作为一名从移动端转前端的开发者,我曾天真以为前端框架 "拿来就能用","没啥护城河","very easy"。
直到遇见 ProseMirror。它既不像 Quill、CKEditor 那样开箱即用,也没有 Draft.js 直观。Selection、Schema、State、Transaction、Plugin、Decorations...等一堆概念直接把我劝退。
后来才发现,ProseMirror 的复杂源于它的 "专业级设计":它不是简单的编辑器组件,而是一套可定制的富文本编辑框架。本文会从开发者视角出发,从宏观到微观,逐步拆解它的构件。
0. 为什么选择 Prosemirror?
对比主流方案,Prosemirror在高度定制的文档结构、多人实时协同编辑、支持复杂的页面逻辑上等等方面具备天然优势。
简单说:如果你的需求是 "快速搭个编辑器",选 Quill、 Draft.js、CKEditor就够;但要做专业的文档协作工具,包括PPT、Word、Excel、在线多人协同文档等等复杂场景,Prosemirror 则是最优解。像金山文档底层就是采用的Prosemirror。
1. 整体框架:编辑器是一棵"文档树"
上来直接展示核心概念,肯定会劝退大部分同学。
当我有这样一篇文档的时候:

其在底层的数据结构是这样的: 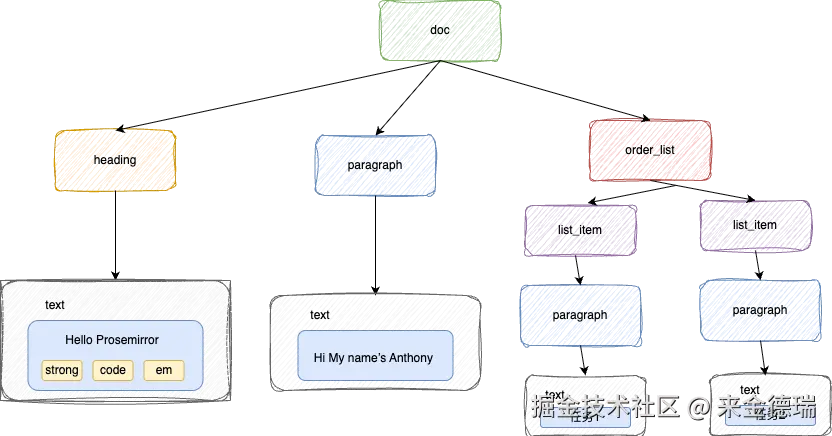 图中,doc是文档的根节点,每一篇文档都必须有个根节点。doc、heading、paragrah、order_list 这种表示节点的名称。
图中,doc是文档的根节点,每一篇文档都必须有个根节点。doc、heading、paragrah、order_list 这种表示节点的名称。
节点有两种类型,一种称为Node,Node可以包含其他Node,最底层的Node称为叶子节点。另一种称呼为Mark,Mark是附属在Node上面的,用于修饰Node,类似于CSS对于DOM tree 中Node Element的修饰。
文档(Document)并不是 HTML 字符串,而是一棵严格定义的树结构。节点(Node) 就像 DOM 里的元素,可以是段落、标题、图片、列表等。Marks 则类似内联样式,比如加粗、斜体、链接。这组成了文档的基本元素。
2. Schema:文档的"语法规则"
既然有文档树,那就需要一份规则手册来约束它能长成什么样,这就是 Schema。
你可以定义哪些节点存在(paragraph、image、table...)。节点能否嵌套?能包含什么?文本是否允许某些样式(marks)。
HTML 是由Dom(文档对象模型)定义的文档树,那么ProseMirror则是由 Scheme定义的文档树。它定义了:允许哪些节点存在,节点之间的嵌套关系,文本是否支持某些标记等等关系。
举个例子,一个最简单的 Schema 可能是:
ts
import { Schema } from "prosemirror-model";
const schema = new Schema({
nodes: {
doc: { content: "block+" }, // 文档根节点必须包含一个或多个块级节点
paragraph: {
content: "text*", // 段落可以包含任意数量的文本
marks: "_" // 允许所有标记应用于段落
},
text: { inline: true } // 文本节点是内联节点
},
marks: {
strong: {}, // 粗体标记
em: {} // 斜体标记
}
});3. State :编辑器的"状态"
你以为编辑器只需要存 "内容"?其实还有 "当前选中的文本范围"、"下一步要加的样式"、"历史记录" 等信息 ------ 这些合起来就是 State(状态)。它相当于编辑器在某一时刻的 "完整快照"。
详细的有:
- doc:当前文档树
- selection:选区信息
- storedMarks:即将应用的标记
- plugins:插件存储的状态数据
- transaction:文档操作对象
State 是一个不可变对象。任何对 State 的修改,都必须通过 "Transaction",不能直接写 state.doc = newDoc,这是 ProseMirror 状态稳定的关键。
4. Transaction:状态变更的 "事务"
每次编辑操作(输入文字、删除、粘贴)都会生成一个 事务(Transaction),它描述了"从旧状态到新状态的变化"。Transaction 也是修改 State 的唯一方式,它记录了一系列对文档的修改操作(Step),并确保这些修改要么全部生效,要么全部不生效。
创建和应用事务的流程如下:
ts
// 假设已初始化好
const { state, dispatch } = view;
// 1. 从当前状态创建一个空事务
let tr = state.tr;
// 2. 往事务里加"修改操作"(可以加多个,批量执行)
tr.insertText("Hello Prosemirror", 0); // 在"位置0"(开头)插入文本
// 给"位置0到16"的文本加粗(16是"Hello Prosemirror"的长度)
tr.setMark(0, 16, mySchema.marks.strong.create());
// 3. 提交事务:生成新 State 并更新视图
dispatch(tr);每个 Transaction 可以包含多个 Step(原子操作),如插入、删除、替换等。这种设计带来两个重要优势:
- 支持撤销 / 重做功能:每个事务都可以被记录和反向应用
- 便于协同编辑:事务可以序列化后在多用户间同步
Transaction是一次编辑操作的集合,那么State则是应用所有事务之后的最新快照。
公式:newState = Transaction(oldState)
5. View:桥接"数据"和"界面"
Schema、State、Transaction都只是数据,用户怎么能看到它?这就需要 EditorView。它把 ProseMirror 的状态(state)渲染成 DOM。
所以:UI = EditorView(EditorState)
下面的极简代码能完整展示数据到界面的过程
ts
import { EditorState } from "prosemirror-state";
import { EditorView } from "prosemirror-view";
import { schema } from "prosemirror-schema-basic";
import { exampleSetup } from "prosemirror-example-setup";
export const setUpEditor = (element: HTMLDivElement) => {
const state = EditorState.create({
schema,
plugins: exampleSetup({ schema })
});
const view = new EditorView(element, { state });
};6. 架构模式:Model-View-Controller

上面这幅图涉及到了ProseMirror的四个基础模块
prosemirror-model-> 定义文档树结构(Model)prosemirror-state-> 保存编辑器状态(State / 数据层)prosemirror-view-> 负责渲染和交互(View)prosemirror-transform-> 提供事务与操作(Controller)
对比传统的MVC架构,是不是有一定的相似性?
7. 总结
ProseMirror 的学习曲线确实陡峭,但它的设计非常优雅。记住这五个核心概念,你就能快速上手:
- 文档树(Node & Mark) → 编辑器的内容模型
- Schema → 定义文档的语法规则
- State & Transaction → 状态与变化的核心机制
- View → 数据与界面的桥梁
- MVC 架构 → 各模块的协作模式