinking 深度思考模型介绍
1.模型亮点
- 在推理任务上的性能显著提升,涵盖逻辑推理、数学、科学、代码编写、文本生成,以及通常需要人类专业知识才能完成的学术基准测试任务。
- 具备高效的工具使用能力。
- 增强了 128K 长上下文理解能力。
2.模型概述
ERNIE-4.5-21B-A3B-Thinking是一款文本混合专家(MoE)后训练模型,总参数量为210亿,每个token的激活参数量为30亿。以下是该模型的具体配置细节:
说明:
-
- "MoE"全称为"Mixture of Experts",即"混合专家模型",是一种通过多个"专家子模型"协同工作、按需激活部分参数来平衡模型性能与计算效率的架构;
-
- "token"指文本处理中的基本语义单位,可理解为"词元",如英文单词、中文汉字或词语片段;3. "激活参数"指模型在处理每个token时实际参与计算的参数,不同于总参数,其规模直接影响模型推理时的计算效率。
| Key | Value |
|---|---|
| Modality | Text |
| Training Stage | Posttraining |
| Params(Total / Activated) | 21B / 3B |
| Layers | 28 |
| Heads(Q/KV) | 20 / 4 |
| Text Experts(Total / Activated) | 64 / 6 |
| Vision Experts(Total / Activated) | 64 / 6 |
| Shared Experts | 2 |
| Context Length | 131072 |
二、环境搭建
1.环境检查
1.1 PaddlePaddle版本检查
此次使用paddlepaddle-gpu==3.2版本 ,2025年9月9日 WaveSummit 发布的最新版
python
!pip list|grep paddlepaddlepaddlepaddle-gpu 3.2.0
python
import warnings
warnings.filterwarnings('ignore')
# 验证安装
!python -c "import paddle;paddle.utils.run_check()"
vbnet
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/utils/cpp_extension/extension_utils.py:718: UserWarning: No ccache found. Please be aware that recompiling all source files may be required. You can download and install ccache from: https://github.com/ccache/ccache/blob/master/doc/INSTALL.md
warnings.warn(warning_message)
Running verify PaddlePaddle program ...
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/pir/math_op_patch.py:219: UserWarning: Value do not have 'place' interface for pir graph mode, try not to use it. None will be returned.
warnings.warn(
I0912 22:05:59.027858 795 pir_interpreter.cc:1524] New Executor is Running ...
W0912 22:05:59.029263 795 gpu_resources.cc:114] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 12.8, Runtime API Version: 12.6
I0912 22:05:59.029959 795 pir_interpreter.cc:1547] pir interpreter is running by multi-thread mode ...
PaddlePaddle works well on 1 GPU.
PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.- 可见使用的是 paddlepaddle-gpu 3.2.0
- GPU上运行正常
1.2 fastdeploy版本检查
python
!pip list|grep fastdeployfastdeploy-gpu 2.1.0可见fastdeploy-gpu 版本为 2.1.0 ,需要更新
python
!python -m pip install -U fastdeploy-gpu -i https://www.paddlepaddle.org.cn/packages/stable/fastdeploy-gpu-80_90/ --extra-index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
python
pip list|grep fastdeploy
vbnet
fastdeploy-gpu 2.2.0
Note: you may need to restart the kernel to use updated packages.更新后为fastdeploy-gpu 版本为 2.2.0
三、FastDeploy模型快速部署
可以使用FastDeploy快速部署服务。
1.注意事项
- 需配备 80GB 显存的 GPU 资源(单卡)。
- 部署本模型需使用 FastDeploy 2.2 版本。
2.部署命令
bash
python -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-21B-A3B-Thinking \
--port 8180 \
--metrics-port 8181 \
--engine-worker-queue-port 8182 \
--load_choices "default_v1" \
--tensor-parallel-size 1 \
--max-model-len 131072 \
--reasoning-parser ernie_x1 \
--tool-call-parser ernie_x1 \
--max-num-seqs 32- --quantization: 表示模型采用的量化策略。不同量化策略,模型的性能和精度也会不同。可选值包括:wint8 / wint4 / block_wise_fp8(需要Hopper架构)。
- --max-model-len:表示当前部署的服务所支持的最长Token数量。设置得越大,模型可支持的上下文长度也越大,但相应占用的显存也越多,可能影响并发数。
- --load_choices: 表示loader的版本,"default_v1"表示启用v1版本的loader,具有更快的加载速度和更少的内存使用。
- --reasoning-parser 、 --tool-call-parser: 表示对应调用的思考内容和工具调用解析器
3.参考资料
4.服务部署
4.1 使用FastDeploy进行部署
python
import subprocess
import time
import requests
import threading
def start_fastdeploy():
cmd = [
"python", "-m", "fastdeploy.entrypoints.openai.api_server",
"--model", "baidu/ERNIE-4.5-21B-A3B-Thinking",
"--port", "8180",
"--metrics-port", "8181",
"--engine-worker-queue-port", "8182",
"--load_choices", "default_v1" ,
"--tensor-parallel-size", "1",
"--max-model-len", "131072",
"--reasoning-parser", "ernie_x1",
"--tool-call-parser", "ernie_x1",
"--max-num-seqs", "32"
]
print("🚀 启动FastDeploy服务...")
print("-" * 50)
process = subprocess.Popen(
cmd,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
universal_newlines=True,
bufsize=1
)
print(f"📝 PID: {process.pid}")
service_ready = False
def monitor_logs():
nonlocal service_ready
try:
while True:
output = process.stdout.readline()
if output == '' and process.poll() is not None:
break
if output:
line = output.strip()
print(f"[日志] {line}")
if "Loading Weights:" in line and "100%" in line:
print("✅ 权重加载完成")
elif "Loading Layers:" in line and "100%" in line:
print("✅ 层加载完成")
elif "Worker processes are launched" in line:
print("✅ 工作进程启动")
elif "Uvicorn running on" in line:
print("🎉 服务启动完成!")
service_ready = True
break
except Exception as e:
print(f"日志监控错误: {e}")
log_thread = threading.Thread(target=monitor_logs, daemon=True)
log_thread.start()
start_time = time.time()
while time.time() - start_time < 120:
if service_ready:
break
if process.poll() is not None:
print("❌ 进程退出")
return None
time.sleep(1)
if not service_ready:
print("❌ 启动超时")
process.terminate()
return None
print("-" * 50)
return process
def test_model():
try:
import openai
print("🔌 测试模型连接...")
client = openai.Client(base_url="http://localhost:8180/v1", api_key="null")
response = client.chat.completions.create(
model="null",
messages=[
{"role": "system", "content": "你是一个有用的AI助手。"},
{"role": "user", "content": "给我讲一下成语泾渭分明"}
],
max_tokens=50,
stream=False
)
print("✅ 模型测试成功!")
print(f"🤖 回复: {response.choices[0].message.content}")
return True
except Exception as e:
print(f"❌ 测试失败: {e}")
return False
def check_service():
try:
response = requests.get("http://localhost:8180/v1/models", timeout=3)
return response.status_code == 200
except:
return False
def setup_service():
print("=== ERNIE-4.5-21B-A3B-Thinking 服务启动 ===")
if check_service():
print("✅ 发现运行中的服务")
if test_model():
print("🎉 服务已就绪!")
return True
print("⚠️ 服务异常,重新启动")
process = start_fastdeploy()
if process is None:
print("❌ 启动失败")
return False
if test_model():
print("🎊 启动成功!现在可以运行知识图谱代码")
return True
else:
print("❌ 启动但连接失败")
return False
if __name__ == "__main__" or True:
setup_service()4.2 注意事项
- 在部署的时候,如果没有下载模型,FastDeploy会自动下载模型,省去下载模型这一步;
- 模型比较大,下载可能中断,多尝试几次即可!
- 输出日志较多,多为下载模型记录,下面截取部分。
4.3 日志分析
bash
✅ 工作进程启动
[日志] INFO 2025-09-12 22:17:51,353 25102 api_server.py[line:552] Launching metrics service at http://0.0.0.0:8181/metrics
[日志] INFO 2025-09-12 22:17:51,353 25102 api_server.py[line:553] Launching chat completion service at http://0.0.0.0:8180/v1/chat/completions
[日志] INFO 2025-09-12 22:17:51,353 25102 api_server.py[line:554] Launching completion service at http://0.0.0.0:8180/v1/completions
[日志]
[日志] Processing 16 items: 0%| | 0.00/16.0 [00:00<?, ?it/s]
[日志] Processing 16 items: 19%|█▉ | 3.00/16.0 [00:00<00:00, 23.0it/s]
[日志] Processing 16 items: 44%|████▍ | 7.00/16.0 [00:00<00:00, 28.5it/s]
[日志] Processing 16 items: 75%|███████▌ | 12.0/16.0 [00:00<00:00, 35.5it/s]
[日志] Processing 16 items: 100%|██████████| 16.0/16.0 [00:00<00:00, 18.1it/s]
[日志] Processing 16 items: 100%|██████████| 16.0/16.0 [00:00<00:00, 21.0it/s]
[日志] [2025-09-12 22:17:53] [ INFO] - Started server process [25102]
[日志] [2025-09-12 22:17:53] [ INFO] - Waiting for application startup.
[日志] [2025-09-12 22:17:53,554] [ INFO] - Using download source: huggingface
[日志] [2025-09-12 22:17:53,554] [ INFO] - Loading configuration file /home/aistudio/data/models/PaddlePaddle/ERNIE-4.5-21B-A3B-Thinking/config.json
[日志] [2025-09-12 22:17:53,555] [ WARNING] - You are using a model of type ernie4_5_moe to instantiate a model of type . This is not supported for all configurations of models and can yield errors.
[日志] [2025-09-12 22:17:53,569] [ INFO] - Using download source: huggingface
[日志] [2025-09-12 22:17:53,569] [ INFO] - Loading configuration file /home/aistudio/data/models/PaddlePaddle/ERNIE-4.5-21B-A3B-Thinking/config.json
[日志] [2025-09-12 22:17:53,569] [ WARNING] - You are using a model of type ernie4_5_moe to instantiate a model of type . This is not supported for all configurations of models and can yield errors.
[日志] [2025-09-12 22:17:53,584] [ INFO] - Using download source: huggingface
[日志] [2025-09-12 22:17:53] [ INFO] - Application startup complete.
[日志] [2025-09-12 22:17:53] [ INFO] - Uvicorn running on http://0.0.0.0:8180 (Press CTRL+C to quit)
🎉 服务启动完成!
--------------------------------------------------
🔌 测试模型连接...
✅ 模型测试成功!
🤖 回复:
🎊 启动成功!现在可以运行知识图谱代码- 有用的链接
- metrics service at http://0.0.0.0:8181/metrics
- chat completion service at http://0.0.0.0:8180/v1/chat/completions
- ompletion service at http://0.0.0.0:8180/v1/completions
5.调用测试
主要是通过openai sdk进行调用测试。
5.1 建立对话
python
import openai
host = "0.0.0.0"
port = "8180"
client = openai.Client(base_url=f"http://{host}:{port}/v1", api_key="null")
chat_completion = client.chat.completions.create(
messages=[
{'role': 'system', 'content': '你是 AI Studio 实训AI开发平台的开发者助理,你精通开发相关的知识,负责给开发者提供搜索帮助建议。'},
{'role': 'user', 'content': '你好,请介绍一下AI Studio'}
],
model="null",
)5.2 打印推理过程
python
print(chat_completion.choices[0].message.reasoning_content)
markdown
用户现在需要我介绍AI Studio。首先,我需要回忆AI Studio的基本信息,它是百度推出的AI开发平台,主要面向开发者。需要涵盖核心功能、适用场景、技术特点等。
首先,用户可能是开发者或者对AI开发感兴趣的人,所以需要详细但易懂地介绍。需要包括平台定位、主要功能(比如模型训练、部署、推理等)、技术生态(比如支持的框架、数据源)、应用场景(比如行业解决方案、智能应用开发)。
然后,要结构清晰,分点说明。可能的结构是:平台定位、核心功能、技术特点、应用场景、生态支持。需要确保信息准确,比如是否支持PyTorch、TensorFlow,是否有开源模型库,是否有GPU加速等。
还要注意用户可能的深层需求,比如是否适合新手入门,是否有免费资源或企业服务,是否需要编程基础。但用户的问题比较基础,可能不需要太深入,但可以简要提到。
需要避免使用过于专业的术语,保持口语化,但作为开发助理,需要专业但易懂。比如"全流程AI开发"可以解释为从数据准备到模型部署的全流程支持。
另外,AI Studio的最新版本或更新可能需要提及,但用户没有指定时间,所以可以一般性。比如是否有新的智能体功能,或者与百度文库、百度网盘的集成等。
还要考虑用户可能的实际应用,比如教育、企业服务、个人项目,所以应用场景部分需要覆盖这些方面。
总结,结构大致如下:
1. 平台定位:百度推出的AI开发平台,支持全流程AI开发。
2. 核心功能:数据管理、模型训练、推理部署、应用集成。
3. 技术支持:支持PyTorch、TensorFlow等框架,提供预训练模型。
4. 生态资源:开源模型库、数据集、行业解决方案。
5. 应用场景:教育、企业智能升级、智能硬件开发等。
6. 优势特点:低代码、GPU加速、企业级服务。
需要确保信息准确,比如是否确实支持这些框架,是否有这些功能。可能需要确认,但根据已有知识,AI Studio确实支持这些。
最后,语言要友好,符合开发助理的角色,帮助开发者快速了解平台。5.3 打印推理日志
python
print(chat_completion.choices[0].message.content)
markdown
AI Studio 是百度推出的全栈式 AI 开发与服务平台,旨在为开发者、企业及科研机构提供从模型训练、部署到应用落地的全流程 AI 开发支持。以下从核心定位、关键功能、技术生态及应用场景等方面为你详细介绍:
### **一、平台定位**
AI Studio 的核心定位是**"智能时代的开发者工具与平台"**,聚焦于解决 AI 开发中"数据管理复杂、模型训练低效、部署困难"等痛点,通过"低代码+高性能"的组合,降低 AI 开发门槛,加速 AI 技术从实验室到产业的落地。
### **二、核心功能**
AI Studio 的功能覆盖 AI 开发的全生命周期,主要包括:
- **数据管理与处理**:支持从数据上传、清洗、标注到分割的全流程操作,集成数据增强工具(如图像裁剪、旋转、归一化),支持 CSV、JSON、Parquet 等多种格式数据导入。
- **模型训练与调优**:提供 PyTorch、TensorFlow、PaddlePaddle 等主流深度学习框架的支持,内置自动超参数调优(如 Bayesian Optimization)、模型压缩(如通道剪枝、量化)等功能,支持分布式训练加速。
- **模型部署与推理**:支持模型导出为 ONNX、TensorRT 等格式,提供 API 调用、容器化部署(如 Docker),并支持百度智能云、阿里云等云服务集成,满足线上/本地部署需求。
- **智能应用开发**:集成智能对话、图像识别、文本分析等场景的预训练模型,支持通过可视化界面或代码快速构建智能应用(如智能客服、智能质检系统)。
### **三、技术特点与优势**
- **高性能计算支持**:深度整合百度智能云 GPU 资源,支持 GPU 加速训练与推理,降低高并发场景下的计算成本。
- **低代码与高扩展性结合**:提供可视化开发界面(如"模型训练-评估-部署"一站式面板),同时支持 Python/PaddleCode 等代码开发,满足进阶开发者灵活需求。
- **行业生态整合**:内置大量行业预训练模型(如金融风控、医疗影像、智能制造),覆盖 200+ 场景;同时支持与百度文库、百度网盘等生态互通,便捷获取数据与资源。
- **企业级服务**:提供团队协作、权限管理、模型监控等功能,支持企业私有化部署,满足中大型企业的数据安全与合规需求。
### **四、典型应用场景**
- **教育与研究**:高校/实验室快速搭建 AI 实验环境,支持从数据标注到模型验证的全流程教学。
- **企业智能升级**:帮助制造业、零售业等企业构建智能质检、智能推荐、智能客服系统,提升生产效率与用户体验。
- **智能硬件开发**:与智能设备(如机器人、智能家居)集成,通过 AI Studio 训练的模型可直接部署到终端设备。
- **行业解决方案**:金融风控(反欺诈)、医疗影像(病灶检测)、自动驾驶(感知与决策)等领域的定制化 AI 开发。
### **五、生态与资源**
- **开源社区**:AI Studio 开放大量预训练模型(如 PaddleSeg、PaddleOCR)、数据集(如 CV、NLP 领域公开数据集),支持开发者复用与改进。
- **学习资源**:提供海量教程、案例(如"图像分类实战""对话系统构建")、文档与视频课程,助力开发者快速入门。
总之,AI Studio 是百度为 AI 开发者打造的全能工具平台,通过"低门槛+高性能+生态整合"的设计,帮助开发者高效完成从模型开发到产业落地的全流程工作,是当前国内主流的 AI 开发平台之一。四、总结
- 需配备 80GB 显存的 GPU 资源(单卡)
- 部署本模型需使用 FastDeploy 2.2 版本
- 下载模型可能会中断,需要多尝试几次
- 推理过程非常详尽
- 生成结果非常优秀