Redis高级面试题解析:深入理解Redis的工作原理与优化策略
Redis是一个广泛应用于高并发场景的内存数据库系统,具备非常高的性能和灵活性。为了深入了解Redis的工作原理以及如何高效使用它,面试官可能会问到一些高级问题。以下是一些常见的高级Redis面试问题和解答,帮助你更好地准备面试。 编辑
编辑
1. Redis为什么快?
Redis之所以快速,主要有以下几个原因:
- 内存存储 :Redis将数据存储在内存中,避免了磁盘I/O操作,因此能够提供极快的读写速度。相比于传统的基于磁盘的数据库,内存操作几乎是瞬时的。
 编辑
编辑 - 数据结构优化:Redis内部使用了高度优化的数据结构(如哈希表、跳表、链表等),并通过高效的算法实现这些数据结构的操作。每种数据结构都根据不同的应用场景进行优化,以提高性能。
- 单线程模型 :Redis采用单线程处理请求,避免了多线程环境中的线程切换和同步开销。在处理大量小请求时,单线程模型能够更高效地利用CPU资源。
 编辑
编辑
2. Redis是怎么实现原子性的?
Redis通过以下方式实现原子性:
- 单线程模型:Redis通过单线程执行命令,保证了命令的顺序执行,因此任何命令在Redis中都是原子的。即使多个客户端同时发出命令,Redis会按顺序处理这些命令,保证数据的一致性。
- 事务支持 :Redis支持事务(通过
MULTI、EXEC命令),所有在MULTI和EXEC之间的命令都将被批量执行,Redis保证它们在执行过程中不会被其他命令干扰。 - 乐观锁 :使用
WATCH命令可以为指定的键添加一个"监视"功能。如果键在事务执行之前发生变化,事务会失败,从而保证了数据的一致性和原子性。
3. Redis为什么要用单线程?最新的Redis 6.0用了多线程,是怎么实现的?
单线程的优势:
- 简单高效:Redis采用单线程模型,这避免了多线程中的线程切换和同步问题,降低了复杂性,减少了上下文切换的开销。
- 充分利用内存:Redis的操作本质上是内存操作,单线程模型使得内存操作不会受到线程切换的影响,从而获得高效的性能。
- 命令顺序执行:由于所有命令都是顺序执行的,因此可以避免复杂的锁机制,从而减少潜在的竞争条件。
Redis 6.0的多线程支持:
在Redis 6.0中,虽然Redis仍然使用单线程来处理命令的执行,但它引入了多线程来优化某些操作,特别是网络I/O。Redis 6.0中的多线程主要用于:
- 网络I/O操作:通过引入多线程,Redis可以并行处理多个客户端的请求,从而提升处理大量连接时的性能。
- 阻塞命令 :如
BLPOP、BRPOP等阻塞式命令的执行可以使用多线程来减少主线程的阻塞时间。
多线程的引入并没有改变Redis的单线程命令执行模型,单个命令的执行依然是原子的,只有在并发连接的处理上增加了多线程的支持。
4. Redis的跳表了解吗?数据结构是怎么样的,查询的时间复杂度是多少?
Redis的有序集合(Sorted Set)是基于跳表(Skip List)实现的。跳表是一种可以支持快速查询、插入、删除操作的概率数据结构。它通过多级索引的方式来加速搜索过程,类似于二分查找。
- 跳表的数据结构 :跳表由多个层次的链表构成,每一层的元素数量比下一层少,最底层包含所有元素,其他层则是通过随机算法选取部分元素来作为索引。
- 查询的时间复杂度:跳表的查询操作时间复杂度为O(log N),这是因为每次查询可以跳过一部分元素,从而大大加速了查询过程。
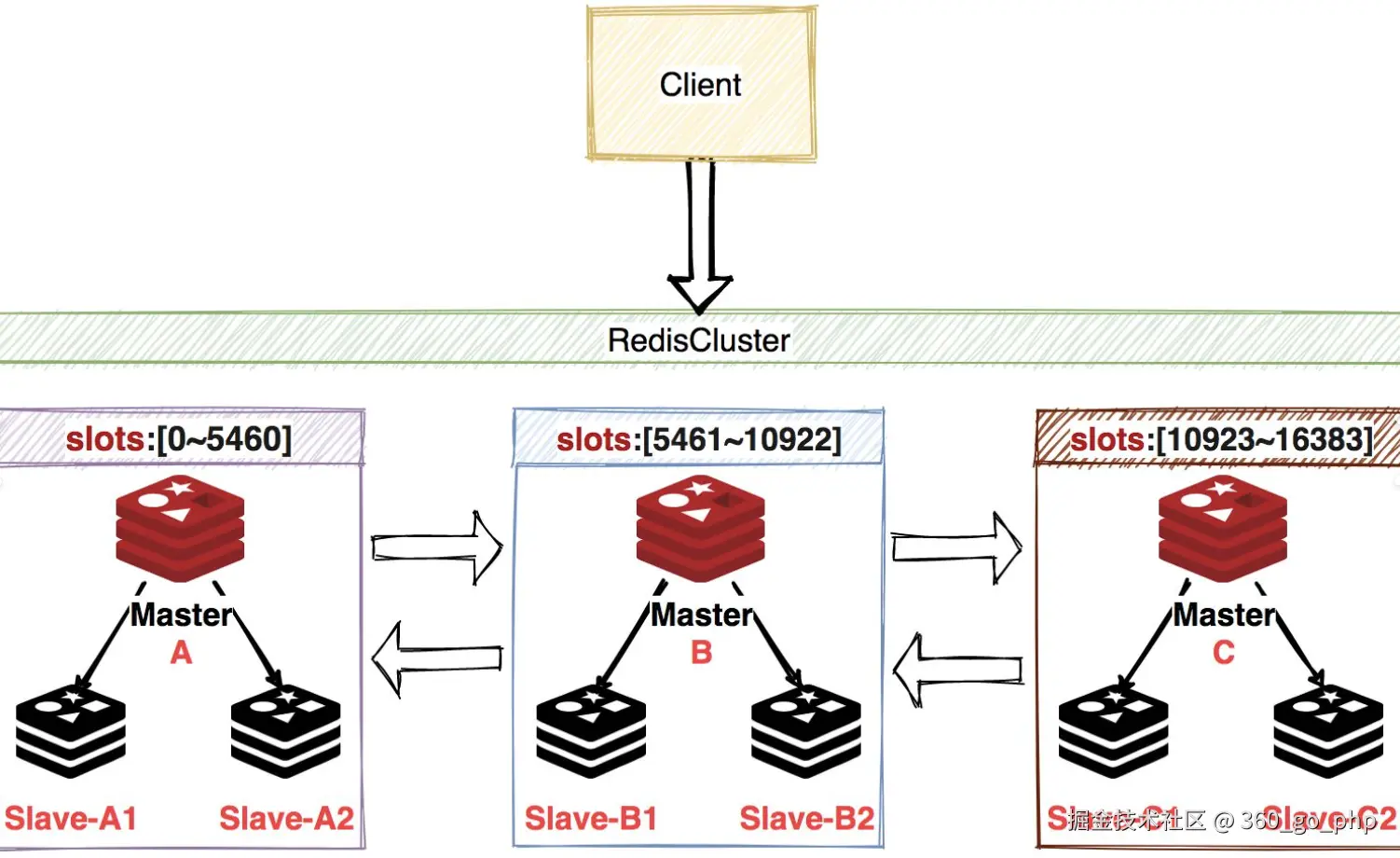
5. Redis的哨兵模式和集群模式,具体是怎么配置的,了解吗?
Redis的哨兵模式(Sentinel):
Redis Sentinel是用于Redis高可用性和故障转移的工具。通过哨兵模式,Redis可以自动进行故障转移,当主节点不可用时,哨兵会自动将某个从节点提升为新的主节点。
配置步骤:
- 启动多个哨兵实例(通常至少3个)。
- 配置每个哨兵实例的监控目标主节点(
sentinel monitor)。 - 配置故障转移规则(
sentinel failover-timeout)。 - 配置哨兵的通信方式和报警机制。
Redis的集群模式(Cluster):
Redis集群模式通过分片机制将数据分散到多个节点上,从而提高了Redis的水平扩展能力。
配置步骤:
- 准备多个Redis节点,至少需要6个节点(3个主节点和3个从节点)。
- 启动集群模式,通过
redis-trib工具进行集群的创建和管理。 - 配置每个节点的集群信息,包括节点角色、IP和端口等。
6. Redis的分布式锁用过吗?怎么用的?
Redis分布式锁通常通过SETNX命令来实现。SETNX只有在指定的键不存在时,才会设置值,因此可以作为分布式锁的原子操作。
示例:
bash
SETNX lock_key 1 # 设置锁
EXPIRE lock_key 30 # 设置锁的过期时间 - 在获取锁时,客户端尝试通过
SETNX获取锁,如果成功返回,表示锁被成功获取。如果失败,则说明锁已被其他客户端占用。 - 设置锁的过期时间是为了防止死锁(如果客户端持有锁的过程中出现异常,锁不会永远被占用)。
7. Redis单实例的QPS是多少?最新的6.0 QPS多少知道吗?
- Redis单实例的QPS(每秒查询数)取决于硬件配置、数据大小和操作类型。一般情况下,Redis可以支持数十万到上百万QPS的读写操作。
- Redis 6.0通过多线程优化了网络I/O操作,因此在高并发的环境下能够提升性能,但具体的QPS也会受到实际硬件和部署环境的影响。
8. Redis的大Key多大算大?单个Redis实例建议多大内存?
- 大Key的定义 :Redis中的大Key通常指的是占用内存较多的键。大Key不仅占用大量内存,还可能导致性能问题,尤其是当Redis需要处理多个大Key时。通常认为,如果一个键的内存占用超过几百兆甚至几GB,就可以算作大Key。
- 内存配置建议:Redis实例的内存大小应根据实际应用需求进行配置。一般来说,单个Redis实例的内存限制在几十GB到几百GB之间。需要根据业务规模和数据量合理规划内存使用,以避免内存不足的情况。
9. 写时复制(Copy-on-Write)了解吗?在Redis哪里用到了?
写时复制(COW)是一种优化内存管理的技术,它延迟复制数据,直到写操作发生时才真正复制数据。在Redis中,COW主要在RDB持久化和AOF持久化中应用,尤其是在BGSAVE(后台保存RDB快照)操作中,Redis会使用COW技术来避免在保存快照的过程中影响主线程的性能。
10. Redis的网卡如果被打爆了,怎么办?
当Redis的网络带宽被打爆时,可以考虑以下几种解决方案:
- 增加带宽:扩展网络资源,增加更多的网卡和带宽。
- 负载均衡:使用代理或负载均衡器(如HAProxy)来分散请求,避免单一节点过载。
- 使用集群:通过Redis集群将请求分布到多个节点上,从而减轻单个节点的负载。
11. Redis缓存和本地缓存是怎么配合使用的,数据的一致性是如何解决的?
Redis缓存和本地缓存的配合使用通常是为了提高读取性能。Redis作为集中式缓存存储,而本地缓存则用于存储短期内访问频繁的数据。
数据一致性问题:
- 本地缓存更新时需要同步到Redis,或者定期从Redis拉取数据。
- 如果缓存失效,需要重新从数据库中加载数据。
- 使用合适的缓存过期策略和缓存同步机制,确保数据一致性。
12. 如何使用Redis做异步队列?
使用Redis作为异步队列通常是通过利用其列表 数据结构(list)来实现的。一个常见的做法是使用Redis的LPUSH和BRPOP命令来实现生产者-消费者模型。下面是一个简单的实现步骤:
1. 基本概念
- 生产者(Producer):向队列中推送任务。
- 消费者(Consumer):从队列中取出任务并执行。
2. 使用Redis列表(List)做异步队列
Redis的列表结构可以完美地充当一个队列。生产者将任务加入队列,消费者从队列中取出任务并处理。
3. 生产者推送任务
生产者通过LPUSH将任务加入到队列中(列表的头部),例如:
bash
LPUSH myqueue "task1"
LPUSH myqueue "task2" 这里,myqueue是队列的名称,task1和task2是任务内容。
4. 消费者拉取任务
消费者通过BRPOP命令从队列中取出任务。BRPOP是阻塞式操作,它会在队列为空时阻塞,直到队列中有新任务加入。
bash
BRPOP myqueue 0 这里,0表示阻塞的超时时间,0表示无限期阻塞,直到有任务被加入队列。
5. 异步队列实现流程
- 生产者:不断地将任务推送到Redis队列中。
- 消费者:不断地从队列中取出任务并处理。消费者可以是多个进程或线程,彼此独立,保证任务的异步处理。
6. 完整示例:Python实现
下面是一个简单的Python实现,使用redis-py库:
生产者(Producer)代码:
python
import redis
# 连接到Redis
r = redis.Redis(host='localhost', port=6379, db=0)
# 推送任务到队列
def push_task(task):
r.lpush('myqueue', task)
print(f"任务 {task} 已加入队列")
# 示例:生产者向队列推送任务
push_task("task1")
push_task("task2") 消费者(Consumer)代码:
python
import redis
# 连接到Redis
r = redis.Redis(host='localhost', port=6379, db=0)
# 阻塞式地从队列中取出任务并处理
def consume_task():
while True:
task = r.brpop('myqueue')[1].decode('utf-8')
print(f"消费者正在处理任务: {task}")
# 处理任务逻辑
# 例如:任务完成后可以进行回调或进一步操作
# 示例:消费者从队列中消费任务
consume_task() 运行流程:
- 生产者向队列中推送任务(例如,
task1、task2)。 - 消费者从队列中取出任务并处理。当队列为空时,消费者会阻塞,直到有新任务加入。
7. 扩展:并发消费
如果你需要多个消费者并发地消费任务,可以启动多个消费者进程(例如,通过多线程或多进程)。Redis的BRPOP操作本身是阻塞的,所以多个消费者会共享同一个队列,并且Redis会保证每个任务只被一个消费者消费。
8. 任务重试与错误处理
如果任务处理失败,消费者可以根据需要将任务重新加入队列进行重试。例如,如果任务发生错误,可以使用LPUSH将任务重新推送回队列,或者将任务存入一个"死信队列"中,以供后续人工干预。
9. 延迟队列(可选)
你还可以实现一个延迟队列来控制任务的执行时间。Redis的ZADD命令(有序集合)可以按时间戳来延迟任务的执行。 编辑
编辑
总结
通过使用Redis的列表结构,你可以非常方便地实现一个异步队列。LPUSH和BRPOP命令帮助你将任务推入队列并从队列中取出任务处理,适用于生产者-消费者模式。这样,你的任务可以异步执行,提高系统的吞吐量和并发处理能力。