8 月 5 日,全球权威 AI 工程联盟 MLCommons 发布了最新的 MLPerf® Storage v2.0 基准测试结果。本次评测吸引了众多厂商参与,包括 Cloud、Shared File、Fabric-Attached Block、Direct-Attached Block 这几大类存储厂商。
由于各厂商在硬件配置、节点规模和应用场景上的差异,直接进行横向比较存在局限性。因此,本文将聚焦于共享文件系统这一类别,分析其在相同测试标准下的表现。
JuiceFS 是支持云上以及机房部署的高性能分布式文件系统。在多个 AI 训练负载下,JuiceFS 均取得了优异的成绩,尤其在带宽利用率、可扩展性等方面均处于领先水平。接下来,本文将结合具体测试结果展开分析,并进一步介绍支撑这些表现的关键特性。
01 MLPerf Storage v2.0 及其测试负载
MLPerf 是 MLCommons 推出的通用 AI 基准评测套件,其中的 MLPerf Storage 通过多客户端模拟真实 AI 负载访问存储系统,能够复现大规模分布式训练集群场景存储负载,从而全面评估存储系统在 AI 训练任务中的实际表现。
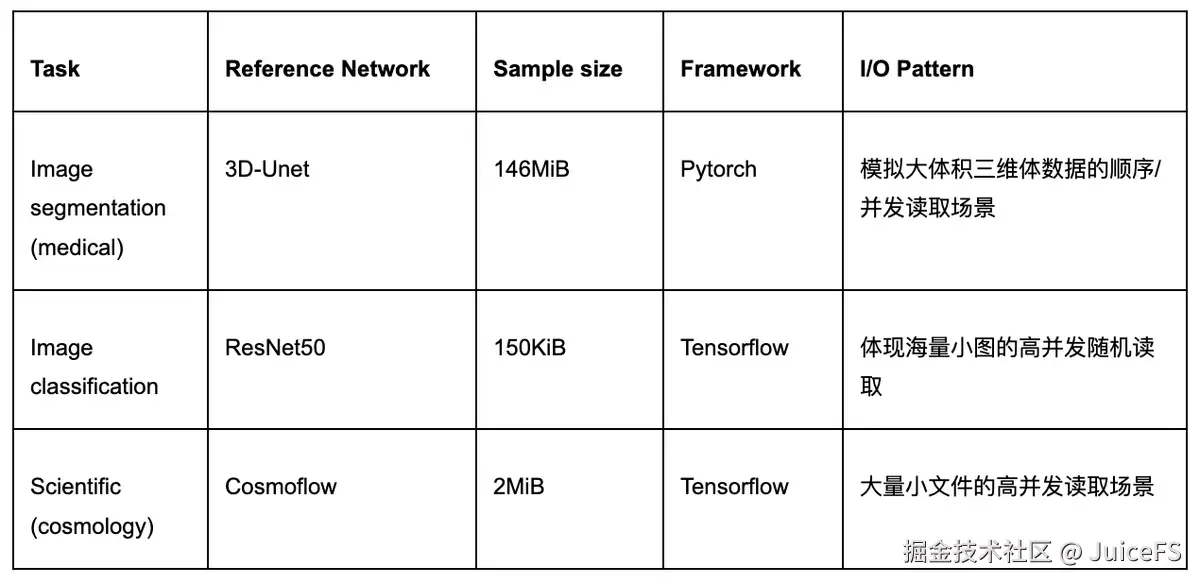
在最新的 v2.0 版本中,MLPerf Storage 提供了三类训练负载,覆盖了深度学习训练中最具代表性的 I/O 模式。
在 3D U-Net 医疗分割负载中,系统需要处理大体积三维医学图像的顺序和并发读取。每个样本平均大小约为 146 MB,并作为独立文件存储。这类任务主要考察存储系统在大文件连续读取场景下的吞吐性能,以及在多节点同时访问时能否保持稳定的响应能力。
ResNet-50 图像分类负载则完全不同,它是小样本的高并发随机读取压力。每个样本平均大小只有 150 KB,数据通过 TFRecord 格式打包存放在大文件中。这样的数据组织方式使得训练过程中存在大量随机 I/O 和频繁的元数据访问,因此该负载对存储系统的 IOPS 提出了极高要求,是衡量小文件场景下并发性能的重要测试。
CosmoFlow 宇宙学预测负载,强调的是跨节点场景下的小文件并发访问和带宽扩展性。每个样本平均 2 MB,通常以单文件形式存储在 TFRecord 中。由于涉及海量小文件的分布式读取,系统不仅要具备足够的整体吞吐能力,还需要在元数据处理和尾延迟控制上表现稳定,否则随着节点规模的增加,延迟波动会显著放大并拖慢整体训练速度。
此外,此次 V2.0 版本中还提供了一类全新的 Checkpointing 负载,用于模拟大模型训练中的 checkpoint 落盘与恢复,主要表现为大文件多并发顺序写负载。在 JuiceFS 架构下,checkpoint 数据通过 JuiceFS 写入到对象存储中,性能瓶颈取决于作为数据持久层的对象存储带宽上限。
02 性能比较:产品类别、弹性扩展能力与资源利用率
在这次 MLPerf Storage v2.0 的测试中,参与的厂商数量众多,涉及块存储和共享文件系统等多种类型,但由于这些类型的存储系统在架构和应用场景上差异大,且各厂商在测试中使用的硬件配置与节点规模差异显著,因此横向对比意义有限。
本文将重点分析共享文件系统这一类别下的结果。在共享文件系统阵营中,还可以进一步细分为两类:
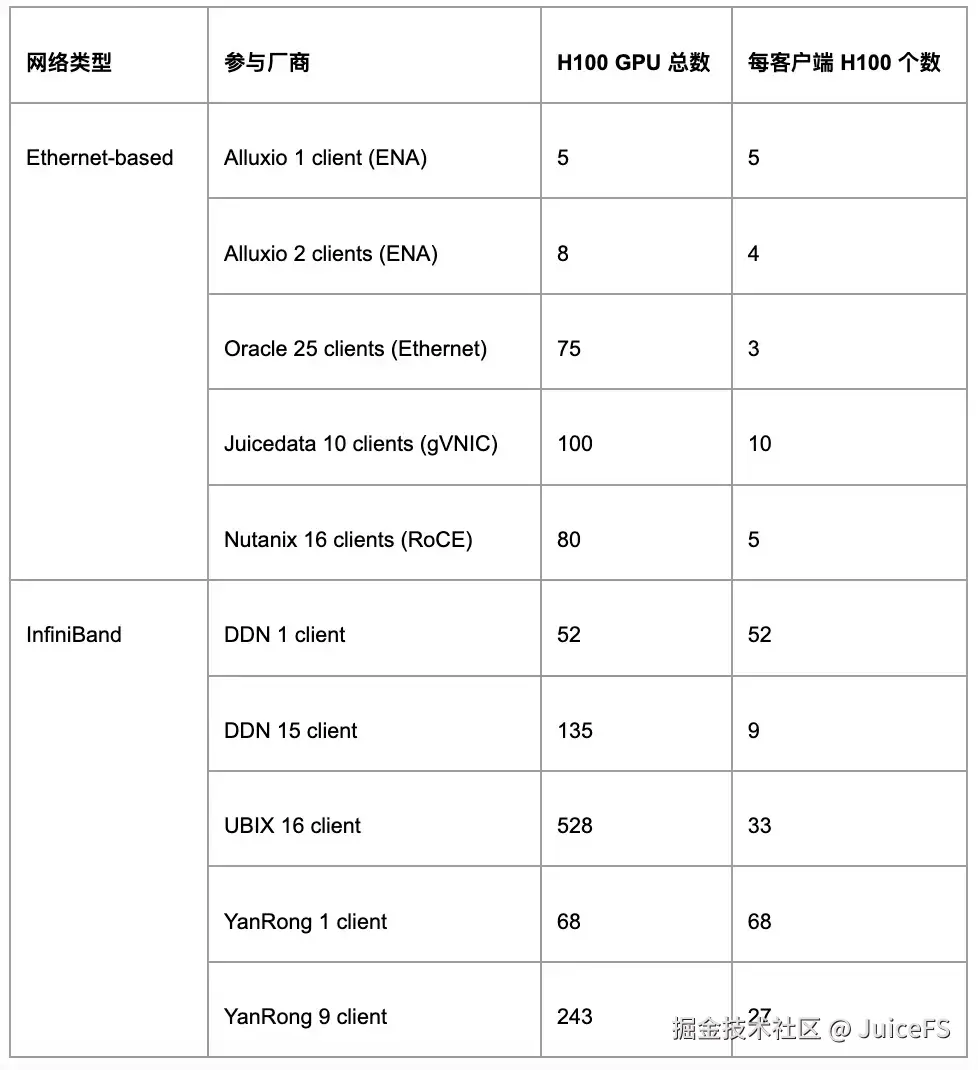
第一类是基于以太网的系统,包括 Alluxio、JuiceFS 和 Oracle,这些云上系统依赖以太网环境提供分布式存储能力,从而实现高性能存储。另有一些厂商,如 Nutanix 和华为,则采用了基于 RoCE 的以太网方案,单机通常配置更高带宽的网卡。
第二类则是基于 IB 网络的存储解决方案,例如 DDN、Hewlett Packard、Ubix 和焱融。这些厂商提供的是完整的存储软硬一体机,通常基于 IB 网络。其硬件配置非常高,整体成本较高,能够提供极高的带宽和性能上限。

在展开结果解读之前,我们先介绍此次比较所依据的标准。
MLPerf Storage 的文档中要求提交的结果满足 GPU 利用率阈值,并尽可能提高 GPU 数量(规模),其中 3D U-Net 与 ResNet-50 的阈值为 90%,Cosmoflow 的阈值为 70%。在满足 GPU 利用率阈值的前提下,真正体现差异的核心指标是存储系统所能支撑的最大 GPU 数量,而这一规模实质上取决于系统能够提供的最大聚合带宽。能够支撑更多 GPU 的存储系统,意味着在大规模训练场景中具备更强的可扩展性与稳定性。尤其是在 Cosmoflow 这样的负载中,由于涉及大量小文件且对延迟高度敏感,对存储系统的扩展性提出了更严苛的考验。
其次,还需要从资源利用率的角度来比较结果 。对于软件厂商而言,关键在于存储软件是否能够充分发挥底层硬件的潜力。存储系统的瓶颈通常是网络带宽,为此,我们采用网卡带宽利用率作为参考指标:利用率越高,说明软件的效率越高,也意味着在相同硬件条件下具备更高性能和性价比。
03 JuiceFS 测试结果解读
在 3D-Unet 负载中,JuiceFS 实现了高达 108 GiB/s 的数据读取带宽,支撑了 10 节点共 40 张 H100 GPU的训练规模,网络带宽利用率达到 86.6%, GPU 利用率是 92.7%。
在 CosmoFlow 负载中,JuiceFS 支撑了 10 节点共 100 张 H100 GPU 的训练规模,GPU 利用率为 75%。这一负载对存储延迟的稳定性要求极高,对网络带宽的要求较低,性能瓶颈并不在带宽。由于需要处理海量小文件的并发访问,IO 延迟大小及延迟稳定性直接决定了整体扩展能力,并限制了 GPU 的利用率。
在 ResNet-50 负载中,JuiceFS 的数据读取带宽达到 90 GiB/s,网络带宽利用率为 72%,整体 GPU 利用率为 95%。
📝 需要说明的是,本次测试在 GCP 上选用的机型中,单个可用区能稳定开启的弹性实例数量有限,因此我们提交的测试最大规模为 10 节点。这并不代表 JuiceFS 系统的最大承载能力,系统在更大规模节点下仍可提供更高的聚合带宽和训练规模。
背景回顾:GPU 规模受限于存储网络的带宽能力
JuiceFS 参与 MLPerf 测试已经进入第三年。第一年我们基于 v0.5 版本自行进行了完整的测试,当时使用的是 V100 GPU 进行模拟。
由于 V100 的单卡带宽需求较低,在较长区间内,GPU 利用率始终维持在 99% 附近,随着训练的 GPU 规模扩大而缓慢下降至 98%左右。直到总带宽接近网卡带宽上限时,才出现拐点,此后随着 GPU 数量增加,利用率便迅速下降。具体分析可参考我们之前的文章:千卡利用率超98%,详解JuiceFS在权威AI测试中的实现策略。根据图中的数据,在 GPU 利用率为 90% 时,大约能支持 110 张 V100 GPU,这一规模上限主要受制于存储网络的带宽能力。
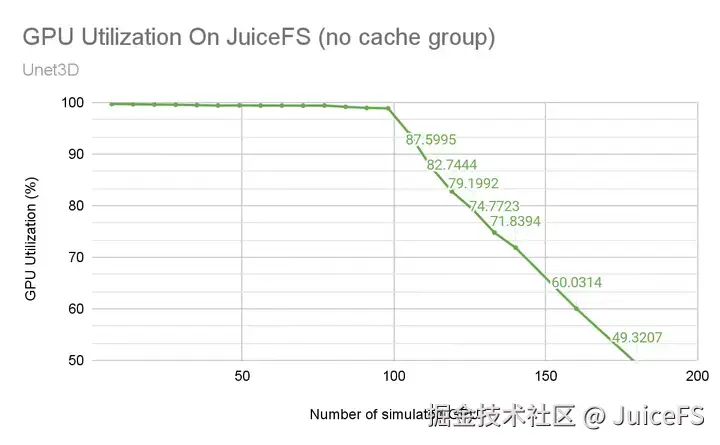
3D-Unet:JuiceFS 以最高带宽与带宽利用率领跑同类系统
3D-Unet 训练负载属于大文件连续读取负载,这类负载对存储系统的读带宽提出了较高要求。
从下图可以清楚看到,在所有基于传统以太网的存储系统中,JuiceFS 的表现最为优秀:在 10 节点、40 张 H100 的规模下,实现了 108 GiB/s 的数据读取带宽,网络带宽利用率达到 86.6%,在同类系统中均为最高。这意味着 JuiceFS 不仅能够提供更高的总带宽,同时也能更充分地发挥网络和硬件资源的性能,从而在性价比上具备显著优势。
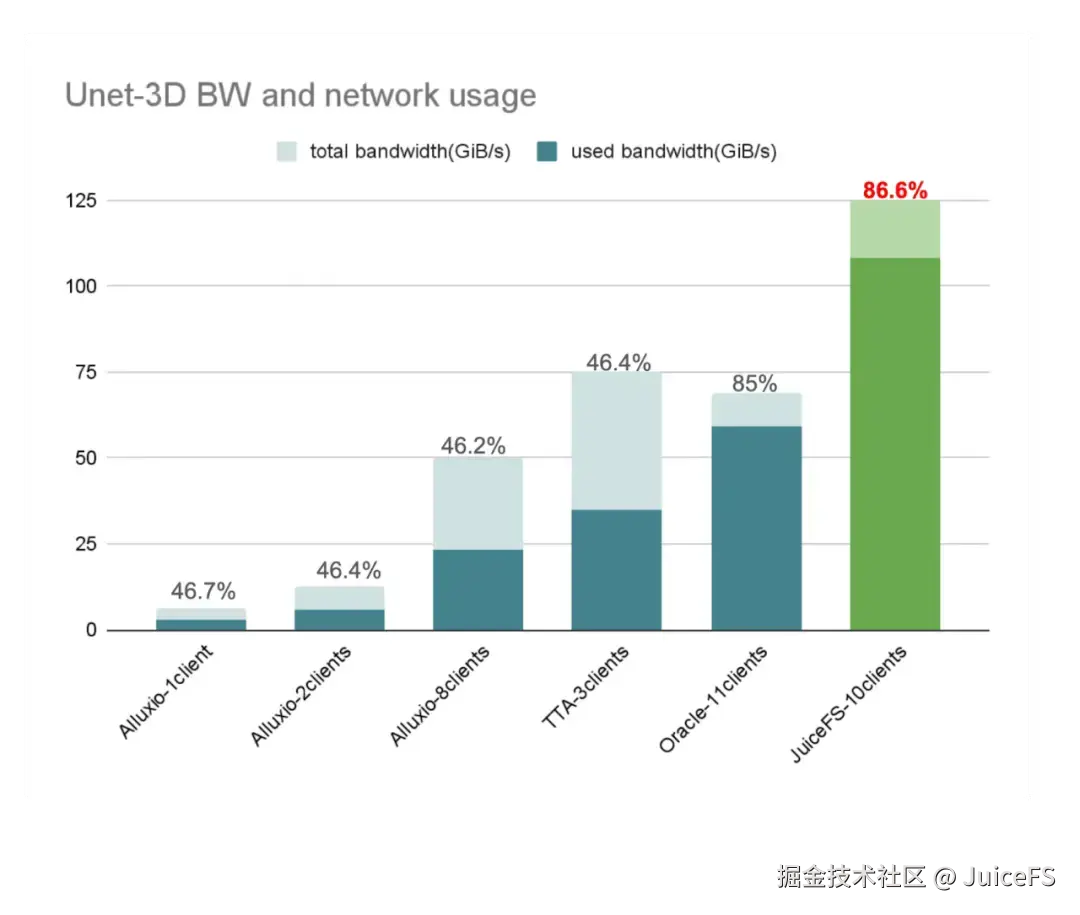
下面这部分是使用 IB 网络和 RoCE 网络(RDMA over Converged Ethernet)的参测厂商结果。这两类厂商的硬件规格整体都非常高,最低的网络总带宽在 400 GiB/s 左右,最高的甚至超过 1500 GiB/s。因此,它们能够为训练业务提供极高的总带宽。值得一提的是 JuiceFS 在弹性扩展分布式缓存节点数后,亦能达到类似的带宽水平,近期测试中,基于 100 台 GCP 100Gbps 节点组成的分布式缓存集群,其聚合读带宽已达到 1.2 TB/s。
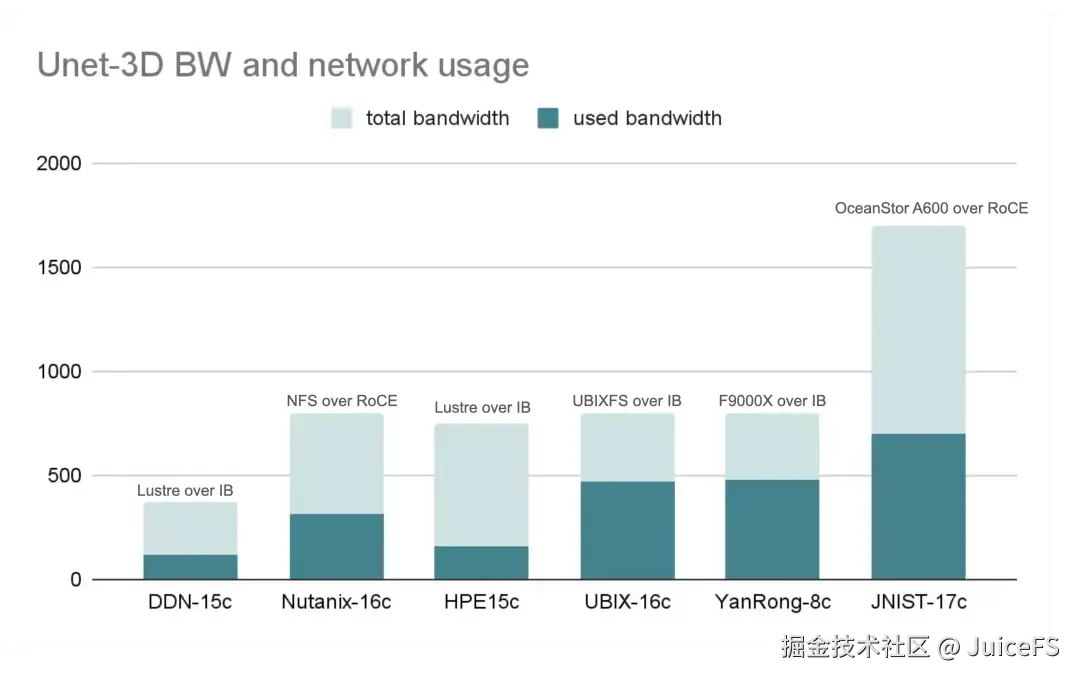
从利用率的角度来看,随着单张网卡带宽的提升,网络带宽利用率会越来越难以提高。在 400 Gb/s 甚至更高规格的网卡配置下,要将带宽利用率做到接近 80% 都是非常有挑战性的。
Cosmoflow:JuiceFS 支撑百卡规模,扩展能力领先
CosmoFlow 训练负载需要读取海量小文件,这对存储系统的元数据性能和读延迟性能提出了极高要求,同时测试规定 GPU 利用率需达到 70% 以上。由于任务对延迟要求非常高,随着 H100 数量的增加,多节点分布式训练的读取延迟方差会显著增加,从而使得 GPU 利用率快速下降,导致水平扩展十分困难。与 3D U-Net 相比,CosmoFlow 的提交结果总数明显更少,这也反映了该负载优化难度较大。
下图横轴表示系统能够支撑的 GPU 总数,即 H100 GPU 的数量,JuiceFS 的表现继续领先。通过 10 个客户端同时运行,成功支撑了 100 张 H100 GPU 的 Cosmoflow 训练任务,GPU 利用率保持在规定阈值以上。
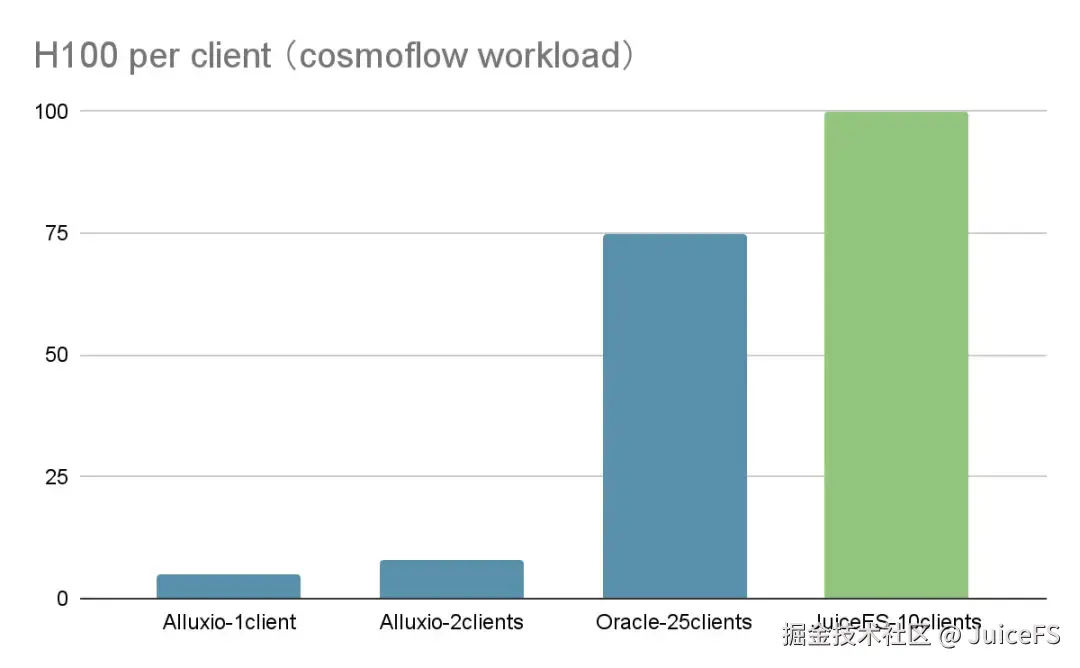
与此同时,基于 IB 网络的系统在该负载下表现尤为突出。这得益于 IB 网络系统性提供了全链路的极低且高度稳定的延迟。尽管其成本较高,但在延迟敏感型任务中,IB 网络的性能优势依然是不可忽视的。
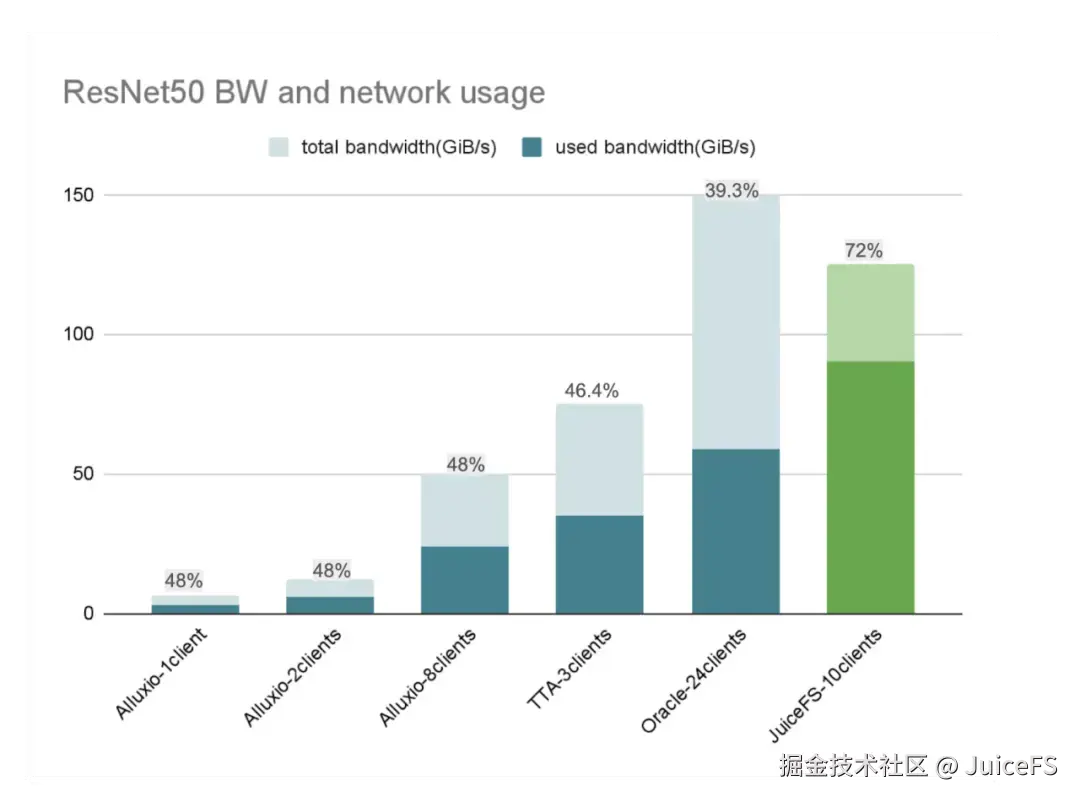
ResNet50: JuiceFS 支持最多 H100, 带宽利用率最高
ResNet-50 训练负载属于大文件高并发随机读负载,对存储系统的 IOPS 提出了极高要求,并要求 GPU 利用率保持在 90% 以上。
在该测试中,JuiceFS 在同类系统中支撑了最多数量的 500 张 H100 GPU,并在所有基于以太网的方案里实现了最高的网络带宽利用率,达到 72%,远高于其他厂商普遍约 40% 的水平。同时,GPU 利用率保持在 95%。这一结果表明,JuiceFS 在高并发随机 I/O 场景下,能够充分发挥软件层面的优化能力,高效利用硬件资源,从而展现出领先的性能和效率。
04 JuiceFS 在 MLPerf 测试中的系统配置
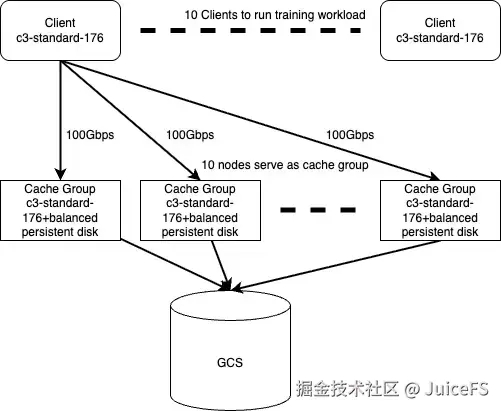
本次测试中,JuiceFS 的系统拓扑主要分为三层:
- 客户端层:最上层为 10 个客户端节点,统一运行在 GCP 的同一机型上,各节点的带宽配置完全对等,保证了客户端侧的均衡性。
- 缓存集群层:中间层为缓存集群,共 10 个缓存节点,缓存节点使用云盘并结合本地内存作为缓存,加速数据访问。
- 冷数据存储层:数据最终都保存在 GCS 中。
在训练开始前,冷数据会从 GCS 预热到缓存集群;训练过程中,客户端则直接从缓存集群中读取数据。这种方式避免了在训练中访问高延迟的对象存储,能够提供稳定的高带宽和低延迟访问,从而满足大规模 AI 训练的持续数据需求。
本轮 MLPerf Storage 测试中,规则允许增加一轮"预热测试"。因此,即便是不支持主动预热功能的系统,也能在测试前提前将预热数据加载到缓存中,保证了测试的公平性;此外,大家还能够享受到 page cache 带来的性能提升,这对于延迟敏感的负载(cosmoflow)来说也十分关键。
在当前配置下,10 个客户端与缓存集群能够支撑约 40 张 H100 GPU 的训练规模。如果训练规模继续扩大,例如 GPU 数量翻倍,只需按比例扩展缓存集群节点数,即可匹配新的带宽需求。这种架构展现了高度的灵活性和弹性,能够适配更大规模的训练任务。
JuiceFS 在本次测试中取得的好成绩,首先依赖于高性能的元数据引擎。该引擎具备非常高的 IOPS 和极低的延迟性能,同时在客户端也集成了元数据缓存,从而显著降低了访问延迟。这一能力对 CosmoFlow 负载尤为关键,因为该场景涉及大量小文件并发访问,对延迟高度敏感,稳定的低延迟保证了 GPU 利用率和整体扩展性。
另一个核心优势是分布式缓存。实测表明,JuiceFS 的缓存集群可提供高达 1.2 TB/s 的聚合带宽(基于 100 台 GCP 100Gbps 节点,数量上限受制于 GCP 上该机型选定分区下的可用机器数量 ),并将访问延迟降低至亚毫秒级。缓存集群支持弹性扩缩容,既能在带宽上提供极致性能,也能根据任务需求扩展 IOPS和带宽。在 ResNet-50 负载中,JuiceFS 的高 IOPS 性能起到了决定性作用。在以太网环境下的对比中,JuiceFS 依靠 IOPS 优势脱颖而出,带宽利用率达到 72%,GPU 利用率保持在 95%。
05 小结
本文分析了此次 MLPerf Storage v2.0 测试结果。在评估存储产品的 GPU 利用率之前,用户首先需要了解存储产品的类型,包括其架构、硬件资源及成本等因素。在 GPU 利用率达标的前提下,存储系统的关键差异体现在其能够支撑的最大 GPU 数量,能够支持更多 GPU 的存储系统意味着在大规模训练场景中具备更强的可扩展性与稳定性。此外,还需关注资源利用率,即存储软件是否能够充分发挥底层硬件的潜力。
JuiceFS 在此次测试的不同 AI 训练负载下展现出稳定的低延迟和高效的资源利用率。作为一款全用户态、云原生的分布式文件系统,它利用分布式缓存实现高吞吐与低延迟,同时借助对象存储保证了成本优势,为大规模 AI 训练提供了无需依赖昂贵专有硬件的可行选择。
我们希望本文中的一些实践经验,能为正在面临类似问题的开发者提供参考,如果有其他疑问欢迎加入 JuiceFS 社区与大家共同交流。