作者:来自 Elastic Mridula Sivanandan

在 Elasticsearch 中探索加权倒数排序融合 (RRF),以及它如何通过实际示例工作。
亲自体验向量搜索,使用这个自定进度的 Search AI 实操学习。你现在可以开始免费云试用,或在本地机器上尝试 Elastic。
想象一下:你正在构建一个餐馆搜索,需要平衡位置相关性和菜系匹配。有些查询更关注 "pizza near me, - 离我近的 pizza",而另一些则优先考虑"Italian restaurants that serve cacio e pepe - 提供 cacio e pepe 的意大利餐馆" 或 "highly reviewed Italian restaurants - 评价很高的意大利餐馆"。直到现在,Elasticsearch 的倒数排序融合 (RRF) 一直把所有检索器视为平等,但你的搜索策略不应该如此。
这就是加权 RRF 的用武之地。它不再让每个检索器在搜索结果中拥有同样的权重,而是允许你微调它们的影响,从而创造更细致和更有效的搜索体验。在这篇博客中,我们将探讨加权 RRF 的必要性,并演示如何在不同的搜索场景中使用它。
挑战:一刀切并不适用
RRF 非常适合将不同的检索策略 ------ 比如关键词、语义和向量搜索 ------ 组合成一个单一的排序结果集。但如果对所有检索器一视同仁,当某些检索方法对特定查询类型更有价值时,就可能限制搜索质量。
想象一个餐厅搜索,不同的查询类型需要不同的排序策略:
- 以位置为中心的查询,比如 "pizza near me",需要以城市、社区或距离等基于位置的信号在排序中占主导。
- 以菜品为中心的查询,比如 "Italian restaurants that serve cacio e pepe",应当优先考虑菜单项匹配和菜系类型,而不是距离远近。
- 以质量为中心的查询,比如 "highly reviewed Italian restaurants",应当把评分和评论置于所有其他因素之上。
在加权 RRF 出现之前,平衡这些信号的标准方法是分数的线性组合(分配固定权重并求和)。虽然功能强大,但这种方式往往需要通过多次搜索、自定义打分函数或人工后处理等变通手段,而这些都很难维护和有效调整。
加权 RRF 消除了这些痛点,它提供了一个统一的框架,让每个检索器都有自己的权重,并由 RRF 算法自动处理排序融合。
解决方案:通过加权实现精确
加权 RRF 提供了一种简单但强大的方式,可以为不同的检索器分配不同的重要性等级。每个检索器现在都接受一个权重参数,用来影响它对最终 RRF 分数的贡献。
这对你的搜索意味着什么
加权 RRF 给了你更大的灵活性,可以创建更智能、更贴合需求的搜索体验。
更智能的相关性调优:不再是一刀切的排序。对于概念性查询("find restaurants with cozy atmosphere"),可以给语义搜索检索器更高的权重;而对于具体词语("Margherita pizza"),则提升关键词匹配的权重。
实践中的运作方式
假设你正在构建餐厅搜索。以下是加权 RRF 如何在不同搜索场景下改变查询策略的示例:
场景 1:"Pizza near me" ------ 以位置为中心的搜索
一个用户在手机上搜索 "pizza near me"。在这种情况下,距离最重要。加权 RRF 让我们能够给予基于位置的信号(城市、社区、邮政编码)更多的影响力,而不是关键词 "pizza" 的匹配。
下面是该查询在 JSON 中可能的样子:
bash
`
1. {
2. "retriever": {
3. "rrf": {
4. "retrievers": [
5. {
6. "retriever": {
7. "standard": {
8. "query": {
9. "multi_match": {
10. "query": "Vienna",
11. "fields": ["city", "neighborhood", "postal_code"]
12. }
13. }
14. }
15. },
16. "weight": 0.8
17. },
18. {
19. "retriever": {
20. "standard": {
21. "query": {
22. "match": {
23. "menu_items": "pizza"
24. }
25. }
26. }
27. },
28. "weight": 0.2
29. }
30. ]
31. }
32. }
33. }
`AI写代码这种加权方式会偏向附近的餐厅,即使菜单文本匹配较弱。
场景 2:"Italian restaurants that serve cacio e pepe" ------ 以菜系和菜品为中心的搜索
在这里,用户想要寻找特定的菜系和菜品。加权 RRF 强调菜系和菜单匹配,同时仍然允许距离作为次要因素发挥作用。
下面是该查询在 JSON 中可能的样子:
markdown
`
1. {
2. "retriever": {
3. "rrf": {
4. "retrievers": [
5. {
6. "retriever": {
7. "standard": {
8. "query": {
9. "match": {
10. "cuisine_type": "Italian"
11. }
12. }
13. }
14. },
15. "weight": 0.4
16. },
17. {
18. "retriever": {
19. "standard": {
20. "query": {
21. "match": {
22. "menu_items": "cacio e pepe"
23. }
24. }
25. }
26. },
27. "weight": 0.6
28. }
29. ]
30. }
31. }
32. }
`AI写代码这种加权方式会提升那些明确提到该菜品和菜系的餐厅,即使它们距离稍远。
场景 3:"Highly reviewed Italian restaurants" ------ 以质量和菜系为中心的搜索
当质量是首要考虑时,评分占据最重要的权重。加权 RRF 允许评分阈值引导排序,同时将菜系类型作为辅助因素。
下面是该查询在 JSON 中可能的样子:
markdown
`
1. {
2. "retriever": {
3. "rrf": {
4. "retrievers": [
5. {
6. "retriever": {
7. "standard": {
8. "query": {
9. "range": {
10. "rating": {"gte": 4.5}
11. }
12. }
13. }
14. },
15. "weight": 0.7
16. },
17. {
18. "retriever": {
19. "standard": {
20. "query": {
21. "match": {
22. "cuisine_type": "Italian"
23. }
24. }
25. }
26. },
27. "weight": 0.3
28. }
29. ]
30. }
31. }
32. }
`AI写代码这种加权方式会提升高评分的 Italian 餐厅,在保持菜系相关性的同时,让评分起主导作用。
加权 RRF 通过为每个检索器设置权重,把这些偏好直接编码进排序中,因此最终的顺序能够反映每个查询真正重要的因素。
底层原理
在计算最终分数时,标准的 RRF 公式被加上了权重:
示例:rank_constant = 60。每个检索器的贡献为:weight × 1 / (rank + rank_constant)。权重越高,影响力越大;排序从 1 开始。
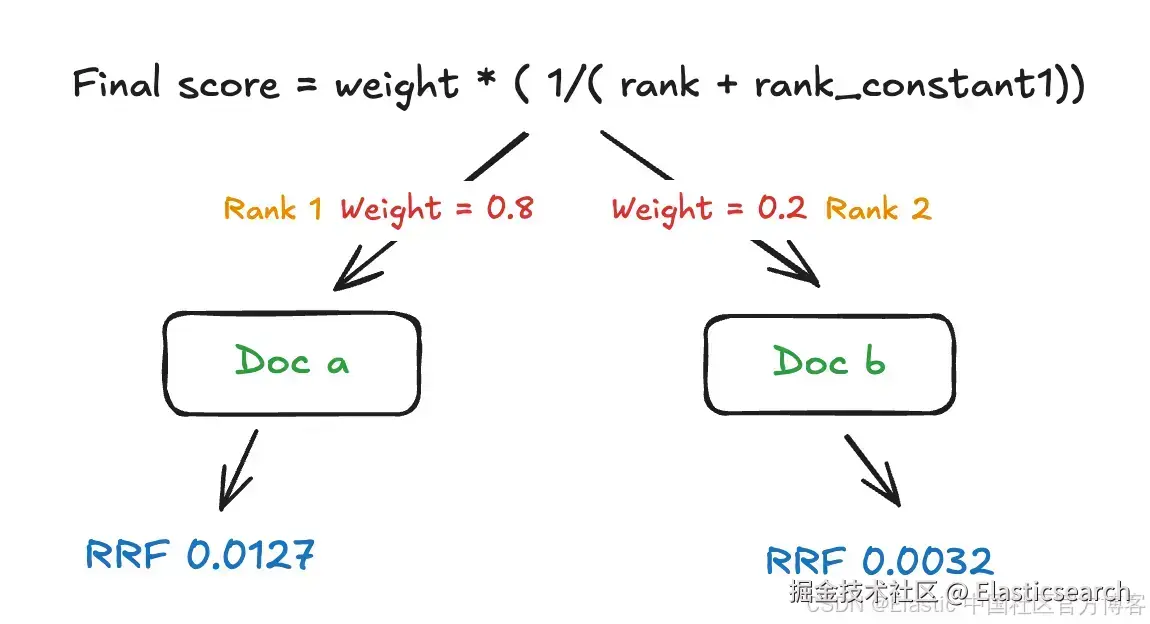
关键技术特性包括:
- 权重可选:当你需要更精细的控制时,可以选择为每个检索器单独设置权重;如果只有部分检索器需要加权,也可以使用默认权重。
- 输入校验:权重必须是非负数。
想要进行高级定制和混合评分(包括归一化),请参阅 Linear retriever www.elastic.co/docs/refere...
接下来?
加权 RRF 将 RRF 扩展到生产场景中,这些场景需要比标准 RRF 更多的控制。那些需要对搜索相关性进行细粒度控制的团队,现在可以使用 RRF,而不必再构建自定义解决方案。无论是餐厅搜索中平衡位置和菜系,电商搜索中平衡品牌和类别,还是其他复杂的排序场景,加权 RRF 都能提供你所需的精确度。
我们迫不及待想看到你如何使用加权 RRF 来打造更智能、更灵活的搜索体验。祝搜索愉快!
准备深入了解?请查阅我们官方文档中的 Reciprocal Rank Fusion 和 Retriever APIs。