Hadoop 1.x 与 2.x 版本对比:架构演进与核心差异解析
Hadoop 从 1.x 到 2.x 的演进是一次架构级别的重大升级,核心目标是解决 1.x 版本的性能瓶颈和单点问题。本文将详细对比两个版本的组成结构、核心缺陷与改进,重点解析 2.x 引入的 YARN 架构如何重塑 Hadoop 的资源管理与任务调度能力。
hadoop1.x版本:基础架构与核心缺陷
Hadoop 1.x 是 Hadoop 的早期版本,奠定了分布式存储与计算的基础,但架构设计存在明显局限性。
1.x 核心组成
Hadoop 1.x 由三个核心模块构成,形成 "存储 - 计算 - 工具" 的基础架构:
- Common:提供 Hadoop 各组件通用的工具类(如 I/O 操作、配置管理、安全机制等),是其他模块的基础依赖。
- HDFS(Hadoop Distributed File System):分布式文件系统,负责海量数据的存储,核心组件为 NameNode(主节点)和 DataNode(从节点)。
- MapReduce:集 "计算框架" 与 "资源调度" 于一体的模块,负责分布式任务的拆分、并行执行和结果聚合。
1.x 架构缺陷:为何需要升级?
Hadoop 1.x 的 MapReduce 架构存在三大核心问题,严重限制了集群的扩展性和性能:
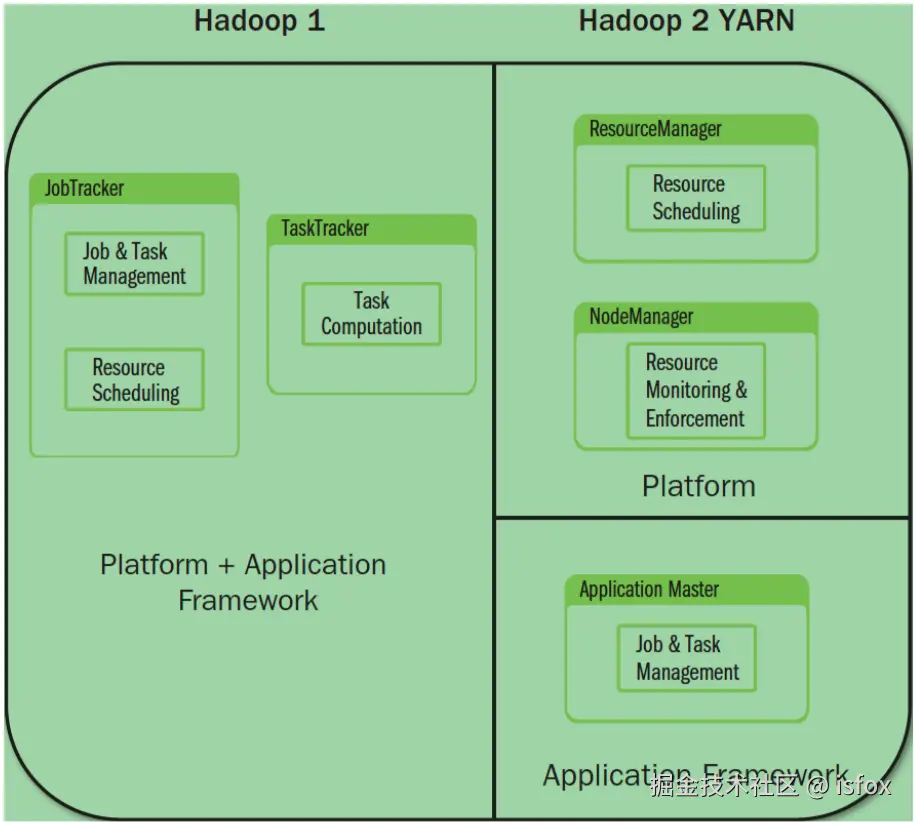
1. JobTracker 成为系统瓶颈
在 1.x 中,JobTracker 同时承担两大核心职责:
- 资源管理:负责集群中 CPU、内存等资源的分配与监控;
- 作业控制:负责 MapReduce 任务的拆分(Map/Reduce 阶段)、任务调度、进度跟踪和容错。
这种 "一身二任" 的设计导致 JobTracker 成为集群的性能瓶颈,尤其在大规模集群(数千节点)中,JobTracker 的内存和 CPU 压力极大,难以支撑高并发任务。
2. 单点故障风险
Hadoop 1.x 采用严格的 Master-Slave 结构 ,其中 JobTracker 是唯一的 Master 节点,不存在备份机制。一旦 JobTracker 宕机,整个集群的任务调度和资源管理将完全中断,导致所有运行中任务失败,且无法提交新任务,可用性极低。
3. 资源分配模型僵化
1.x 采用基于 "槽位(Slot)" 的资源分配模型:
- 集群资源被划分为固定数量的 Map Slot (供 Map 任务使用)和 Reduce Slot(供 Reduce 任务使用);
- 两种槽位独立隔离,不允许跨类型共享资源。
这种设计导致资源利用率低下:例如,当集群中 Map 任务已完成但 Reduce 任务未开始时,Map Slot 会大量闲置,而 Reduce Slot 可能因资源不足导致任务排队,造成资源浪费。
Hadoop 2.x 版本:架构升级与核心改进
为解决 1.x 的缺陷,Hadoop 2.x 引入了全新的 YARN(Yet Another Resource Negotiator) 架构,实现了 "资源管理" 与 "任务调度" 的解耦,彻底重塑了 Hadoop 的扩展性和灵活性。
2.x 核心组成
Hadoop 2.x 在 1.x 基础上拆分出独立的资源调度模块,形成四大核心组件:
- Common:与 1.x 功能一致,提供通用工具支持。
- HDFS:在 1.x 基础上优化(如支持 HDFS 联邦、HA 高可用),存储功能不变。
- YARN:全新的资源管理框架,替代 1.x 中 MapReduce 的资源调度功能。
- MapReduce:仅保留计算框架功能,任务调度依赖 YARN 完成。
2.x 核心改进:YARN 架构的突破
YARN 的核心设计是将 1.x 中 JobTracker 的职责拆分为两个独立服务,解决了 1.x 的根本性问题:
1. 职责拆分:资源管理与任务调度分离
- ResourceManager(全局资源管理器): 作为 YARN 的 "Master 节点",负责整个集群的资源(CPU、内存、磁盘等)统一管理和分配,接收所有应用程序的资源申请并调度。
- ApplicationMaster(应用程序管理器): 每个应用程序(如一个 MapReduce 任务)会启动一个专属的 ApplicationMaster,负责该应用的任务拆分、任务调度、进度监控和容错处理。
这种拆分彻底解决了 1.x 中 JobTracker 的 "一身二任" 瓶颈,ResourceManager 专注于资源分配,ApplicationMaster 专注于单任务管理。
2. 解决单点问题
- YARN 的 ResourceManager 支持 HA 高可用配置(通过 ZooKeeper 实现主备切换),避免了 1.x 中 JobTracker 的单点故障风险;
- HDFS 在 2.x 中也引入了 NameNode HA 机制,通过 Active/Standby 两个 NameNode 实现元数据高可用。
3. 灵活的资源分配模型
YARN 摒弃了 1.x 中僵化的 "槽位模型",采用基于 容器(Container) 的动态资源分配机制:
- 资源以 "容器" 为单位分配,每个容器可灵活配置 CPU 核数、内存大小等资源,不再区分 Map/Reduce 类型;
- 应用程序可根据需求动态申请和释放容器资源,资源利用率大幅提升;
- 支持多种计算框架共享集群资源(如 MapReduce、Spark、Flink 等均可运行在 YARN 上),实现 "一集群多框架" 的统一资源管理。
YARN 核心工作流程
以 MapReduce 任务在 YARN 上的执行为例,核心流程如下:
- 客户端提交应用程序到 YARN 的 ResourceManager;
- ResourceManager 为应用程序分配第一个容器,并启动 ApplicationMaster;
- ApplicationMaster 向 ResourceManager 申请后续任务所需的容器资源;
- ResourceManager 分配容器后,ApplicationMaster 在容器中启动 Map/Reduce 任务;
- 任务执行过程中,ApplicationMaster 监控任务状态,处理失败重试;
- 所有任务完成后,ApplicationMaster 向 ResourceManager 注销并释放资源。
1.x 与 2.x 核心差异对比表
| 对比维度 | Hadoop 1.x | Hadoop 2.x |
|---|---|---|
| 核心组成 | Common + HDFS + MapReduce | Common + HDFS + YARN + MapReduce |
| 资源管理 | 由 MapReduce 的 JobTracker 负责 | 由 YARN 的 ResourceManager 负责 |
| 任务管理 | JobTracker 统一管理所有任务 | 每个应用由专属 ApplicationMaster 管理 |
| 资源分配模型 | 基于 Map/Reduce 槽位的静态分配 | 基于容器(Container)的动态资源分配 |
| 单点问题 | JobTracker 和 NameNode 均存在单点故障 | 支持 ResourceManager 和 NameNode HA 高可用 |
| 扩展性 | 集群规模受限(通常 ≤4000 节点) | 支持大规模集群(万级节点) |
| 多框架支持 | 仅支持 MapReduce | 支持 MapReduce、Spark、Flink 等多框架共享资源 |
| 典型版本 | 1.0.x、1.2.x | 2.4.x、2.7.x、2.10.x |
参考文献