spymemcached的IO流程解析
spymemcached的整体源码结构介绍 从整体上介绍了spymemcached的设计流程,功能流转以及有特色的地方;本文重点介绍一下spymemcached的核心功能--网络IO功能;了解一下高性能的缓存数据库的SDK核心功能,看看是如何设计?我们能从中学习到什么?
整体流程
简单介绍一下
- spymemcached的网络IO的入口在MemcachedConnection,
- 在MemcachedConnection是以单线程无限循环的方式发送命令、等待返回结果、响应命令结果;
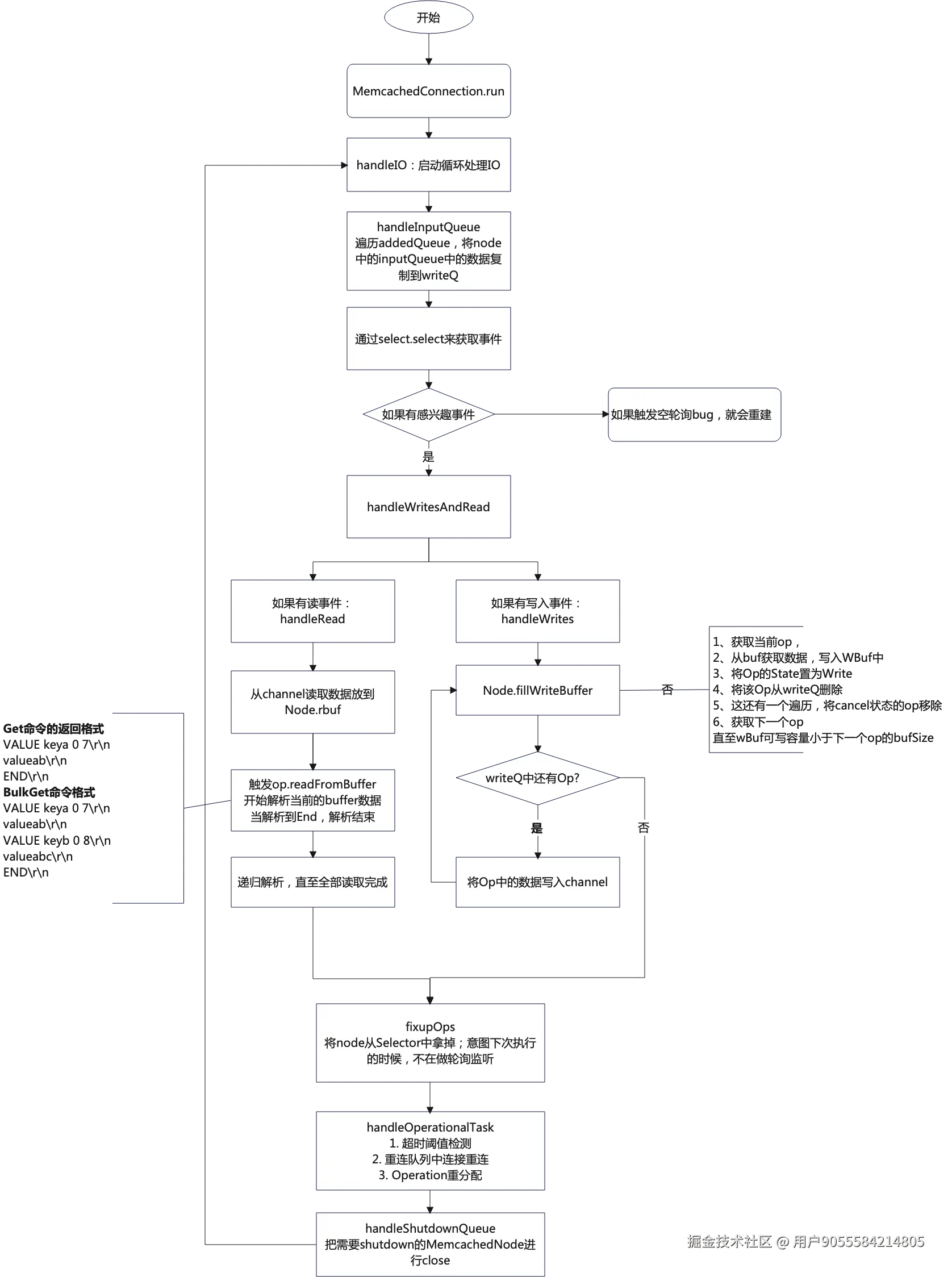
spymemcached的IO部分的源码介绍
MemcachedConnection.run
- 判断是否shutdown
- 将异步增加的待执行的MemcachedNode中的Operations从inputQueue转移至writeQ
- 如果重试队列有任务,则更新下次selector的唤醒时间;(最大等待时间1s);(ps:rpc的指数退避重连)
- 执行Selector.select后,发现感兴趣的事件=0,会执行handleEmptySelects;如果发现有空轮询Bug,进行断连、重连;(ps: netty的重轮询bug)
- 否则会执行handleIO进行读写的逻辑解析
- 后处理:超时超过阈值,则重连;如果本次循环中有一些MemcachedNode没有命令执行,就会将其channel给close掉;
ini
public void handleIO() throws IOException {
if (shutDown) {
logger.debug("No IO while shut down.");
return;
}
handleInputQueue();
long delay = wakeupDelay;
if (!reconnectQueue.isEmpty()) {
long now = System.currentTimeMillis();
long then = reconnectQueue.firstKey();
delay = Math.max(then - now, 1);
}
assert selectorsMakeSense() : "Selectors don't make sense.";
int selected = selector.select(delay);
if (shutDown) {
return;
} else if (selected == 0 && addedQueue.isEmpty()) {
handleWokenUpSelector();
} else if (selector.selectedKeys().isEmpty()) {
handleEmptySelects();
} else {
emptySelects = 0;
Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();
while(iterator.hasNext()) {
SelectionKey sk = iterator.next();
handleIO(sk);
iterator.remove();
}
}
// 负责处理清理工作,比如:超过超时阈值次数后,断连; 重连reconnectQueue
handleOperationalTasks();
handleReconnectDueToTimeout();
}1、接收待处理的MemcachedNode
- 判断是否有待执行的MemcachedNode
- 遍历待执行的
List<MemcachedNode>; - 如果node is active & 正在进行写操作,就直接调用handleWrites; 否则就会将该MemcachedNode中的operation从inputQueue复制的writeQ;
- 同时将给socket注册write的监听事件;
- 如果node is not active, 那就会将其重新加入addQueue,等待下次重试;
ini
private void handleInputQueue() {
if (!addedQueue.isEmpty()) {
Collection<MemcachedNode> toAdd = new HashSet<>();
Collection<MemcachedNode> todo = new HashSet<>();
MemcachedNode qaNode;
while ((qaNode = addedQueue.poll()) != null) {
todo.add(qaNode);
}
for (MemcachedNode node : todo) {
boolean readyForIO = false;
if (node.isActive()) {
if (node.getCurrentWriteOp() != null) {
readyForIO = true;
}
} else {
toAdd.add(node);
}
node.copyInputQueue();
if (readyForIO) {
try {
if (node.getWbuf().hasRemaining()) {
handleWrites(node);
}
} catch (IOException e) {
logger.warn("Exception handling write", e);
lostConnection(node);
}
}
node.fixupOps();
}
addedQueue.addAll(toAdd);
}
}2、向Server发送数据(inputQueue -> writeQ)
前面省略了一些建连、监听事件的逻辑, 直入主题:主干源码流程;
- 将node中的数据写入write buffer,直至buffer满
- 如果write buffer已经写入数据,先把buffer里面的数据发送给server,然后在继续写入;
- 依次迭代执行2,3直至把当前MemcachedNode里面所有的数据写完;
ini
private void handleWrites(final MemcachedNode node) throws IOException {
// 核心:把node中的op的数据写入writebuffer
node.fillWriteBuffer(shouldOptimize);
boolean canWriteMore = node.getBytesRemainingToWrite() > 0;
while (canWriteMore) {
int wrote = node.writeSome();
metrics.updateHistogram(OVERALL_AVG_BYTES_WRITE_METRIC, wrote);
node.fillWriteBuffer(shouldOptimize);
canWriteMore = wrote > 0 && node.getBytesRemainingToWrite() > 0;
}
}2.1 将Op数据写入Socket,MemcachedNode.fillWriteBuffer
- 获取当前Op,并将其加入到readQ;并将当前的Op.state 由WRITE_QUEUE->WRITING 详见getNextWritableOp()
- 计算当前buffer是否大于即将要写入的命令大小,
- 如果小于,则说明buffer已经快满了,需要flush到channel
- 如果大于,则将命令内容写入buffer, 把当前Op状态由WRITING-> READING ;并把这个Op从WriteQ中移除
- 如果开启优化,就会将
- 循环执行2-5
scss
public final void fillWriteBuffer(boolean shouldOptimize) {
if (toWrite == 0 && readQ.remainingCapacity() > 0) {
getWbuf().clear();
Operation o=getNextWritableOp();
while(o != null && toWrite < getWbuf().capacity()) {
synchronized(o) {
assert o.getState() == OperationState.WRITING;
ByteBuffer obuf = o.getBuffer();
assert obuf != null : "Didn't get a write buffer from " + o;
if (obuf != null) {
int bytesToCopy = Math.min(getWbuf().remaining(), obuf.remaining());
byte[] b = new byte[bytesToCopy];
obuf.get(b);
getWbuf().put(b);
if (!o.getBuffer().hasRemaining()) {
o.writeComplete();
transitionWriteItem();
preparePending();
if (shouldOptimize) {
optimize();
}
o = getNextWritableOp();
}
toWrite += bytesToCopy;
} else {
reportFillWriteBufferBug();
removeCurrentWriteOpWhileWriteBufferIsNull();
o = getNextWritableOp();
}
}
}
getWbuf().flip();
assert toWrite <= getWbuf().capacity() : "toWrite exceeded capacity: "
+ this;
assert toWrite == getWbuf().remaining() : "Expected " + toWrite
+ " remaining, got " + getWbuf().remaining();
} else {
logger.debug("Buffer is full, skipping");
}
}这里有个问题: read-write的顺序问题; 在这个方法执行中,有一个时间段:如果readQ和writeQ都有这个Op, 此时server OOM,就会导致当前的Op已经有返回值了;所以这种情况下,就需要把writeQ中的Op给清掉;不然执行就会出错;
2.1.1 获取下一个可写Op:getNextWritableOp
- 获取当前的writeQp, 判断是否是WRITE_QUEUE状态,
- 再判断是否超时、cancel
- 如果没有timeout、cancel,则会将op从WRITE_QUEUE->WRITING状态, 然后加入到readQ
ini
private Operation getNextWritableOp() {
Operation o = getCurrentWriteOp();
while (o != null && o.getState() == OperationState.WRITE_QUEUED) {
synchronized(o) {
if (o.isCancelled()) {
logger.debug("Not writing cancelled op.");
Operation cancelledOp = removeCurrentWriteOp();
assert o == cancelledOp;
} else if (o.isTimedOut(defaultOpTimeout)) {
logger.debug("Not writing timed out op.");
Operation timedOutOp = removeCurrentWriteOp();
assert o == timedOutOp;
} else {
o.writing();
if (!(o instanceof TapAckOperationImpl)) {
readQ.add(o);
}
return o;
}
o = getCurrentWriteOp();
}
}
return o;
}3、发送命令(writeQ -> readQ)
- 先从readQ中读取Op,
- 再从ByteBuffer中获取数据, 按照memcached的协议 进行解码
- 解码完成后, 调用Callback的receiveStatus、gotData、complete等函数将结果回传给使用方;
ini
private void handleReads(final MemcachedNode node) throws IOException {
Operation currentOp = node.getCurrentReadOp();
if (currentOp instanceof TapAckOperationImpl) {
node.removeCurrentReadOp();
return;
}
ByteBuffer rbuf = node.getRbuf();
final SocketChannel channel = node.getChannel();
int read = channel.read(rbuf);
metrics.updateHistogram(OVERALL_AVG_BYTES_READ_METRIC, read);
if (read < 0) {
currentOp = handleReadsWhenChannelEndOfStream(currentOp, node, rbuf);
}
while (read > 0) {
rbuf.flip();
while (rbuf.remaining() > 0) {
if (currentOp == null) {
throw new IllegalStateException("No read operation.");
}
long timeOnWire =
System.nanoTime() - currentOp.getWriteCompleteTimestamp();
metrics.updateHistogram(OVERALL_AVG_TIME_ON_WIRE_METRIC,
(int)(timeOnWire / 1000));
metrics.markMeter(OVERALL_RESPONSE_METRIC);
synchronized(currentOp) {
readBufferAndLogMetrics(currentOp, rbuf, node);
}
currentOp = node.getCurrentReadOp();
}
rbuf.clear();
read = channel.read(rbuf);
node.completedRead();
}
}3.1 开始解码 readFromBuffer
注:net.spy.memcached.protocol.ascii.OperationImpl#readFromBuffer
- 先判断当前状态是否是COMPLETE以及是否有可写数据
- 初次进来时,readType=LINE,所以会先进行解码,mc是按照\r\n为一行,所以当遍历data解析到\r\n后,就会将其转成字符串
- 会判断LINE是否有errorMsg,如果有,则抛错,如果没有,则会执行handleLine进行解析,解析完成后,readType就会转换成DATA
- 随后会再次进入这个while,执行handleRead;进行回填CallBack
ini
public void readFromBuffer(ByteBuffer data) throws IOException {
// Loop while there's data remaining to get it all drained.
while (getState() != OperationState.COMPLETE && data.remaining() > 0) {
if (readType == OperationReadType.DATA) {
handleRead(data);
} else {
int offset = -1;
for (int i = 0; data.remaining() > 0; i++) {
byte b = data.get();
if (b == '\r') {
foundCr = true;
} else if (b == '\n') {
assert foundCr : "got a \n without a \r";
offset = i;
foundCr = false;
break;
} else {
assert !foundCr : "got a \r without a \n";
byteBuffer.write(b);
}
}
if (offset >= 0) {
String line = new String(byteBuffer.toByteArray(), CHARSET);
byteBuffer.reset();
OperationErrorType eType = classifyError(line);
if (eType != null) {
errorMsg = line.getBytes();
handleError(eType, line);
} else {
handleLine(line);
}
}
}
}
}3.1.1 不同命令按照指定格式解码:以 Get命令为例
net.spy.memcached.protocol.ascii.BaseGetOpImpl#handleLine
- 如果line是以END结尾,则会调用callback设置状态
- 如果line以VALUE开头,则会根据get命令格式进行解析,同时将dataType设置成DATA
- 如果是LOCK_ERROR,则会调用callback设置LOCK_ERROR状态,然后将op的状态设置成COMPLETE
ini
public final void handleLine(String line) {
if (line.equals("END")) {
if (hasValue) {
getCallback().receivedStatus(END);
} else {
getCallback().receivedStatus(NOT_FOUND);
}
transitionState(OperationState.COMPLETE);
data = null;
} else if (line.startsWith("VALUE ")) {
String[] stuff = line.split(" ");
assert stuff[0].equals("VALUE");
currentKey = stuff[1];
currentFlags = Integer.parseInt(stuff[2]);
data = new byte[Integer.parseInt(stuff[3])];
if (stuff.length > 4) {
casValue = Long.parseLong(stuff[4]);
}
readOffset = 0;
hasValue = true;
setReadType(OperationReadType.DATA);
} else if (line.equals("LOCK_ERROR")) {
getCallback().receivedStatus(LOCK_ERROR);
transitionState(OperationState.COMPLETE);
} else {
assert false : "Unknown line type: " + line;
}
}4、断连触发时机
断连时机
断连时机一:OperationException
当服务端返回SERVER_ERROR时,客户端捕获后,并将其封装成OperationException,逐步向上抛,最终被net.spy.memcached.MemcachedConnection#handleIO捕获,执行lostConnection断连
断连时机二:ConnectionException
出现连接异常
断连时机三:ClosedChanelException
channel被关闭,但是MemcachedConnection没有被shutdown
断连时机四:Exception
兜底异常
lostConnection
- 把当前的MemcachedNode的状态置为inactive,不再接收新命令
- 将当前MemcachedNode中channel进行close,
- 将当前的MemcachedNode加入到reconnectQueue中,并计算下次重连时间
- 根据当前的FailureMode模式将MemcachedNode中的Operation进行分发,若Redistribute,则会遍历inputQueue中的所有Op,将其分发给其他正常的MemcachedNode;如果是Cancel,则会将inputQueue里面所有的Op都会cancel掉;
scss
private void lostConnection(final MemcachedNode node) {
queueReconnect(node);
for (ConnectionObserver observer : connObservers) {
observer.connectionLost(node.getSocketAddress());
}
}
scss
protected void queueReconnect(final MemcachedNode node) {
if (shutDown) {
return;
}
logger.warn("Closing, and reopening {}, attempt {}.", node, node.getReconnectCount());
if (node.getSk() != null) {
node.getSk().cancel();
assert !node.getSk().isValid() : "Cancelled selection key is valid";
}
node.reconnecting();
try {
if (node.getChannel() != null && node.getChannel().socket() != null) {
node.getChannel().socket().close();
} else {
logger.info("The channel or socket was null for {}", node);
}
} catch (IOException e) {
logger.warn("IOException trying to close a socket", e);
}
node.setChannel(null);
// 指数退避重连,下次重连时间 = 当前时间 + 2^node的重连次数
long delay = (long) Math.min(maxDelay, Math.pow(2,
node.getReconnectCount()) * 1000);
long reconnectTime = System.currentTimeMillis() + delay;
// 如果已经包含了,则下次执行时间++;
while (reconnectQueue.containsKey(reconnectTime)) {
reconnectTime++;
}
reconnectQueue.put(reconnectTime, node);
metrics.incrementCounter(RECON_QUEUE_METRIC);
node.setupResend();
if (failureMode.get() == FailureMode.Redistribute) {
redistributeOperations(node.destroyInputQueue());
} else if (failureMode.get() == FailureMode.Cancel) {
cancelOperations(node.destroyInputQueue());
}
}5、后置处理
- 检查超时请求个数超过阈值,则执行lostConnection;
- 如果reconnectQueue有数据,则会尝试重连
- 如果是retry策略且retryOps不为空,则会将这些Op进行redistribute;
scss
private void handleOperationalTasks() throws IOException {
checkPotentiallyTimedOutConnection();
if (!shutDown && !reconnectQueue.isEmpty()) {
attemptReconnects();
}
if (!retryOps.isEmpty()) {
ArrayList<Operation> operations = new ArrayList<>(retryOps);
retryOps.clear();
redistributeOperations(operations);
}
handleShutdownQueue();
}学习总结 & 开源组件对比
源码看多了,发现大家解决问题的思路殊途同归,下面总结一下spymemcached的经典解决问题的思想
1、连接断开后策略:指数退避重连
spymemcached
如果建连失败,会一直重试,但是每次重试的时间间隔是指数间隔,这样避免频繁无效的重试;
grpc
grpc中的重连逻辑也是指数退避重连思想
JDK 空轮训bug
spymemcached
在spymemcached中,利用重建来规避这个问题,同时阈值是256次空轮询;spymemcached是2013年解决的;
netty
netty也是利用重建的方式规避这个bug,监听阈值也是256, 但是netty使用该思路规避的时间是2019年 ;
并发串行化
在并发中,开发是最复杂的,各种情况都需要考虑, 尤其是多线程同时操作导致线程不安全、资源竞争激烈、效率降低等问题;所以在很多组件中,都会采用并发串行化的思想,即把需要并发执行的操作都封装成一个个对象,然后放到Queue,当线程执行的时候,依次从Queue中取任务执行,这样就避免资源竞争、线程不安全等问题了;
spymemcached
- 在spymemcached中,只有一个IO线程进行不断轮询、等待Server响应,编解码;从而避免出现频繁上下文切换带来的性能损耗,以及减少多线程操作带来的线程不安全问题;
- 业务所有的操作都会封装成Operation,将Operation压入MemcachedNode的inputQueue栈,在IO线程读取inputQueue的数据,通过inputQueue -> writeQ -> readQ 的数据流转、状态切换来保证数据安全、数据操作的正确性;业务线程的操作终止于inputQueue, 其他后续的操作是在IO线程中操作,执行完成后,又通过CallBack进行回调填写数据;
- 这样既提高性能、又简化操作;
Lettuce & Netty
- 在Netty中,业务所有的操作会封装成一个对象,然后放到EventLoop的TaskQueue中,等待EventLoop的线程执行,
- 在处理响应结果的时候,EventLoop处理完成结果后,会通过Future将结果回传给业务;
总结
思路如出一辙
状态机
spymemcached
MemcachedOperation 利用state来表示当前处于什么状态;
- WRITE_QUEUE 表示刚刚加入,待将其发送给Server
- WRITING 表示正在写入,ps:在调用getNextWriableOp时
- READING 已经发送给SERVER,正在等待响应结果;ps:发送finish
- COMPLETE 说明当前Op已经执行完成;

Netty
ChannelRegistered -> ChannelActive -> ChannelRead -> ChnannlReadComplete 等等
熔断组件