大家好,我是小悟。
最近,阿里通义正式开源了他们的首个深度研究Agent模型------DeepResearch。
简单来说,它是一种能像人类研究员一样,自主完成信息搜集、分析、推理,最后形成有价值结论的AI模型。
根据公开信息,它在多个国际权威评测集上,比如HLE、GAIA、BrowseComp这些"硬核考试"中,都拿到了SOTA的成绩。
更厉害的是,它只用了3B的激活参数,就超越了像OpenAI的o3、DeepSeek-V3.1和Claude-4-Sonnet这些动辄更大更复杂的模型所驱动的Agent。
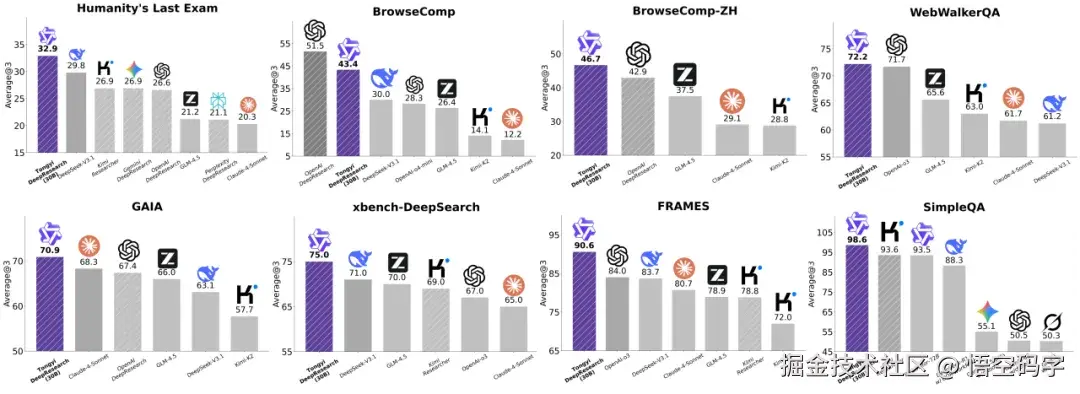
并不是靠堆参数或者砸数据来硬推效果,而是搭建了一套以合成数据为核心、贯穿预训练和后训练的完整训练体系。
说白了,就是用更聪明、更高效的方式去"教"这个模型,让它不仅学得快,而且学得准,还能举一反三。
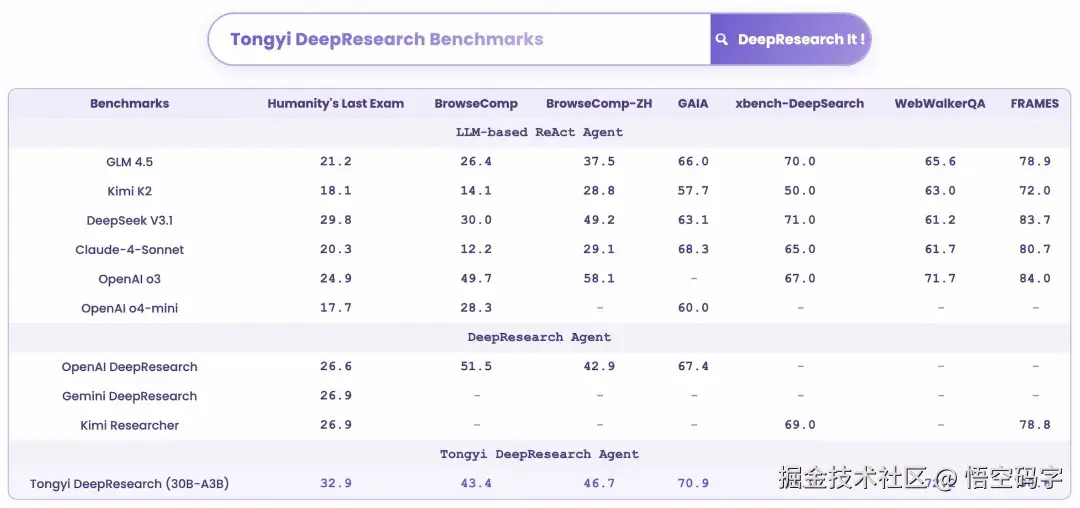
另外,在推理阶段他们也做了创新,设计了两种模式:一个是ReAct,用来考察模型的基础能力。
另一个是他们自研的IterResearch驱动的Heavy模式,专门用来挖掘模型在长时间、复杂任务中的潜力。
这就好比一个学生,不仅能答好基础题,还能在面对压轴大题时稳住心态、一步步拆解问题,最终给出高分答案。
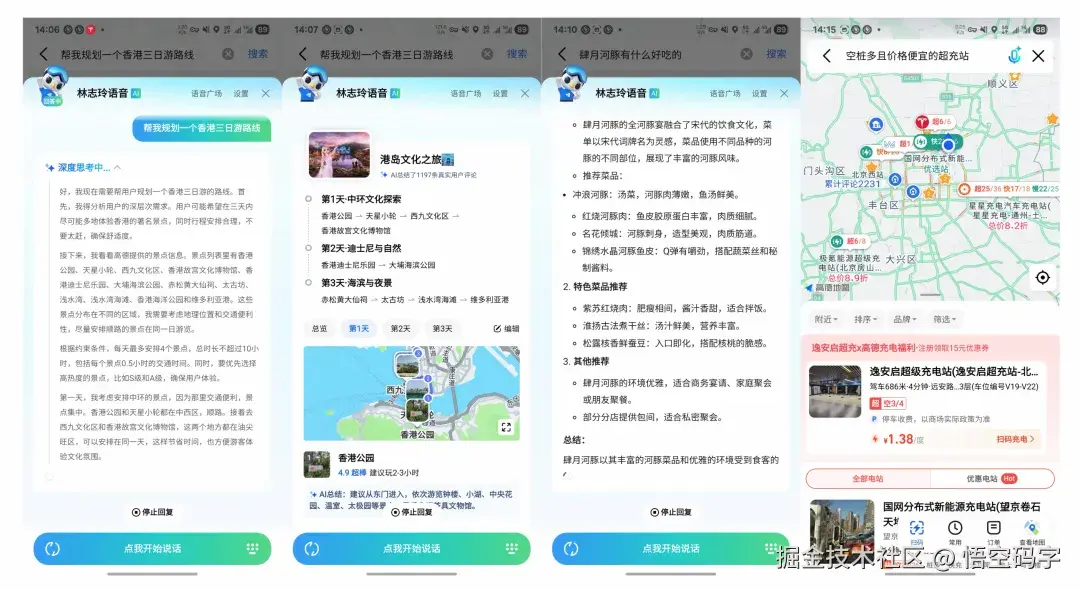
值得一提的是,这个模型可不是只存在于实验室里的"理论派"。阿里已经把它用在一些实际场景中了,比如跟高德合作推出的"小高老师",能帮你做复杂的旅行规划。
还有通义法睿,据说能像初级律师那样,自动检索案例、分析法规,做法律方面的深度研究。
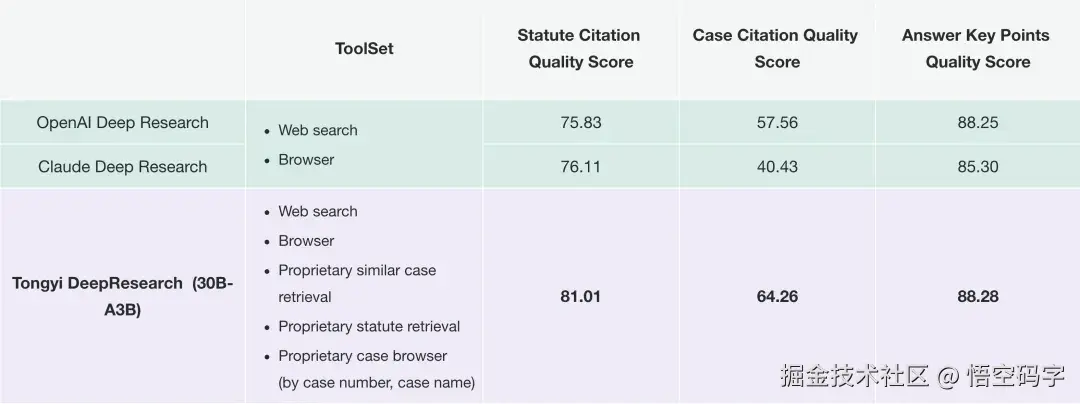
这些落地应用,证明DeepResearch不只是刷榜神器,而是真的有能力在现实世界中解决问题。
其实,这并不是阿里第一次在Agent领域发力。今年他们还陆续开源了WebWalker、WebDancer、WebSailor等项目,在智能体的数据合成和强化学习方面也取得了很不错的成绩。

可以说,DeepResearch的开源,是他们在这一方向上的又一个重要里程碑,也进一步丰富了他们在开源生态中的布局。
从个人角度来看,这次DeepResearch的开源,不仅仅是一个技术突破,更像是一种信号:AI正在从"能回答问题"向"能深入研究问题"迈进。
而阿里用一个相对轻量级(3B激活参数)的模型做到这一点,给整个行业都提供了新的思路和可能性。
未来的AI,肯定不是只会聊天的工具,而是能真正帮我们解决问题、甚至参与到复杂决策过程中的伙伴。而像DeepResearch这样的模型,正在让这一天加速到来。
阿里这次不仅开源了模型本身,连框架和方案都一并开放了,代码托管在GitHub、Hugging Face和魔搭社区,可以直接去下载、研究和二次开发。

快速入门
1、环境配置
推荐 Python 版本:3.10.0(使用其他版本可能导致依赖问题)。
强烈建议使用 conda 或 virtualenv 创建隔离环境。
ini
# Example with Conda
conda create -n react_infer_env python=3.10.0
conda activate react_infer_env2、安装
安装所需的依赖项:
pip install -r requirements.txt3、准备评估数据
在项目根目录下创建一个名为 eval_data/ 的文件夹。
将您的QA文件以JSON格式放置在这个目录中,例如 eval_data/example.json。
每一行必须是一个包含以下两个键的 JSON 对象:
json
{"question": "...","answer": "..."}在 eval_data 文件夹中提供了一个示例文件供参考。
如果你计划使用文件解析器工具, 需将文件名添加到问题字段前 ,并将引用的文件放置在 eval_data/file_corpus/ 目录内。
4、配置推理脚本
打开 run_react_infer.sh,并按照注释中的说明修改以下变量:
MODEL_PATH - 本地或远程模型权重的路径。
DATASET - 评估集的路径,例如 example。
OUTPUT_PATH - 用于保存预测结果的路径,例如 ./outputs。
根据您启用的工具(检索、计算器、网络搜索等),提供所需的 API_KEY、BASE_URL 或其他凭证。每个密钥在 bash 脚本中均有内联说明。
5、运行推理脚本
bash run_react_infer.sh这种开放的态度,对于整个AI社区的推动作用是巨大的。毕竟,只有更多人参与进来,这个技术才能更快进化,应用场景也能更广。

谢谢你看我的文章,既然看到这里了,如果觉得不错,随手点个赞、转发、在看三连吧,感谢感谢。那我们,下次再见。
您的一键三连,是我更新的最大动力,谢谢
山水有相逢,来日皆可期,谢谢阅读,我们再会
我手中的金箍棒,上能通天,下能探海