要求 service 配置externalTraffcLocal ,节点挂了 metallb 的 vip 首先会迁移,然后会发到本地节点的pod。
这是一种前端 vip 和 后端 pod ip (利用本地化)优势的一种逻辑,
是一种绑定
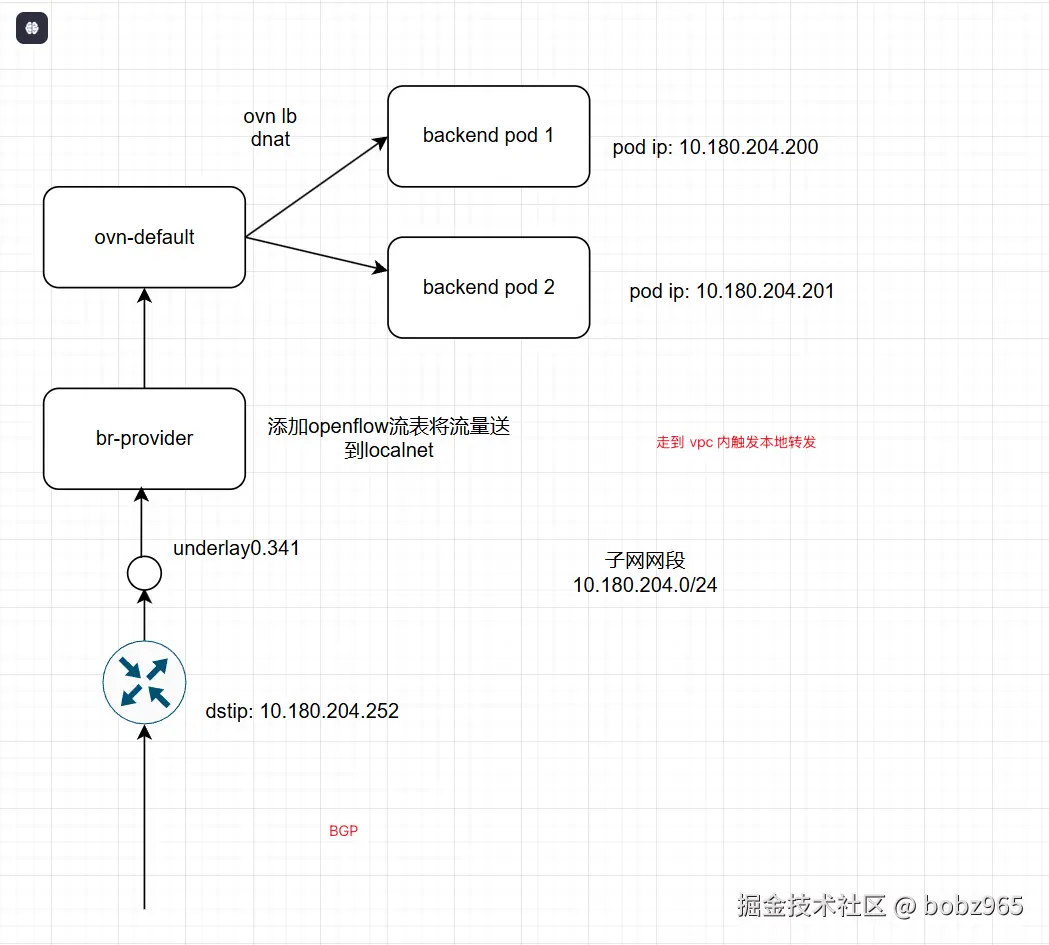
这里的路由会跳过 node 上的 ipvs,从而利用 ovn-default 中的 switch lb
MetalLB 在 K8s 中的负载均衡实现
要理解 MetalLB 在 K8s Node 上的负载均衡实现,需先明确其核心定位:为裸金属 K8s 集群补充 LoadBalacer 类型 Service 的能力 (云厂商集群依赖云厂商 LB,裸金属环境无此组件,MetalLB 填补这一空白)。其实现依赖 "控制平面配置管理 + 数据平面流量转发" 的双层架构,核心技术原理分为 Layer 2(二层模式) 和 BGP(三层模式) 两种,且均需与 K8s 原生组件(如 kube-proxy)协作完成最终的 Pod 流量分发。
一、MetalLB 整体架构:控制平面与数据平面
MetalLB 的工作流程需先拆解为 "控制平面配置下发" 和 "数据平面流量转发" 两个阶段,二者协同实现从 "外部流量" 到 "Pod" 的完整路径:
| 组件 / 平面 | 核心功能 | 与 Node 的关联 |
|---|---|---|
| 控制平面 | 1. 监听 K8s API 中的 Service(仅 type: LoadBalancer 类型)和 Endpoint;2. 从预配置的 IPAddressPool 中为 Service 分配 VIP(虚拟 IP,即 LoadBalancer 的外部 IP);3. 根据 Service 配置的模式(L2/BGP),生成对应的流量转发规则(如 ARP 宣告、BGP 路由),下发到集群内的 Node。 |
控制平面通常以 Deployment 形式运行(1 个或多个副本,通过 Leader 选举保证唯一性),不直接在 Node 上处理流量,仅负责 "规则配置"。 |
| 数据平面 | 基于控制平面下发的规则,在 Node 上实现 "外部流量→VIP→Node→Pod" 的转发,是负载均衡的核心执行层。 | 数据平面通过 DaemonSet 部署(每个 Node 上运行 1 个 speaker 容器),直接在 Node 内核层(或通过路由协议)处理流量。 |
二、核心实现:两种负载均衡模式的技术原理
MetalLB 的核心差异体现在数据平面,即 "如何将目标为 VIP 的外部流量引导到集群内的 Node,并最终转发到 Pod"。两种模式的实现逻辑完全不同,适用场景也有明确区分。
模式 1:Layer 2(二层模式)------ 基于 ARP/NDP 的本地流量牵引
Layer 2 模式是 MetalLB 最常用的模式(无需依赖外部路由器支持),核心原理是通过 ARP 协议(IPv4)或 NDP 协议(IPv6),在局域网内 "宣告" VIP 与某个 Node 的 MAC 地址绑定,从而将外部流量牵引到该 Node,再由 kube-proxy 转发到后端 Pod。
具体实现步骤(以 IPv4 为例)
-
VIP 分配:
当用户创建
type: LoadBalancer的 Service 后,MetalLB 控制平面从IPAddressPool中分配一个 VIP(如 192.168.1.100),并关联到该 Service 的 Endpoint(即后端 Pod 的 IP 列表)。 -
Leader Node 选举:
MetalLB 会在集群内的 Node 中选举一个 Leader Node(通过 Lease 锁实现),该 Node 成为 VIP 的 "唯一持有者"------ 只有 Leader Node 会对外发送 ARP 报文,宣告 "VIP 192.168.1.100 的 MAC 地址是 Leader Node 的网卡 MAC"。
为何需要 Leader 选举?
若多个 Node 同时宣告同一 VIP 的 MAC,会导致局域网内 ARP 欺骗(交换机不知道该转发到哪个 Node),因此 Layer 2 模式下 VIP 仅绑定到单个 Leader Node(故障时会重新选举新 Leader,实现高可用)。
-
外部流量牵引到 Leader Node:
客户端发送目标为 VIP(192.168.1.100)的流量时,会先在局域网内发送 ARP 请求("谁拥有 192.168.1.100?")。此时 Leader Node 上的 MetalLB
speaker容器会响应 ARP 回复,告知客户端 "192.168.1.100 的 MAC 是 Leader Node 的 MAC"。客户端收到回复后,会将流量封装为 "目标 MAC = Leader Node MAC" 的以太网帧,交换机根据 MAC 表将流量转发到 Leader Node。
-
流量从 Node 转发到 Pod(依赖 kube-proxy):
流量到达 Leader Node 后,MetalLB 本身不处理 Pod 层面的负载均衡,而是由 K8s 原生组件 kube-proxy 完成最终转发:
-
若 kube-proxy 使用
iptables模式:Node 内核中的 iptables 规则会将 "目标为 VIP:Port" 的流量,通过 DNAT 转换为 "后端 Pod IP:Port"(规则由 kube-proxy 监听 Endpoint 动态生成); -
若 kube-proxy 使用
IPVS模式:IPVS 会直接将 VIP 作为虚拟服务地址,后端 Pod 作为真实服务器,通过轮询 / 加权等算法分发流量。
Layer 2 模式的核心特点
-
优点:无需外部路由器支持(仅需局域网环境),配置简单,适合小规模裸金属集群;
-
缺点:所有外部流量先集中到 Leader Node,再由 Leader Node 转发到其他 Node 上的 Pod(存在 "流量瓶颈");VIP 仅绑定单个 Node(故障转移需秒级时间,有短暂中断风险)。
模式 2:BGP(三层模式)------ 基于路由协议的分布式流量分发
BGP(边界网关协议)模式是更高效的负载均衡方案,核心原理是MetalLB 作为 BGP Speaker(路由发言人),与集群外的物理路由器建立 BGP 邻居关系,向路由器宣告 "VIP 对应的下一跳是集群内的多个 Node",路由器通过 ECMP(等价多路径)算法将流量分布式转发到不同 Node,再由 kube-proxy 转发到 Pod。
具体实现步骤
-
BGP 邻居配置:
需先在 MetalLB 中配置物理路由器的信息(如路由器 IP、AS 号),同时 MetalLB 自身也会使用一个 AS 号(如 64512)。当 MetalLB
speaker容器启动后,会在每个 Node 上与物理路由器建立 BGP 邻居连接(每个 Node 都是一个独立的 BGP Speaker)。 -
VIP 与路由宣告:
当 Service 分配到 VIP(如 192.168.1.100)后,MetalLB 控制平面会通知所有 Node 上的
speaker:向 BGP 路由器宣告一条路由规则 ------"目标网络为 VIP/32(即单个 IP),下一跳为当前 Node 的 IP"。最终,路由器会收到来自集群内多个 Node 的相同路由(目标都是 VIP/32,下一跳不同),并通过 ECMP 算法将这些路由加入路由表。
-
外部流量分布式转发到 Node:
客户端发送目标为 VIP 的流量时,流量先到达物理路由器。路由器根据 ECMP 算法(如轮询、哈希),将流量转发到其中一个 "下一跳 Node"(例如,第一次转发到 Node A,第二次转发到 Node B),实现流量的分布式负载均衡。
-
流量从 Node 转发到 Pod(仍依赖 kube-proxy):
与 Layer 2 模式一致,流量到达 Node 后,由 kube-proxy 通过 iptables/IPVS 将流量转发到后端 Pod。此时每个 Node 仅处理一部分流量,不存在 "Leader Node 瓶颈"。
BGP 模式的核心特点
-
优点:流量通过路由器 ECMP 分布式转发到多个 Node,无单点瓶颈,性能更高;故障转移由路由器自动完成(某个 Node 下线后,路由器会删除对应下一跳路由,流量直接转发到其他 Node);
-
缺点:依赖外部物理路由器支持 BGP 协议(需提前配置路由器的 BGP 邻居),配置复杂度高,适合中大规模裸金属集群。
三、关键细节:MetalLB 与 K8s 组件的协作边界
很多人会混淆 MetalLB 与 kube-proxy 的职责,需明确二者的协作边界:
-
MetalLB 的职责:解决 "外部流量如何到达集群内的 Node"------ 即通过 L2/BGP 模式,将目标为 VIP 的外部流量牵引到 Node(相当于 "集群入口的负载均衡");
-
kube-proxy 的职责:解决 "流量到达 Node 后如何转发到 Pod"------ 即通过 iptables/IPVS,将 Node 上的 VIP 流量分发到后端 Pod(相当于 "Node 内部的负载均衡");
-
两者的关联:MetalLB 分配的 VIP 会被 kube-proxy 识别为 Service 的 "外部 IP",并自动生成对应的转发规则,二者缺一不可。
四、总结:两种模式的对比与适用场景
| 维度 | Layer 2 模式 | BGP 模式 |
|---|---|---|
| 核心技术 | ARP/NDP 协议(二层) | BGP 协议 + 路由器 ECMP(三层) |
| 流量分发方式 | 集中到 Leader Node,再转发到 Pod | 路由器 ECMP 分布式转发到多个 Node |
| 依赖组件 | 无(仅需局域网) | 支持 BGP 的物理路由器 |
| 性能瓶颈 | 有(Leader Node 是单点) | 无(分布式转发) |
| 适用场景 | 小规模裸金属集群、测试环境、无 BGP 路由器 | 中大规模集群、高并发场景、有 BGP 路由器支持 |
通过以上原理可见,MetalLB 本质是 "将云厂商 LB 的能力在裸金属环境中'模拟'出来"------ 无论是 Layer 2 模式的 ARP 宣告,还是 BGP 模式的路由协作,最终都是为了实现 "外部流量到 Node 的负载均衡",再结合 K8s 原生的 kube-proxy 完成 "Node 到 Pod 的负载均衡",形成完整的流量链路。
如果需要进一步了解某部分细节(比如 MetalLB 的具体配置步骤、BGP 路由器的调试方法,或 Layer 2 模式的故障转移机制),可以告诉我你的具体需求,我会补充更详细的操作指南或技术拆解。