向量数据库概念
向量数据库是专为高维向量数据设计的数据库系统,能够将文本、图像、音频等非结构化数据转化为数学向量(即高维数组),并基于相似性度量(如余弦相似度、欧氏距离)实现高效检索。
核心优势
- 处理非结构化数据:通过嵌入模型(Embedding)将复杂数据转化为向量,突破传统数据库的行列限制。
- 近似最近邻搜索(ANN):利用索引技术(如HNSW、LSH)实现毫秒级海量数据检索,支持模糊匹配。
- 多模态支持:统一管理文本、图像、视频等多源数据,构建跨模态检索能力
Milvus
Milvus 是一款开源向量数据库
普通数据库(比如 Excel 表格)存的是文字、数字(比如 "苹果,红色,5 元"),而向量数据库专门存上面说的 "向量",因为 AI 处理数据时,不是直接比文字,而是比向量。
安装
milvus文档:milvus.io/zh
js
pip install pymilvus在win安装报错 The milvus-lite readme says it only supports Ubuntu and MacOS. So, in windows os, the milvus-lite package won't be installed along with pymilvus.
只支持Ubuntu
入门
在 Milvus 里,需要借助 Collections 来存储向量及其相关元数据,可将其类比为传统 SQL 数据库中的表格。创建 Collections 时,能定义 Schema 和索引参数,以此配置向量规格,包括维度、索引类型和远距离度量等。此外,还有一些复杂概念用于优化索引,提升向量搜索性能。但就目前而言,重点关注基础知识,并尽量采用默认设置。至少,需设定 Collections 的名称和向量场的维度。例如:
js
from pymilvus import MilvusClient, DataType
client = MilvusClient("milvus_demo.db")
# 创建schema
schema = client.create_schema(
auto_id=False,
enable_dynamic_field=True,
)
# 添加字段
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=128)
# 创建集合
client.create_collection(
collection_name="my_collection",
schema=schema
)Collection
Collection是一个二维表格,拥有固定的列和行,每一列表示一个字段,每一行表示一个实体,
构建Collection
构建一个Collection需要如下三个步骤:
- 需要创建Schema,Schema定义了Collection的列和字段的类型。
- 设置索引参数(可选)。
- 创建Collection
首先,对于Schema,参考如下代码:
js
from pymilvus import MilvusClient, DataType
# 创建MilvusClient实例
client = MilvusClient(uri="http://localhost:19530")
# 定义collection schema
schema = client.create_schema(
auto_id=False,
enable_dynamic_fields=True,
)
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="content", datatype=DataType.VARCHAR, max_length=1024)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=1024)其次创建索引,加载集合
js
# 设置索引参数
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "IP",
"params": {
"nlist": 1024
}
}
# 在vector字段上创建索引
collection.create_index(
field_name="embedding",
index_params=index_params,
timeout=None
)
# 加载整个collection
collection.load()
# 或加载指定字段
collection.load(
load_fields=["id", "embedding"],
skip_load_dynamic_field=True
)基本向量搜索
ANN 搜索和 kNN 搜索
-
什么是 "kNN 搜索"? 全称是 "k 近邻搜索"。简单说就是:拿你的查询向量,和数据库里所有向量一个个比,找出最像的前 k 个(k 是你指定的数量,比如前 5 个)。
-
什么是 "ANN 搜索"? 全称是 "近似近邻搜索"。它不跟所有向量比,而是用 "偷懒" 的办法:提前给向量做 "分类整理"(也就是建 "索引"),然后只在 "可能相似的小范围" 里找,最后返回差不多像的前 k 个。
-
ANN 搜索基础 与 kNN 的区别:kNN 需比较所有向量,耗时耗资源;ANN 依赖预建索引文件,快速定位相似向量子组,平衡性能与正确性。 AUTOINDEX:自动分析集合数据分布,优化索引参数,降低使用门槛,适配多种度量类型。 度量类型:不同度量方式对应不同相似度判断标准,如L2(值越小越相似)、IP(值越大越相似)等,距离范围各有不同。
标量查询(Query)
js
from pymilvus import MilvusClient
client = MilvusClient("http://localhost:19530")
results = client.query(
collection_name="product_recommendation",
filter="", # 空表达式查询所有数据
output_fields=["id", "category", "brand", "price"],
limit=100 # 限制返回100条记录
)
print("所有商品数据:")
for result in results:
print(f"ID: {result['id']}, 类别: {result['category']}, "
f"品牌: {result['brand']}, 价格: {result['price']}")条件查询
js
# 2. 基于单个条件查询
results = client.query(
collection_name="product_recommendation",
filter='category == "electronics"',
output_fields=["id", "category", "brand", "price"]
)
print("电子产品:")
for result in results:
print(f"ID: {result['id']}, 品牌: {result['brand']}, 价格: {result['price']}")
# 3. 基于数值范围查询
results = client.query(
collection_name="product_recommendation",
filter='price >= 100 and price <= 1000',
output_fields=["id", "category", "brand", "price"]
)
print("价格在100-1000之间的商品:")
for result in results:
print(f"ID: {result['id']}, 类别: {result['category']}, "
f"品牌: {result['brand']}, 价格: {result['price']}")索引
一种典型的"空间换时间"策略
向量索引解决了两个关键问题:
- 海量数据的快速检索:当你有百万、千万甚至亿级向量时,暴力搜索(逐一比较)会变得极其缓慢
- 近似的"足够好"结果:在大多数应用场景中,我们不需要100%精确的结果,95%的准确性已经足够,但速度提升是巨大的
ANNS技术核心与价值
ANNS(近似近邻检索)的核心技术理念 在于不局限于返回最精确的topK结果,而是通过在可接受范围内牺牲一定精确度,换取检索效率的显著提升。其核心价值体现在能够有效加快大型数据集上相似性搜索的速度,从而提升此类查询的实用性 。
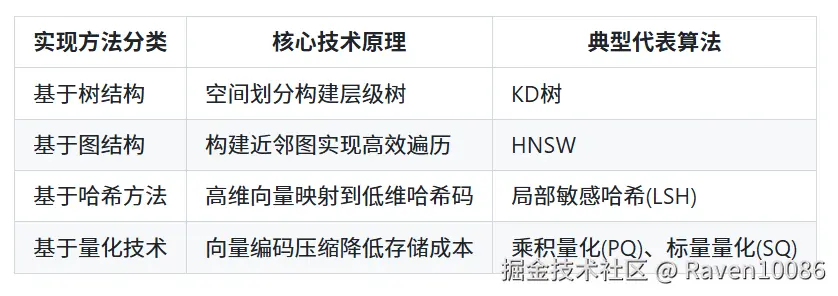
索引分类
从实现方法角度 ANNS向量索引可分为四大类:基于树结构、基于图结构、基于哈希方法和基于量化技术。
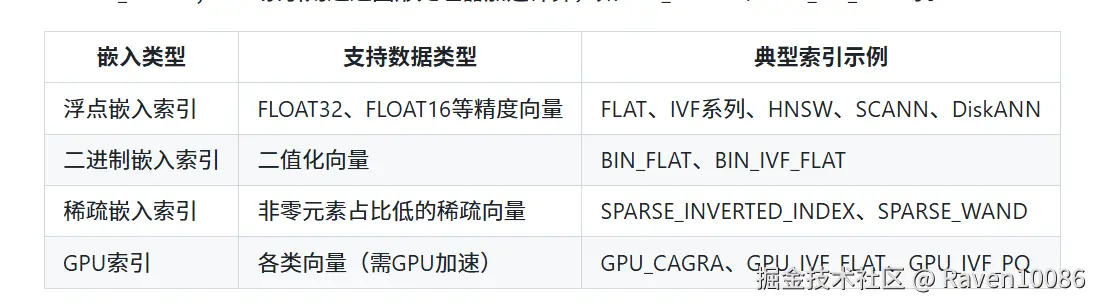
 从向量嵌入类型角度
从向量嵌入类型角度
索引可按处理的数据类型划分为浮点嵌入索引、二进制嵌入索引、稀疏嵌入索引及GPU索引。
归一化
假设你有一个向量 V = [3, 4] (想象一个从原点指向点(3,4)的箭头)。
Step 1: 计算这个向量的长度(L2范数) 长度 = ||V||₂ = √(3² + 4²) = √(9 + 16) = √25 = 5
Step 2: 把向量中的每一个数字都除以这个长度归一化后的向量 V_norm = [3/5, 4/5] = [0.6, 0.8]
聚类算法
K-Means
原理: k-means 的核心思想是,把数据分成 k 个群组(也叫簇),每个群组都有一个"中心点"(也叫质心),目标是让每个点都尽可能靠近自己群组的中心点。简单来说,就是"物以类聚,人以群分"。
步骤:
选中心: 先随机选 k 个点,把它们当成初始的中心点。
分堆: 把每个数据点都分到离它最近的中心点所在的群组。
算中心: 重新计算每个群组的中心点(通常是这个群组里所有点的平均值)。
重复: 重复 "分堆" 和 "算中心" 这两步,直到中心点不再怎么变化,或者达到你设定的最大循环次数。
算法详解:github.com/datawhalech...
HDBSCAN
核心概念:
核心距离: 对于每个点,找到包含至少 minPts 个点的最小半径,这个半径就是该点的核心距离。
可达距离: 点 A 到点 B 的可达距离是:点 B 的核心距离 和 A 到 B 的实际距离,两者取最大值。
互达性图: 基于可达距离构建的图,距离越小,连接越紧密。
簇的提取: 通过在互达性图上进行聚类,提取簇。
步骤(简化版):
算密度: 评估每个点周围的密度。
建树: 构建一个层次聚类树,把密度相近的点放在一起。
剪枝: 根据密度和连通性,对聚类树进行剪枝,去除噪声和不稳定的簇。
提取簇: 从剪枝后的树中提取最终的簇。
复现项目地址:github.com/datawhalech...
感悟
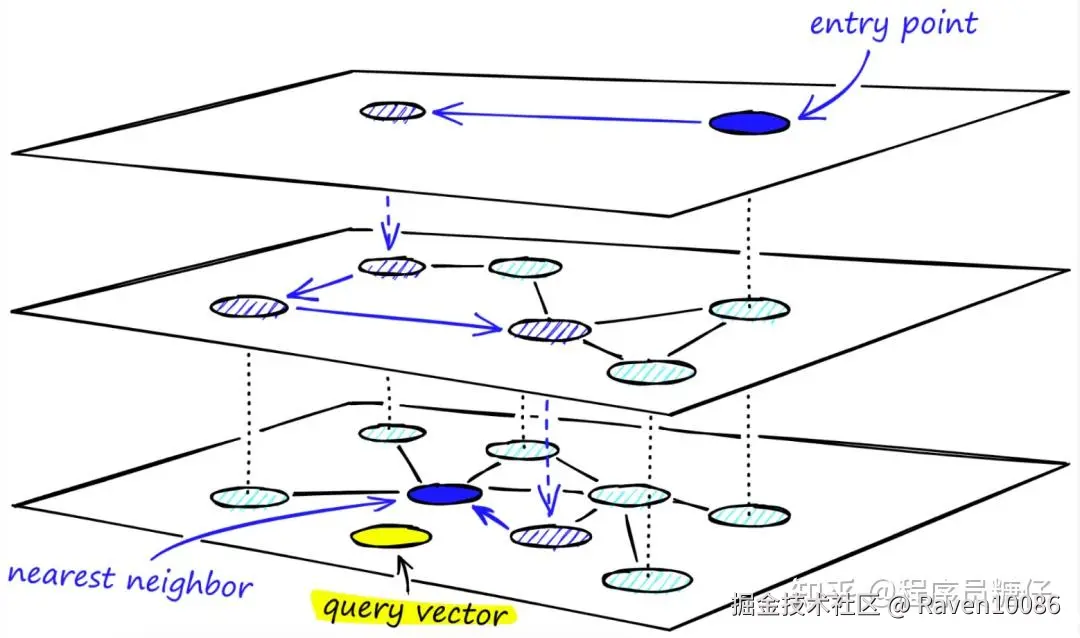
与传统关系型数据库(处理结构化数据)或键值数据库不同,向量数据库的核心能力是高效执行相似性搜索(Similarity Search),即通过比较向量之间的距离,快速找到与查询向量最相似的向量集合。这种能力在推荐系统、语义搜索、图像检索和检索增强生成(RAG)等场景中至关重要。