TabNet
1、原理
核心目标是想在深度学习领域实现树模型类似的功能,其整体框架是输入通过一个标准化模块后通过特征转换模块分成两块,一块送到注意力模块中获取接下来要选择特征的mask,一部分通过relu变化输出;mask部分继续通过特征转化模块,分成两块重复上一步的处理,多次执行,得到的输出加起来通过全连接给到下游任务使用(如回归任务,分类任务);同时该框架还支持输出特征贡献度.
通过多步转换选择输出的模式,实现类似树多层的特征选择划分过程,其论文中的实验也证明其有效性,这里不再展开.
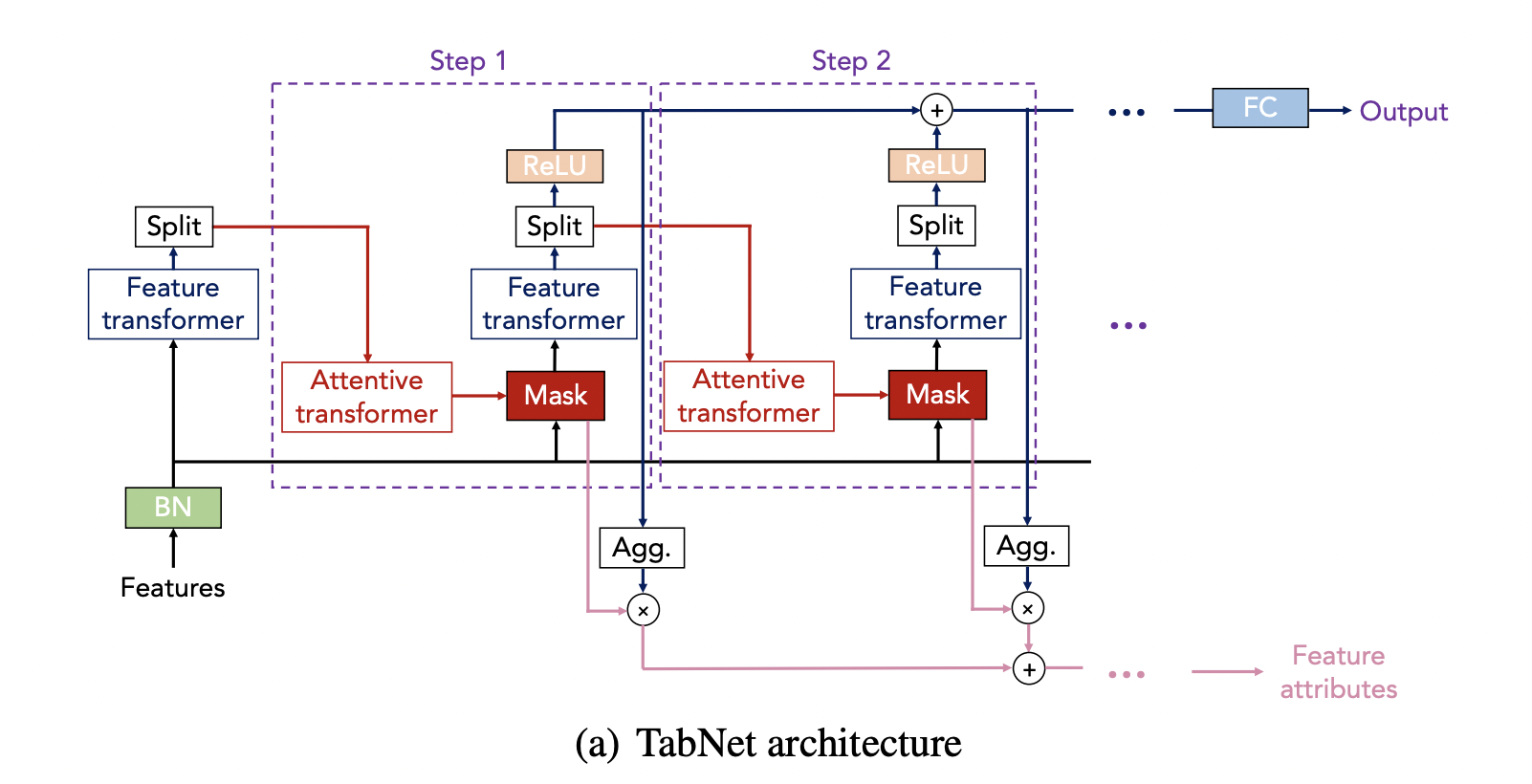
1.1 模块原理功能介绍
- 标准化模块:其中实现了Ghost Batch Normalization(GBN )将一个大的 Batch 划分为若干个小的"虚拟Batch"(ghost batches),在每个小Batch上独立计算均值和方差用于归一化;该标准化的特点是简单好实现,小 batch 的统计量波动性更大,引入了额外的噪声,相当于隐式的正则化,在兼容大batch下保持小batch的优势;然过于波动也可能会导致训练不稳定,其虚拟batch大小也需要依靠经验设置.
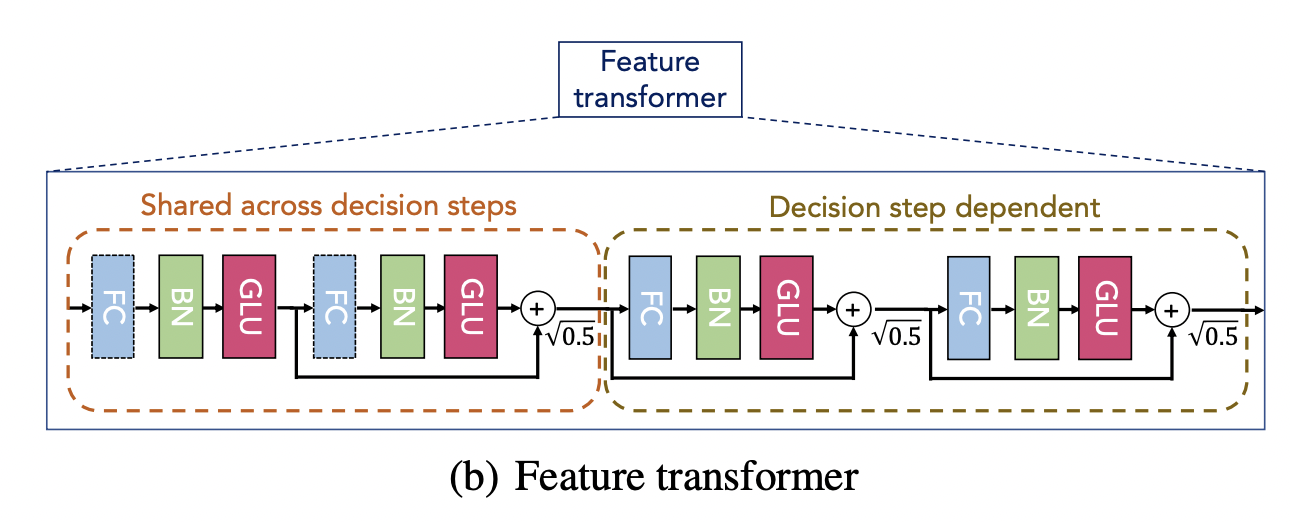
- 特征转换模块,其构成分为共享决策层与独立决策层,层之间添加残差连接,增强稳定性,每层是由全连接,BatchNorm 与非线性变换单元GLU构成.共享层的原因 可以看到整体方案,每一次选择都是从原始输入进行选择,这意味着在转化的浅层中存在共享信息,这样设计可以高效、稳定地抽取tabular数据的基础、通用特征,避免参数冗余,同时为后续每个decision step的个性化专家系统提供坚实、高效的特征基础.
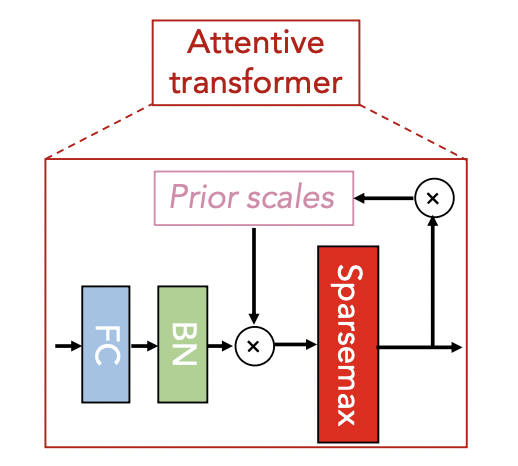
- 注意力掩码模块:特征转化层输出的一部分给到该模块,先通过全连接与BatchNorm,然后乘以一个优先级矩阵,通过一个稀疏函数得到mask矩阵输出;其计算公式如下所示,第一个公式是M掩码矩阵计算公式,输入a通过h(全连接)乘以优先级矩阵,通过稀疏函数变换得到;接下来通过掩码更新优先矩阵(初始为单位矩阵),使用一个参数 γ \gamma γ来调节后续特征选择的软硬程度,若参数为1,则前面选到过的特征就不会再次被选,因此参数小于1,可以让更多特征参与选择.通常设置在(0.1,2)之间.
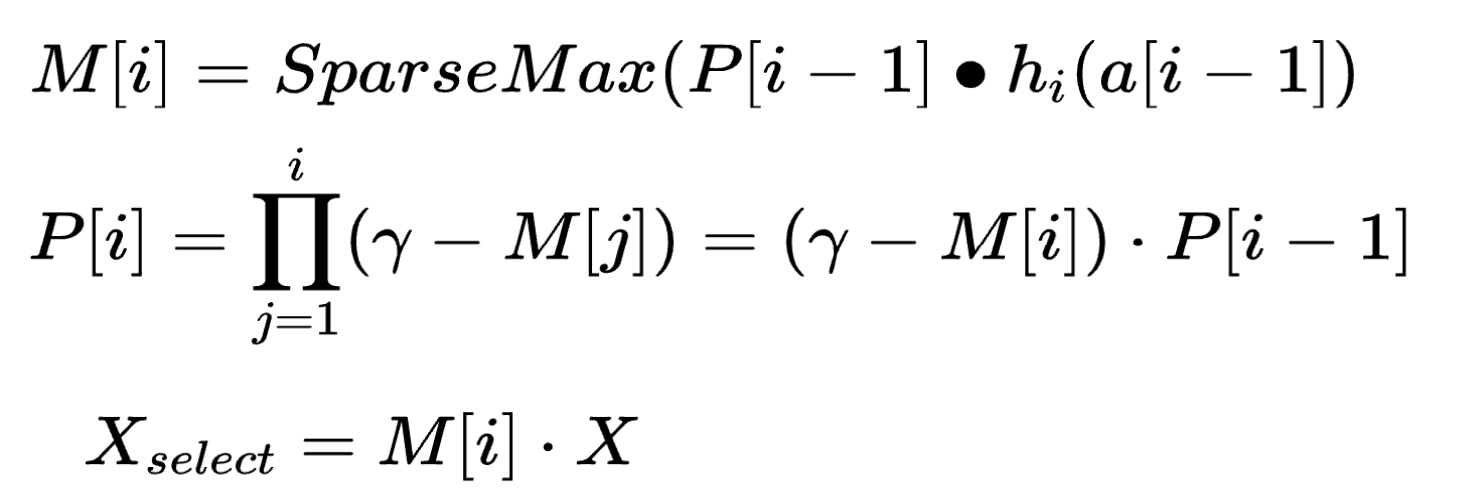
值得注意的是论文里在此处还设计了一个稀疏损失函数,通过掩码熵得到,目的是得到更稀疏的特征,该设计通常在有冗余特征的场景中比较有效.

1.2 数据流转
- 特征输出
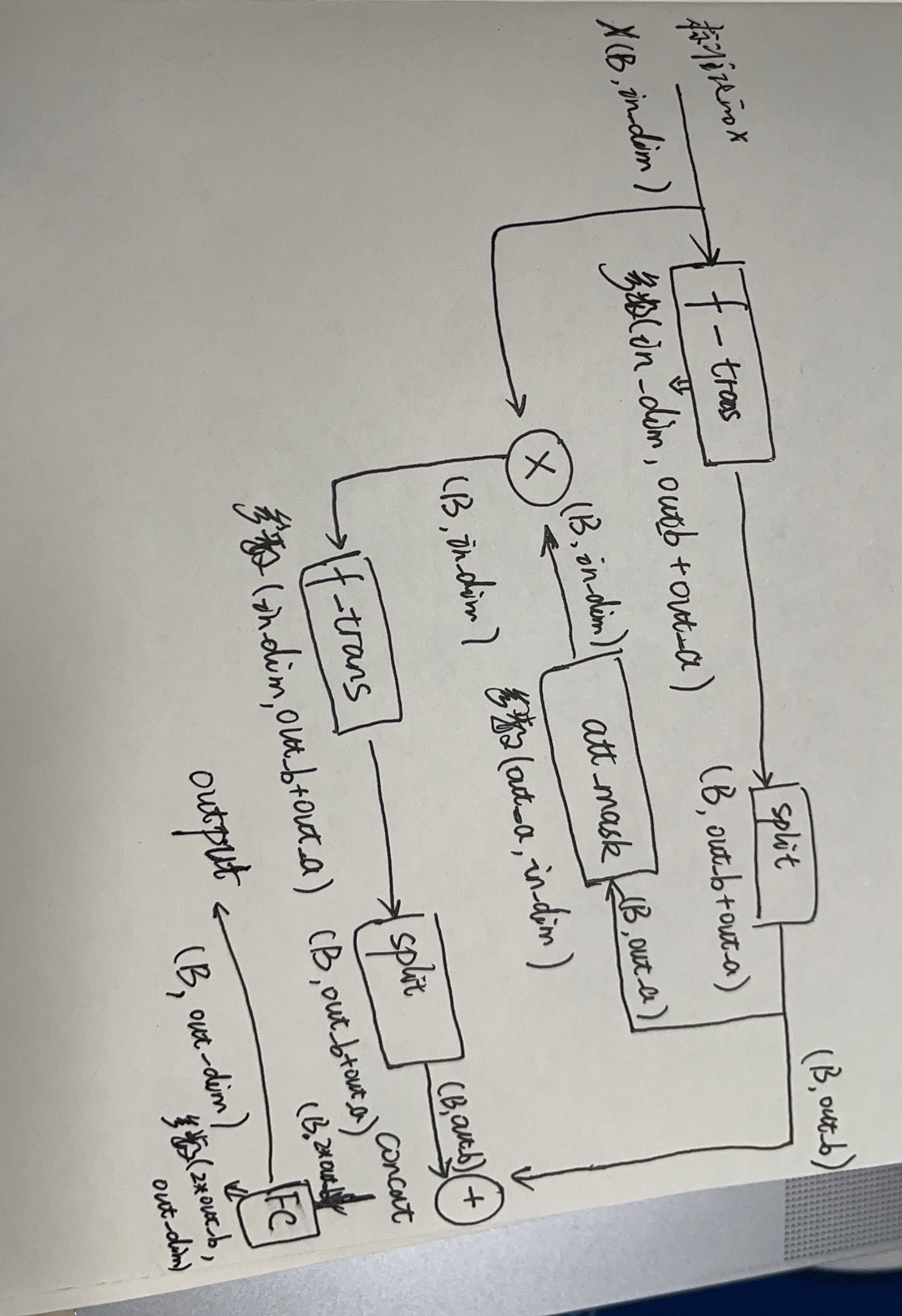
输入(Batch_size,F_dims),其中输入数值型无需做标准化,可以通过batchNorm进行标准化,类别型需要提前做embedding.给到特征转化模块输出维度为(Batch_size,out_b+out_a),输出维度是为了后续划分作准备,out_b为输出部分,out_a为给大注意力模块获取mask部分.mask维度如果没有特别指定将为输入维度,乘以原始输入得选择特征,依次循环多步;每步的输出拼接起来给到后续输出层,其中两步的数据流转如下图所示.
- 特征重要性输出
其重要性由多步mask掩码矩阵跟输出的out_b统计计算得到,单个样本其一列特征重要性计算如公式所示,原理比较好理解不再进一步说明, M b j M_{b}^{j} Mbj就代表样本b其特征j在所有步,整体特征中的重要性.
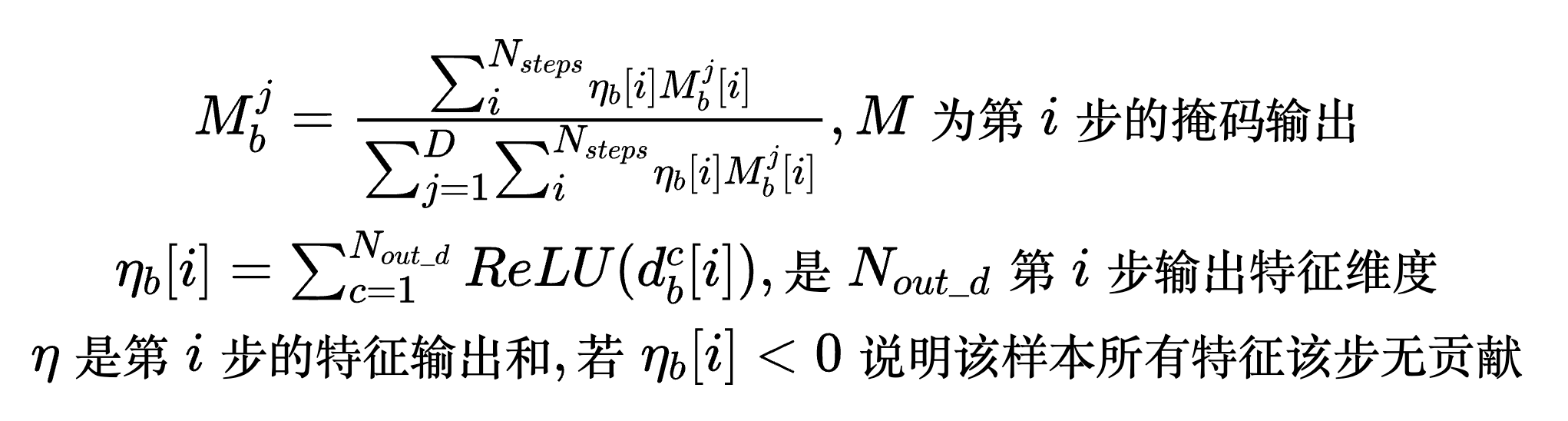
2、应用
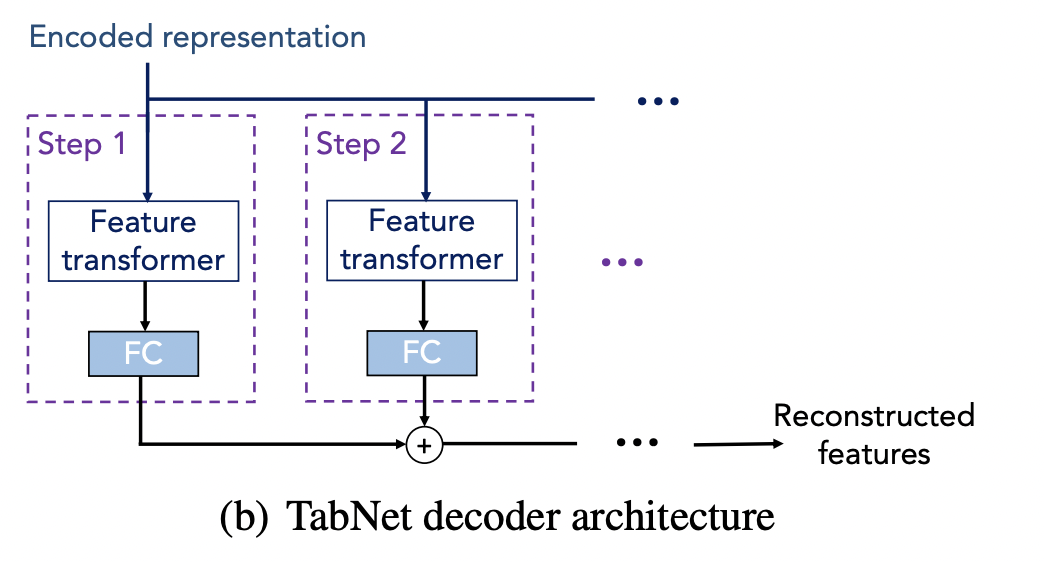
前面的整体图展示的是encoder,encoder 的输出可以直接给到输出模块如mlp进行回归,分类等任务;比较特别的是还可以进行无监督训练如特征空缺补齐任务,其在encoder的输出后面接了一个decoder ,通过多步的特征转换层,拼接起来给到重构层得到输出,重构层通常可以用线性层其输出维度与原始输入维度一样,这样就可以计算输出与输入特征之间的loss,来进行训练.
3、实现
该模型已在pytorch-tabnet库中实现了,其中包括encoder,decoder,特征重要性计算,以及输入前的类别型特征嵌入,预训练均可找到相关类与方法.
其应用可以将模型当做一个模块构建自己的完整模型,如引入encoder
python
from pytorch_tabnet.tab_network import TabNetEncoder
#TabNetEncoder 参数如下
def __init__(
self,
input_dim, #输入维度
output_dim,#输出维度
n_d=8,#划分特征输出部分维度
n_a=8,#划分掩码输入部分维度
n_steps=3,#决策步数
gamma=1.3,#优先矩阵里的参数(0.1,2)
n_independent=2,#特征转化层中独立的层数
n_shared=2,#特征转化层中共享的层数
epsilon=1e-15,#最小值,防止出现0
virtual_batch_size=128,#虚拟batch_size大小
momentum=0.02,#动量参数
mask_type="sparsemax",#稀疏化方法
group_attention_matrix=None,#掩码输出是否分组,无默认维度为输入维度,有则需要相乘该矩阵再得mask
):也可以直接使用其高度包装好的应用实现的类进行任务训练预测,如分类预测,其损失函数,评价指标都是内定的,直接掉包使用即可.
python
from pytorch_tabnet.tab_model import TabNetClassifier, TabNetRegressor
clf = TabNetClassifier() #TabNetRegressor()
clf.fit(
X_train, Y_train,
eval_set=[(X_valid, y_valid)]
)
preds = clf.predict(X_test)