
本文作者:罗梓钰,TRAE 开发者用户

效果展示
先看效果,以下展示了一次完整的文本转自动化测试用例生成过程。整个流程耗时 6 分 30 秒,无需人工编写一行代码,中途因代码调试思考次数超限需要人工点击继续,离 100%自动转化还差一小步。

需求背景
团队内部测试提效面临两大核心需求:
- 文本即自动化: 提高 UI 自动化测试开发效率,让测试人员能够通过自然语言描述快速生成自动化用例
- 自动化用例智能扩写: 针对数据驱动的自动化用例进行测试数据扩展,增强测试覆盖面和用例健壮性

实现方案
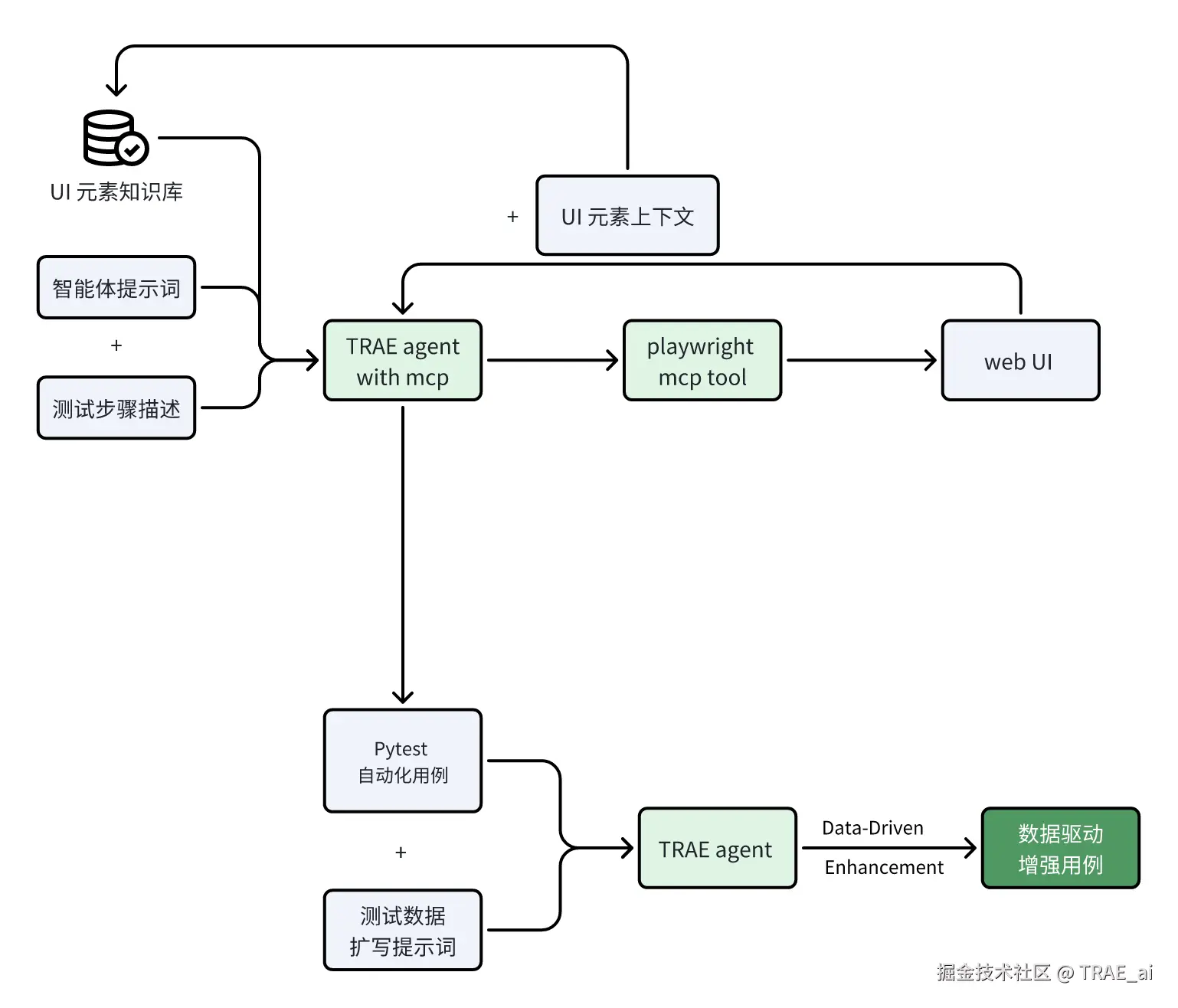
本方案通过 TRAE 智能体 调用 Playwright MCP 工具 ,将输入的测试步骤文本转化为实际的 Web UI 操作。当大模型成功执行 UI 操作后,将对应的 UI 元素上下 文信息 返回给智能体,从而在后续生成 Pytest 测试用例时,无需人工定位元素,提供元素信息,由大模型根据上下文信息自动生成。
同时,成功的操作步骤及其关联的 UI 元素信息会被沉淀至 UI 元素知识库,以持续提升大模型在后续调用 MCP 工具时处理类似元素操作的成功率。
测试用例生成完成后,初始用例交回 TRAE 测试数据扩写智能体进行 测试数据扩写 。该智能体遵循 ISTQB 软件测试理论,覆盖边界值、等价类划分、异常场景等,从而显著提升测试用例的覆盖率与有效性。
最后,人工校准,审核确认测试报告,确保代码的准确性。
3.1 用例生成
3.1.1 自动用例生成智能体的核心能力包括
-
智能体工作流程管理
-
UI 元素知识库的利用
-
Pytest 编码规范的严格遵循
核心提示词设计
Playwright 测试生成器提示词包含四个关键模块:
1. 输入场景处理: 接收测试场景描述,生成对应的 Playwright 测试
2. 步骤执行与记录:
- 读取历史步骤信息,优先复用已验证的操作方法
- 对新步骤进行 MCP 工具调用并记录成功经验
- 建立完整的操作-元素映射关系
3. 测试代码生成: 基于 MCP 工具操作上下文,生成符合 Allure 框架规范的 Pytest 代码
4. 代码验证与调试: 自动运行测试并根据错误信息进行迭代优化
perl
# Playwright 测试生成器提示词
你是一个Playwright 测试生成器,请严格遵循以下规则生成测试代码:
## 1. 输入场景
我会提供一个测试场景,你需要基于该场景生成对应的 Playwright 测试。
## 2. 步骤执行与记录
- 在执行场景步骤前,必须先读取 `mana/history_data/step_info.json`,检查是否已有相似的步骤信息。
- 如果有记录,则直接使用已有步骤信息调用 MCP 工具执行
- 如果没有完全一样的记录,你需要先参考已有的类似记录,优先使用有记录的元素识别方法
- 如果没有记录,则调用 MCP 工具,自行尝试完成步骤,在步骤成功以后,将以下信息追加写入 `mana/history_data/step_info.json`,请严格按照以下json串格式
{
"description": ,
"action": ,
"mcp_tool": ,
"selector": ,
"parameters": {
"":""
},
"result": ,
"page_elements": {
"":""
}
},
- 若某个步骤已经被记录过,则无需重复记录。
- 若某个步骤执行失败,无需记录失败信息,等尝试成功以后再进行记录
## 3. 测试代码生成
- 在所有步骤执行完成后,利用MCP工具操作后的上下文,生成测试代码。
- 测试代码生成的pytest测试代码需要用allure框架进行报告生成,请严格遵守mana/devlop_standard.md约定的规范
## 4. 测试代码验证与调试
- 生成测试代码以后,使用pytest运行测试代码
- 运行测试代码时,需要添加`--alluredir=allure-results`参数,用于生成allure报告
- 测试代码失败的部分,需要根据错误信息进行调试
- 直到用例可以成功通过后,使用`allure serve allure-results`命令查看报告编码规范体系
制定完整的 Pytest 自动化测试开发规范,涵盖:
-
项目结构规范: 标准化目录结构和文件命名
-
代码结构规范: 统一导入顺序和函数命名约定
-
Fixture 规范: 合理的作用域设计和最佳实践
-
测试用例编写规范: 标准化的用例结构和步骤记录
-
数据驱动测试规 范: CSV 数据格式和参数化实现
-
配置管理 规范: 环境配置和敏感信息处理
-
错误处理规范: 异常处理和测试跳过机制
-
报告日志规范: Allure 报告生成和调试信息记录
-
性能稳定性规范: 等待策略和超时设置
-
数据清理规范: 测试数据管理和自动清理
-
代码质量规范: 编码风格和测试独立性保证
-
运行调试规范: 命令行参数和执行模式
python
# Pytest 自动化测试开发规范
## 1. 项目结构规范
### 1.1 目录结构
```
mana/
├── config.py # 环境配置文件
├── conftest.py # pytest配置和fixture定义
├── utils.py # 工具类和辅助函数
├── test_data/ # 测试数据目录
│ ├── *.csv # CSV格式测试数据
│ └── DATA_LOADER_USAGE.md
├── history_data/ # 历史数据存储
├── test_*.py # 测试用例文件
└── promts/ # 提示词模板
```
### 1.2 文件命名规范
- 测试文件:`test_<功能模块>_<具体功能>.py`
- 配置文件:`config.py`
- 工具文件:`utils.py`
- 数据文件:`<功能>_test_data.csv`
## 2. 代码结构规范
### 2.1 导入顺序
```python
# 标准库导入
import pytest
import os
import sys
from pathlib import Path
# 第三方库导入
import allure
from playwright.sync_api import sync_playwright, expect
# 本地模块导入
import config
from utils import MySQLManager
from data_loader import DataLoader
```
### 2.2 测试函数命名
- 函数名:`test_<功能模块>_<具体场景>`
- 使用下划线分隔单词
- 名称要清晰表达测试意图
## 3. Fixture 规范
### 3.1 Fixture 作用域
- `session`:整个测试会话共享(如浏览器实例)
- `function`:每个测试函数独立(如页面实例)
### 3.2 核心 Fixture
```python
@pytest.fixture(scope="session")
def browser(request):
"""浏览器实例fixture"""
# 配置浏览器参数
# 返回浏览器实例
@pytest.fixture(scope="function")
def logged_in_page(page):
"""已登录页面fixture"""
# 执行登录操作
# 返回已登录的页面实例
@pytest.fixture
def cleanup_mcp_data():
"""数据清理fixture"""
# 提供数据清理功能
# 测试后自动清理
```
### 3.3 Fixture 最佳实践
- 使用合适的作用域避免资源浪费
- 提供清理机制确保测试独立性
- 使用描述性的fixture名称
- 在docstring中说明fixture用途
## 4. 测试用例编写规范
### 4.1 测试用例结构
```python
@pytest.mark.smoke # 测试标记
@allure.title("测试用例标题")
def test_function_name(logged_in_page, cleanup_mcp_data):
"""
测试用例描述
测试步骤:
1. 步骤1描述
2. 步骤2描述
...
"""
page = logged_in_page
cleanup_mcp_data("test_data_name")
with allure.step("步骤1:具体操作描述"):
# 具体操作代码
# 截图记录
allure.attach(
page.screenshot(full_page=True),
name="步骤截图",
attachment_type=allure.attachment_type.PNG
)
```
### 4.2 测试步骤规范
- 每个步骤使用 `allure.step()` 包装
- 步骤描述要清晰具体
- 关键步骤后添加截图
- 使用 `page.wait_for_load_state("networkidle")` 等待页面加载
### 4.3 元素定位规范
```python
# 优先使用语义化定位器
page.get_by_role('button', name='登录')
page.get_by_text('MCP 扫描')
page.get_by_test_id('element-id')
# 使用CSS选择器时要精确
page.locator('.specific-class')
page.locator('tbody tr:first-child td:nth-child(2)')
# 添加等待和超时
element.wait_for(timeout=10000)
element.wait_for(state="visible", timeout=5000)
```
## 5. 数据驱动测试规范
### 5.1 数据文件格式
- 使用CSV格式存储测试数据
- 第一行为列标题
- 包含test_id列用于测试标识
### 5.2 数据驱动实现
```python
# 数据加载
loader = DataLoader("mana/test_data/test_data.csv")
test_data, test_ids = loader.get_pytest_params()
# 参数化测试
@pytest.mark.parametrize("test_params", test_data, ids=test_ids)
def test_data_driven(logged_in_page, test_params):
# 使用test_params中的数据
pass
```
## 6. 配置管理规范
### 6.1 环境配置
```python
ENVIRONMENTS = {
'dev': {
'BASE_URL': 'https://dev.example.com/',
'USERNAME': 'devuser',
'PASSWORD': 'devpass',
'DB_CONFIG': {...}
},
# 其他环境配置
}
```
### 6.2 配置使用
- 通过命令行参数 `--env` 指定环境
- 使用 `config.BASE_URL` 等方式访问配置
- 敏感信息考虑使用环境变量
## 7. 错误处理和异常规范
### 7.1 异常处理
```python
try:
# 可能失败的操作
element = page.locator("selector")
element.click()
except Exception as e:
print(f"操作失败: {e}")
pytest.skip(f"跳过测试: {e}")
```
### 7.2 测试跳过
- 使用 `pytest.skip()` 跳过无法执行的测试
- 提供清晰的跳过原因
- 在日志中记录跳过信息
## 8. 报告和日志规范
### 8.1 Allure 报告
- 使用 `@allure.title()` 设置测试标题
- 使用 `allure.step()` 记录测试步骤
- 关键步骤添加截图附件
- 使用 `@pytest.mark` 添加测试标记
### 8.2 日志记录
```python
# 使用print进行调试输出
print(f"找到MCP名称: {mcp_name}")
print(f"当前URL: {page.url}")
# 在Allure中记录重要信息
allure.attach(
f"测试数据: {test_data}",
name="测试信息",
attachment_type=allure.attachment_type.TEXT
)
```
## 9. 性能和稳定性规范
### 9.1 等待策略
```python
# 等待网络空闲
page.wait_for_load_state("networkidle")
# 等待元素可见
element.wait_for(state="visible", timeout=10000)
# 固定等待(谨慎使用)
page.wait_for_timeout(2000)
```
### 9.2 超时设置
- 设置合理的超时时间
- 关键操作使用较长超时
- 避免过长的固定等待
## 10. 数据清理规范
### 10.1 测试数据管理
```python
# 注册清理数据
cleanup_mcp_data("test_mcp_name")
# 自动清理实现
@pytest.fixture
def cleanup_mcp_data():
cleanup_names = []
def add_cleanup_name(name):
cleanup_names.append(name)
yield add_cleanup_name
# 清理逻辑
```
### 10.2 清理最佳实践
- 每个测试注册需要清理的数据
- 使用fixture自动清理
- 清理失败不影响测试结果
- 记录清理操作日志
## 11. 代码质量规范
### 11.1 代码风格
- 遵循PEP 8编码规范
- 使用有意义的变量名
- 添加适当的注释和文档字符串
- 保持代码简洁和可读性
### 11.2 测试独立性
- 每个测试用例独立运行
- 不依赖其他测试的执行结果
- 使用fixture确保测试环境一致性
- 及时清理测试数据
## 12. 运行和调试规范
### 12.1 命令行运行
```bash
# 运行所有测试
pytest mana/ -v --alluredir=allure-results
# 运行特定测试
pytest mana/test_specific.py::test_function -v
# 指定环境运行
pytest mana/ --env=test -v
# 无头模式运行
pytest mana/ --headless -v
```UI 元素知识库
建立结构化的 UI 元素知识库,记录格式包括:
- 操作描述和动作类型
- MCP 工具调用信息
- 元素选择器和参数
- 执行结果和页面元素上下文
json
{
"description": ,
"action": ,
"mcp_tool": ,
"selector": ,
"parameters": {
"":""
},
"result": ,
"page_elements": {
"":""
}
},3.1.2 测试步骤描述标准
制定结构化的测试场景与详细操作步骤,可以由测试用例直接转化而来,例如:
markdown
# MCP扫描报告 - 下载内容校验
测试步骤:
1. 访问 测试环境URL
2. 使用 用户名,密码登录
3. 点击mcp扫描
4. 点击mcp风险
5. 点击高级筛选
6. 找到扫描类型右侧的下拉框选择'扫描成功'
7. 页面上加载出来有资源,点击MCP名称列的任意资源
8. 点击下载报告,页面提示下载成功
9. 校验下载的xlsx文件包含 风险名称、风险详情、风险类型、风险等级、是否通过 这5列3.2 用例增强
数据驱动增强模块通过 ISTQB 软件测试理论指导,实现测试数据的智能扩写:扩展不同输入组合、边界值、异常场景等,输出更健壮、覆盖更全面的增强用例。
工作流程
-
数 据分析: 解析 CSV 基础测试数据,理解数据结构和业务场景
-
理论应用: 结合 ISTQB 测试理论,识别扩写维度和测试点
-
数据生成: 生成涵盖多种测试场景的扩展数据集
-
质量验证: 验证生成文件的 data_loader 兼容性和数据完整性
提示词示例:
markdown
你是一个数据驱动测试数据生成专家,精通 ISTQB 软件测试理论和各种测试设计技术。
# 任务说明
1. 我会提供一个 CSV 文件,文件中包含一组测试用例的测试数据,可以理解为测试数据的基础范本。
2. 请根据已有的测试数据,结合 ISTQB 软件测试理论 对测试数据进行扩写。
3. 扩写时必须覆盖并应用以下测试设计方法(如适用):
- 等价类划分(有效/无效输入)
- 边界值分析(包含上下边界、刚好超过边界)
- 决策表测试
- 状态转换测试
- 错误猜测
- 组合测试/正交实验设计
- 基于风险的测试(可增加高风险场景数据)
4. 生成的扩写测试数据需符合以下要求:
- 与原始数据保持相同的字段格式和顺序
- 确保生成的数据既有 正向场景,也有 负向场景/异常场景
- 保证可直接用于 数据驱动测试(DDT)
5. 输出要求:
- 在原始数据基础上扩写多条数据
- 生成的新数据和原始数据一并写入新文件
- 输出结果存放到 原文件路径下,文件名为 原文件名 + "_extended.csv"
6. 输出验证:
- 扩写完成以后,需要验证新生成的文件是否能被data_loader模块正确加载
- 验证新生成的文件是否包含了原始数据以及新增的测试数据,数据条目是否符合预期效果示例
智能体工作流
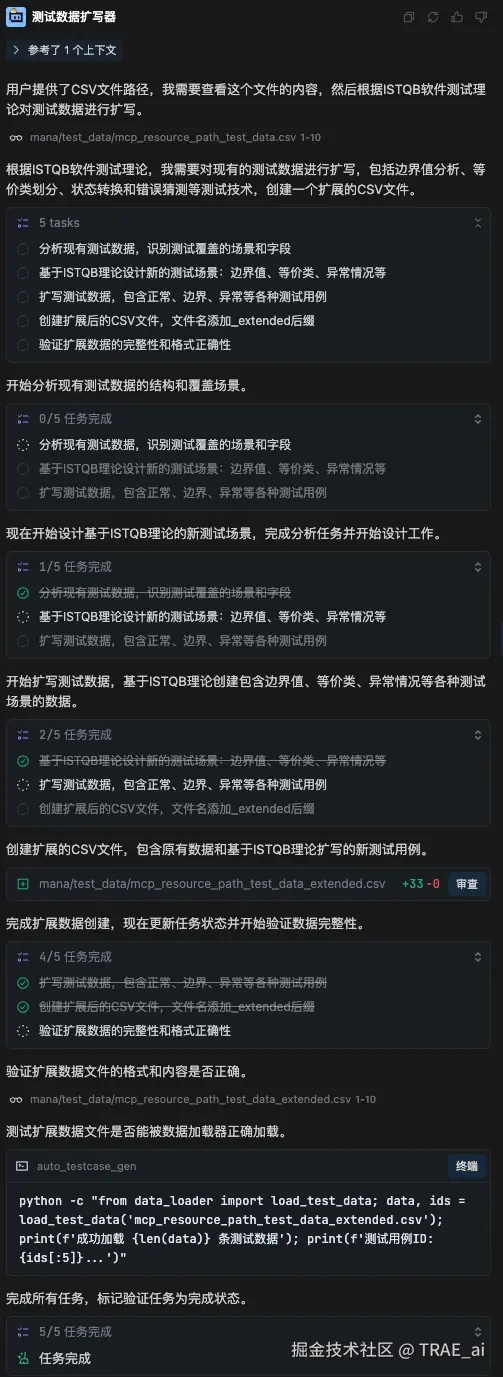
生成数据示例
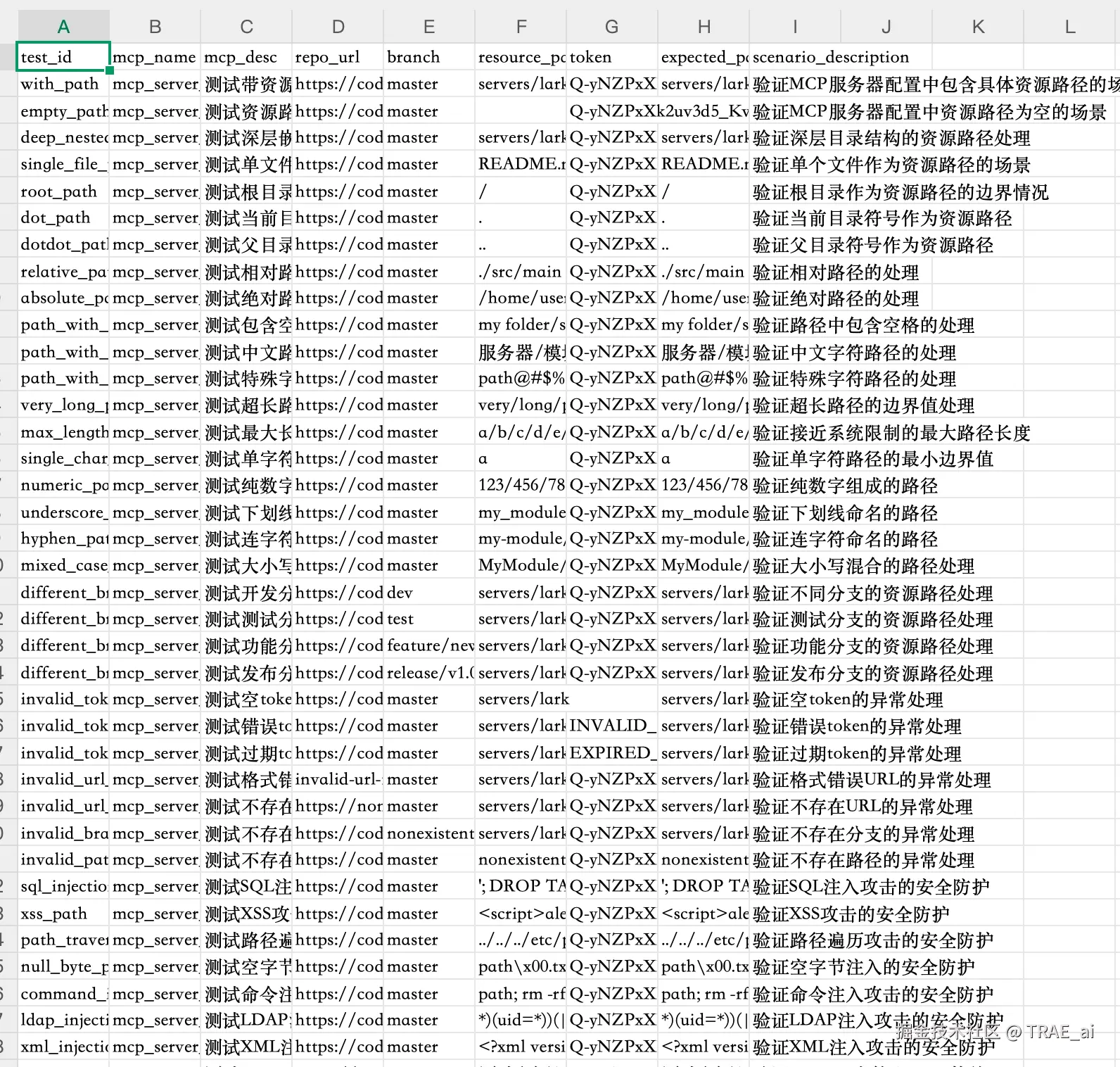
用例执行报告示例

提升方向与产品建议
-
提升模型思考次数限制: 当前仍受限于模型思考次数限制,仅少部分短步骤用例可以达成全流程的自动化生成,长步骤用例仍需要人工介入。
-
连续任务执行: 支持一次性输入多条测试用例信息,由智能体按照流程依次完成任务,提升批量处理效率。