堆 是一种非常重要且应用广泛的数据结构。它不仅在排序算法中有着出色的表现,还在优先队列等场景中发挥着关键作用。今天,我们就来全面深入地探讨堆的相关知识,包括它的概念、结构、实现以及经典应用。
堆的概念及结构
如果有一个关键码的集合K = {k0k_{0}k0,k1k_{1}k1,k2k_{2}k2,k3k_{3}k3...knk_{n}kn},将它的所有元素按照完全二叉树的顺序储存方式储存在一个一维数组中,
并满足:kik_{i}ki<=k2i+1k_{2i+1}k2i+1并且kik_{i}ki<=k2i+2k_{2i+2}k2i+2(或者kik_{i}ki>=k2i+1k_{2i+1}k2i+1并且kik_{i}ki>=k2i+2k_{2i+2}k2i+2),
其中i=0,1,2,3,4,5,...,n/2,那么这个集合称为堆。
从这个定义中,我们可以提炼出堆的几个关键特征。首先,堆是一种完全二叉树 ,这意味着它的存储结构可以很自然地用一维数组来实现,不需要额外的指针来连接节点,大大节省了存储空间。其次,堆中的每个节点都要满足特定的堆序性质。根据堆序性质的不同,堆可以分为两种类型:
小堆(小根堆) :每个节点的值都小于或等于 其左右孩子节点的值,即kik_{i}ki<=k2i+1k_{2i+1}k2i+1并且kik_{i}ki<=k2i+2k_{2i+2}k2i+2。在小堆中 ,根节点的值是整个堆中最小的 。
大堆(大根堆) :每个节点的值都大于或等于 其左右孩子节点的值,即kik_{i}ki>=k2i+1k_{2i+1}k2i+1并且kik_{i}ki>=k2i+2k_{2i+2}k2i+2。在大堆中 ,根节点的值是整个堆中最大的 。
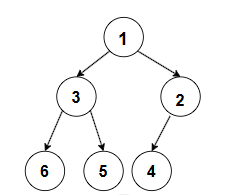
我们可以通过一个简单的例子来理解堆的结构。比如对于小堆,假设数组为 1,3,2,6,5,4,将其按照完全二叉树的形式排列,根节点是 1,它的左孩子是 3,右孩子是 2,3 的左孩子是 6,右孩子是 5,2 的左孩子是 4,每个父节点都小于等于其孩子节点,符合小堆的定义。
堆的实现
要实现一个堆,我们需要掌握几个核心的操作,包括堆的向下调整算法、堆的向上调整算法,堆的创建、堆的插入和堆的删除等。
堆向下调整算法
堆的向下调整算法是堆实现中的一个基础且关键的操作,它的作用是当堆中的某个节点的值不满足堆的性质时,通过将其向下调整,使整个堆重新满足堆的性质。
该算法的前提是:假设 当前节点的左右子树都已经是堆 。在这个前提下,我们从当前节点开始,将其与左右孩子中值较小(对于小堆)或较大(对于大堆)的节点进行比较 。如果当前节点的值不满足堆的性质(比如在小堆中,当前节点的值大于左孩子或右孩子的值),就将当前节点与那个值较小(或较大)的孩子节点交换 位置。交换之后,继续以交换后的孩子节点为当前节点,重复上述过程,直到当前节点满足堆的性质或者当前节点是叶子节点 为止。
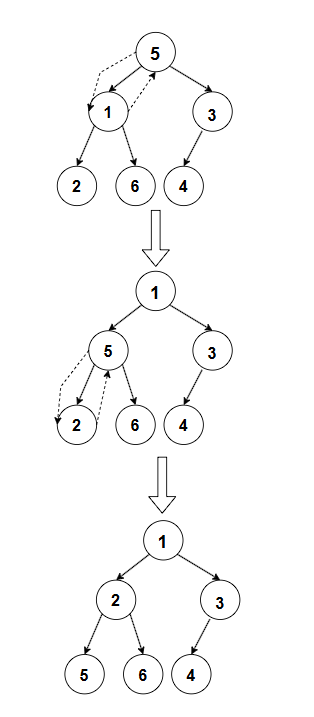
以小堆为例,假设我们有一个数组 5,1,3,2,6,4,根节点是 5,它的左孩子是 1,右孩子是 3。由于 5 大于 1 和 3,不满足 小堆的性质,我们需要进行向下调整。首先比较左孩子 1 和右孩子 3,选择较小的 1 与根节点 5 交换,得到数组 1,5,3,2,6,4。此时,原来的根节点 5 被交换到了左孩子的位置,我们需要检查它是否满足堆的性质。5 的左孩子是 2,右孩子是 6,5 大于 2,所以将 5 和 2 交换,得到数组 1,2,3,5,6,4。此时,5 的位置是叶子节点的父节点,它的左孩子不存在,右孩子是 4,5 大于 4,继续交换,得到数组 1,2,3,4,6,5,此时 5 是叶子节点,调整结束,整个堆满足 小堆的性质。
c
//用于堆的创建和删除
void AdjustDown(HPDataType* arr, int n, int parent)
{
int child = parent*2+1;
while (child <n)
{
if (child + 1 < n && arr[child] > arr[child + 1])
{
child++;
}
if (arr[child] < arr[parent])
{
Swap(&arr[child], &arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else
break;
}
}堆的向上调整算法
堆的向上调整算法同样是堆操作中的重要组成部分,它主要用于当堆的末尾添加了一个新元素 ,或者某个节点的值变小 (对于小堆)或变大 (对于大堆)时,通过向上调整使堆重新满足性质 。
该算法的操作过程是:
从需要调整的节点开始,将其与父节点进行比较。如果是小堆,且当前节点的值小于父节点的值,或者是大堆,且当前节点的值大于父节点的值,就将当前节点与父节点交换位置。交换后,以父节点作为新的当前节点,继续与它的父节点进行比较,重复上述交换过程,直到当前节点满足堆的性质或者当前节点成为根节点为止。
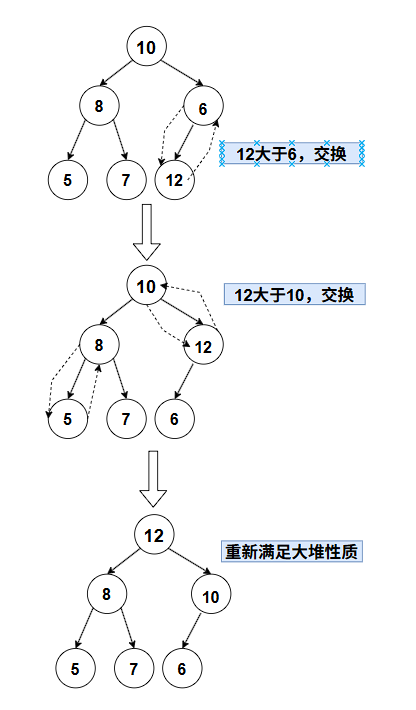
例如,在一个大堆 中,数组为 10,8,6,5,7,2,此时我们将索引为 5 的元素 2 修改为 12。修改后的数组为 10,8,6,5,7,12,由于 12 大于其父节点 6(父节点索引为 2),不满足大堆性质,需要向上调整。将 12 与 6 交换,得到数组 10,8,12,5,7,6。此时 12 的父节点是 10(索引为 0),12 大于 10,再次交换,得到数组 12,8,10,5,7,6,此时 12 成为根节点,调整结束,堆重新满足大堆性质。
向上调整算法的关键在于从下往上逐步修复堆的性质,它的时间复杂度为( O(log n),其中 n 是堆中元素的个数,因为堆的高度为log n 左右,最多需要进行 log n 次比较和交换操作。
c
//向上调整算法,适用于堆的插入
void AdjustUp(HPDataType* arr, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (arr[child] < arr[parent])
{
Swap(&arr[child], &arr[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
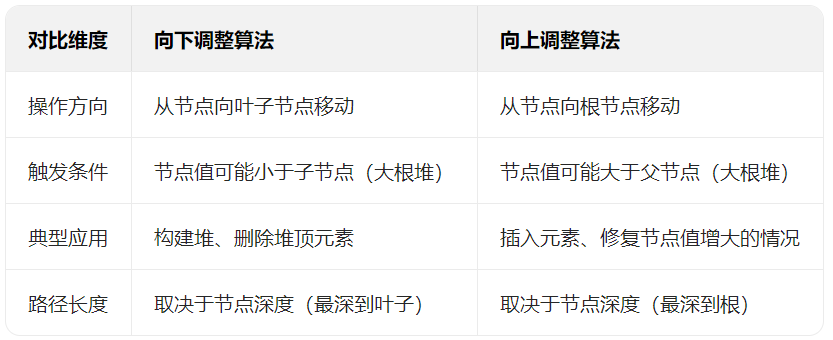
}堆向上调整和向下调整算法的区别
堆的创建
堆的创建就是将一个无序的数组转换为一个满足堆性质的数组。创建堆的过程可以利用堆的向下调整算法来实现。具体的做法是:
从数组中最后一个非叶子节点 开始(最后一个非叶子节点的索引是 n/2-1 ,其中 n 是数组的长度),依次向前对每个节点执行向下调整算法。因为最后一个非叶子节点的左右子树都是叶子节点,而叶子节点本身可以看作是一个只有一个节点的堆,满足向下调整算法的前提条件。当我们对这个节点执行向下调整后,它和它的子树就构成了一个堆。然后向前移动到前一个非叶子节点,此时它的左右子树可能已经是堆了(因为我们已经对后面的节点进行了调整),再对其执行向下调整算法,以此类推,直到对根节点执行完向下调整算法,整个数组就变成了一个堆。
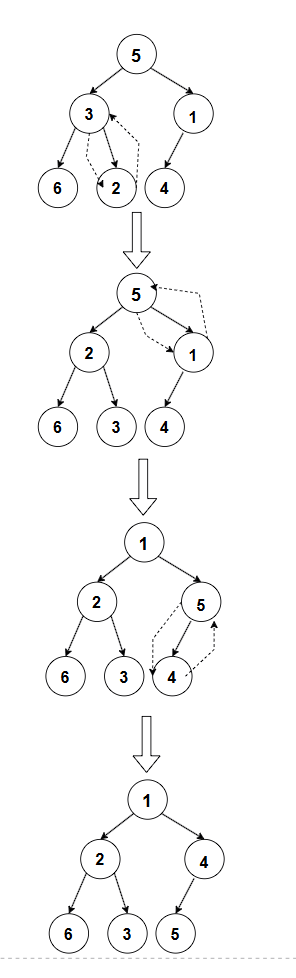
比如对于数组 5,3,1,6,2,4,长度 n=6,最后一个非叶子节点的索引是(6/2 )-1=3-1=2(索引从 0 开始),即值为 1 的节点。对其执行向下调整(小堆),1 的右孩子不存在,左孩子是 4,1 小于 4,无需交换。然后移动到前一个非叶子节点,索引为 1,即值为 3 的节点。它的左孩子是 6,右孩子是 2,2 较小,3 大于 2,交换得到 5,2,1,6,3,4。接着移动到索引为 0,即值为 5 的节点。它的左孩子是 2,右孩子是 1,1 较小,5 大于 1,交换得到 1,2,5,6,3,4。接着检查交换后的 5 是否满足堆的性质,5 的左孩子是 4,5 大于 4,交换得到 1,2,4,6,3,5,此时整个数组已经是一个小堆了。
堆的插入
堆的插入操作是在堆的末尾添加一个新的元素,然后通过向上调整算法 使堆重新满足堆的性质。
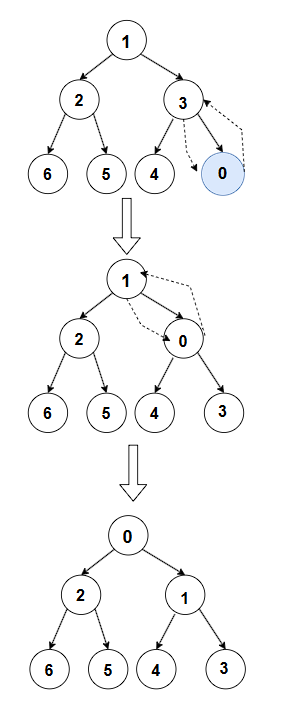
例如,我们有一个小堆 1,2,3,6,5,4,现在要插入元素 0。首先将 0 添加到堆的末尾 ,得到数组 1,2,3,6,5,4,0。然后进行向上调整 ,0 的父节点是索引为 2 的 3(因为对于索引为 i 的节点,其父节点的索引是( i-1)/2,这里 i=6,(6-1)/2=2,0 小于 3,交换得到 1,2,0,6,5,4,3。接着,0 的父节点是索引为 0 的 1,0 小于 1,交换得到 0,2,1,6,5,4,3,此时 0 成为根节点 ,满足小堆的性质 调整结束。
堆的删除
堆的删除操作通常是删除堆的根节点 (因为堆的根节点是最大值或最小值,删除根节点是最常见的需求)。删除根节点后,为了保持堆的结构,我们需要将堆的最后一个元素移动到根节点的位置,然后通过向下调整算法 使堆重新满足堆的性质。
具体步骤如下:
• 首先,保存根节点的值 (以便返回删除的元素);
• 然后,将堆的最后一个元素赋值给根节点 ;
• 接着,删除堆的最后一个元素 (即减小堆的大小);
• 最后,对根节点执行向下调整算法 ,使堆重新满足性质。
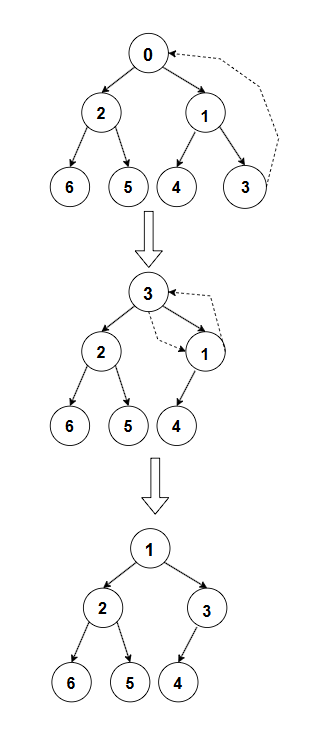
比如,对于小堆 0,2,1,6,5,4,3,删除根节点 0。首先保存 0 的值,然后将最后一个元素 3 移动到根节点的位置,得到数组 3,2,1,6,5,4(堆的大小变为 6)。然后对根节点 3 执行向下调整算法,3 的左孩子是 2,右孩子是 1,1 较小,3 大于 1,交换得到 1,2,3,6,5,4,此时 3 的位置是索引为 2,它的左孩子是 4,右孩子不存在,3 小于 4,不需要再调整,满足了小堆的性质。
堆的应用
堆的应用非常广泛,其中最经典的应用之一就是堆排序。
堆排序
堆排序是一种高效的排序算法,它利用了堆的性质来实现排序,时间复杂度为 O(n*log n) ,且是一种原地排序算法 (不需要额外的大量存储空间)。
堆排序的核心逻辑是:
- 升序排序用大根堆:每次提取最大元素(堆顶)放到数组末尾,剩余元素重新调整为大根堆,最终末尾元素依次递增。
- 降序排序用小根堆:每次提取最小元素(堆顶)放到数组末尾,剩余元素重新调整为小根堆,最终末尾元素依次递减。
堆排序的基本思想是:
- 建堆:将待排序的数组构建成一个大堆(如果要进行升序排序)或者小堆(如果要进行降序排序)。对于升序排序,我们选择构建大堆,因为大堆的根节点是最大值,便于我们将最大值放到数组的末尾。
- 交换与调整:将堆顶元素(根节点)与堆的最后一个元素交换位置,此时最大的元素就被放到了数组的末尾(正确的位置)。然后,将堆的大小减小 1(排除已经排好序的最后一个元素),对新的堆顶元素执行向下调整算法,使剩下的元素重新构成一个大堆。
- 重复操作 :重复步骤 2,直到堆的大小为 1,此时整个数组就已经排好序了。
我们通过一个例子来具体了解堆排序的过程。假设待排序的数组是 5,3,1,6,2,4,我们要对其进行升序排序。
首先,将数组构建成一个大堆。按照堆的创建方法,从最后一个非叶子节点开始向下调整,得到大堆 6,5,4,3,2,1。
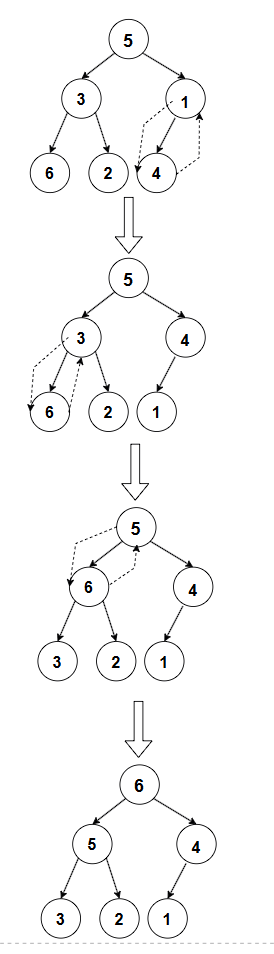
然后,将堆顶元素 6 与最后一个元素 1 交换,得到数组 1,5,4,3,2,6,此时 6 已经排好序。将堆的大小减小为 5,对新的堆顶元素 1 执行向下调整,得到大堆 5,3,4,1,2。
接着,将堆顶元素 5 与当前堆的最后一个元素 2 交换,得到数组 2,3,4,1,5,6,5 排好序。堆的大小减小为 4,对堆顶元素 2 执行向下调整,得到大堆 4,3,2,1。
继续,将堆顶元素 4 与当前堆的最后一个元素 1 交换,得到数组 1,3,2,4,5,6,4 排好序。堆的大小减小为 3,对堆顶元素 1 执行向下调整,得到大堆 3,1,2。
再将堆顶元素 3 与当前堆的最后一个元素 2 交换,得到数组 2,1,3,4,5,6,3 排好序。堆的大小减小为 2,对堆顶元素 2 执行向下调整,得到大堆 2,1。
最后,将堆顶元素 2 与当前堆的最后一个元素 1 交换,得到数组 1,2,3,4,5,6,2 排好序。此时堆的大小为 1,排序结束。
c
// 堆排序(升序)
void heapSort(int* arr, int n) {
if (arr == NULL || n <= 1) {
return;
}
// 构建大堆
for (int i = (n - 1 - 1) / 2; i >= 0; i--) {
heapDownForSort(arr, n, i);
}
// 交换并调整
int end = n - 1;
while (end > 0) {
swap(&arr[0], &arr[end]);
heapDownForSort(arr, end, 0);
end--;
}
}
// 堆排序中使用的向下调整算法(大堆)
void heapDownForSort(int* arr, int size, int parent) {
int child = 2 * parent + 1;
while (child < size) {
if (child + 1 < size && arr[child + 1] > arr[child]) {
child++;
}
if (arr[parent] < arr[child]) {
swap(&arr[parent], &arr[child]);
parent = child;
child = 2 * parent + 1;
} else {
break;
}
}
}堆排序凭借其高效的性能,在很多场景中都得到了广泛的应用,比如在处理大量数据的排序问题时,堆排序是一个非常不错的选择。
堆的代码实现
头文件Heap.h
c
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int HPDataType;
typedef struct Heap
{
HPDataType* a;
int size;
int capacity;
}Heap;
//向下调整算法
void AdjustDown(HPDataType* arr, int n, int parent);
//向上调整算法
void AdjustUp(HPDataType* arr, int child);
void HeapInit(Heap* hp);
// 堆的销毁
void HeapDestory(Heap* hp);
// 堆的插入
void HeapPush(Heap* hp, HPDataType x);
// 堆的删除
void HeapPop(Heap* hp);
// 取堆顶的数据
HPDataType HeapTop(Heap* hp);
// 堆的数据个数
int HeapSize(Heap* hp);
// 堆的判空
int HeapEmpty(Heap* hp);
//用堆来实现排序
void HeapSort(HPDataType* arr, int n);函数实现文件Heap.c
c
#include"Heap.h"
//堆的定义
void HeapInit(Heap* hp)
{
hp->a = NULL;
hp->size = 0;
hp->capacity = 0;
}
// 堆的销毁
void HeapDestory(Heap* hp)
{
assert(hp->a);
free(hp->a);
hp->a = NULL;
}
void Swap(HPDataType* p1, HPDataType* p2)
{
HPDataType tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
//向上调整算法,适用于堆的插入
void AdjustUp(HPDataType* arr, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (arr[child] < arr[parent])
{
Swap(&arr[child], &arr[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
// 堆的插入
void HeapPush(Heap* hp, HPDataType x)
{
assert(hp);
int newcapacity = hp->capacity == 0 ? 4 : hp->capacity * 2;
if (hp->size == hp->capacity)
{
int newcapacity = 2 * hp->capacity;
HPDataType* tmp = (HPDataType*)realloc(hp->a, newcapacity * sizeof(HPDataType));
if (tmp == NULL)
{
perror("realloc fail");
return;
}
hp->a = tmp;
hp->capacity = newcapacity;
}
hp->a[hp->size] = x;
hp->size++;
AdjustUp(hp->a, hp->size-1);
}
//向下调整算法
void AdjustDown(HPDataType* arr, int n, int parent)
{
int child = parent*2+1;
while (child <n)
{
if (child + 1 < n && arr[child] > arr[child + 1])
{
child++;
}
if (arr[child] < arr[parent])
{
Swap(&arr[child], &arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else
break;
}
}
// 堆的删除
void HeapPop(Heap* hp)
{
assert(hp);
assert(hp->a);
Swap(hp->a[0], hp->a[hp->size - 1]);
hp->size--;
AdjustDown(hp->a, hp->size, 0);
}
// 取堆顶的数据
HPDataType HeapTop(Heap* hp)
{
assert(hp);
assert(hp->a);
return hp->a[0];
}
// 堆的数据个数
int HeapSize(Heap* hp)
{
assert(hp);
return hp->size;
}
// 堆的判空
int HeapEmpty(Heap* hp)
{
return hp->size == 0 ? 1 : 0;
}
//用堆来实现排序
void HeapSort(HPDataType* arr, int n)
{
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(arr, n, i);
}
int end = n - 1;
while (end>0)
{
HPDataType tmp = arr[0];
arr[0] =arr[end];
arr[end] = tmp;
AdjustDown(arr, end, 0);
end--;
}
}通过以上内容,我们详细介绍了堆的概念、结构、实现以及在堆排序中的应用。希望这些内容能够帮助你更好地理解和掌握堆这种重要的数据结构,在实际的编程和开发中灵活运用它来解决问题。