TL;DR
- 场景:以电商销售事实表为例,在 Kylin 上按"日期"维度预计算加速聚合查询。
- 结论:合理裁剪 Cuboid、优化维度/事实表可在存储与性能间取得平衡;构建与查询链路跑通。
- 产出:项目/数据源/模型/Cube 全流程指引、监控与常见错误定位表、实操 SQL 示例。

版本矩阵
| 模块 | 技术要点 | 工程化建议 |
|---|---|---|
| 数据源准备 | Hive表结构设计,分区字段选择 | 维度表主键唯一,单表≤300MB;事实表字段精简,避免使用Hive视图 |
| 维度建模 | 星型/雪花模型选择,维度层级定义 | 维度表快照复用,时间维度单独拆分;事实表外键映射避免复杂JOIN |
| Cube设计 | 维度/度量配置,Aggregation Group划分 | 高频维度置于独立Group,低基数维度优先剪枝 |
| 预计算优化 | Cuboid剪枝策略(Mandatory/层级/联合维度) | 使用衍生维度减少Cuboid数量,Spark构建替代MapReduce |
| 存储与压缩 | HBase列族设计,Snappy/LZO压缩算法选择 | 冷热数据分离存储,RowKey设计避免Region热点 |
| 增量构建 | 自动合并策略,分段构建时间范围控制 | 按小时/天分区,保留最小必要历史分段 |
| 实时OLAP(Kylin 4.0) | Kafka流接入,微批处理窗口配置 | 消息分区对齐维度表,启用Exactly-Once语义 |
| 监控与调优 | Cube构建耗时指标,查询命中率分析 | 使用Grafana监控Cuboid利用率,优化超过50ms的查询 |
SQL示例代码块
sql
-- 维度表优化示例
CREATE TABLE dim_product (
product_id STRING PRIMARY KEY,
category_path STRING COMMENT '层级维度',
price_bucket INT COMMENT '衍生维度'
) STORED AS ORC;
-- 事实表优化示例
CREATE TABLE fact_sales (
order_id STRING,
product_id STRING COMMENT '外键映射',
dt DATE PARTITIONED,
amount DECIMAL(18,2)
) PARTITIONED BY (dt) STORED AS PARQUET;公式与参数
关键参数计算公式:
-
Cuboid数量估算
N=∏i=1n(Li+1)( Li为第i个Aggregation Group的维度层级数)
-
存储优化阈值
Soptimal=RcompTbase×Cratio( Tbase为基准表大小, Cratio为压缩比, Rcomp为副本数)

Cube 介绍
Apache Kylin 是一个开源的分布式分析引擎,专注于提供大数据的实时OLAP(在线分析处理)能力。它最初由 eBay 开发并贡献给 Apache 软件基金会,现已成为 Hadoop 生态系统中重要的OLAP解决方案。Kylin 能够与多种大数据组件集成,包括 HBase、Spark、Kafka 等,特别适合处理 PB 级别的海量数据。
Cube(立方体)是 Apache Kylin 的核心概念之一,通过预计算大规模数据的多维数据集合,加速复杂的 SQL 查询。Cube 的设计借鉴了数据仓库中的星型模型和雪花模型,但采用了独特的预计算机制。具体来说,Cube 会预先计算并存储所有可能的维度组合(称为 Cuboid),这样在执行查询时就能直接使用预计算结果,而不需要实时扫描原始数据。
下面详细介绍 Cube 的关键点:
-
多维建模:Cube 基于事实表和维度表构建,支持星型模型和雪花模型。例如,在电商分析场景中,事实表可以是销售记录,维度表包括时间、商品、地区等维度。
-
预计算机制:Kylin 会在构建 Cube 时预先计算各种维度的组合(Cuboid)。比如一个包含5个维度的Cube,理论上会计算2^5=32个Cuboid,包括所有维度的组合情况。
-
存储优化:Kylin 使用 HBase 作为存储引擎,将预计算结果以列式存储,并采用高效的编码和压缩技术。例如,可以选择使用 Snappy 或 LZO 压缩算法来减少存储空间。
-
增量构建:支持增量构建 Cube,只处理新增数据而不用重建整个 Cube。这在处理每日新增数据的场景中特别有用,比如每日销售报表分析。
-
智能剪枝:通过 Aggregation Group 等技术优化,可以只计算部分重要的 Cuboid,在查询性能和存储成本之间取得平衡。例如,可以设置某些维度组合为必须计算的,而其他组合则按需计算。
Cube 的基本概念
Kylin 中的 Cube 是通过对一组事实表(通常是业务数据表)进行多维建模后,生成的预计算数据结构。Cube 涉及对多维数据的度量和维度的组合,从而可以在查询时通过检索预先计算的结果来显著减少计算开销。
- 维度(Dimension):数据中用于分组、筛选和切片的数据字段,例如时间、地区、产品等。
- 度量(Measure):通常是需要进行聚合计算的数据字段,例如销售额、订单数等。
- Cuboid:每个 Cube 由多个 Cuboid 构成,Cuboid 是一个特定维度组合的子集。Cube 中每种维度组合都会生成一个 Cuboid,每个 Cuboid 存储了该组合下的预聚合结果。
Cube 的创建过程
- 数据建模:首先在 Kylin 中创建一个数据模型(Data Model),这个模型定义了事实表和维度表之间的关系,类似于星型或雪花型模式。模型中也定义了需要聚合的度量字段。
- Cube 设计:基于数据模型设计 Cube,指定 Cube 的维度和度量。Kylin 会根据定义自动计算所有可能的维度组合(Cuboid)。
- 构建 Cube:构建过程会读取底层数据源(如 Hive、HBase、Kafka),然后根据指定的维度和度量生成每个 Cuboid 的预计算数据。这些预计算结果存储在 HBase 或其他存储引擎中。
Cube 的查询与优化
- 查询加速:当有 SQL 查询请求到达时,Kylin 会根据查询所涉及的维度组合,选择合适的 Cuboid 返回结果,避免了实时计算,极大地提高了查询性能。
- Cube 优化:为了控制 Cube 大小和加速构建,Kylin 支持裁剪 Cube,通过配置仅生成部分 Cuboid,这称为"Aggregation Group",可以减少冗余计算。
实时 OLAP
Kylin 4.0 引入了对实时 OLAP 的支持,使用 Kafka 作为实时数据流输入,构建实时 Cube。通过使用 Lambda 架构,Kylin 可以支持实时和批处理数据的整合分析。
Cube 的典型应用场景
大规模数据分析
Cube 特别适合处理 PB 级以上的超大规模数据集。通过其独特的预计算机制,能够将复杂的聚合查询性能提升数百倍。例如:
- 电商平台可以分析数亿条用户行为记录
- 金融行业可以处理海量的交易数据
- 电信运营商可以分析TB级的通话记录
实时分析
实时 Cube 解决方案支持流式数据的即时分析:
- 采用 Lambda 架构,同时处理批数据和流数据
- 支持 Kafka 等消息队列的实时接入
- 典型应用包括:
- 实时监控系统
- 即时营销效果分析
- 欺诈交易实时检测
商业智能(BI)工具集成
Kylin 提供了完善的 BI 工具集成能力:
- 支持标准 JDBC/ODBC 接口
- 与主流 BI 工具深度整合:
- Tableau:支持拖拽式多维分析
- Power BI:无缝对接可视化功能
- Superset:开源的BI集成方案
- 保留完整的 SQL 语法支持,包括:
- 复杂的多表连接
- 嵌套子查询
- 窗口函数等高级分析功能
维度表优化
- 要具有数据一致性,主键值必须是唯一的(否则Kylin构建过程会报错)
- 维度表越小越好,因为Kylin会将维度表加载到内存中供查询使用,过大的表不适合作为维度表,默认的阈值是300MB
- 改变频率低,Kylin会在每次构建中试图重用维度表的快照(Snapshot),如果维度表经常改变的话,重用就会失效,这就会导致要经常对维度表创建快照
- 维度表最好不要是Hive视图(View),因为每次都需要将视图进行物化,从而导致额外的时间开销
事实表优化
- 移除不参与Cube构建的字段,可以提升构建的速度,降低Cube构建结果的大小
- 尽可能将事实表进行维度拆分,提取公用的维度
- 保证维度与事实表的映射关系,过滤无法映射的记录
创建Cube(按日期)
核心步骤
DataSource => Model => Cube
- Model:描述了一个星型模式的数据结构,定义事实表(FactTable)和维度表(LookUpTable),以及它们之间的关系
- 基于一个Model可以创建多个Cube,可以减少重复工作
Cube设计
- 维度:日期
- 度量:订单商品销售量、销售总金额
sql
select date1, sum(price), sum(amount)
from dw_sales
group by date1;结构图如下: 
执行步骤
- 创建项目Project(非必须)
- 创建数据源(DataSource),指定有哪些数据需要进行数据分析
- 创建模型(Model),指定具体要对哪个事实表、维度表进行数据分析
- 创建立方体(Cube),指定对哪个数据模型执行预处理,生成不同维度的数据
- 执行构建 等待构建完成
- 再执行SQL查询,获取结果,从Cube中查询结果。
操作步骤
创建项目(Project)
左上角有一个 Add Project  我们点击之后弹窗,随便填写信息,创建
我们点击之后弹窗,随便填写信息,创建 
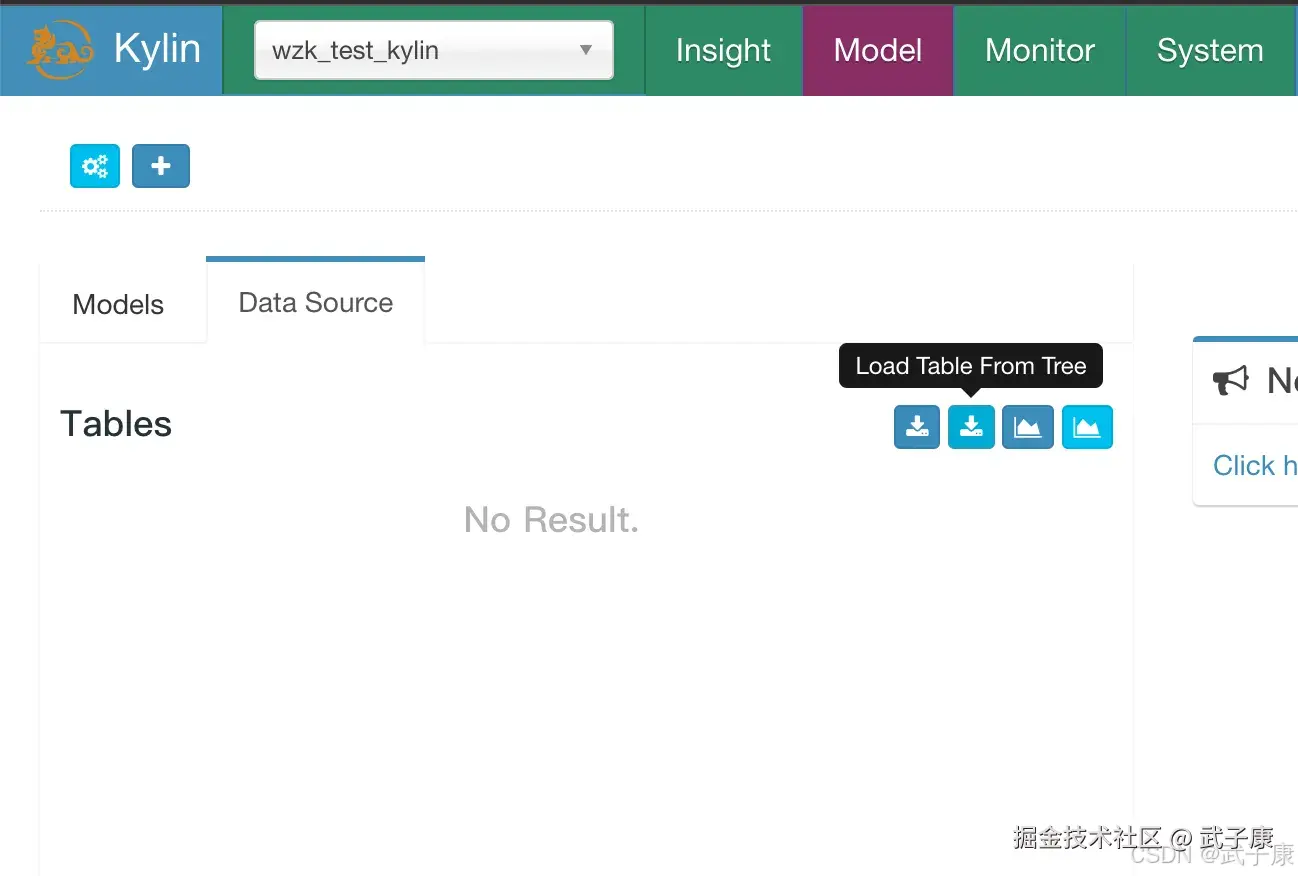
创建数据源(DataSource)
此时页面来到这里:
- 选择:DataSource面板
- 点击蓝色的小按钮:Load Table From Tree
 点击左侧的数据库:wzk_kylin,选择之后,展开了树:
点击左侧的数据库:wzk_kylin,选择之后,展开了树:
- wzk_kylin.dim_channel 点击
- wzk_kylin.dim_product 点击
- wzk_kylin.dim_region 点击
- wzk_kylin.dim_sales 点击
可以看到选中的都成蓝色了,记着点击 SYNC 按钮。 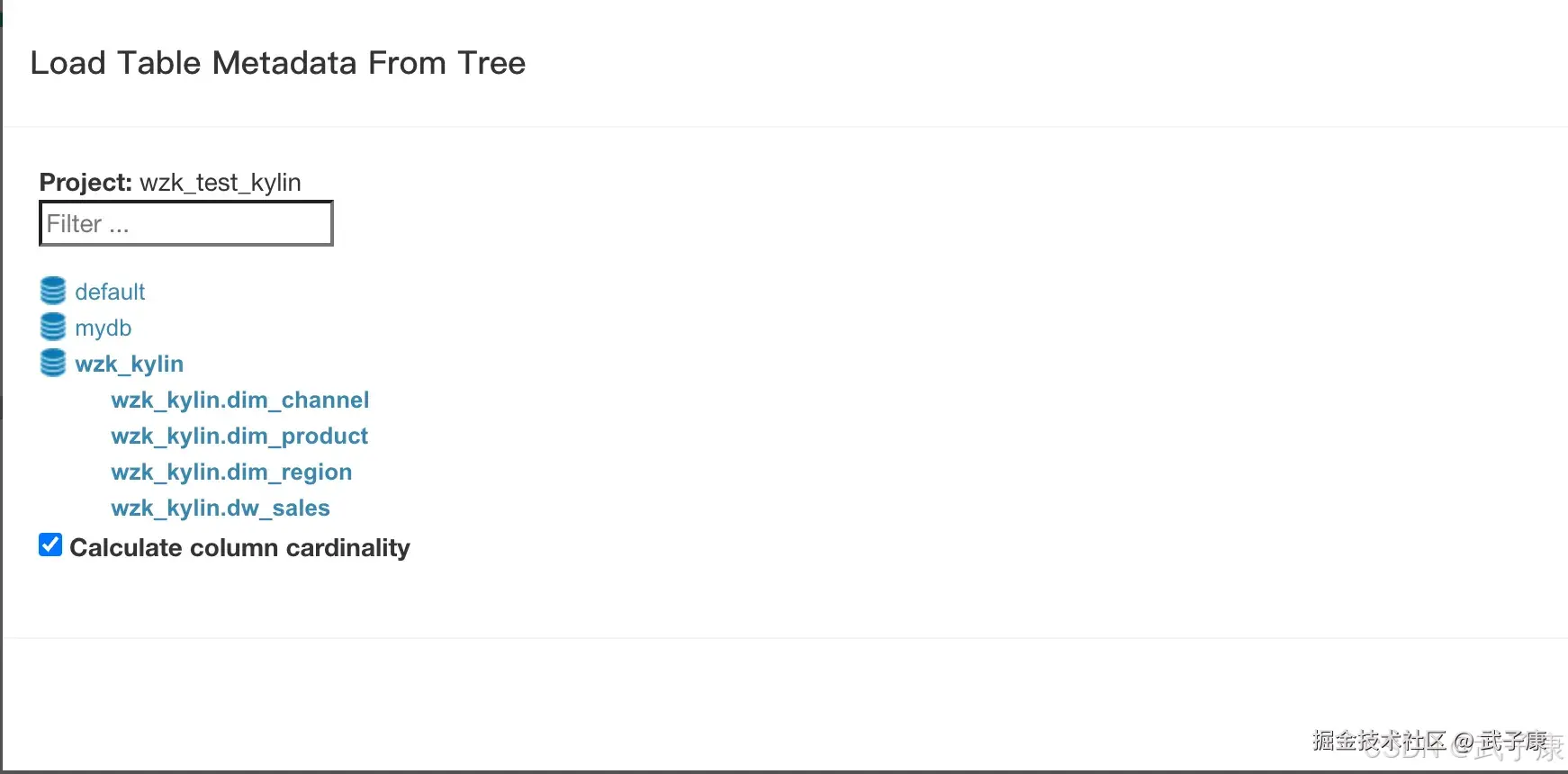
创建模型(Model)
切换到 Models 面板,点击New按钮,选择 New Model: 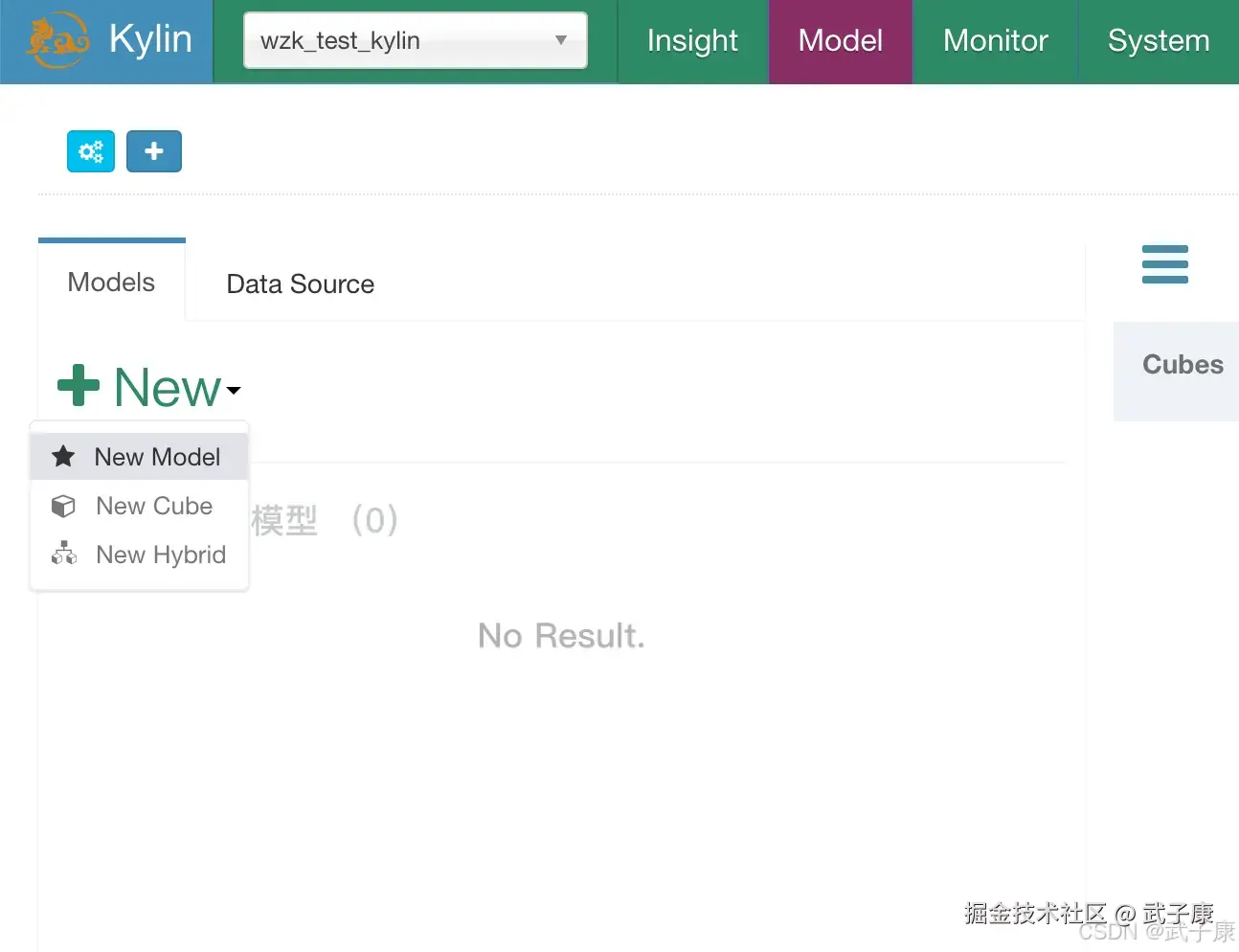 指定模型名称:
指定模型名称: 
选择事实表,选择 WZK_KYLIN.DW_SALES: 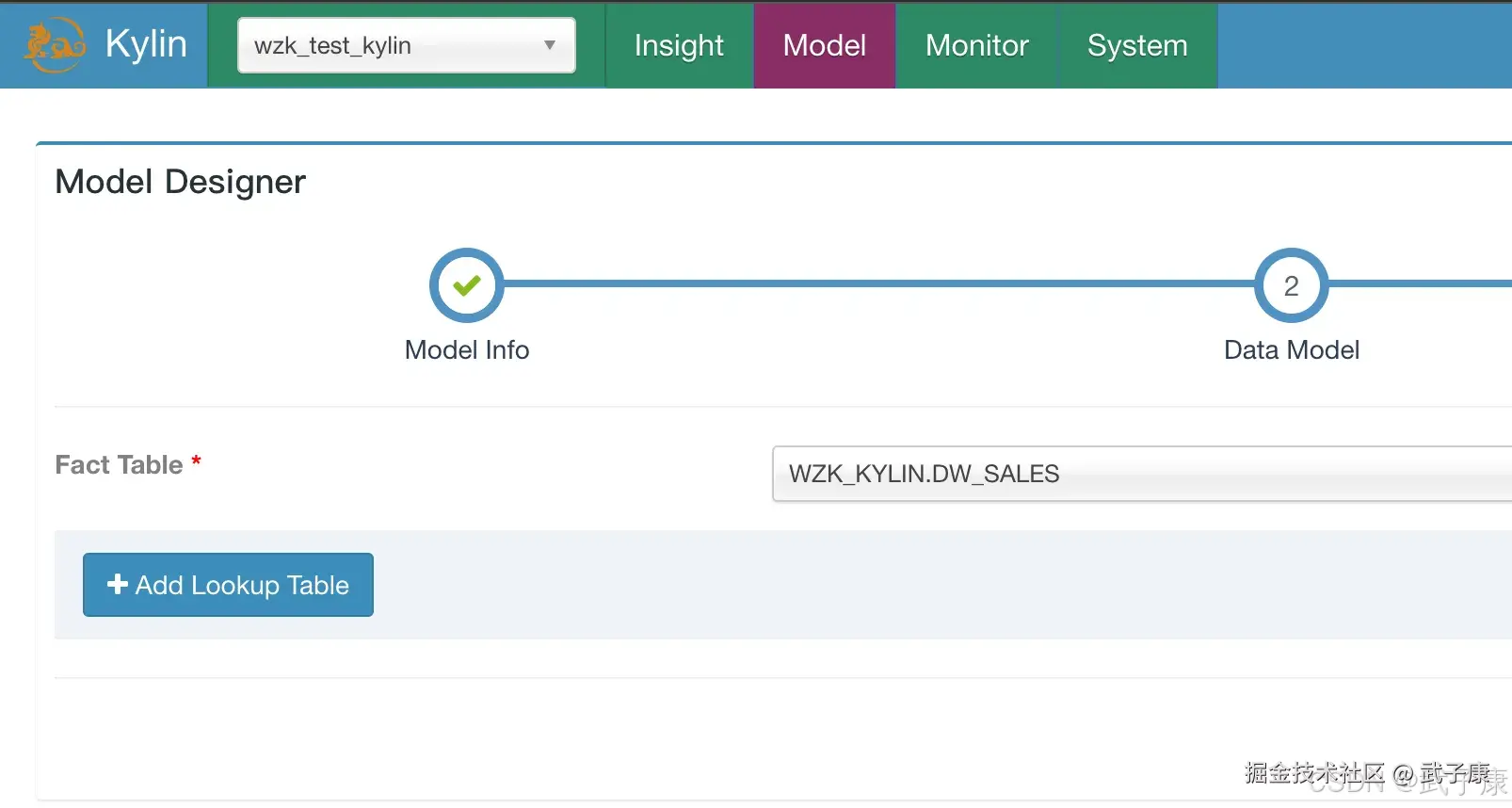 选择维度,Columns这里段 DATE1:
选择维度,Columns这里段 DATE1: 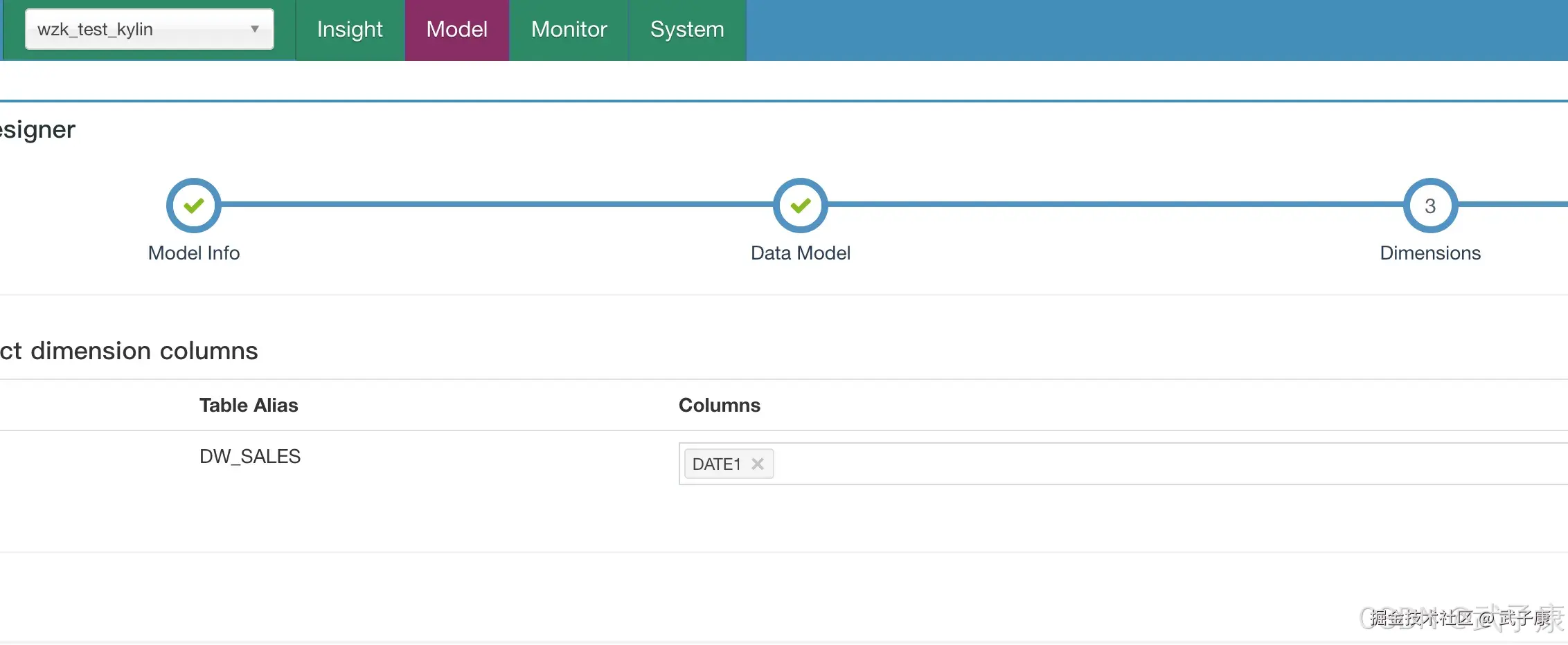 选择度量,Columns选择 AMOUNT和PRICE:
选择度量,Columns选择 AMOUNT和PRICE: 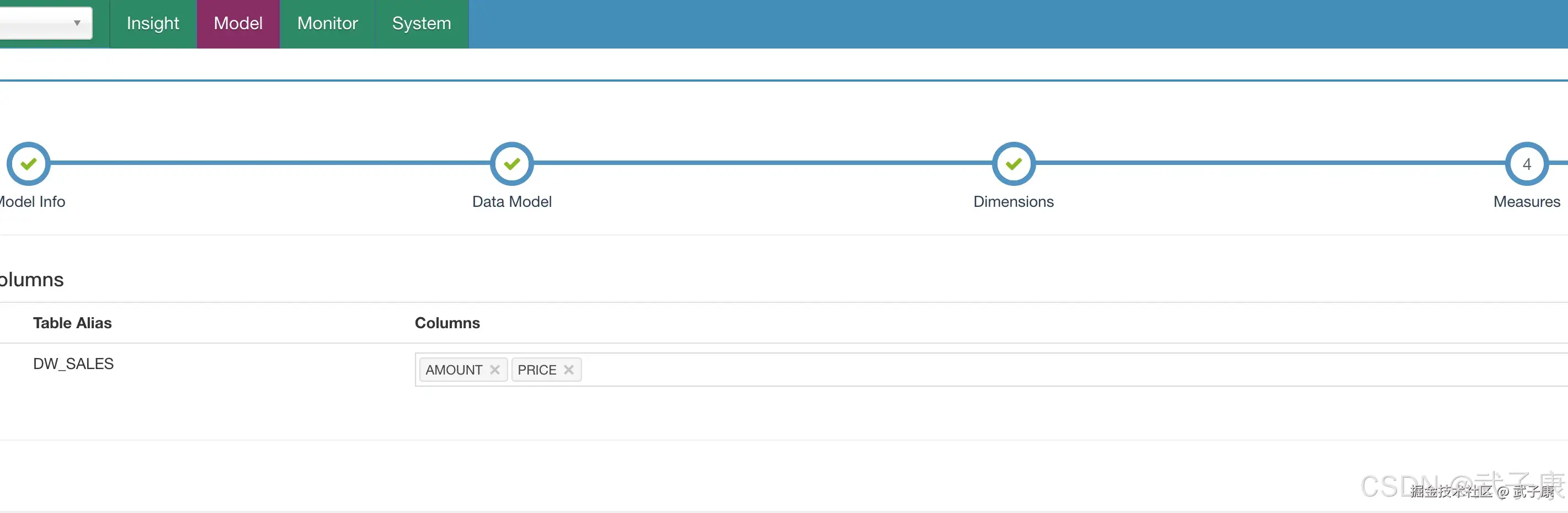 指定分区和过滤条件,不修改:
指定分区和过滤条件,不修改:  完毕之后,可以看到左侧多了一个:(刚才名字改了一下):
完毕之后,可以看到左侧多了一个:(刚才名字改了一下): 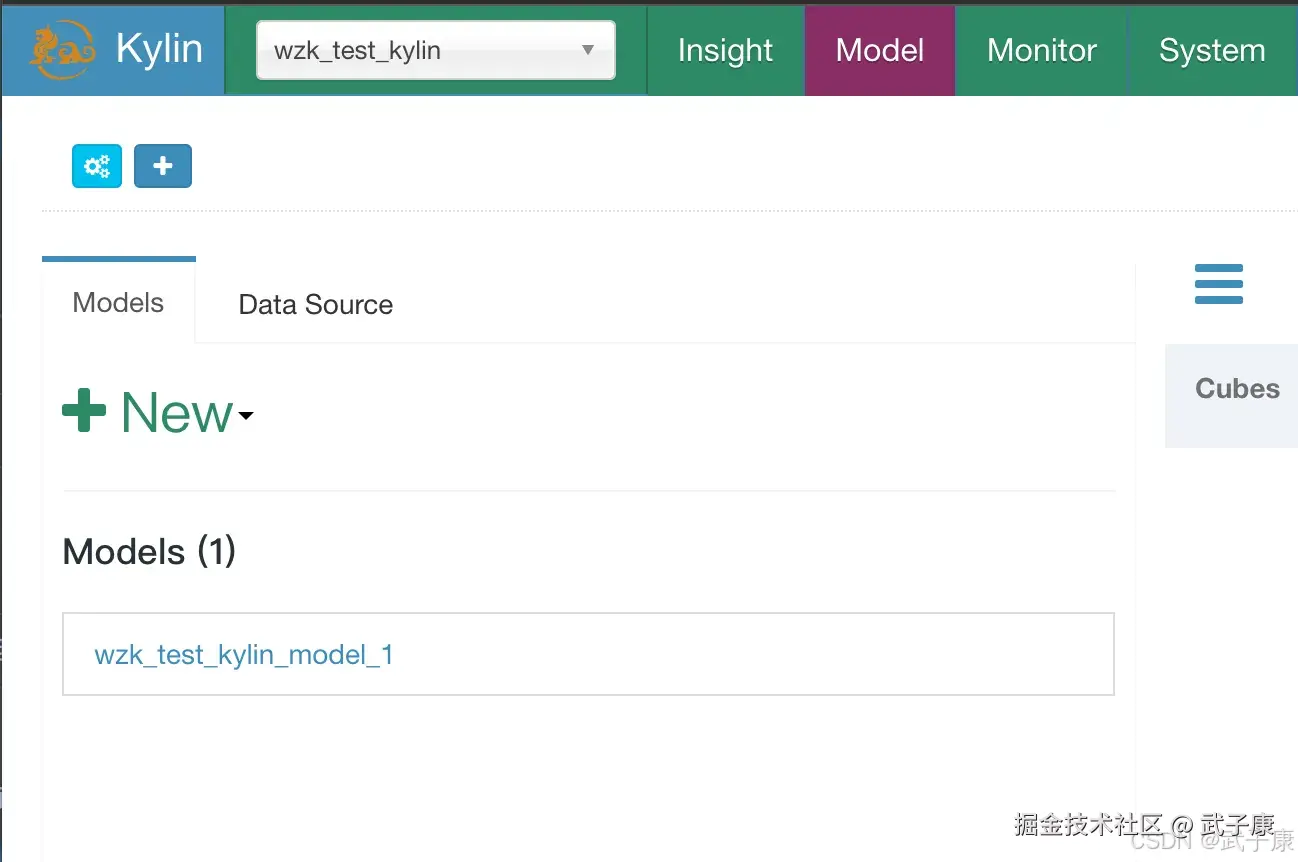
创建立方体(Cube)
新建Cube  选择数据模型,同时设置一个Cube的名字:
选择数据模型,同时设置一个Cube的名字: 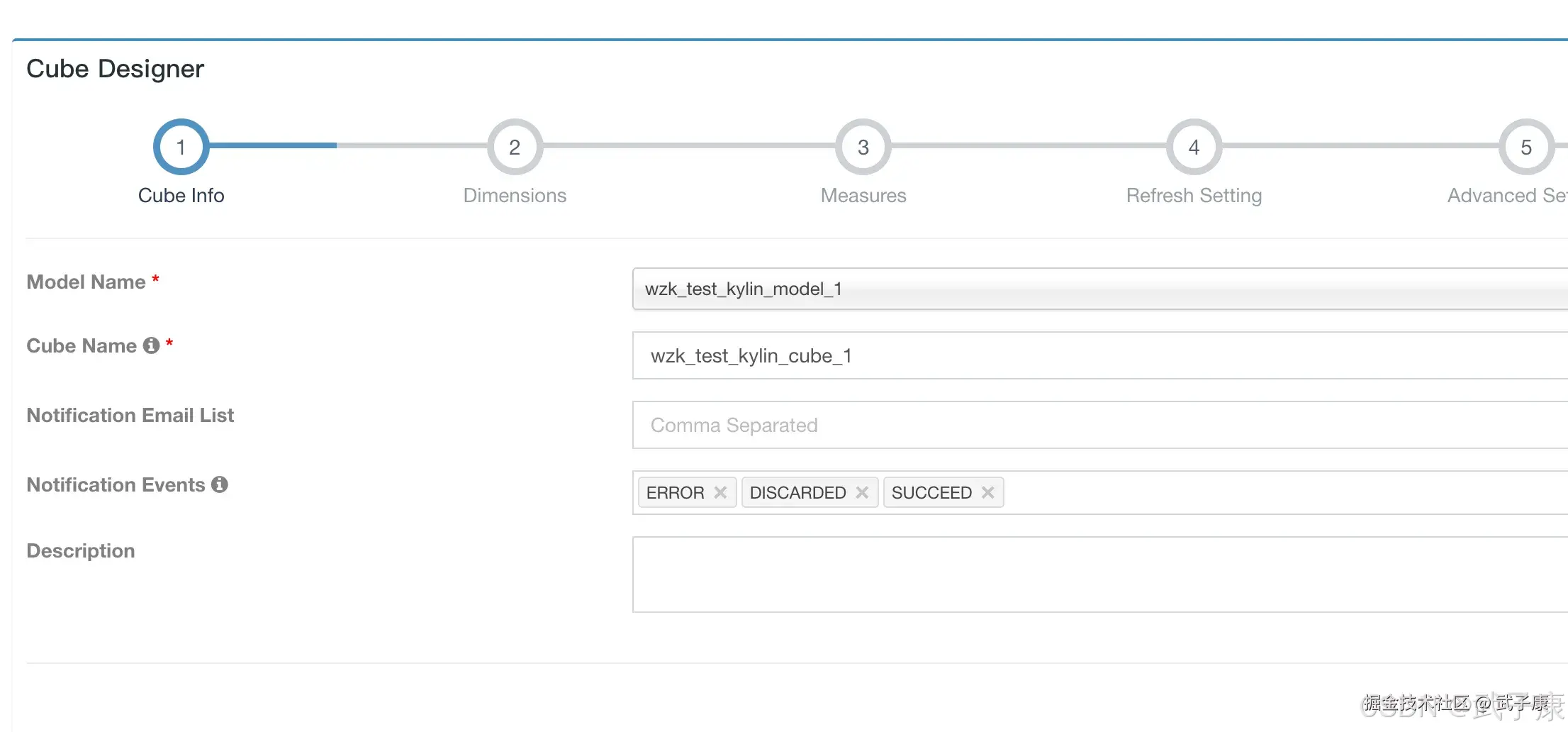 选择 Add Dimensions 指定维度:
选择 Add Dimensions 指定维度: 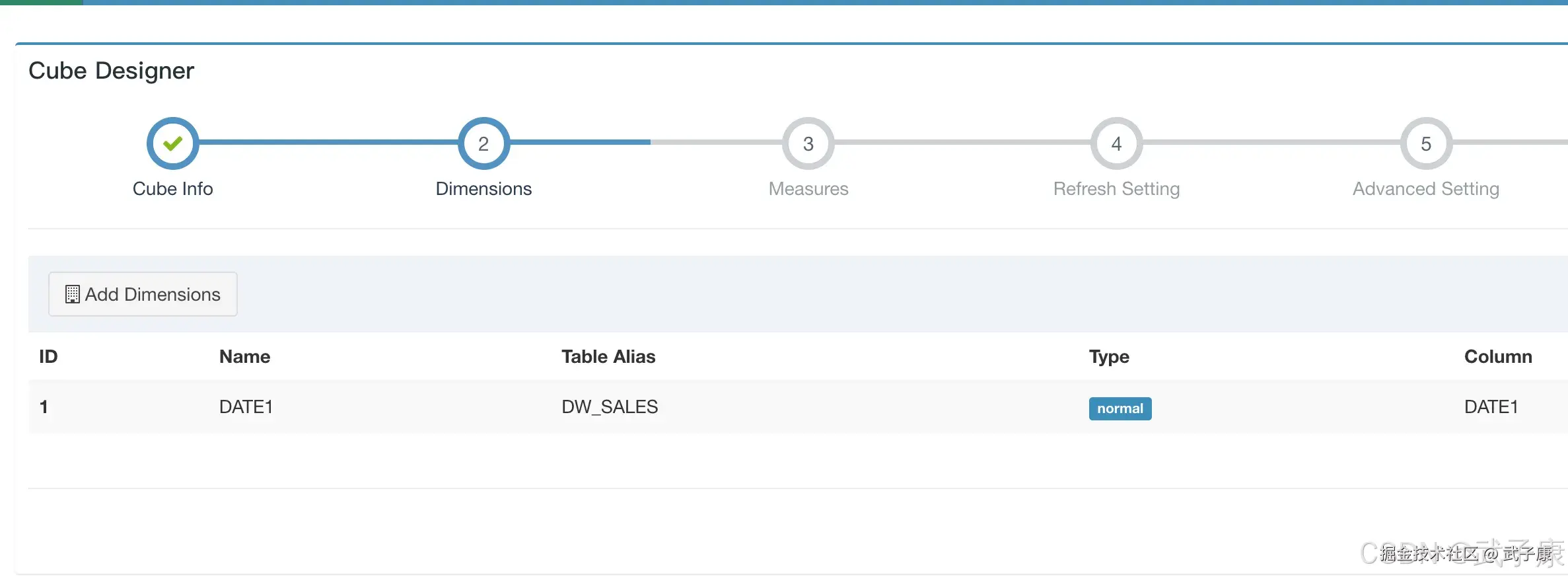 指定度量:
指定度量:
- _COUNT_是系统缺省参数给的。
- 新增 column叫 total_money 选择 DW_SALES.PRICE
- 新增 column叫 total_amount 选择 DW_SALES.AMOUNT
图片1 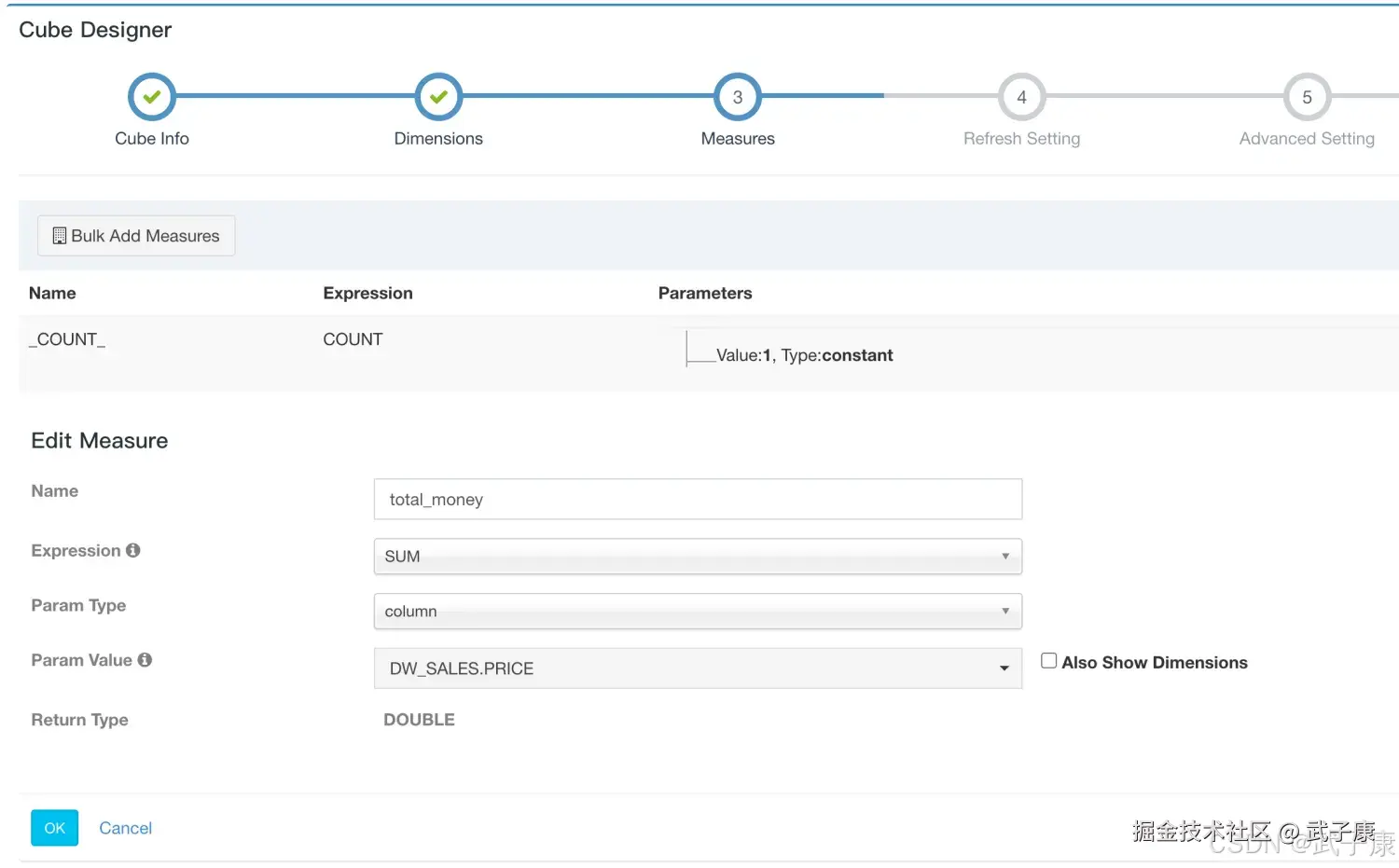 图片2
图片2 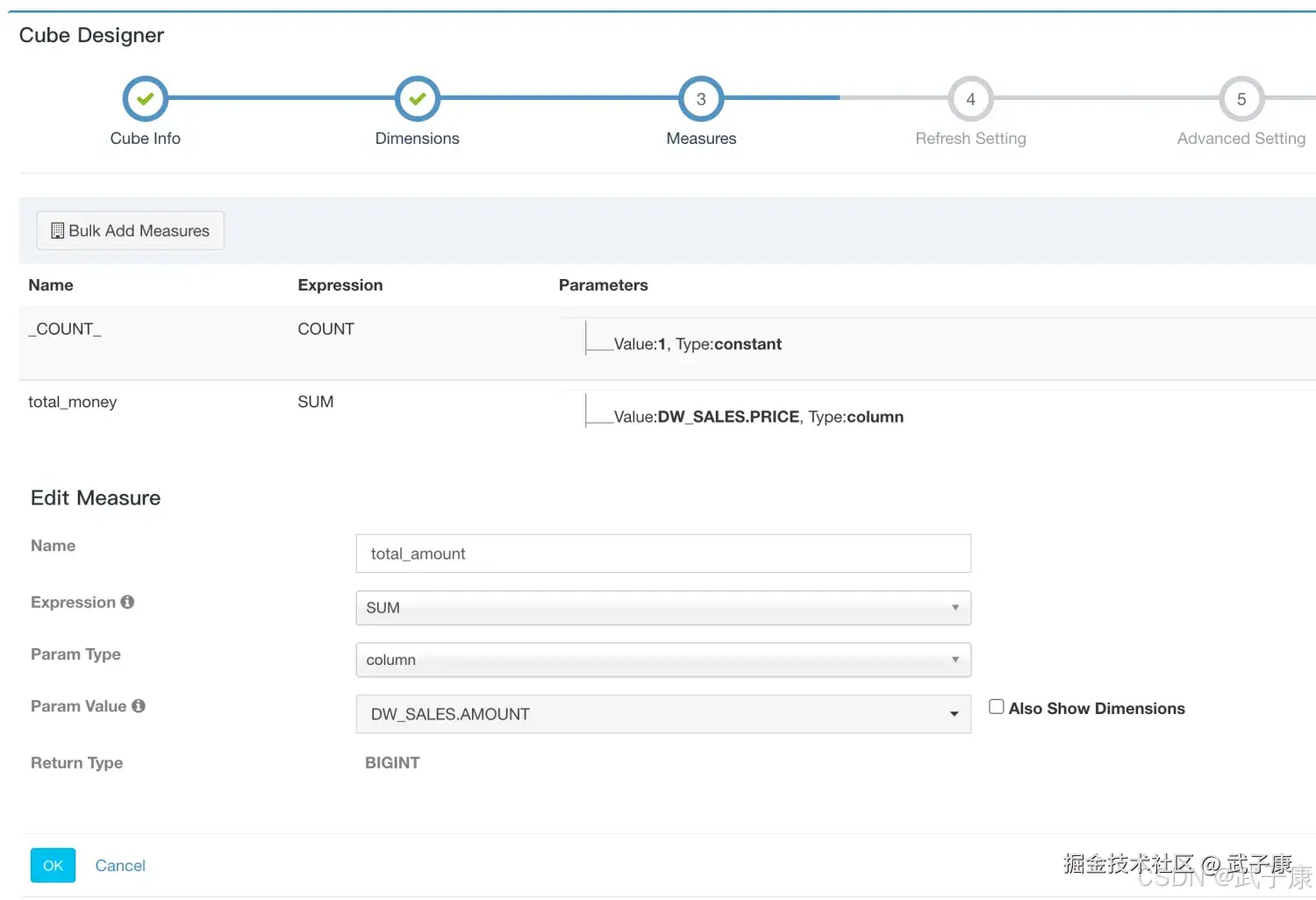 指定刷新设置:(默认的没改)
指定刷新设置:(默认的没改) 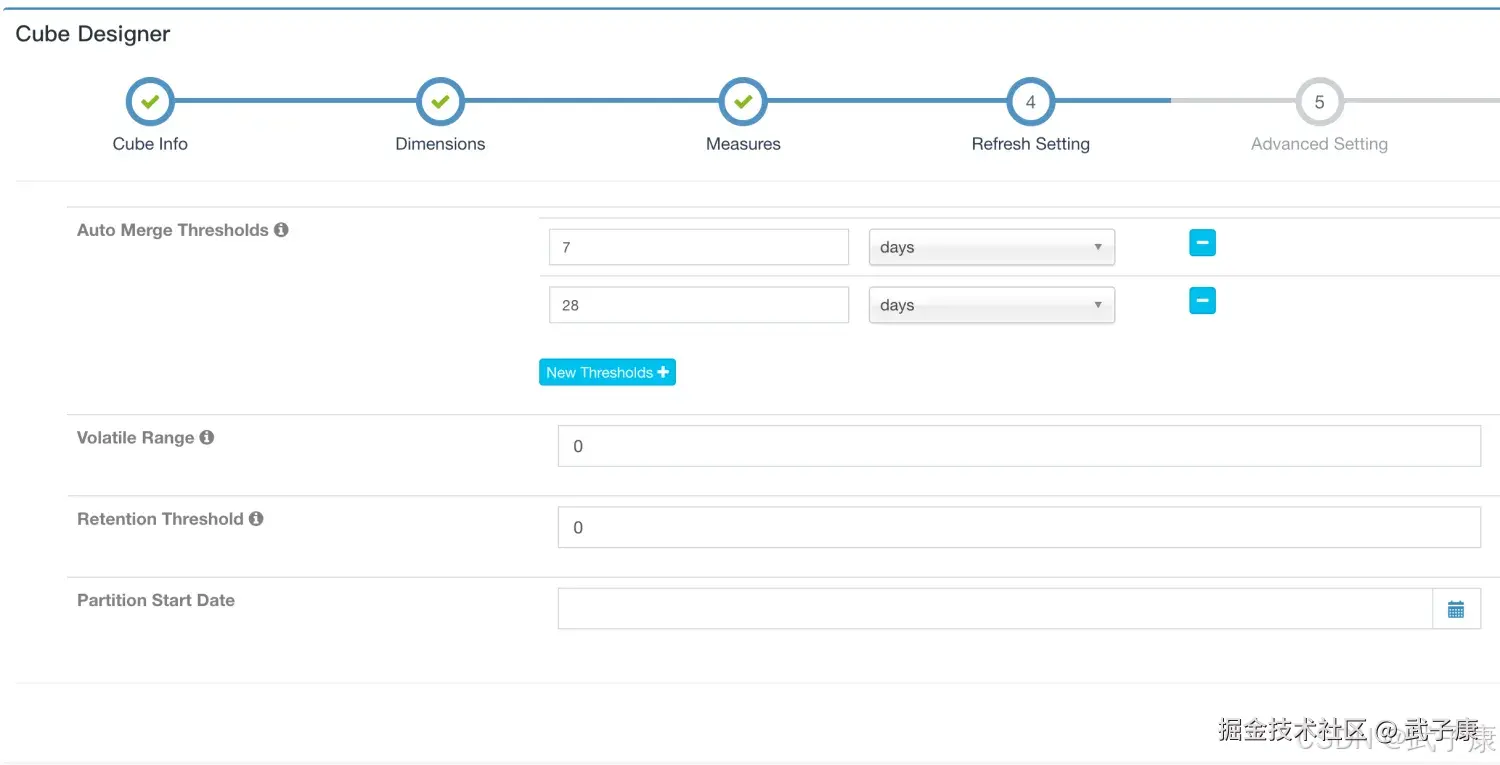 高级设置,找到Cube Engine的部分,选择 MapReduce:
高级设置,找到Cube Engine的部分,选择 MapReduce: 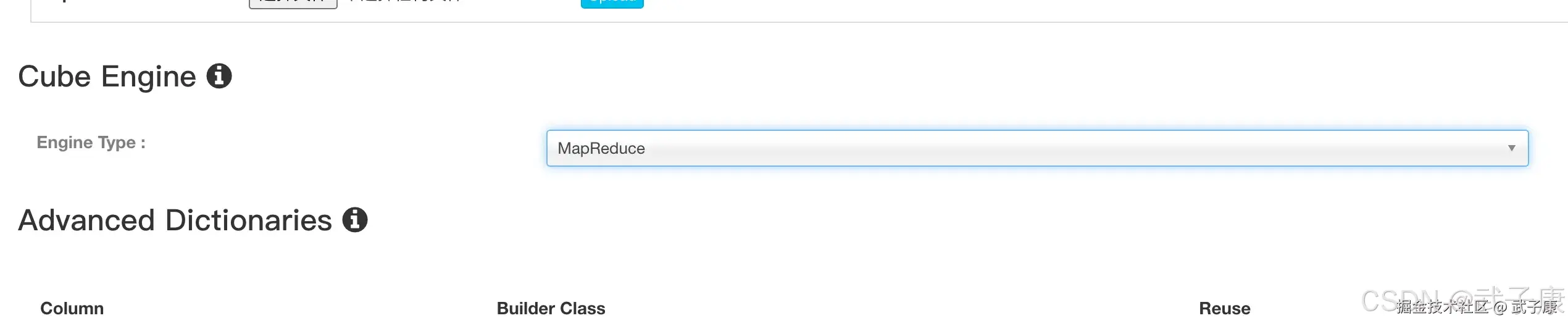 后边的都默认就行,最后保存Save之后,可以看到如下的页面:
后边的都默认就行,最后保存Save之后,可以看到如下的页面: 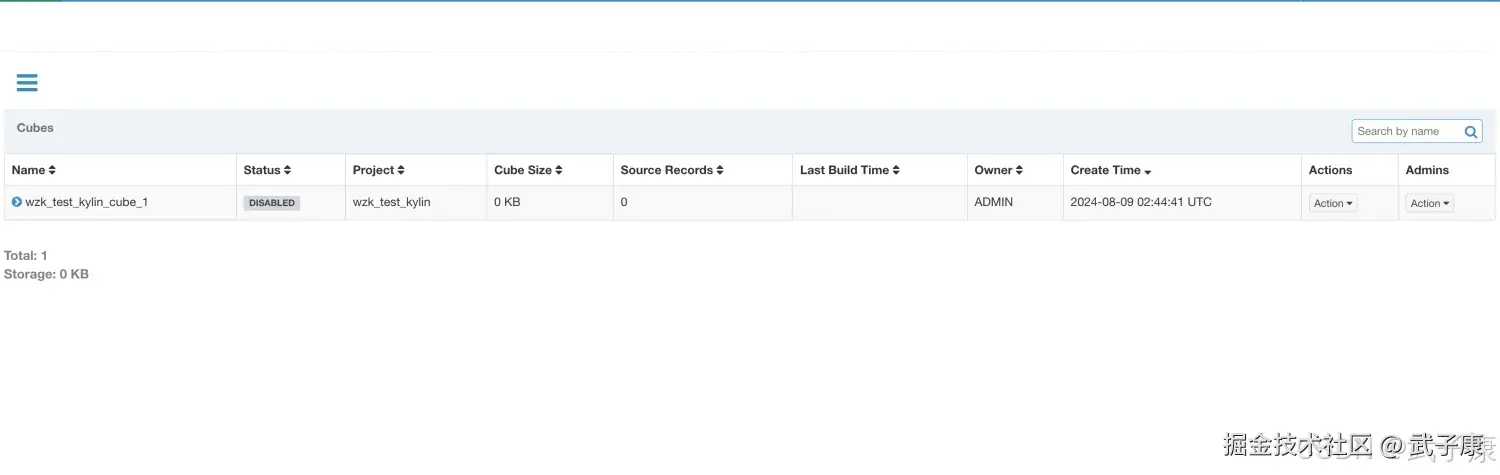 选择后面的Actions的Build:
选择后面的Actions的Build:  进入Monitor页面可以看到任务的进度,可视化的,刷新页面可以看到数据在变,但是我性能太差了,需要等好长时间:
进入Monitor页面可以看到任务的进度,可视化的,刷新页面可以看到数据在变,但是我性能太差了,需要等好长时间: 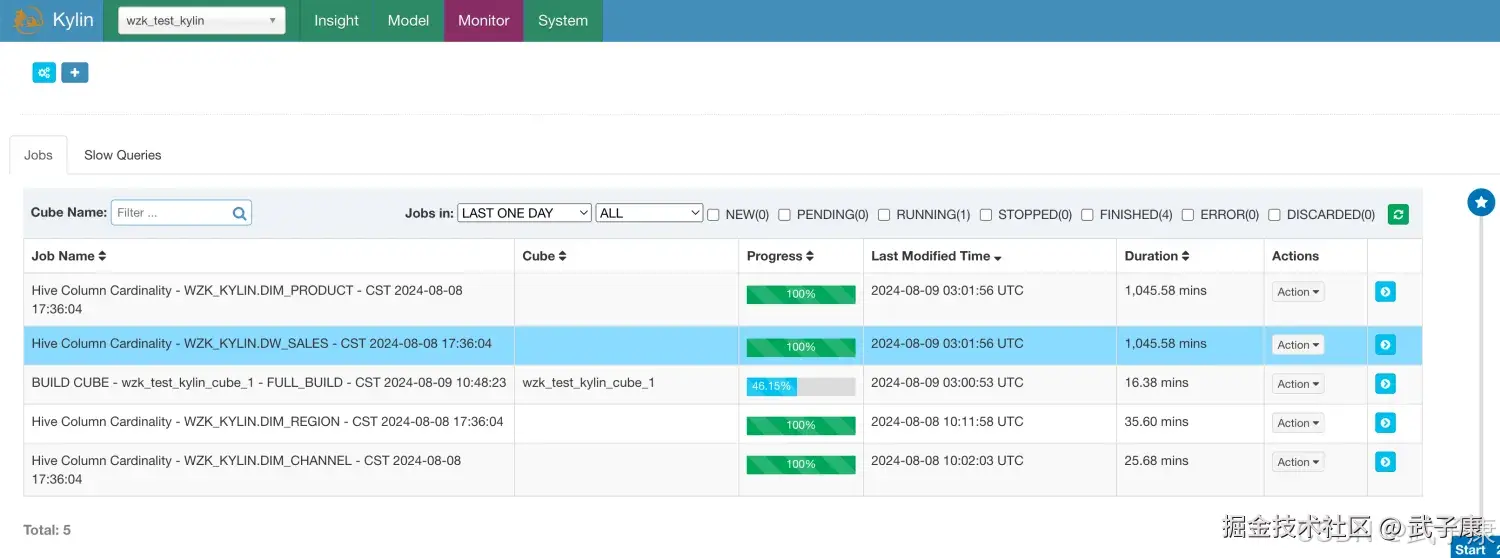 等了好久好久··· 终于执行完毕了:
等了好久好久··· 终于执行完毕了: 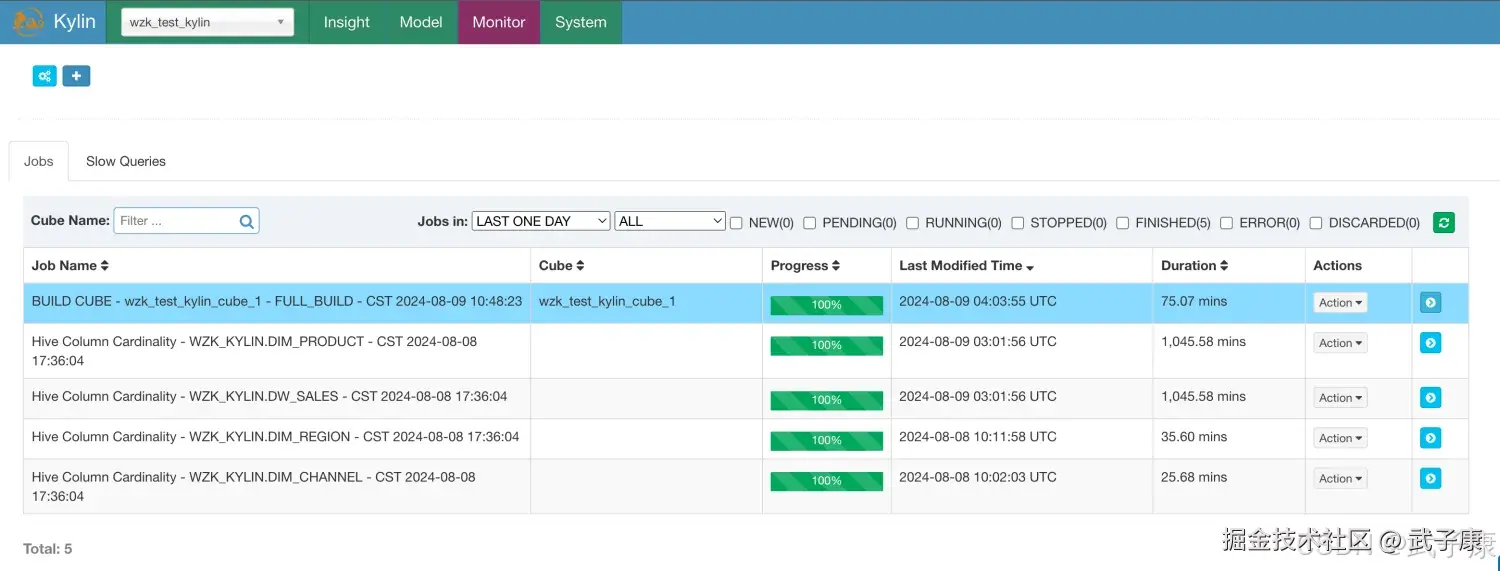
执行SQL
进入 Insight 选项卡中,执行下面的SQL进行查询:
sql
select
date1,
sum(price) as total_money,
sum(amount) as total_amount
from dw_sales
group by date1;运行出来的结果是: 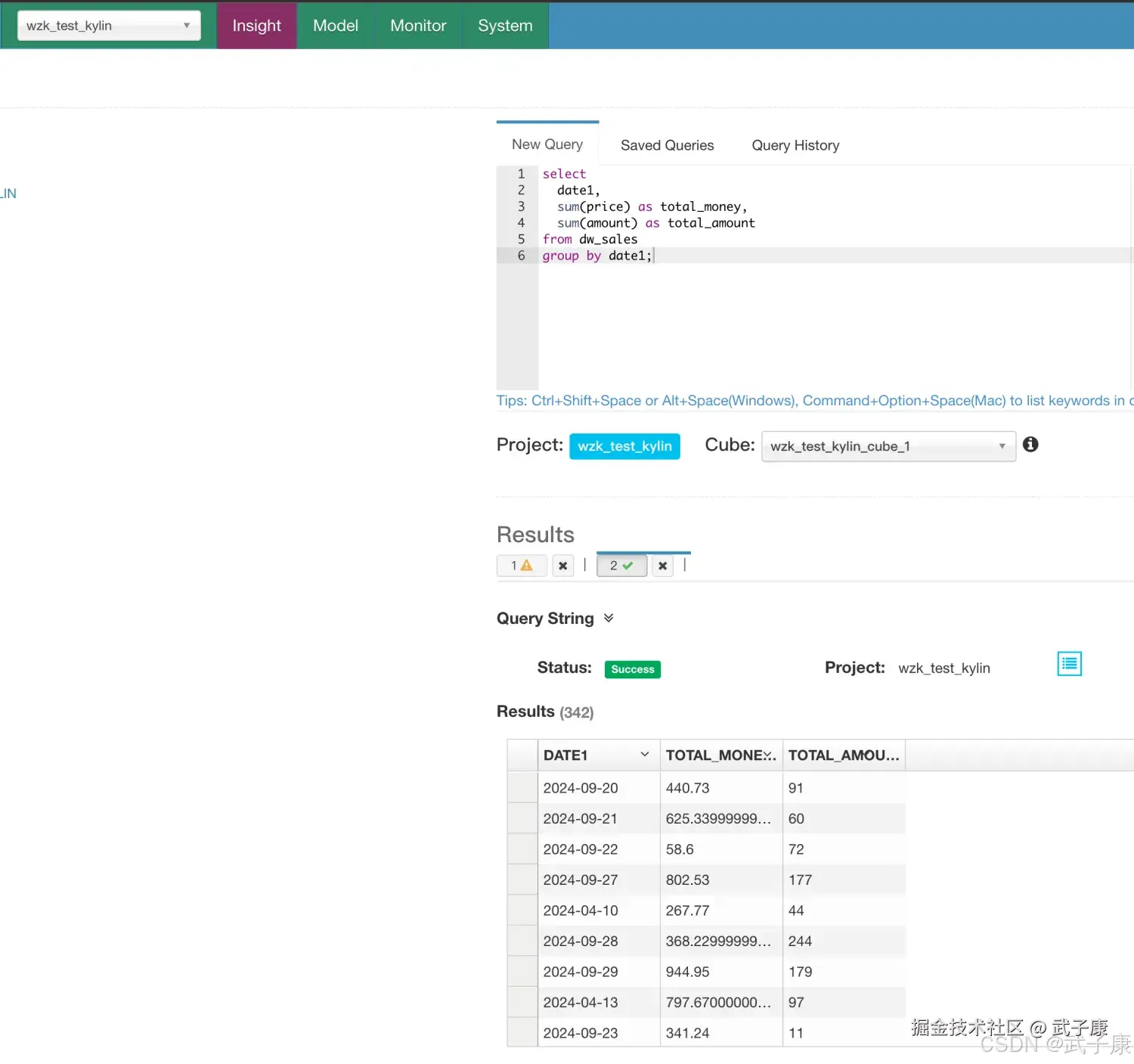
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| 构建失败,日志提示维度表冲突 | 维度主键非唯一 | Build 日志中查重复键;对比维表去重保证主键唯一;预处理去重/筛选脏数据 |
| 构建极慢/超时 | 选了 MR 引擎且 Cuboid 过多 | 监控页 Task 阶段耗时长启用 Aggregation Group 剪枝;调大并行度与资源队列 |
| 维度表加载内存溢出 | 维度表过大或频繁快照 | Job 日志内存报错缩小维度列、分拆维度;提高阈值配置或改查法 |
| 查询未命中 Cube,回源变慢 | 维度/度量与查询不匹配 | Query Profile/日志看命中补缺失的 Cuboid 或调整 SQL(维度/过滤一致) |
| HBase 读放大/热点 | RowKey 设计或 Region 不均 | HBase UI/RegionServer 指标调整分区与预分裂;优化编码与聚合层级 |
| 构建卡在 Snapshot | 维度表频繁变更 | 观察快照步骤耗时稳定维表更新周期;启用快照复用策略 |
| Kafka 实时延迟(如启用) | 批量大小/并发不当 | 消费滞后、端到端延迟调参批量与并发;区分冷热路径(Lambda) |
| JDBC 连接失败 | 驱动/URL/权限错误 | 客户端报错码校正驱动与 URL;开白名单并授予只读账户 |
| MapReduce 任务失败 | 资源不足/超配额 | Yarn 日志/失败重试调整容器内存与并发;为 Job 绑定独立队列 |
| 聚合结果异常 | 事实→维度映射缺失 | 比对外键空值比例过滤无法映射记录;完善 ETL 校验规则 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-127 Qwen2.5-Omni 深解:Thinker-Talker 双核、TMRoPE 与流式语音
💻 Java篇持续更新中(长期更新)
Java-174 FastFDS 从单机到分布式文件存储:实战与架构取舍 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 正在更新,深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解