Redis是一个开源的内存数据结构存储系统,广泛应用于高性能、高并发的场景。作为一个分布式缓存系统,Redis具有高效的读写性能,但也面临一些挑战。本文将回答一些Redis高级面试中的常见问题,并探讨其底层原理及解决方案。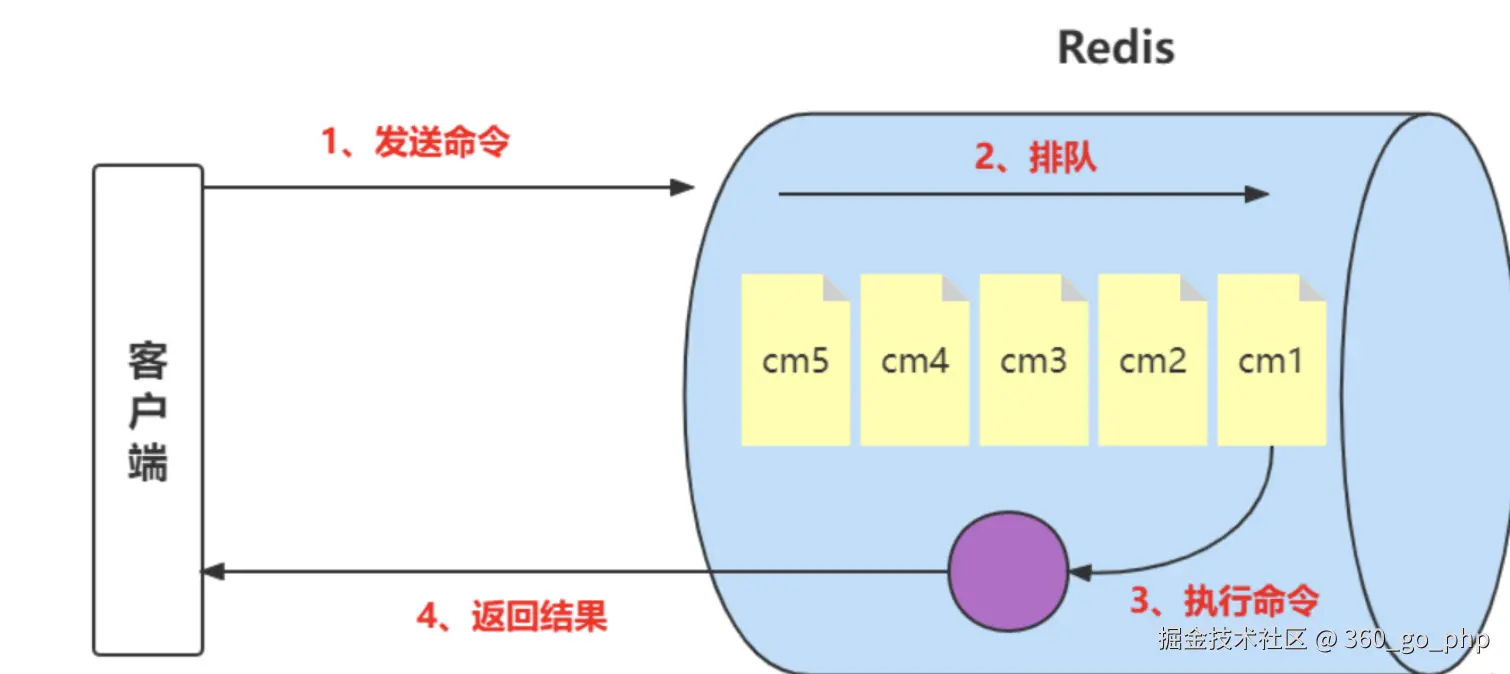 编辑
编辑
1. Redis的大key和热key问题
答案:
- 大Key问题 :
Redis的大key问题通常是指存储的单个数据对象过大(如一个巨大的字符串、哈希、列表等),导致在执行命令时,Redis需要将整个数据加载到内存中,可能会导致内存溢出,甚至整个Redis实例崩溃。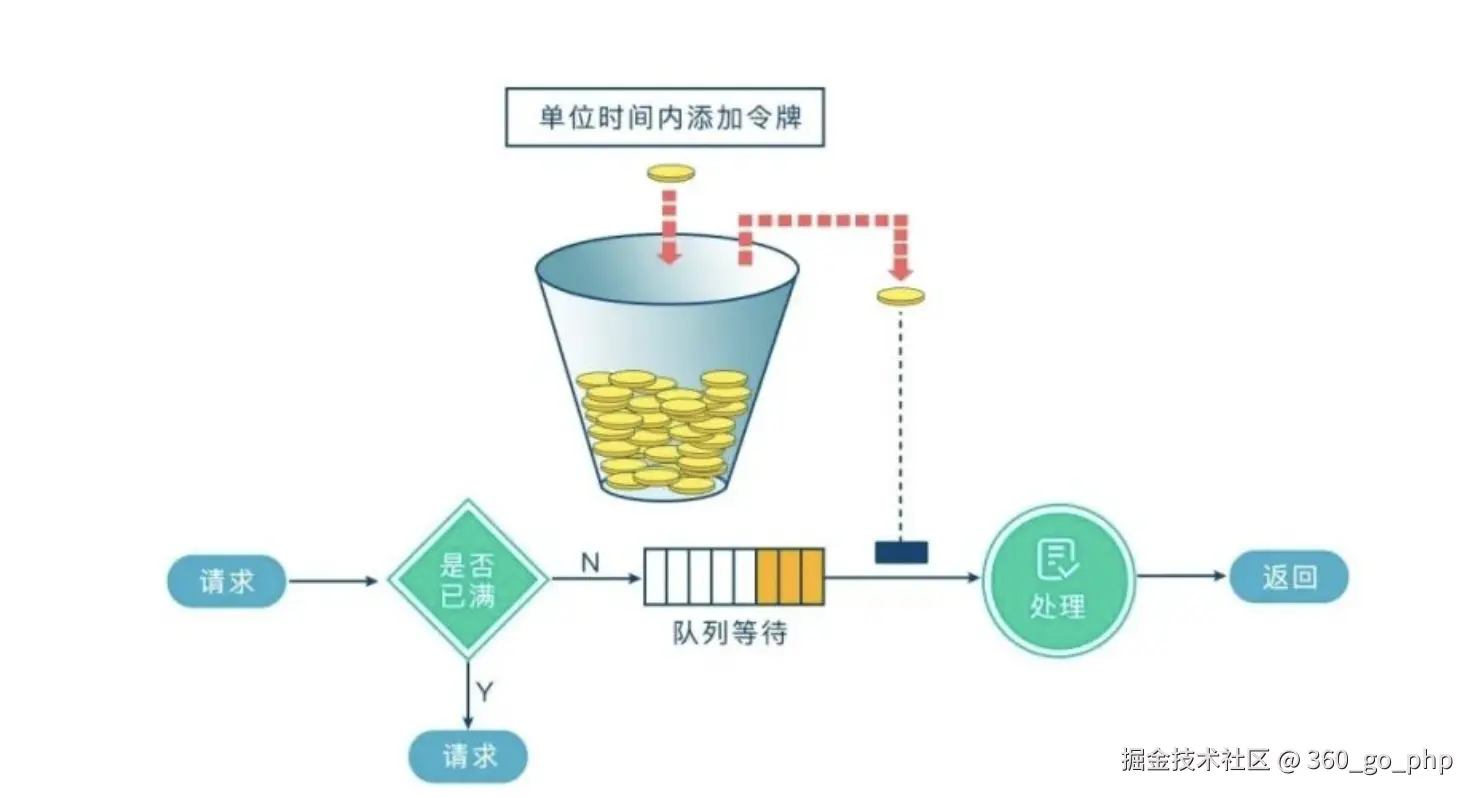 编辑
编辑
原因 :
Redis是一个内存数据库,当大key存储时,整个对象被加载到内存中,会占用大量的内存空间,并且操作时可能需要时间较长,导致系统性能下降。
解决方案 :
-
避免大key的生成 :尽量避免使用过大的数据结构,建议使用多个小的键值对代替一个大key。
-
监控和报警 :定期检查Redis中是否存在大key,通过
redis-cli --bigkey命令可以找出可能存在的大key。 -
分片存储 :对于大的数据结构,可以使用分片存储,将其拆分成多个小块,存储在多个Redis实例中。
 编辑
编辑
- 热Key问题 :
热key是指频繁访问的键,这些键可能由于某些原因(如流量不均)占用了大量的计算资源。Redis是单线程模型,某一个热key可能会导致整个Redis实例变得繁忙,影响到其他的请求。
解决方案 :
-
热点数据分散 :可以将热点数据通过加前缀、后缀的方式分散到不同的Redis实例或不同的数据库。
-
使用缓存失效策略 :使用LRU等淘汰策略,尽量保证热key不会长期存在,避免Redis成为单一热key的瓶颈。
-
分布式缓存:使用Redis集群,将数据分布到不同的节点上,减轻单一节点的压力。
2. 为什么热key影响Redis的背后底层原理  编辑
编辑
答案 :
Redis是一个单线程的事件驱动模型,每个命令在执行时都要等待前一个命令完成。当有热key时,由于该key的访问频繁,导致Redis长时间在处理该请求,其他请求需要等待。即使Redis能抗住1000w QPS,但若其中有100w的热key,Redis可能会由于这些频繁访问的请求导致性能下降甚至崩溃。
原因:
- 单线程模型:Redis是单线程的,这意味着每个命令必须依次处理。热key的高频访问会占用大部分处理能力,导致其他命令的处理延迟,影响整个Redis实例的响应时间。
- 内存瓶颈:频繁访问的热key可能会导致内存使用不均衡,某些key占用过多内存,造成Redis的内存压力,甚至出现内存不足的情况。
3. 热点菜品问题处理方案
答案 :
在电商或餐饮类系统中,热点菜品问题类似于Redis中的热key问题。某些菜品由于促销活动、用户偏好等原因,突然成为热销商品,导致大量请求涌入。
处理方案:
- 缓存热点菜品:使用缓存系统(如Redis)将热点菜品的数据进行缓存,减少数据库的负担。
- 延迟更新:对于一些数据(如菜品库存等),可以通过异步处理和延迟更新来避免频繁的数据库操作。
- 负载均衡:通过负载均衡策略将请求分发到多个服务节点,避免单点压力过大。
4. 限流应该怎么做?
答案 :
限流是控制系统负载、保障服务稳定的常见方法。常见的限流策略有:
- 令牌桶(Token Bucket):系统以固定的速率生成令牌,客户端请求时,先获取令牌,令牌数量为零时,拒绝服务。适用于突发流量的控制。
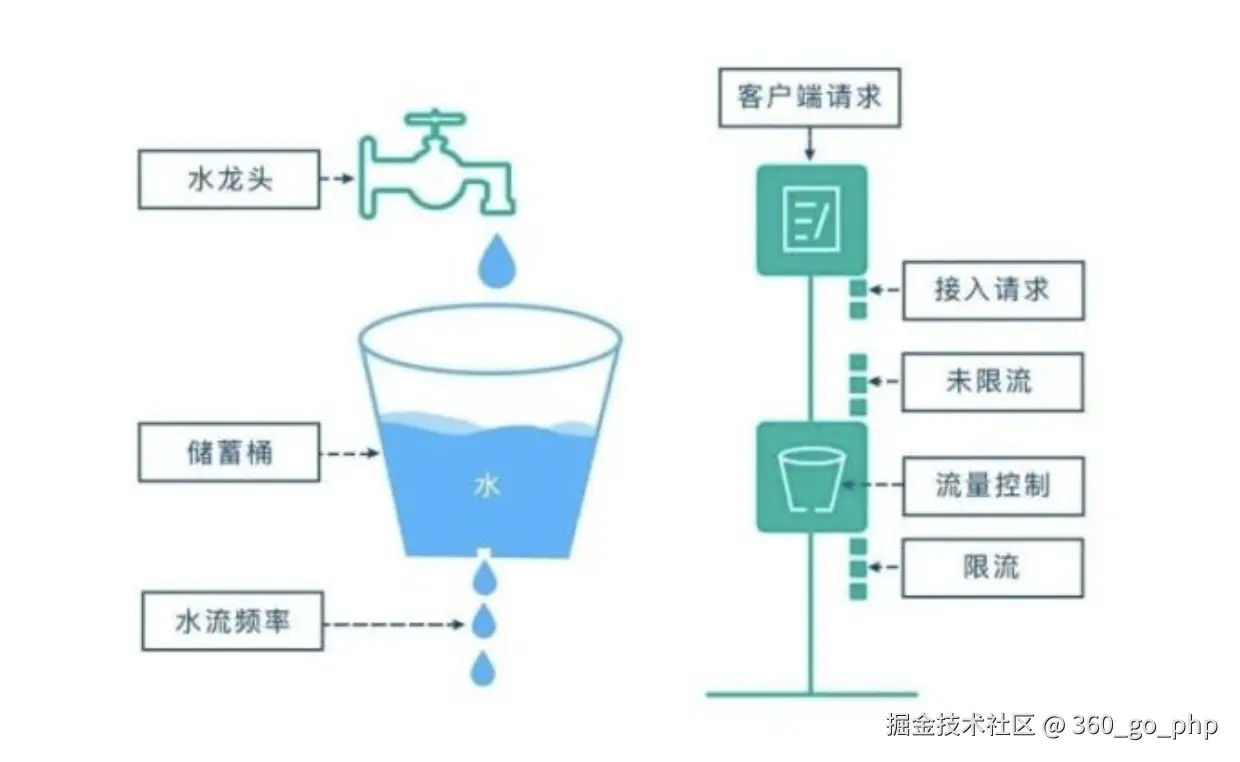
- 漏桶算法(Leaky Bucket):请求按照一定的速率流出,超过速率的请求会被丢弃。适用于平稳流量的控制。
- 计数器法:每个时间窗口内对请求次数进行计数,超过阈值则拒绝服务。
Redis应用 :
可以使用Redis的INCR和EXPIRE命令来实现令牌桶或计数器法。
5. 服务降级应该有什么准则
答案 :
服务降级是应对系统过载的常见手段。设计时需要考虑以下准则:
- 优先级:根据服务的优先级进行降级,优先保留关键服务,非核心服务可以降级。
- 透明性:降级操作应该尽量不影响用户的使用体验,或者提前告知用户。
- 自动化:降级应自动化触发,避免人工干预。
- 容错机制:服务降级时要提供合理的容错处理,如返回默认值、缓存数据等。
6. 服务注册和服务发现怎么做的?
答案 :
服务注册和发现是微服务架构中的关键问题,通常通过以下方式实现:
- 服务注册:每个服务启动时,将自己的信息(如IP、端口、健康检查信息)注册到服务注册中心。
- 服务发现:服务消费者通过查询服务注册中心获取服务提供者的地址。
常用工具:
- Consul:一个支持健康检查的服务注册与发现工具。
- Eureka:Netflix开源的服务注册与发现框架。
- Zookeeper:分布式协调服务,常用于服务注册与发现。
7. 服务注册和服务发现内部实现细节
答案 :
服务注册和发现的实现细节通常包括以下几个步骤:
- 服务注册:服务启动时,向注册中心(如Consul、Eureka、Zookeeper)注册服务信息,注册信息包括服务名、实例ID、IP地址、端口、健康检查信息等。
- 服务发现:服务消费者查询注册中心,获取所有可用的服务实例列表。如果某个实例不可用,注册中心会定期更新服务列表。
8. 权限校验机制怎么做的?
答案 :
权限校验是确保系统安全的重要组成部分,通常使用基于角色的访问控制(RBAC)或者基于属性的访问控制(ABAC)来实现。
- RBAC:根据用户的角色来分配不同的权限。
- ABAC:基于用户、资源和环境属性来动态决定是否允许访问。
9. 权限操作的数据安全和操作安全
答案 :
数据安全和操作安全的核心在于确保系统不受未经授权的访问和操作。常用技术包括:
- 加密:使用对称加密或非对称加密保护敏感数据。
- 认证:确保用户身份的真实性,可以使用OAuth、JWT等机制进行身份认证。
- 授权 :确保用户有权限进行特定操作,基于角色或属性进行访问控制。
 编辑
编辑
10. 慢查询
答案 :
慢查询是指执行时间较长的数据库查询,通常会影响系统的响应速度和性能。解决方案包括:
- 优化查询:检查查询是否可以优化,如使用索引、减少联接等。
- 分库分表:对于大数据量的表,考虑分库分表,降低单个查询的压力。
- 缓存:使用Redis等缓存工具缓存查询结果,减少对数据库的频繁访问。
算法题:
题目:给定一个数n(如23121),给定一组数字a(如2, 4, 9),求由a中元素组成的小于n的最大数。
解答:
- 对于给定的数字a,先对a进行排序,降序排列。
- 从左到右尝试每一位数,确保生成的数字小于n。
- 需要判断每一位能否构成一个合法的数字,并保持尽量大的数值。
代码实现:
python
def max_number_less_than_n(n, a):
n_str = str(n)
a.sort(reverse=True)
result = ""
for i in range(len(n_str)):
for num in a:
if int(result + str(num)) < int(n_str[:i + 1]):
result += str(num)
break
return result
# 示例
n = 23121
a = [2, 4, 9]
print(max_number_less_than_n(n, a)) # 输出最大的小于n的数