结论
- FLink KeyBy算子的KeySelector的构造是在JobManager/客户端构造的 ,而getKey获取key去进行分区,是在TaskManager的subTask中执行的,因此,这就涉及到一个数据传递的问题。
- Flink的并行度,也就是subTask其实底层就是一个个互相隔离的Task线程,不了解的可以先看Flink TM、subTask、JVM、算子链、slot、slot组的关系
- Session 模式下,多个任务共享集群资源,但 Flink 会通过类加载隔离(如 ChildFirstClassLoader)和任务执行上下文隔离,保证不同任务的用户代码(包括 JsonKeySelector2)相互独立
- 线程级隔离(subTask之间) :ThreadLocal每个线程生成独立的 Field 缓存副本。即使两个任务的 subtask 运行在同一个 TM 的不同线程中,它们的 usedFieldCache 也会各自持有 "属于当前线程" 的缓存,不会互相覆盖或干扰
- 任务级隔离(同一session,不同FlinkJob间) :Flink 也会通过以下机制保证隔离,即使两个任务的 subtask 运行在同一个 TM 的相同线程中(极端情况,比如资源超配时的线程复用)
- 类加载隔离:每个任务的用户代码(包括 JsonKeySelector)由独立的类加载器加载,避免类定义 / 静态变量串用;
- 执行上下文隔离:任务的状态、算子逻辑的初始化参数(如 jsonKeyFields)都是任务专属的,不同任务的 JsonKeySelector 实例在初始化时,会根据自身任务的配置加载字段,与其他任务无关。
- Field本身可以序列化,但是Field一旦关联上某个字段,并获取了这个字段的上下文信息后,是不可序列化和反序列化的,会报错
java.io.NotSerializableException: java.lang.reflect.Field,而transient修饰会让其不参与序列化 readObject()是 Java自定义反序列化机制 的核心方法,与其相对的是序列化机制writeObject(),他有具体被调用的规则如下- 当前类实现了
java.io.Serializable接口 - 方法必须被定义为
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException
- 当前类实现了
1.自定义JsonKeySelector
功能:通过传入一个keyFiedls数组,去实现分组操作
java
public class JsonKeySelector<IN> implements KeySelector<IN, Long>, Serializable {
private static final Logger LOGGER = LoggerFactory.getLogger(JsonKeySelector2.class);
private static final long serialVersionUID = 1L;
private static final char SPLIT_CHAR = '\001';
private static final char NULL_MARKER = '\002';
// 核心配置变量
private final List<String> jsonKeyFields; // 配置的JSON分组字段
private final boolean isAutoSalt; // 加盐开关
private final String autoSalt; // 盐值
private final Class<IN> bindPojoClass; // POJO类
/**
* 1.Field不可序列化和反序列化,因此需要用transient修饰
* 2.采用ThreadLocal是确保线程安全,Flink多并行度底层其实也是多线程,只不过用线程隔离机制隔开了
*/
private transient ThreadLocal<Map<String, Field>> usedFieldCache;
/**
* 构造函数,在JobManager/client中被调用
*/
public JsonKeySelector2(List<String> jsonKeyFields, boolean isAutoSalt, String pojoName) {
// 参数校验
if (jsonKeyFields == null || jsonKeyFields.isEmpty()) {
throw new IllegalArgumentException("JSON Key Fields name is null");
}
if (StringUtils.isEmpty(pojoName)) {
throw new IllegalArgumentException("POJO name is null");
}
// 加载POJO类
Class<IN> pojoClass;
try {
pojoClass = (Class<IN>) Class.forName(pojoName);
} catch (ClassNotFoundException e) {
throw new RuntimeException("POJO {} is not exists :" + pojoName, e);
}
// 初始化配置
this.jsonKeyFields = jsonKeyFields;
this.isAutoSalt = isAutoSalt;
this.autoSalt = isAutoSalt ? UUID.randomUUID().toString() : "";
this.bindPojoClass = pojoClass;
// 初始化Field缓存 -- 其实用的反射去获取jsonKeyFields的Fields进行缓存
initFieldCache();
LOGGER.info("Initialization completed, POJO: {}, KeyBy fields: {}", pojoClass.getSimpleName(), jsonKeyFields);
}
/**
* 优化核心:用映射表替代嵌套循环,时间复杂度从O(n*m)降为O(n+m)
*/
private void initFieldCache() {
this.usedFieldCache = ThreadLocal.withInitial(() -> {
// 1. 构建POJO字段的"JSON键→Field"映射表(只遍历一次POJO字段)
Map<String, Field> pojoJsonFieldMap = new HashMap<>();
Field[] allPojoFields = bindPojoClass.getDeclaredFields();
for (Field pojoField : allPojoFields) {
JsonProperty jsonProp = pojoField.getAnnotation(JsonProperty.class);
if (jsonProp != null) {
String jsonKey = jsonProp.value();
// 若有重复的@JsonProperty值,后面的会覆盖前面的(符合注解使用规范)
pojoJsonFieldMap.put(jsonKey, pojoField);
}
}
// 2. 遍历配置的JSON字段,从映射表中O(1)查找(无嵌套循环)
Map<String, Field> fieldCache = new HashMap<>(jsonKeyFields.size());
for (String targetJsonKey : jsonKeyFields) {
Field matchedField = pojoJsonFieldMap.get(targetJsonKey);
if (matchedField == null) {
throw new RuntimeException("No field in POJO is annotated with @JsonProperty(\"" + targetJsonKey + "\")");
}
// 开启私有字段访问权限
matchedField.setAccessible(true);
fieldCache.put(targetJsonKey, matchedField);
}
LOGGER.info("FieldCache initialization done, number of fields loaded: {}", fieldCache.size());
return fieldCache;
});
}
/**
* Flink TaskManager的subTask获取JobManager发来的信息,会进行反序列化,此时我们进行重建缓存
*/
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
// 保留默认反序列化逻辑
in.defaultReadObject();
// 对transient修饰的属性将进行重新初始化
initFieldCache();
}
@Override
public Long getKey(IN record) throws Exception {
Map<String, Field> fieldCache = usedFieldCache.get();
Hasher hasher = Hashing.murmur3_128().newHasher();
for (String jsonKey : jsonKeyFields) {
Field field = fieldCache.get(jsonKey);
Object value = field.get(record);
if (value == null) {
hasher.putChar(NULL_MARKER);
} else {
putValue(hasher, value);
}
hasher.putChar(SPLIT_CHAR);
}
if (isAutoSalt) {
hasher.putString(autoSalt, StandardCharsets.UTF_8);
}
Long key = hasher.hash().padToLong();
return key;
}
/** 按类型写哈希 */
private void putValue(Hasher hasher, Object value) {
if (value instanceof Long) hasher.putLong((Long) value);
else if (value instanceof Integer) hasher.putInt((Integer) value);
else if (value instanceof Boolean) hasher.putBoolean((Boolean) value);
else if(value instanceof Double) hasher.putDouble((Double) value);
else hasher.putString(value.toString(), StandardCharsets.UTF_8);
}2.现象
Flink的JobManager的log如下 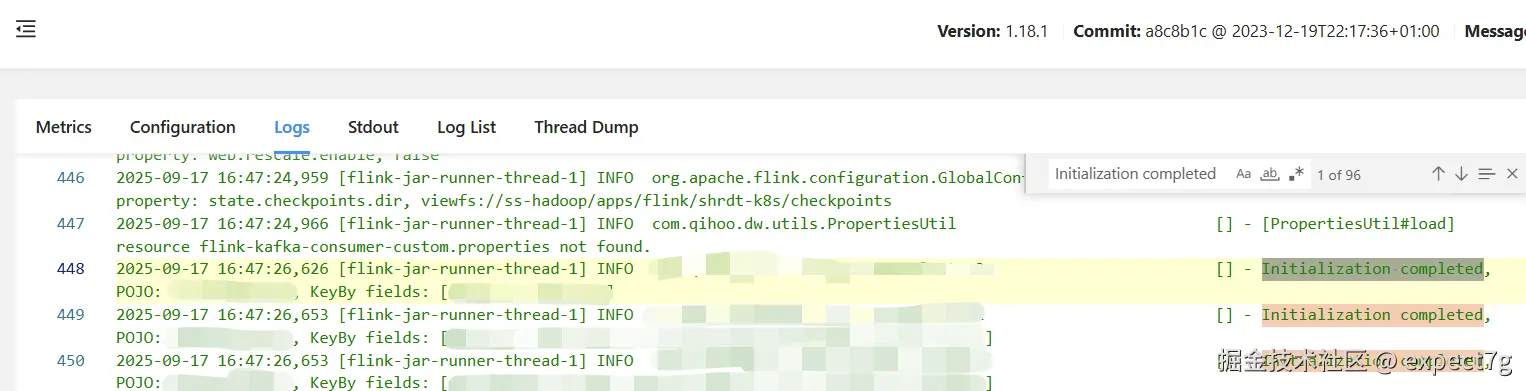 Flink的TaskManager的log如下
Flink的TaskManager的log如下 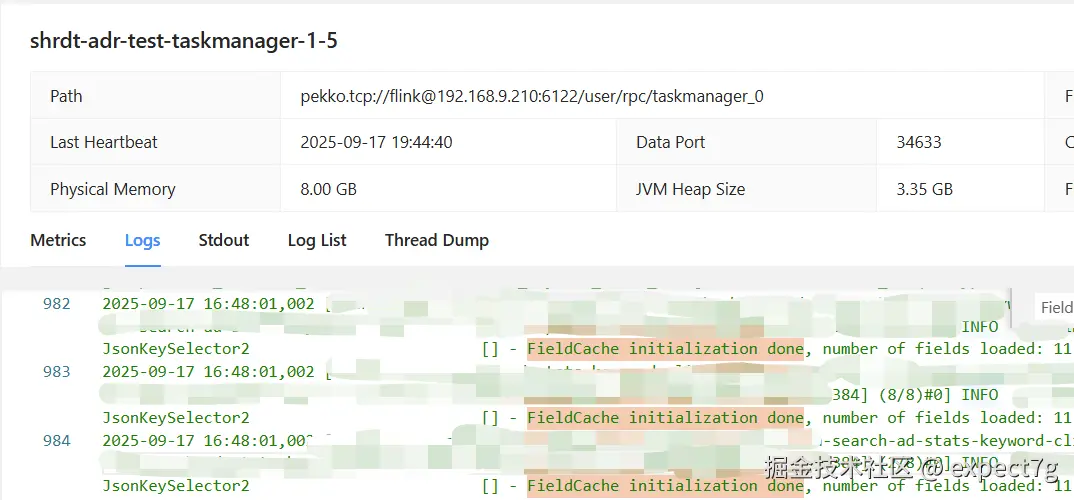 从日志打印,我们可以看出
从日志打印,我们可以看出
FieldCache initialization done, number of fields loaded: {}日志只在TaskManager中打印,它属于initFieldCache(),而构造函数和readObject()都有调用它,但构造函数会多打印Initialization completed, POJO: {}, KeyBy fields: {},但是TaskManager中并没有这个日志,说明他是readObject()进行反序列化的时候调用的,因此,反序列化和getKey的操作是由TaskManager的subTask执行的,且根据并行度会打印对应数量的日志Initialization completed, POJO: {}, KeyBy fields: {}这个日志在JobManager中打印,说明构造函数是在客户端中调用的,客户端执行后会生成JobGraph然后传给JobManager,日志也在JobManager中- 构造函数中也调用了
initFieldCache()但是为啥没打印FieldCache initialization done, number of fields loaded: {}呢?原因在于:ThreadLocal.withInitial()是懒加载,他只是先创建这么个实例,但是真正执行里面的Lambda表达式是在首次调用usedFieldCache.get()时才会执行 ,而构造函数中并没有调usedFieldCache.get()所以在JobManager的日志中根本没有FieldCache initialization done, number of fields loaded: {}这个日志