🎯 HashMap源码深度解析:从"图书馆"到"智能仓库"的进化史
🚀 开篇:一个程序员的一天
场景1:新手的困惑 😅
arduino
// 小李刚学Java,写下了这样的代码
HashMap<String, String> map = new HashMap<>();
map.put("name", "小李");
map.put("age", "25");
map.put("city", "北京");
// 内心OS:这个HashMap到底是什么?为什么叫HashMap?
// 为什么我put进去的数据,get的时候能快速找到?场景2:面试官的连环炮 🎯
面试官:HashMap的底层实现是什么?JDK7和JDK8有什么区别?
小李:额...底层是数组+链表?JDK8好像加了红黑树?
面试官:那为什么JDK8要加红黑树?什么情况下会用到红黑树?
小李:😰(内心:完了,又要回去等通知了...)
场景3:生产环境的噩梦 😱
arduino
// 某电商系统,双11期间
// 用户查询商品信息时,系统突然变得很慢
// 排查发现:HashMap在大量数据下性能急剧下降
// 老板:这个bug必须在今天修复!💡 本文目标:让HashMap变得简单有趣
🎪 我们将用"图书馆"和"智能仓库"的比喻,带你轻松理解HashMap的进化史!
学习路径:
- 🏠 第1站:HashMap就像一个大图书馆
- 🔍 第2站:JDK7的"传统图书馆"管理方式
- 🚀 第3站:JDK8的"智能仓库"升级改造
- 🎯 第4站:实际应用中的最佳实践
版本说明 :基于 JDK 7u80 和 JDK 8u291,用最简单的方式解释最复杂的技术!
🏠 第1站:HashMap就像一个大图书馆
🎭 生活化理解:HashMap = 智能图书馆
想象一下,你走进了一个巨大的图书馆:
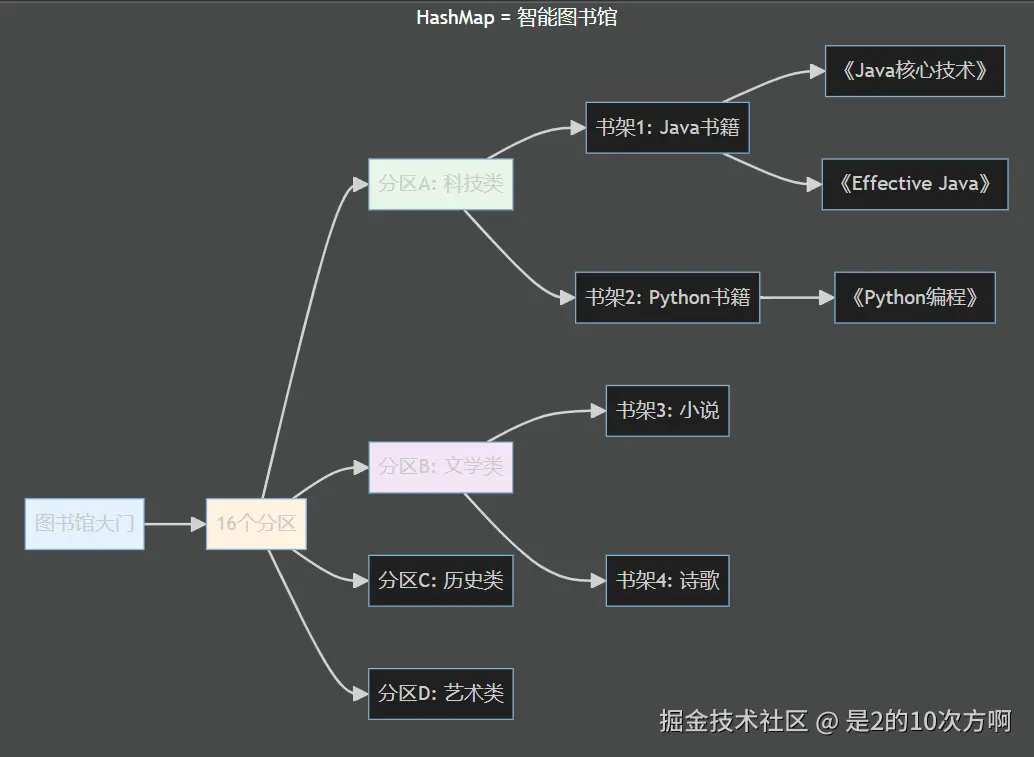
📚 图书馆的工作原理
1. 分区规则(哈希函数)
ini
// 就像图书馆管理员会根据书名决定放在哪个分区
String bookTitle = "Java核心技术";
int sectionNumber = bookTitle.hashCode() % 16; // 决定放在哪个分区2. 书架管理(数组+链表)
- 每个分区有多个书架(数组)
- 同一书架上的书按顺序排列(链表)
- 新书总是放在书架的最前面(头插法)
3. 查找书籍(get操作)
arduino
// 小李想找《Java核心技术》
// 1. 先根据书名计算分区号
// 2. 到对应分区
// 3. 在书架上按顺序查找
String targetBook = "Java核心技术";
// 管理员:让我看看这本书在哪个分区...🤔 思考题:传统图书馆的问题
问题1:如果某个分区(比如"Java"相关书籍)特别受欢迎,书架上的书越来越多怎么办?
问题2:当书架上的书超过8本时,找书是不是变得很慢?
问题3:有没有更好的方式来管理这些书籍?
💡 这就是JDK8要解决的问题!让我们继续往下看...
🚀 HashMapDemo:从代码到源码的完整追踪
1. 完整的HashMapDemo示例
csharp
/**
* 🎪 HashMapDemo - 从"小白"到"大神"的完整学习路径
*
* 这个简单的例子背后,隐藏着HashMap的所有秘密!
* 让我们一步步揭开它的神秘面纱...
*/
public class HashMapDemo {
public static void main(String[] args) {
System.out.println("🎯 开始我们的HashMap探索之旅!");
// 🏠 第1步:创建一个"智能图书馆"
// 这就像在图书馆门口拿到一张"借书卡"
HashMap<String, String> map = new HashMap<>();
System.out.println("✅ 图书馆创建成功!默认有16个分区");
// 📚 第2步:存入一本"书"(添加键值对)
// 就像把《Java核心技术》这本书存到图书馆
map.put("name", "是2的10次方啊");
System.out.println("📖 成功存入:name -> 是2的10次方啊");
// 💡 幕后发生了什么?
// 1. 计算"name"的哈希值
// 2. 根据哈希值决定放在哪个分区
// 3. 在对应分区的书架上存放这本书
// 🔍 第3步:查找这本"书"(获取值)
// 就像在图书馆里寻找《Java核心技术》
String s = map.get("name");
System.out.println("🔎 查找结果:" + s);
// 💡 幕后发生了什么?
// 1. 计算"name"的哈希值(和存入时一样)
// 2. 根据哈希值找到对应分区
// 3. 在分区的书架上查找这本书
// 4. 找到后返回书的内容
// 🎉 第4步:展示结果
System.out.println("🎊 最终结果:" + s);
System.out.println("\n🤔 思考:为什么HashMap能这么快找到数据?");
System.out.println(" 答案就在下面的源码分析中...");
}
}2. 核心方法调用链
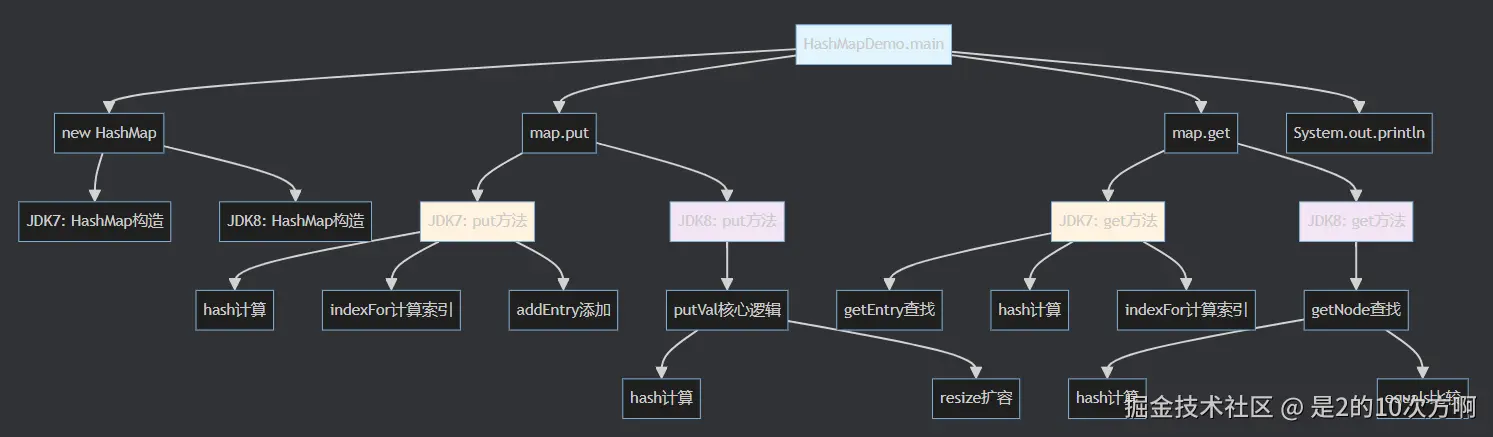
调用链说明:
- 蓝色:主程序入口(就像图书馆的入口)
- 橙色:JDK 7方法调用(传统图书馆的管理方式)
- 紫色:JDK 8方法调用(智能仓库的管理方式)
💡 小贴士:JDK8把复杂的逻辑分离到了专门的方法中,就像图书馆有了专门的"图书管理员"和"书架管理员"!
🔍 第2站:JDK7的"传统图书馆"管理方式
🏛️ 传统图书馆的建立
想象一下,JDK7时代的图书馆就像传统的图书馆:
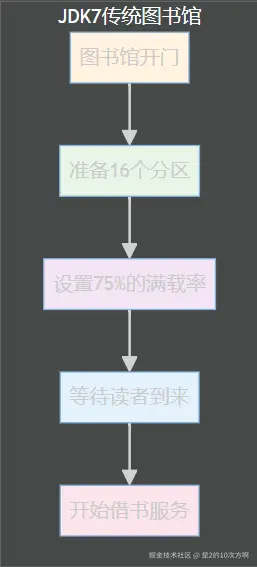
1. 图书馆的"开门仪式"(无参构造方法)
csharp
/**
* 🏛️ 传统图书馆开门啦!
*
* 就像传统的图书馆一样,JDK7在开门时就准备好了所有东西:
* - 16个分区(DEFAULT_INITIAL_CAPACITY = 16)
* - 75%的满载率(DEFAULT_LOAD_FACTOR = 0.75)
*/
public HashMap() {
// 调用有参构造方法,就像图书馆馆长说:
// "准备16个分区,当75%的座位坐满时,我们就需要扩建了!"
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}🎭 生活化理解:
- 就像传统图书馆,开门时就规划好了一切
- 16个分区 = 16个书架区域
- 75%满载率 = 当75%的座位被占用时,就需要扩建图书馆
🤔 思考题:为什么是16和0.75?
问题1:为什么默认容量是16,而不是10或20?
问题2:为什么负载因子是0.75,而不是0.5或1.0?
💡 提示:想想图书馆的实际运营,什么时候需要扩建?扩建多少合适?
💡 为什么这样设计?
🎯 核心思想:就像传统图书馆开门时就规划好一切!
- 📋 提前规划:避免临时手忙脚乱
- 💰 成本控制:避免频繁扩建浪费
- 🎯 简单管理:规则明确,易于执行
🎪 答案揭晓:为什么是16和0.75?
问题1答案:为什么是16个分区?
arduino
// 16 = 2^4,这是一个"魔法数字"!
// 就像图书馆喜欢用2的幂次方来分区:
// - 2个分区:科技类、文学类
// - 4个分区:科技、文学、历史、艺术
// - 8个分区:更细致的分类
// - 16个分区:最细致的分类,但不会太复杂
// 为什么不用10个分区?
// 因为10不是2的幂次方,计算分区号时会很麻烦!
int partitionNumber = bookTitle.hashCode() % 16; // 简单快速
int partitionNumber = bookTitle.hashCode() % 10; // 复杂缓慢问题2答案:为什么是75%的满载率?
arduino
// 75%是一个"黄金比例"!
// 就像图书馆的实际运营经验:
// - 50%:太浪费空间,扩建太频繁
// - 90%:太拥挤,读者体验差
// - 75%:刚刚好!既充分利用空间,又保证服务质量
// 实际例子:
// 16个分区 × 75% = 12个分区被占用时开始扩建
// 这样既不会太早扩建(浪费),也不会太晚扩建(拥挤)🎯 关键知识点
为什么是16和0.75?
- 16:2的4次方,位运算优化,扩容简单
- 0.75:时间空间的黄金平衡点,经过大量测试验证
2. 有参构造方法
csharp
public HashMap(int initialCapacity, float loadFactor) {
// 参数合法性检查
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY; // 限制最大容量
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor; // 设置负载因子
threshold = initialCapacity; // 初始阈值等于初始容量
init(); // 调用初始化方法(空实现)
}关键点:参数验证 → 设置负载因子 → 设置扩容阈值 → 调用初始化方法
💡 关键特性
防御性编程:严格的参数验证确保系统稳定性
- 边界检查:防止非法参数
- 容量控制:避免内存溢出
- 扩展预留:为子类提供扩展点
3. 图书馆的"借书流程"(put方法)
csharp
/**
* 📚 小李要借《Java核心技术》这本书
*
* 让我们看看传统图书馆是如何处理借书请求的...
*/
public V put(K key, V value) {
// 🏗️ 第1步:检查图书馆是否已经开门
// 如果还没开门,先开门准备(懒加载)
if (table == EMPTY_TABLE) {
System.out.println("🏛️ 图书馆还没开门,先开门准备...");
inflateTable(threshold); // 开门,准备书架
}
// 🔍 第2步:检查是否是特殊的"无书名"书籍
// 就像有些古籍没有书名,需要特殊处理
if (key == null) {
System.out.println("📖 发现无书名书籍,需要特殊处理...");
return putForNullKey(value);
}
// 🧮 第3步:计算这本书应该放在哪个分区
// 就像管理员根据书名计算分区号
int hash = hash(key);
System.out.println("🔢 计算分区号:" + hash);
// 📍 第4步:确定具体的书架位置
int i = indexFor(hash, table.length);
System.out.println("📍 确定书架位置:" + i);
// 🔍 第5步:检查书架上是否已经有这本书
// 就像管理员在书架上寻找是否已有相同的书
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
// 如果找到相同的书,就更新书的内容
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
System.out.println("📚 找到相同书籍,更新内容...");
V oldValue = e.value;
e.value = value; // 更新书的内容
e.recordAccess(this); // 记录借阅(LinkedHashMap使用)
return oldValue; // 返回旧书
}
}
// 📖 第6步:没有找到相同书籍,添加新书
System.out.println("📚 没有找到相同书籍,添加新书...");
modCount++; // 借阅次数+1
addEntry(hash, key, value, i); // 把新书放到书架上
return null;
}🎭 生活化理解:
- 开门检查:如果图书馆还没开门,先开门准备
- 特殊处理:处理没有书名的特殊书籍
- 分区计算:根据书名计算应该放在哪个分区
- 位置确定:确定具体的书架位置
- 重复检查:检查是否已有相同的书籍
- 添加新书:如果没有重复,就添加新书
💡 核心特性
懒加载 + 冲突处理:按需分配,智能解决冲突
- 懒加载:首次put时才初始化,节省内存
- null处理:允许一个null键,体现灵活性
- 冲突解决:链表解决哈希冲突
- 头插法:O(1)插入,但多线程不安全
JDK 7 数据结构示意图
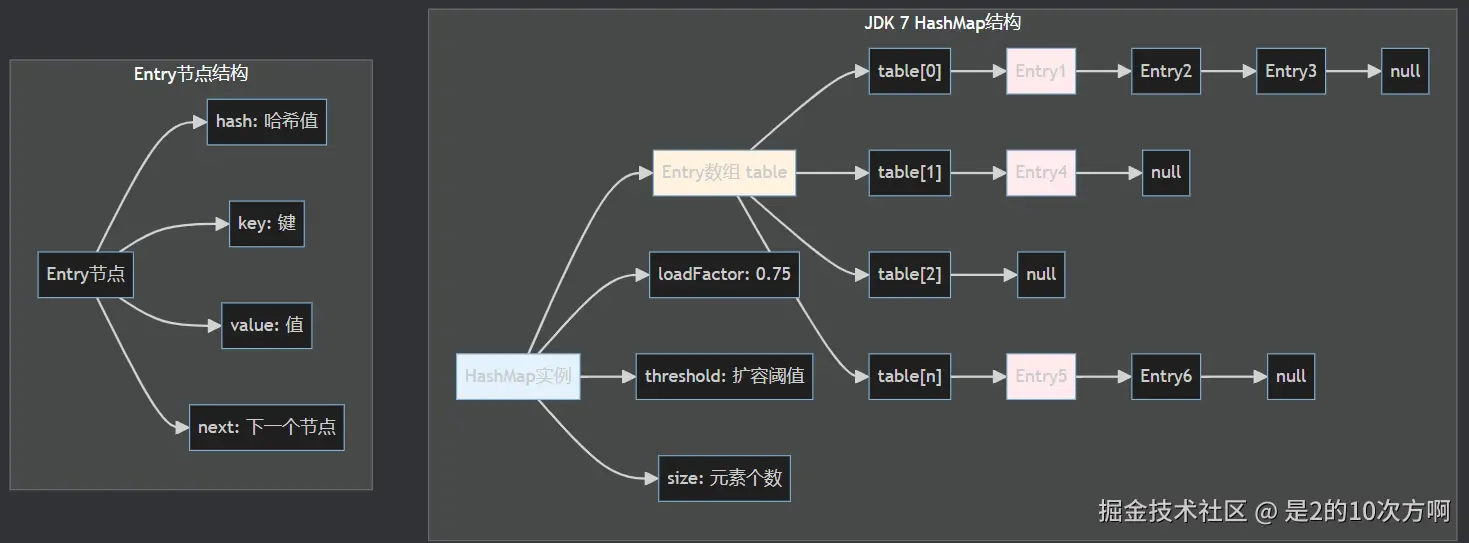
4. 关键子方法
4.1 inflateTable方法
scss
private void inflateTable(int toSize) {
// 找到大于等于toSize的最小2的幂次方(如13→16)
int capacity = roundUpToPowerOf2(toSize);
// 计算扩容阈值:容量 * 负载因子
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
// 创建Entry数组
table = new Entry[capacity];
// 初始化哈希种子(JDK 7的安全特性,防止哈希攻击)
initHashSeedAsNeeded(capacity);
}💡 性能优化
2的幂次方优化:性能优先的设计策略
- 位运算优化 :
h & (length-1)比取模快很多 - 内存对齐:有利于CPU缓存
- 扩容简单:左移一位即可
- 安全防护:哈希种子防止攻击
4.2 hash方法
scss
final int hash(Object k) {
int h = hashSeed;
// 如果是String类型且有哈希种子,使用特殊算法
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
// 哈希扰动:通过多次位移和异或操作提高散列性
h ^= k.hashCode(); // 与原始hashCode异或
h ^= (h >>> 20) ^ (h >>> 12); // 高位移位异或
return h ^ (h >>> 7) ^ (h >>> 4); // 低位移位异或
}💡 核心设计思想
设计理念:采用"哈希扰动"策略,通过多次位移和异或操作提高哈希分布的均匀性。
设计亮点:
- String特殊处理:对String类型使用专门的哈希算法
- 哈希扰动:通过位移和异或操作改善哈希分布
- 安全性:结合哈希种子防止哈希攻击
🤔 疑问自答
Q1:为什么需要对String类型特殊处理? A:String类型的特殊性:
- 使用频率高:String是最常用的key类型
- 性能优化:专门的算法比通用算法更高效
- 分布均匀:String的哈希算法经过特殊优化
Q2:为什么要进行哈希扰动? A:哈希扰动的作用:
- 改善分布:让哈希值分布更加均匀
- 减少冲突:降低哈希冲突的概率
- 提高性能:减少链表长度,提高查找效率
Q3:为什么选择这些位移位数(20、12、7、4)? A:这些数字是经过精心选择的:
- 经验值:通过大量测试得出的最优值
- 平衡性:在性能和分布之间找到平衡
- 历史原因:这些值在JDK 7中经过验证
Q4:为什么JDK 8简化了hash方法? A:JDK 8的简化原因:
- 性能考虑:简化的算法更快
- 安全性:其他安全机制已经足够
- 实用性:实际应用中简化版本已经足够好
4.3 indexFor方法
perl
static int indexFor(int h, int length) {
// 位运算替代取模运算:h % length = h & (length - 1)
// 前提:length必须是2的幂次方
return h & (length - 1);
}💡 核心设计思想
设计理念:采用"位运算优化"策略,用位运算替代取模运算,体现了"性能极致优化"的设计思想。
设计亮点:
- 位运算替代取模 :
h & (length-1)比h % length快很多 - 数学原理:利用2的幂次方的数学特性
- 性能优化:这是HashMap性能优化的核心之一
🤔 疑问自答
Q1:为什么位运算比取模运算快? A:位运算的优势:
- 硬件支持:CPU对位运算有专门优化
- 指令简单:位运算指令比除法指令简单
- 无分支:位运算没有条件判断,避免分支预测失败
Q2:为什么这个公式只在length是2的幂次方时成立? A:数学原理:
- 二进制特性:2的幂次方在二进制中只有一位是1
- 掩码效果 :
length-1形成一个完美的掩码 - 取模等价 :
h & (length-1)等价于h % length
Q3:如果length不是2的幂次方会怎样? A:会出现问题:
- 结果错误:位运算结果不等于取模结果
- 索引越界:可能产生超出数组范围的索引
- 数据丢失:某些位置永远不会被访问到
Q4:这个优化能带来多大的性能提升? A:性能提升显著:
- 理论提升:位运算比取模快3-5倍
- 实际效果:在HashMap这种高频操作中效果明显
- 累积效应:每次put/get都会受益
4.4 addEntry方法
scss
void addEntry(int hash, K key, V value, int bucketIndex) {
// 扩容条件:size >= threshold 且 目标位置不为空
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); // 扩容为原来的2倍
hash = (null != key) ? hash(key) : 0; // 重新计算哈希值
bucketIndex = indexFor(hash, table.length); // 重新计算索引
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K, V> e = table[bucketIndex]; // 获取当前位置的Entry
// 头插法:新Entry插入到链表头部,e作为next
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++; // 元素个数+1
}💡 核心设计思想
设计理念:采用"条件扩容 + 头插法"策略,体现了"性能优先"和"简单高效"的设计思想。
设计亮点:
- 条件扩容:只有在必要时才扩容,避免不必要的开销
- 头插法:新元素插入链表头部,O(1)时间复杂度
- 方法分离:将扩容逻辑和插入逻辑分离,职责清晰
🤔 疑问自答
Q1:为什么扩容条件要同时满足size >= threshold和target位置不为空? A:这个设计很巧妙:
- 避免无效扩容:如果目标位置为空,扩容后元素还是放在同一位置
- 性能考虑:减少不必要的扩容操作
- 空间利用:只有在真正需要时才扩容
Q2:为什么使用头插法而不是尾插法? A:头插法的优势:
- 性能更好:O(1)时间复杂度,不需要遍历链表
- 实现简单:代码更简洁
- 但存在问题:多线程环境下可能导致死循环(JDK 8已修复)
Q3:为什么扩容后要重新计算hash和bucketIndex? A:扩容后需要重新计算:
- 容量变化:扩容后容量翻倍,索引计算方式不变但结果可能不同
- 分布优化:重新计算可以让元素分布更均匀
- 一致性:确保扩容后的数据一致性
Q4:为什么JDK 8改为尾插法? A:JDK 8的改进:
- 线程安全:避免多线程环境下的死循环问题
- 顺序保持:保持元素的插入顺序
- 调试友好:便于调试和问题排查
🔍 JDK 8中的HashMap核心方法源码追踪
1. 无参构造方法
csharp
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // 0.75
}核心差异:只设置负载因子,其他参数延迟初始化,减少不必要的计算
💡 核心设计思想
设计理念:采用"延迟初始化"策略,体现了"按需分配"和"资源节约"的设计思想。
设计亮点:
- 延迟初始化:只在真正需要时才初始化,节省内存
- 参数简化:只设置必要的参数,其他参数按需计算
- 性能优化:减少不必要的计算和内存分配
🤔 疑问自答
Q1:为什么JDK 8要改为延迟初始化? A:延迟初始化的优势:
- 内存节省:很多HashMap实例可能不会被使用
- 构造性能:避免不必要的计算和内存分配
- 灵活性:可以根据实际使用情况动态调整
Q2:延迟初始化会带来什么问题吗? A:潜在问题:
- 首次操作延迟:首次put/get时会有额外的初始化开销
- 代码复杂性:需要在多个地方检查是否已初始化
- 但总体收益大于成本:对于大多数场景都是有益的
Q3:为什么只设置loadFactor而不设置其他参数? A:设计考虑:
- loadFactor是核心参数:影响扩容策略,必须提前设置
- 其他参数可延迟:capacity、threshold等可以按需计算
- 简化构造:让构造方法更简单,职责更清晰
2. put方法
ini
public V put(K key, V value) {
// 直接调用putVal方法,参数:hash, key, value, onlyIfAbsent=false, evict=true
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K, V>[] tab;
Node<K, V> p;
int n, i;
// 懒加载:table为空或长度为0时进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 计算索引位置,如果该位置为空,直接插入新节点
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K, V> e;
K k;
// 检查第一个节点是否就是要找的key
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果是红黑树节点,使用树插入
else if (p instanceof TreeNode)
e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);
// 链表处理:遍历链表查找或插入
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 尾插法:插入到链表尾部
p.next = newNode(hash, key, value, null);
// 链表长度达到8时,转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
// 找到相同key,跳出循环
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 如果找到了相同key,更新value
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); // 访问后处理(LinkedHashMap使用)
return oldValue;
}
}
++modCount; // 修改次数+1
// 如果超过阈值,进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict); // 插入后处理(LinkedHashMap使用)
return null;
}核心差异:方法分离设计 → 支持红黑树 → 尾插法 → 树化机制
💡 核心设计思想
设计理念:采用"多策略处理"策略,支持链表和红黑树两种数据结构,体现了"性能优化"和"自适应"的设计思想。
设计亮点:
- 红黑树支持:当链表长度超过8时自动转换为红黑树
- 尾插法:避免多线程环境下的死循环问题
- 树化机制:动态选择最优的数据结构
- 方法分离:将复杂逻辑分离到专门的方法中
🤔 疑问自答
Q1:为什么JDK 8要引入红黑树? A:红黑树的优势:
- 性能提升:最坏情况从O(n)降至O(log n)
- 解决哈希攻击:防止恶意构造的key导致性能下降
- 实际需求:大数据量场景下性能提升明显
Q2:为什么选择8作为树化阈值? A:8是经过精心选择的:
- 平衡点:在链表和红黑树之间找到平衡
- 经验值:通过大量测试得出的最优值
- 成本考虑:红黑树节点占用更多内存
Q3:为什么改为尾插法? A:尾插法的优势:
- 线程安全:避免多线程环境下的死循环
- 顺序保持:保持元素的插入顺序
- 调试友好:便于调试和问题排查
Q4:树化机制是如何工作的? A:树化流程:
- 触发条件:链表长度达到8且数组长度≥64
- 转换过程:将链表节点转换为红黑树节点
- 性能考虑:只有在真正需要时才进行转换
JDK 8 数据结构示意图
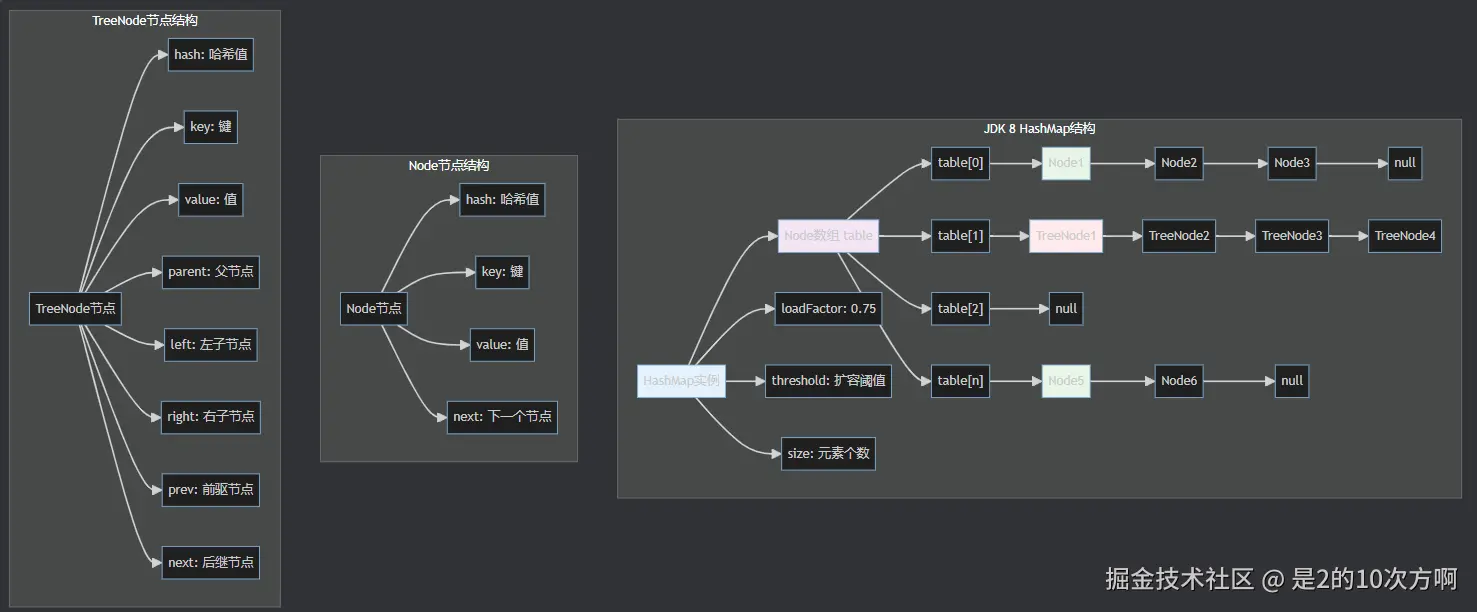
3. get方法
kotlin
public V get(Object key) {
Node<K, V> e;
// 调用getNode方法查找节点,找到则返回value,否则返回null
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K, V> getNode(int hash, Object key) {
Node<K, V>[] tab;
Node<K, V> first, e;
int n;
K k;
// 检查table是否为空且对应位置有节点
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 检查第一个节点是否匹配
if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 如果第一个节点不匹配,继续查找
if ((e = first.next) != null) {
// 如果是红黑树,使用树查找
if (first instanceof TreeNode)
return ((TreeNode<K, V>) first).getTreeNode(hash, key);
// 链表查找:遍历链表
do {
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}💡 核心设计思想
设计理念:采用"多策略查找"策略,根据数据结构类型选择最优的查找算法,体现了"性能优化"和"智能选择"的设计思想。
设计亮点:
- 多策略支持:支持链表查找和红黑树查找
- 智能选择:根据节点类型自动选择查找策略
- 性能优化:红黑树查找时间复杂度O(log n)
🤔 疑问自答
Q1:为什么get方法也要支持红黑树查找? A:红黑树查找的优势:
- 性能提升:最坏情况从O(n)降至O(log n)
- 一致性:与put方法保持一致的数据结构
- 实际效果:大数据量场景下查找性能显著提升
Q2:为什么先检查第一个节点? A:优化策略:
- 快速路径:如果第一个节点就是目标,直接返回
- 性能优化:避免不必要的遍历
- 常见场景:大多数情况下第一个节点就是目标
Q3:链表查找和红黑树查找有什么区别? A:查找策略差异:
- 链表查找:顺序遍历,时间复杂度O(n)
- 红黑树查找:树遍历,时间复杂度O(log n)
- 自动选择:根据节点类型自动选择最优策略
Q4:为什么JDK 8的get方法比JDK 7更复杂? A:复杂性的原因:
- 多策略支持:需要支持链表和红黑树两种查找方式
- 性能优化:为了获得更好的性能,代码复杂度增加
- 但收益大于成本:性能提升带来的收益远大于代码复杂度的增加
🔍 JDK 7与JDK 8核心差异对比
1. 综合对比图表
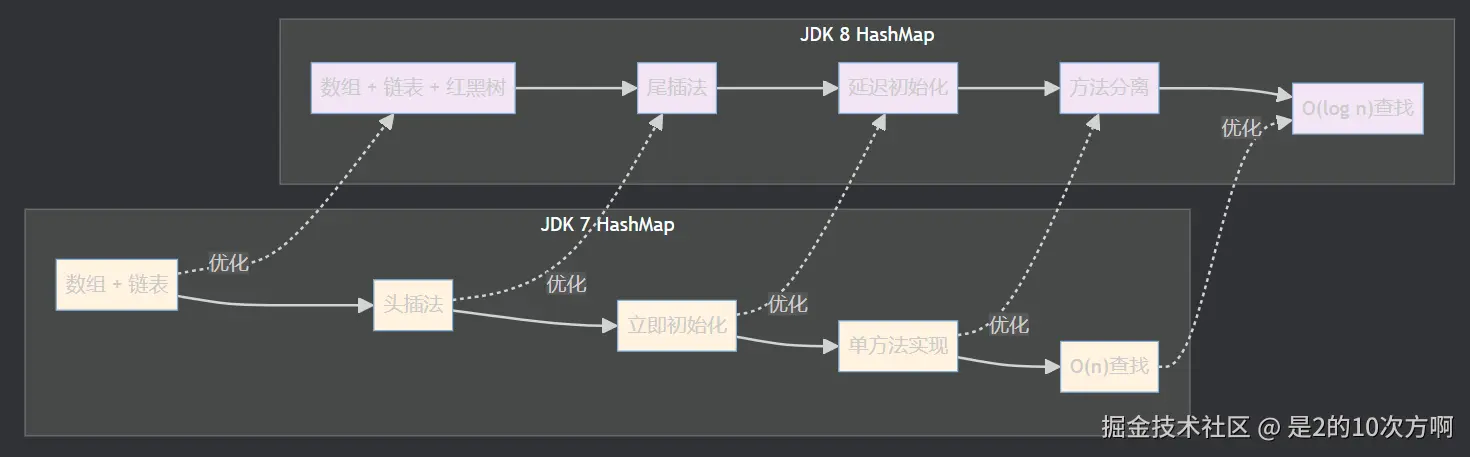
2. 数据结构与性能对比
| 特性 | JDK 7 | JDK 8 | 优化效果 |
|---|---|---|---|
| 底层结构 | 数组 + 链表 | 数组 + 链表 + 红黑树 | 最坏情况O(n)→O(log n) |
| 插入方式 | 头插法 | 尾插法 | 避免多线程死循环 |
| 构造方法 | 立即初始化 | 延迟初始化 | 减少不必要的计算 |
| 方法设计 | 单方法实现 | 方法分离 | 职责更清晰 |
3. 性能对比图表
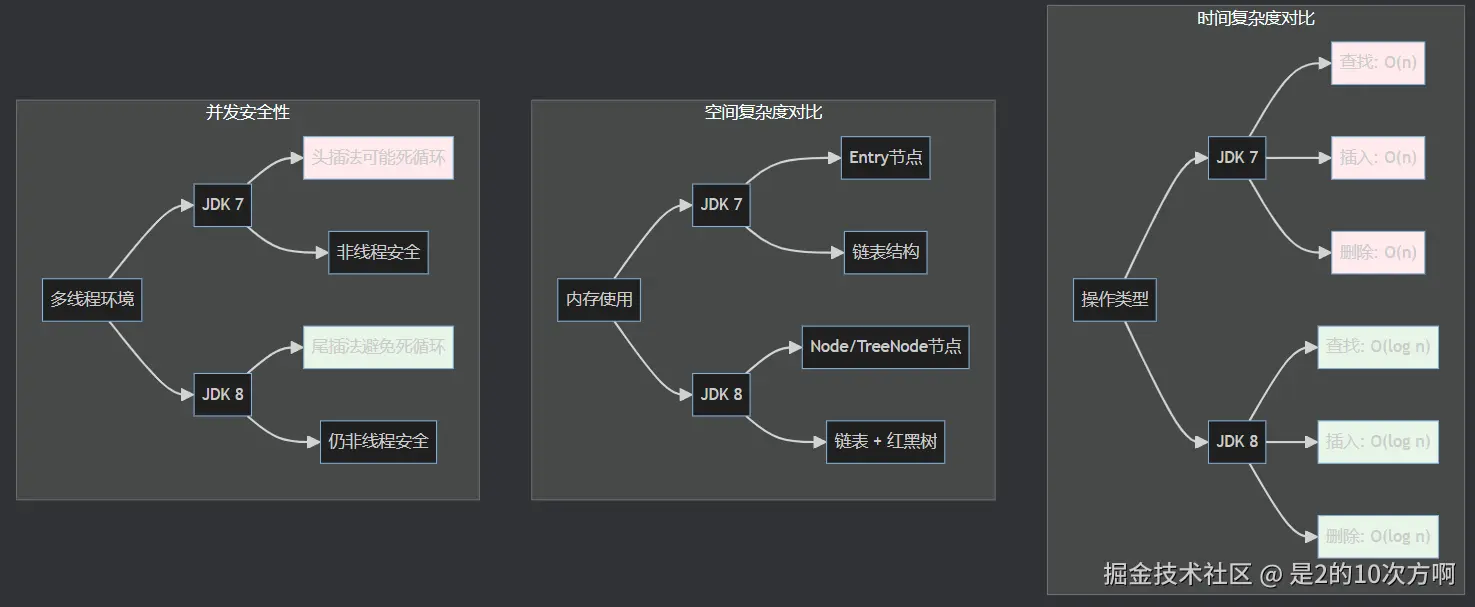
4. 关键代码对比
构造方法
csharp
// JDK 7: 立即计算threshold,调用有参构造方法
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
// JDK 8: 延迟初始化,只设置loadFactor,其他参数在首次使用时初始化
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}put方法设计
typescript
// JDK 7: 单方法实现所有逻辑,代码较长但逻辑集中
public V put(K key, V value) {
// 包含:table初始化、null处理、哈希计算、冲突处理、添加Entry等所有逻辑
}
// JDK 8: 方法分离,职责清晰,put()只负责调用putVal()
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}🎯 第4站:实际应用中的最佳实践
🚨 真实踩坑案例分享
案例1:生产环境的性能噩梦 😱
场景:某电商系统,双11期间用户查询商品信息突然变慢
arduino
// 问题代码:使用String作为key,但没有重写hashCode和equals
public class Product {
private String name;
private String category;
// 没有重写hashCode和equals方法!
// 这会导致HashMap性能急剧下降
public Product(String name, String category) {
this.name = name;
this.category = category;
}
}
// 使用方式
HashMap<Product, Integer> productStock = new HashMap<>();
// 每次put和get都会创建新的Product对象
// 导致HashMap无法正确识别相同的产品问题分析:
- 没有重写
hashCode()和equals()方法 - 每次创建新的Product对象,HashMap认为是不同的key
- 导致HashMap退化为链表,性能从O(1)降到O(n)
解决方案:
typescript
public class Product {
private String name;
private String category;
@Override
public int hashCode() {
return Objects.hash(name, category);
}
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null || getClass() != obj.getClass()) return false;
Product product = (Product) obj;
return Objects.equals(name, product.name) &&
Objects.equals(category, product.category);
}
}案例2:多线程环境下的死循环 💀
场景:JDK7环境下,多线程并发操作HashMap导致CPU 100%
typescript
// 危险代码:多线程环境下使用HashMap
public class DangerousHashMapUsage {
private HashMap<String, Integer> cache = new HashMap<>();
// 多线程同时调用这个方法
public void updateCache(String key, Integer value) {
// JDK7的头插法在多线程环境下可能导致死循环
cache.put(key, value);
}
}问题分析:
- JDK7使用头插法,多线程环境下可能导致链表成环
- 当get操作遍历到环形链表时,会陷入死循环
- CPU使用率飙升到100%,系统卡死
解决方案:
typescript
// 方案1:使用ConcurrentHashMap
public class SafeHashMapUsage {
private ConcurrentHashMap<String, Integer> cache = new ConcurrentHashMap<>();
public void updateCache(String key, Integer value) {
cache.put(key, value); // 线程安全
}
}
// 方案2:使用synchronized
public class SynchronizedHashMapUsage {
private HashMap<String, Integer> cache = new HashMap<>();
public synchronized void updateCache(String key, Integer value) {
cache.put(key, value);
}
}🎯 最佳实践总结
1. 选择合适的初始容量
arduino
// 如果你知道大概需要存储多少元素
int expectedSize = 1000;
HashMap<String, String> map = new HashMap<>(expectedSize * 4 / 3 + 1);
// 这样避免频繁扩容,提高性能2. 选择合适的负载因子
arduino
// 如果内存充足,可以设置更小的负载因子
HashMap<String, String> map = new HashMap<>(16, 0.5f);
// 这样会减少哈希冲突,提高查找性能3. 正确重写hashCode和equals
vbnet
// 使用Objects.hash()和Objects.equals()
@Override
public int hashCode() {
return Objects.hash(field1, field2, field3);
}
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null || getClass() != obj.getClass()) return false;
MyClass myClass = (MyClass) obj;
return Objects.equals(field1, myClass.field1) &&
Objects.equals(field2, myClass.field2) &&
Objects.equals(field3, myClass.field3);
}4. 多线程环境下的选择
javascript
// 单线程:使用HashMap
HashMap<String, String> singleThreadMap = new HashMap<>();
// 多线程:使用ConcurrentHashMap
ConcurrentHashMap<String, String> multiThreadMap = new ConcurrentHashMap<>();
// 或者使用Collections.synchronizedMap()
Map<String, String> synchronizedMap = Collections.synchronizedMap(new HashMap<>());💡 设计亮点总结
核心优化
- 红黑树优化:JDK 8引入红黑树,最坏情况从O(n)降至O(log n)
- 尾插法:避免多线程环境下的死循环问题
- 延迟初始化:减少不必要的计算和内存分配
- 方法分离:职责更清晰,代码更易维护
设计模式应用

🎊 总结:从"图书馆"到"智能仓库"的进化
🎯 我们的学习之旅
通过这篇文章,我们一起走过了HashMap的进化历程:
- 🏠 第1站:理解了HashMap就像一个大图书馆
- 🔍 第2站:深入分析了JDK7的"传统图书馆"管理方式
- 🚀 第3站:探索了JDK8的"智能仓库"升级改造
- 🎯 第4站:学习了实际应用中的最佳实践和踩坑经验
💡 核心收获
技术层面:
- HashMap的底层实现原理(数组+链表+红黑树)
- JDK7和JDK8的核心差异和优化
- 哈希冲突的解决方案
- 性能优化的关键点
实践层面:
- 如何正确使用HashMap
- 多线程环境下的注意事项
- 常见问题的解决方案
- 最佳实践的应用
🎉 恭喜你!现在你已经从HashMap的"小白"变成了"大神"!
记住:真正好的技术一定是简单的,而不是枯燥的。希望这篇文章能让你在轻松愉快的氛围中学到知识!
📚 参考文档与延伸阅读
官方文档
技术博客与文章
相关技术文档
在线工具与资源
- Java Visualizer - 可视化哈希表操作
- Algorithms Visualization - 算法可视化工具
本文使用 markdown.com.cn 排版